【人工智能】— 感知机、线性分类器、感知机、感知机、最小二乘法分类、模型复杂性和过度拟合、规范化
- Linear predictions 线性预测
- 分类
- 线性分类器
- 感知机
- 感知机学习策略
- 损失函数的选取
- 距离的计算
- 最小二乘法分类
- 求解最小二乘分类
- 矩阵解法
- 一般线性分类
- 模型复杂性和过度拟合
- 训练误差
- 测试误差
- 泛化误差
- 复杂度与过拟合
- 规范化
- 最小二乘分类小结
Linear predictions 线性预测
分类
从具有有限离散标签的数据中学习。机器学习中的主导问题
线性分类器
二元分类可以看作是在特征空间中分离类的任务(特征空间) 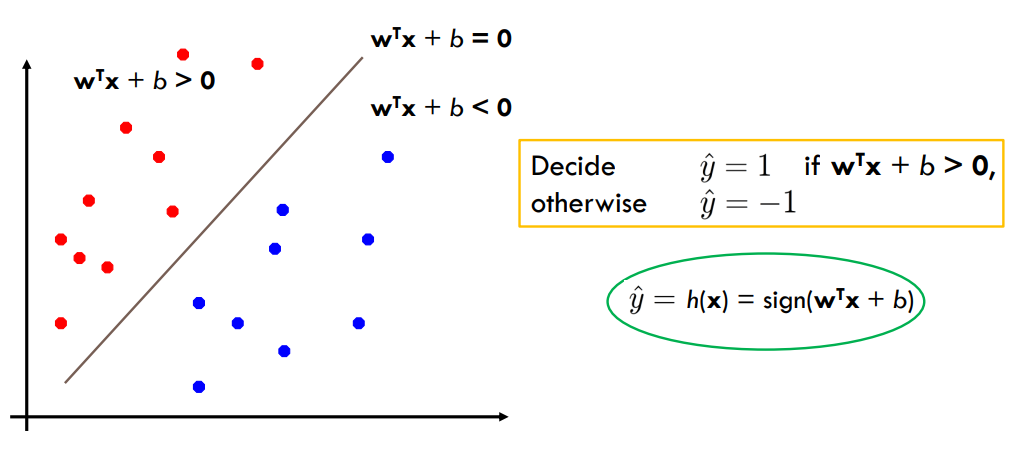
感知机
感知机是一种线性分类模型。它的决策边界是一个超平面,将特征空间分成了两个部分,分别对应于输出为 +1 和 -1 的两个类别。
感知机的线性分类模型可以表示为:
f ( x ) = sign ( w ⋅ x + b ) f(x) = \text{sign}(\boldsymbol{w} \cdot \boldsymbol{x} + b) f(x)=sign(w⋅x+b)
其中
w
\boldsymbol{w}
w和
b
\boldsymbol{b}
b为感知机模型参数,
w
∈
R
n
\boldsymbol{w}\in \textbf{R}^n
w∈Rn 是权重或者权值向量,
x
\boldsymbol{x}
x 是输入的特征向量,
b
∈
R
b\in \textbf{R}
b∈R 是偏置(bias),
w
⋅
x
w\cdot x
w⋅x 表示
w
w
w和
x
x
x的内积,
sign
(
⋅
)
\text{sign}(\cdot)
sign(⋅) 是符号函数。
sign
(
x
)
=
{
+
1
,
x
≥
0
−
1
,
x
<
0
\text{sign}(x)=\begin{cases} +1,\quad x \ge 0\\ -1,\quad x<0 \end{cases}
sign(x)={+1,x≥0−1,x<0
感知机的训练目标是找到一个能够将训练集中的正负样本完全分开的超平面,即找到一个合适的权重向量
w
\boldsymbol{w}
w 和偏置项
b
b
b,使得对于任意训练样本
(
x
i
,
y
i
)
(\boldsymbol{x}_i, y_i)
(xi,yi),都有
y
i
(
w
⋅
x
i
+
b
)
>
0
y_i (\boldsymbol{w} \cdot \boldsymbol{x}_i + b) > 0
yi(w⋅xi+b)>0
这个式子表达了感知机模型的训练目标,即让感知机能够对训练集中的正负样本进行完全分开,使得每个样本都被正确分类。
对于一个训练样本 ( x i , y i ) (\boldsymbol{x}_i, y_i) (xi,yi), y i y_i yi 是其真实的标签, x i \boldsymbol{x}_i xi是其特征向量, w \boldsymbol{w} w 是感知机的权重向量, b b b 是偏置项。根据感知机模型的定义,当 w ⋅ x i + b > 0 \boldsymbol{w} \cdot \boldsymbol{x}_i + b > 0 w⋅xi+b>0 时,模型的输出为 +1,否则输出为 -1。
因此,当 y i = + 1 y_i=+1 yi=+1 时,要求 w ⋅ x i + b > 0 \boldsymbol{w} \cdot \boldsymbol{x}_i + b > 0 w⋅xi+b>0,即要求模型将正样本正确分类为 +1。同理,当 y i = − 1 y_i=-1 yi=−1 时,要求 w ⋅ x i + b < 0 \boldsymbol{w} \cdot \boldsymbol{x}_i + b < 0 w⋅xi+b<0,即要求模型将负样本正确分类为 -1。
综合以上两种情况,我们可以将训练目标表达为 y i ( w ⋅ x i + b ) > 0 y_i (\boldsymbol{w} \cdot \boldsymbol{x}_i + b)>0 yi(w⋅xi+b)>0,即要求每个训练样本都被正确分类,即对于任意训练样本 ( x i , y i ) (\boldsymbol{x}_i, y_i) (xi,yi),都有 y i ( w ⋅ x i + b ) > 0 y_i (\boldsymbol{w} \cdot \boldsymbol{x}_i + b) > 0 yi(w⋅xi+b)>0。如果存在任意一个训练样本不能被正确分类,那么就需要不断地更新权重向量和偏置项,直到训练集中的所有样本都能被正确分类。
感知机学习策略
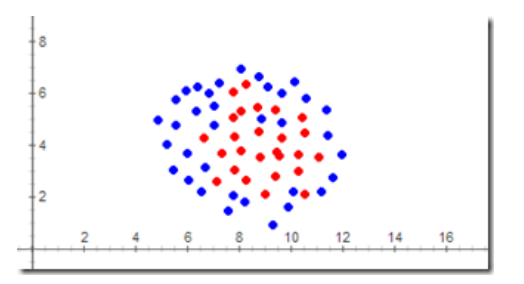
- 数据集线性可分性
- 在二维平面中,可以用一条直线将+1类和-1类完美分开,那么这个样本空间就是线性可分的。下图中的样本就是线性不可分的,感知机就不能处理这种情况。因此,感知机都基于一个前提:问题空间线性可分
损失函数的选取
-
损失函数的一个自然选择就是误分类点的总数,要找到决策边界,即分类超平面,使得分类误差最小,可以通过最小化期望的 0/1 损失函数来实现。对于一个样本 ( x , y ) (x, y) (x,y),0/1 损失函数定义为:
L ( h ( x ) , y ) = { 0 , h ( x ) = y 1 , h ( x ) ≠ y L(h(\textbf{x}), y) = \begin{cases} 0, \quad h(\textbf{x}) = y\\ 1, \quad h(\textbf{x}) \neq y \end{cases} L(h(x),y)={0,h(x)=y1,h(x)=y
其中, h ( x ) h(\textbf{x}) h(x) 是模型预测的输出, y y y 是样本的真实标签。但是这样的点不是参数 w , b w,b w,b的连续可导函数,不易优化 -
损失函数的另一个选择就是误分类点到划分超平面 S ( w ⋅ x + b = 0 ) S(\textbf{w} \cdot \textbf{x}+b=0) S(w⋅x+b=0)的总距离

距离的计算
点 x 0 x_0 x0 到超平面 S : w T x + b = 0 S: w^Tx+b=0 S:wTx+b=0 的距离 d d d(注: x 0 , w , x x_0,w,x x0,w,x全为N维向量)可以通过以下步骤计算:
- 设点 x 0 x_0 x0 在平面 S S S 上的投影为 x 1 x_1 x1,则有 w T x 1 + b = 0 w^Tx_1+b=0 wTx1+b=0
- -
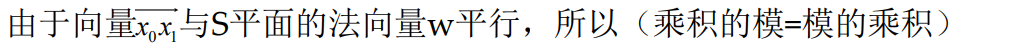


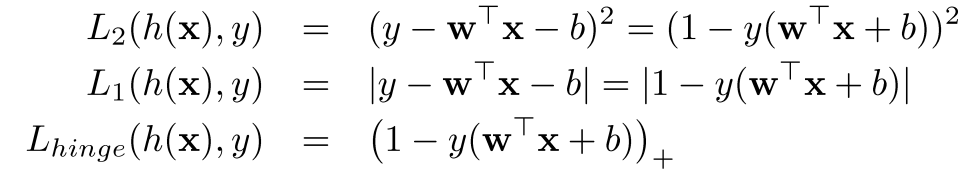
Lhinge(也称为 hinge 损失函数)是一种常用的分类器损失函数,通常用于支持向量机(SVM)和感知机等模型 中。它的形式如下:
L h i n g e ( w , b ; x , y ) = max { 0 , 1 − y ( w T x + b ) } L_{hinge}(w,b;x,y) = \max\{0, 1 - y(w^Tx+b)\} Lhinge(w,b;x,y)=max{0,1−y(wTx+b)}
其中, w w w 和 b b b 是模型的参数, x x x 是输入样本, y y y 是样本的标签,取值为 + 1 +1 +1 或 − 1 -1 −1,表示正类或负类。 h ( x ) = sign ( w T x + b ) h(x) = \text{sign}(w^Tx+b) h(x)=sign(wTx+b) 表示模型对样本 x x x 的预测输出。
当模型对样本 x x x 的预测结果正确时(即 y ( h ( x ) ) > 0 y(h(x))>0 y(h(x))>0),损失函数为 0 0 0;当模型对样本 x x x 的预测结果错误时(即 y ( h ( x ) ) ≤ 0 y(h(x))\leq 0 y(h(x))≤0),损失函数为 1 − y ( h ( x ) ) ( w T x + b ) 1-y(h(x))(w^Tx+b) 1−y(h(x))(wTx+b)。
这个损失函数的含义是,对于误分类的样本,我们希望让其距离超平面至少为 1 1 1,即 y ( w T x + b ) ≥ 1 y(w^Tx+b)\geq 1 y(wTx+b)≥1,如果距离小于 1 1 1,则损失函数为 1 − y ( w T x + b ) 1-y(w^Tx+b) 1−y(wTx+b),表示分类错误的程度;如果距离大于等于 1 1 1,则损失函数为 0 0 0,表示分类正确。
Lhinge 损失函数是一个凸函数,但不是连续可导的,因为在 y ( w T x + b ) = 1 y(w^Tx+b)=1 y(wTx+b)=1
时,存在一个“拐点”,导致其导数不连续。因此,在使用梯度下降等优化算法时,需要使用次梯度(subgradient)来代替导数,使得算法可以收敛。同时,Lhinge
损失函数也可以通过一些优化算法(如 SMO 算法)来求解支持向量机模型的最优解。
最小二乘法分类
最小二乘损失函数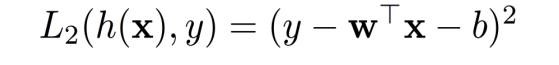
目标:学习分类器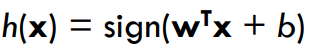 以最小化最小二乘损失
以最小化最小二乘损失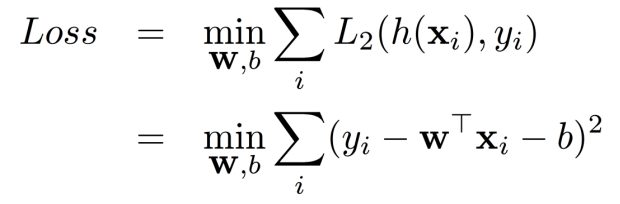
求解最小二乘分类
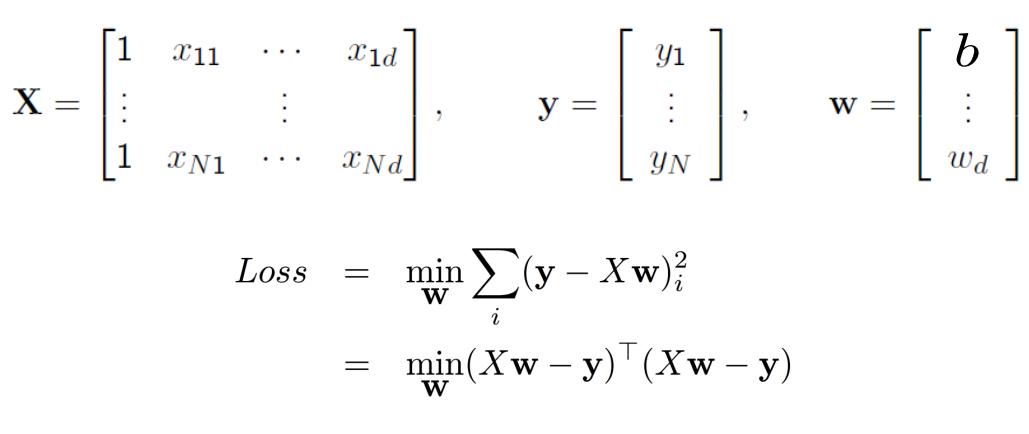
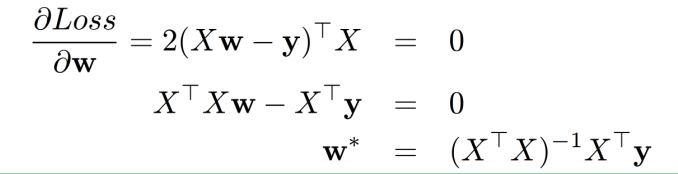
矩阵解法
线性回归定义为:
h
θ
(
x
1
,
x
2
,
…
x
n
−
1
)
=
θ
0
+
θ
1
x
1
+
…
+
θ
n
−
1
x
n
−
1
h_{\theta}\left(x_{1}, x_{2}, \ldots x_{n-1}\right)=\theta_{0}+\theta_{1} x_{1}+\ldots+\theta_{n-1} x_{n-1}
hθ(x1,x2,…xn−1)=θ0+θ1x1+…+θn−1xn−1
其中
θ
\theta
θ 为参数。假设现在有
m
m
m 个样本,每个样本有
n
−
1
n-1
n−1 维特征,将所有样本点代入模型中得:
h
1
=
θ
0
+
θ
1
x
1
,
1
+
θ
2
x
1
,
2
+
…
+
θ
n
−
1
x
1
,
n
−
1
h
2
=
θ
0
+
θ
1
x
2
,
1
+
θ
2
x
2
,
2
+
…
+
θ
n
−
1
x
2
,
n
−
1
⋮
h
m
=
θ
0
+
θ
1
x
m
,
1
+
θ
2
x
m
,
2
+
…
+
θ
n
−
1
x
m
,
n
−
1
\begin{aligned} h_{1} &=\theta_{0}+\theta_{1} x_{1,1}+\theta_{2} x_{1,2}+\ldots+\theta_{n-1} x_{1, n-1} \\ h_{2} &=\theta_{0}+\theta_{1} x_{2,1}+\theta_{2} x_{2,2}+\ldots+\theta_{n-1} x_{2, n-1} \\ & \vdots \\ h_{m} &=\theta_{0}+\theta_{1} x_{m,1}+\theta_{2} x_{m,2}+\ldots+\theta_{n-1} x_{m, n-1} \end{aligned}
h1h2hm=θ0+θ1x1,1+θ2x1,2+…+θn−1x1,n−1=θ0+θ1x2,1+θ2x2,2+…+θn−1x2,n−1⋮=θ0+θ1xm,1+θ2xm,2+…+θn−1xm,n−1
为方便用矩阵表示,我们令
x
0
=
1
x_0=1
x0=1,于是上述方程可以用矩阵表示为:
h
=
X
θ
\mathbf{h}=\mathbf{X} \theta
h=Xθ
其中,
h
\mathbf{h}
h 为
m
×
1
m \times 1
m×1 的向量,代表模型的理论值,
θ
\theta
θ 为
n
×
1
n \times 1
n×1 的向量,
X
\mathbf{X}
X 为
m
×
n
m \times n
m×n 维的矩阵,
m
m
m 代表样本的个数,
n
n
n 代表样本的特征数。于是目标损失函数用矩阵表示为:
J
(
θ
)
=
∥
h
−
Y
∥
2
=
∥
X
θ
−
Y
∥
2
=
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
J(\theta)=\|\mathbf{h}-\mathbf{Y}\|^2=\|\mathbf{X}\theta-\mathbf{Y}\|^2=(\mathbf{X} \theta-\mathbf{Y})^{T}(\mathbf{X} \theta-\mathbf{Y})
J(θ)=∥h−Y∥2=∥Xθ−Y∥2=(Xθ−Y)T(Xθ−Y)
其中
Y
\mathbf{Y}
Y 是样本的输出向量,维度为
m
×
1
m \times 1
m×1。
根据高数知识我们知道函数取得极值就是导数为0的地方,所以我们只需要对损失函数求导令其等于0就可以解出
θ
\theta
θ。矩阵求导属于矩阵微积分的内容,我们先介绍两个用到的公式:
∂
x
T
a
∂
x
=
∂
a
T
x
∂
x
=
a
\frac{\partial x^{T} a}{\partial x}=\frac{\partial a^{T} x}{\partial x}=a
∂x∂xTa=∂x∂aTx=a
∂
x
T
A
x
∂
x
=
A
x
+
A
T
x
\frac{\partial x^{T} A x}{\partial x}=Ax+A^{T} x
∂x∂xTAx=Ax+ATx
如果矩阵
A
A
A 是对称的:
A
x
+
A
T
x
=
2
A
x
Ax+A^{T} x=2Ax
Ax+ATx=2Ax
对目标函数化简:
J
(
θ
)
=
θ
T
X
T
X
θ
−
θ
T
X
T
Y
−
Y
T
X
θ
+
Y
T
Y
J(\theta)=\theta^{T} X^{T} X \theta-\theta^{T} X^{T}Y-Y^{T} X\theta+Y^{T} Y
J(θ)=θTXTXθ−θTXTY−YTXθ+YTY
求导令其等于0:
∂
∂
θ
J
(
θ
)
=
2
X
T
X
θ
−
2
X
T
Y
=
0
\frac{\partial}{\partial \theta} J(\theta)=2X^{T} X \theta-2X^TY=0
∂θ∂J(θ)=2XTXθ−2XTY=0
解得:
θ
=
(
X
T
X
)
−
1
X
T
Y
\theta=\left(X^{T}X\right)^{-1} X^{T}Y
θ=(XTX)−1XTY
经过推导我们得到了
θ
\theta
θ 的解析解,现在只要给了数据,我们就可以带入解析解中直接算出
θ
\theta
θ。
一般线性分类
基函数(非线性)
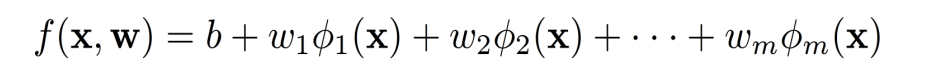
其中
ϕ
\phi
ϕ为基函数,用于拟合非线性
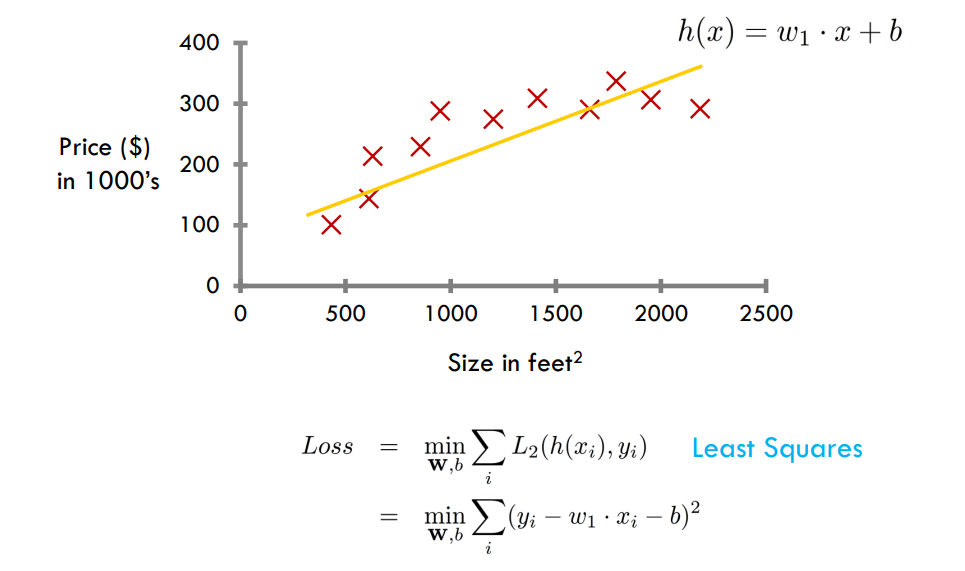
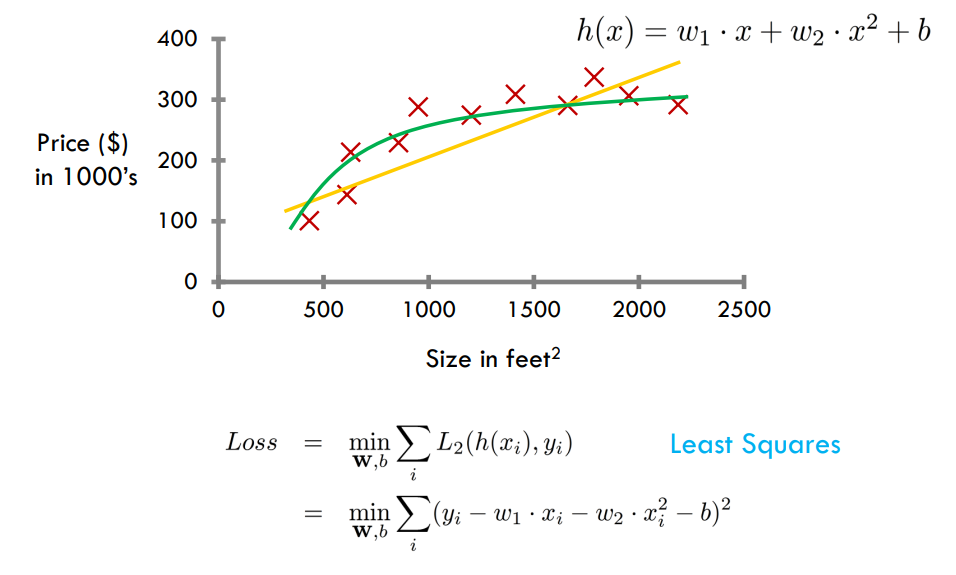
模型复杂性和过度拟合
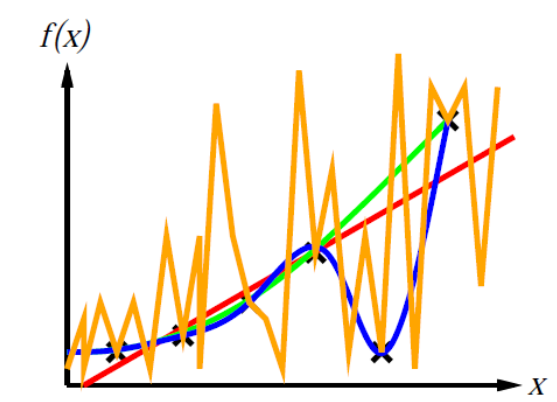
Ockham‘s razor(奥卡姆剃刀原则): maximize a combination of consistency and simplicity
优先选择与数据一致的最简单的假设
训练误差
训练误差(Training errors),也称为表观误差(Apparent errors),是指在训练数据集上用模型进行训练时所产生的误差。训练误差是模型在学习过程中不可避免的产物,通常我们希望训练误差越小越好,因为模型对训练数据的拟合程度越高,就越可能对未知数据产生良好的预测能力。但是,如果模型过于拟合训练数据,训练误差可能会变得非常小,但是这种模型可能会过度拟合,对于未知数据的预测性能将变得很差。
测试误差
测试误差(Test errors)是指在测试数据集上用模型进行测试时所产生的误差。测试误差用于评估模型的泛化能力,即模型是否具有对未知数据的预测能力。测试误差与训练误差之间的差异通常被称为泛化误差。
泛化误差
泛化误差(Generalization errors)是指模型在未知数据上的期望误差,即模型对于新数据的预测能力。泛化误差是机器学习中最为重要的概念之一,因为机器学习的目标是构建泛化能力强的模型,而不是仅仅在训练数据上表现良好的模型。泛化误差通常用测试误差来近似估计,但是测试误差只能提供模型的一种局部估计,因此为了更准确地估计模型的泛化误差,需要使用交叉验证等方法。
复杂度与过拟合
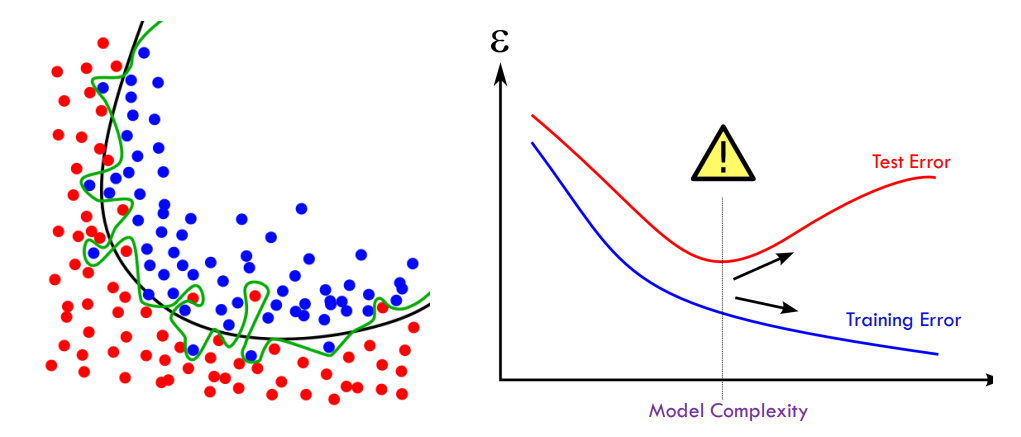
欠拟合:当模型过于简单时,训练和测试误差都很大
过拟合:当建模过于复杂时,训练误差很小,但测试误差很大
给定两个具有相似泛化误差的模型,人们应该更喜欢更简单的模型而不是更复杂的模型
复杂的模型更有可能因数据错误而意外拟合
因此,在评估模型时应包括模型复杂性
规范化

λ
λ
λ是惩罚权重
取
w
w
w的L2范数作为惩罚项,让系数的取值变得平均。对于关联特征,能够获得更相近的对应系数
L1范数,系数
w
w
w的L1范数作为惩罚项加到损失函数上,由于非零,迫使那些弱的特征所对应的系数变成0,达到特征选择
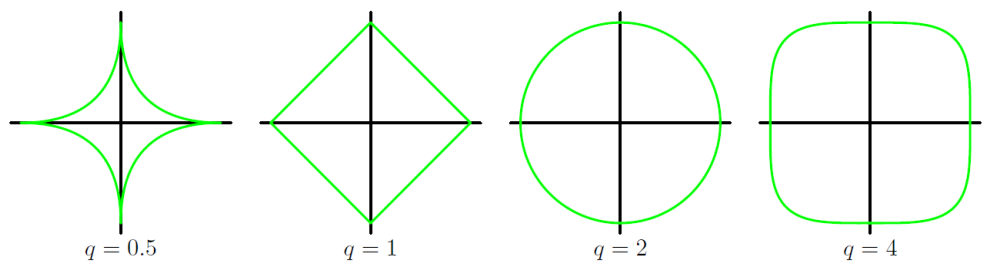
当𝜆 足够大,相当于:
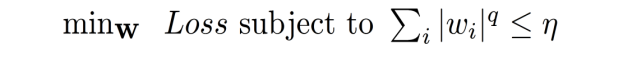
不同q值的正则化项的等高线
最小二乘分类小结
- 不是进行分类的最佳方法
- 但是易于训练的封闭式解决方案(闭式解=解析解)
- 可以与许多经典学习原理联系起来