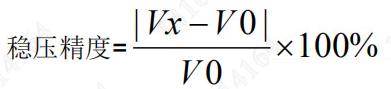1.安装指令
pip install scrapy2.创建 scrapy 项目
任意终端 进入到目录(用于存储我们的项目)
scrapy startproject 项目名
会在目录下面 创建一个以 项目名 命名的文件夹
终端也会有提示
cd 项目名
scrapy genspider example example.com
3.运行爬虫指令
scrapy crawl 爬虫名 --nolog //nolog是不看日志
4.输出 xml csv json格式的文件
scrapy crawl 爬虫名 -o 文件名
5.目录

(1)__init__.py 此文件为项目的初始化文件,主要写的是一些项目的初始化信息。
(2)items.py 爬虫项目的数据容器文件,主要用来定义我们要获取的数据
(3)piplines.py 爬虫项目的管道文件,主要用来对items里面定义的数据进行进一步的加工与处理
(4)settings.py 爬虫项目的设置文件,主要为爬虫项目的一些设置信息
(5)spiders文件夹 此文件夹下放置的事爬虫项目中的爬虫部分相关
6.novel.py文件
import scrapy
from scrapy import Selector
# scrapy01 文件的名字
# items scrapy01文件下面的名字
# Scrapy01Item items里面的类名
from scrapy01.items import Scrapy01Item
class NovelSpider(scrapy.Spider):
# 爬虫名
name = "novel"
#允许爬取的域名
allowed_domains = ["www.shicimingju.com"]
# 爬取的具体地址 必须在 允许域名的下面 子域名
start_urls = ["https://www.shicimingju.com/book/hongloumeng.html"]
# parse 爬取到数据 默认/调用的
def parse(self, response):
# response 已经 是爬取的结果 requests.get()
sel = Selector(response)
li_list = sel.css('div.book-mulu > ul > li')
for li_item in li_list:
novel_item = Scrapy01Item()
# 章节是 a标签内容
# 取标签内容 标签名::text
# extract() 所有的标签
# extract_first() 第一个标签
chapter = li_item.css('a::text').extract_first()
# 链接是 a标签属性
# 取标签属性值 标签名::(属性)
url = li_item.css("a::attr(href)").extract_first()
# novel_item的字段和 items.py里面 定义的模型 对应
novel_item['chapter'] = chapter
novel_item['url'] = url
print("novel_item:",novel_item)
# return novel_item # 循环一次就出去了
yield novel_item # yield 迭代器
# 配置伪装 头 settings里面配置 17行
7.piplines.py文件对数据进行json和xlsx导出
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import json
import openpyxl
from itemadapter import ItemAdapter
class Scrapy01XlsxPipeline:
def __init__(self):
print('init---------初始化')
# 创建工作库
self.wb = openpyxl.Workbook()
# 获取激活的工作
self.ws = self.wb.active
self.ws.title = '红楼梦'
# 参数是元组
self.ws.append(('章节','地址'))
# item就是爬虫文件 解析/parse的数据
def process_item(self, item, spider):
print('process_item-----钩子----数据',item)
# item.['chapter']
chapter = item.get('chapter','默认值')
url = item.get('url') or ''
# 追加数据
self.ws.append((chapter,url))
return item
# 开始爬取 必须写第二个参数spider
def open_spider(self,spider):
print('打开蜘蛛')
# 爬取完毕
def close_spider(self,spider):
self.wb.save('红楼梦1.xslx')
print('爬取完毕')
class Scrapy01JsonPipeline:
def __init__(self):
# 存储爬取的数据
self.data = []
self.fp = open("./练习.json",'w',encoding='utf-8')
# 拿到数据就走
def process_item(self,item,spider):
url = item.get("url") or ''
chapter = item.get("chapter",'')
# 添加爬取数据
self.data.append((chapter,url))
# 防止每爬取一次数据就写一次
if len(self.data)>50:
json.dump(self.data,self.fp,ensure_ascii=False)
self.data.clear()
return item
def close_spider(self,spider):
if len(self.data) > 0:
json.dump(self.data, self.fp, ensure_ascii=False)
self.fp.close()
print('关闭')
# 共52条数据
# 节流 51次写入一次 置空
# 第52次 完了走关闭 发现还有一条数据写入
8.items.py
import scrapy
class Scrapy01Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
chapter = scrapy.Field()
# 存储 章节内容的url
url=scrapy.Field()
# 根据自己的需求 定义字段 N个9.settings.py文件
1.USER_AGENT需要打开爬取数据
USER_AGENT ="Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57"2.开启管道,Scrapy01XlsxPipeline和Scrapy01JsonPipeline都是iplines.py文件中的类名。
# 开启管道 配置多个管道 数字越小优先级越小
# Scrapy01XlsxPipeline 管道文件类名
ITEM_PIPELINES = {
"scrapy01.pipelines.Scrapy01XlsxPipeline": 300,
"scrapy01.pipelines.Scrapy01JsonPipeline": 200,
}