文章目录
- 一、序列化和反序列化
- 1.1 概念
- 1.2 场景
- 1.3 如何序列化
- 二、Protobuf介绍
- 1. 自身特点
- 2.使用特点
一、序列化和反序列化
1.1 概念
🎯[总结]:
- 序列化:把对象转换为字节序列的过程称为对象的序列化。
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
1.2 场景
🎯[总结]:
- 存储数据:把的内存中的对象状态保存到⼀个文件中或者存到数据库中时
- 网络传输:在网络间传输数据时
我们生活中都有过序列化和反序列化的场景:打电话的时候,我们说的和听到的都是声音信号,而传输过程中信号则是以光电的形式传输的。发送方将声音信号按照一定的协议转为光电信号的过程就是序列化,接收方将光电信号再转化为声音信号,重新还原原始的语音内容的过程就是反序列化。
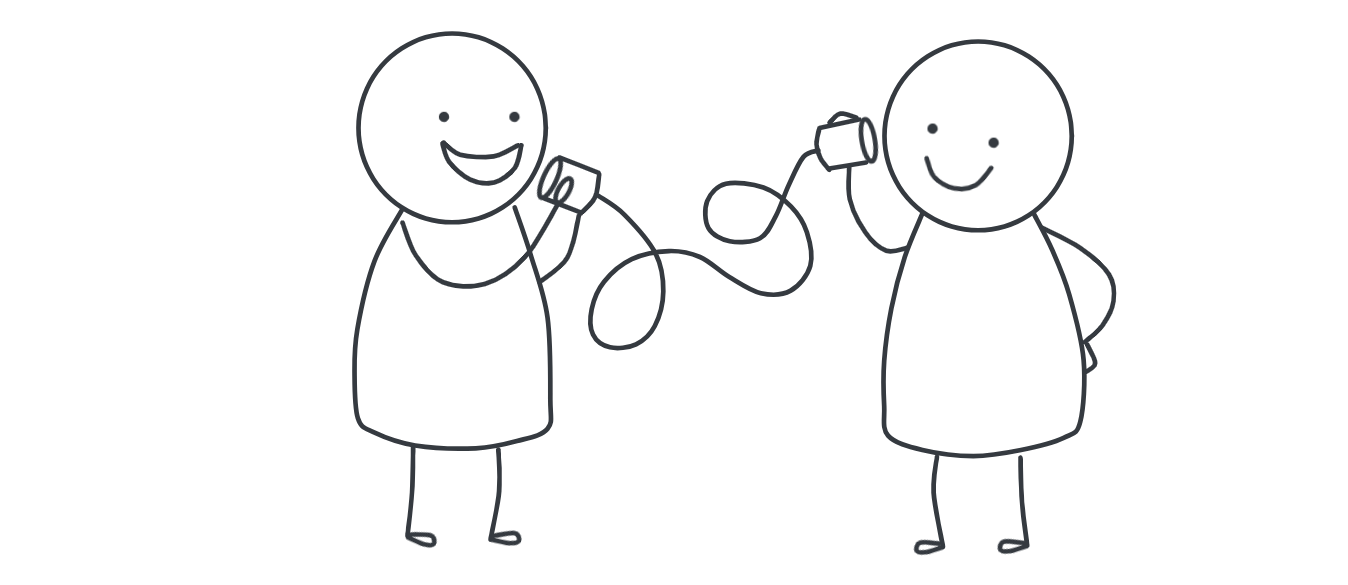
而在实际上在编程中,序列化和反序列化是将抽象的数据结构或对象转换为字节流,并再次还原回原始数据的过程。
序列化和反序列化的意义就在于,我们可以以一种通用的方式传输数据。例如在网络世界中,传输数据时我们只需要关注字节流。这省去了我们很多的麻烦,因为不同主机间内存对齐的方式可能不同、变量的大小也可能不同……如果以二进制的方式直接传输结构体对象,上面的问题我们都需要考虑。
而对于字节流,我们只需要按照一定的协议,一定能将结构体的信息完整正确的读出。例如对于下面这个结构体对象,我们可以设计这样的协议:结构体成员变量间用\3分隔,结构体间用\r\n分隔;一个结构体字节流中,先出现的代表id,后出现的代表name。
这样,虽然不同平台间的可能存在不同,但是协议规定了成员变量间用 \3 分隔。因此在没有读到 \3 之前,我们都认为这是一个成员变量的一部分;读到 \3 后表示一个完整的成员变量被读取了,此时我们只需要根据协议做字符串的类型转换即可。
struct data{
// ……
int id;
string name;
};
现在我们有如下两个结构体变量需要传输:
data d1(1, "A");
data d2(2, "B")
根据上面的协议序列化后就变成了这样一段字符串: 1\3A\r\n2\3B\r\n ,接收方收到这段字符串数据后,根据协议就能准确的读取出原来结构体成员的数据了
1.3 如何序列化
通过上面的例子我们可以看出,序列化反序列化和协议是息息相关的。对于复杂的项目来说,协议设计就不会这么简单了。如果每次序列化和反序列化这种重复但又不可缺少的工作要让程序员来做,那么程序员的效率要大打折扣。
于是涌现出了一批的工具来帮我们完成序列化和反序列化的工作,例如xml、json以及本系列教程所要重点说明了Protobuf
二、Protobuf介绍
1. 自身特点
首先看看官方文档对于Protobuf的介绍:
ProtocolBuffers是Google的⼀种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
ProtocolBuffers类比于XML,是⼀种灵活,高效,自动化机制的结构数据序列化方法,但是比XML更小、更快、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使⽤各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序
总结起来就是
- 语言无关、平台无关: 即ProtoBuf支持Java、C++、Python等多种语言,支持多个平台
- 高效: 比XML、JSON更小,更加高效
- 扩展性好
2.使用特点
ProtoBuf依赖通过Protoc编辑器编译生成的头文件和源文件来使用的:

在传统的业务逻辑中,程序员都需要在class中编写下面的内容:
- 定义一系列属性字段
- 处理字段的方法(例如get与set)
- 序列化和反序列化方法
但是使用Protobuf时,我们只需要完成第一步工作(定义属性字段),Protoc编译器会自动根据属性字段生成对应的处理方法和序列化反序列化方法,我们只需要调用对应的头文件即可。
下篇博客中将带大家完成Protobuf的环境安装