收录于合集
#开源4个
#GIS34个
#社交媒体2个
#大数据4个
哈喽大家好,我又来啦!最近一直有小伙伴私戳问我要
签到数据,本着开源共享的精神,我这次给大家分享中国多个城市2022年9月的匿名签到数据,欢迎大家点击在看转发,您的支持是喵喵原创写作最大的动力!也欢迎与我做朋友!
之前几期我们介绍过微博数据的获取,大概获取为下图所示的json数据。
我们以杭州市为例,对json进行简单的处理,转化为csv格式,对属性进行一个统计。数据主要的属性有这些:
'userid', 'lng', 'lat', 'username', 'repostscount', 'weibotext', 'weiboid', 'createtime', 'fansnum', 'location', 'imgurl', 'follow_num', 'gender', 'Address', 'Heat', 'Source', 'city'

分别是用户的ID,经纬度,转发数,终端设备,地址描述,性别等信息。

单条微博平均转发数约为1.5,平均关注约为1242。可以看到这里的lng与lat值为0,不要担心,只是我抓取的时候为了避免网络错误,避免因秘钥超出配额引发的各种各样的错误特意设置的。
我们先来看看如何根据名称请求地址。

这位男性微博用户签到地址为 杭州·神游,不知道是什么类型的地址。我们使用百度API对其进行解析,将 杭州·替换为 杭州市,将 city限制在杭州,大家自己申请地址解码API,每天大概有5000次的免费额度。s
-
http://api.map.baidu.com/geocoder?address=" + address + "&city=" + str(city) + "&output=json&key=你申请的key
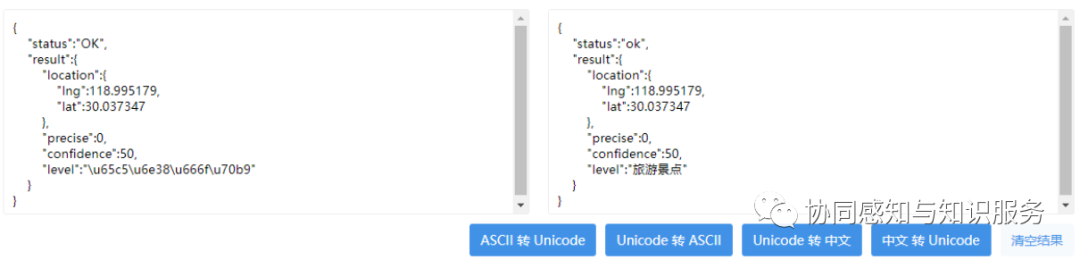
请求的结果长这样。



经纬度很容易看出来,这个奇怪的字符是啥?啥啥啥,写的都是啥?
我们将这个奇怪的Unicode编码转成中文试试,哦,原来这个神游有50%(confidence)的可能是个旅游景点...
我们知道,由于国家法律规定坐标需要加密,所以我们经常在谷歌地球上看到这种奇怪的位置偏移。
我们使用网上开源的纠偏算法对其进行处理,这一步骤的代码如下,当然您也可以点击文末的阅读原文访问Github代链接。
import requestsimport timeimport jsonimport reimport osfrom pyquery import PyQuery as pqimport mathimport os,jsonimport pandas as pdkey = '' # 这里填写你的百度开放平台的keyx_pi = 0pi = 0 # πa =0 # 长半轴ee = 0 # 扁率#椭球参数关注微信公众号“协同感知与知识服务”(sensingcity)后台回复 椭球参数 免费获取def transformlat(lng, lat):ret = -100.0 + 2.0 * lng + 3.0 * lat + 0.2 * lat * lat + \0.1 * lng * lat + 0.2 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 *math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lat * pi) + 40.0 *math.sin(lat / 3.0 * pi)) * 2.0 / 3.0ret += (160.0 * math.sin(lat / 12.0 * pi) + 320 *math.sin(lat * pi / 30.0)) * 2.0 / 3.0return retdef transformlng(lng, lat):ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng + \0.1 * lng * lat + 0.1 * math.sqrt(math.fabs(lng))ret += (20.0 * math.sin(6.0 * lng * pi) + 20.0 *math.sin(2.0 * lng * pi)) * 2.0 / 3.0ret += (20.0 * math.sin(lng * pi) + 40.0 *math.sin(lng / 3.0 * pi)) * 2.0 / 3.0ret += (150.0 * math.sin(lng / 12.0 * pi) + 300.0 *math.sin(lng / 30.0 * pi)) * 2.0 / 3.0return retdef out_of_china(lng, lat):"""判断是否在国内,不在国内不做偏移:param lng::param lat::return:"""if lng < 72.004 or lng > 137.8347:return Trueif lat < 0.8293 or lat > 55.8271:return Truereturn Falsedef bd09togcj02(bd_lon, bd_lat):"""百度坐标系(BD-09)转火星坐标系(GCJ-02)百度——>谷歌、高德:param bd_lat:百度坐标纬度:param bd_lon:百度坐标经度:return:转换后的坐标列表形式"""x = bd_lon - 0.0065y = bd_lat - 0.006z = math.sqrt(x * x + y * y) - 0.00002 * math.sin(y * x_pi)theta = math.atan2(y, x) - 0.000003 * math.cos(x * x_pi)gg_lng = z * math.cos(theta)gg_lat = z * math.sin(theta)return [gg_lng, gg_lat]def gcj02towgs84(lng, lat):"""GCJ02(火星坐标系)转GPS84:param lng:火星坐标系的经度:param lat:火星坐标系纬度:return:"""if out_of_china(lng, lat):return lng, latdlat = transformlat(lng - 105.0, lat - 35.0)dlng = transformlng(lng - 105.0, lat - 35.0)radlat = lat / 180.0 * pimagic = math.sin(radlat)magic = 1 - ee * magic * magicsqrtmagic = math.sqrt(magic)dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * pi)dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * pi)mglat = lat + dlatmglng = lng + dlngreturn [lng * 2 - mglng, lat * 2 - mglat]def bd09towgs84(lng, lat): # 114.277591,30.580842result2 = bd09togcj02(lng, lat)result4 = gcj02towgs84(result2[0], result2[1])return result4# 日期转换def trans_format(time_string):from_format = '%a %b %d %H:%M:%S +0800 %Y'to_format = '%Y-%m-%d %H:%M:%S'time_struct = time.strptime(time_string, from_format)times = time.strftime(to_format, time_struct)return timesdef geocodeB(address, city):loca = {}try:if address.find('·'):address = address.replace('·', '市', 1)base = "http://api.map.baidu.com/geocoder?address=" + address + "&city=" + str(city) + "&output=json&key="+keyresponse = requests.get(base,timeout=(3.05, 27))answer = response.json()tamped = bd09towgs84(answer['result']['location']['lng'], answer['result']['location']['lat'])loca['lng'] = tamped[0]loca['lat'] = tamped[1]level=answer['result']['level']loca['level']=levelprint(address,loca['lng'], loca['lat'],level)if loca:return locaexcept:print(address)loca['lng'] = 0loca['lat'] = 0loca['level']='无'return loca# geocodeB(address, city)def get_latlng(location,address_dict,cityname):if location in address_dict:loca = address_dict[location]else:loca = geocodeB(location, cityname)# print(location)address_dict[location] = locareturn loca#前面是坐标转换分割线######################def pdfFilesPath(path):filePaths = [] # 存储目录下的所有文件名,含路径for root,dirs,files in os.walk(path):for file in files:if file.split('.')[-1]=='json':filePaths.append(os.path.join(root,file))return filePathsif __name__=='__main__':# 原始Json文件所在文件夹filepath = r'C:\全国微博数据'files=pdfFilesPath(filepath)#我们抓取的字段columns=['user_id','lng','lat','user_name','reposts_count','weibo_text','weibo_id','create_time','fans_num','location','img_url','follow_num','gender','Address','Heat','Source','city']for file in files:#每个城市一个地址词典address_dict = {}with open(file,'rb+') as f:tmp=f.readlines()cityname=json.loads(tmp[0])['city']print('正在处理...'+cityname)if cityname in ['长沙','深圳','广州','上海','杭州','郑州','成都','天津','福州','南京']:with open(cityname+'.csv','w+',encoding='utf-8') as f:for col in columns:f.write(col)f.write(',')f.write('\n')for i in tmp:data=json.loads(i)for col in columns:f.write(str(data[col]).replace('\n',''))f.write(',')f.write('\n')df=pd.read_csv(cityname+'.csv',error_bad_lines=False)rf=df.drop_duplicates(subset=['weibo_id'], keep='first', inplace=False)rf=rf.drop(['Unnamed: 17'], axis=1)rf['latlng'] = rf.apply(lambda x: get_latlng(x['location'],address_dict,cityname), axis=1)rf['lat'] = rf.apply(lambda x: x['latlng']['lat'], axis=1)rf['lng'] = rf.apply(lambda x: x['latlng']['lng'], axis=1)rf['level'] = rf.apply(lambda x: x['latlng']['level'], axis=1)rf=rf.drop(['latlng'], axis=1)rf.to_csv('完整版'+cityname+'.csv',index=None)rf[['user_id','lng','lat','reposts_count','weibo_text','weibo_id','create_time','fans_num','location','follow_num','gender','Address','Heat','Source','city']].head(20000).to_csv('共享版'+cityname+'.csv',index=None)
这样处理还有一点小的缺点,因为百度API的准确度并不能达到100%,如果遇见异常值,使用address而不是location字段应该会避免一些问题(使用天目山路518号东南方向160米而不是神游),当然如果地址过于模糊,如(杭州)这样就没办法啦。好啦,那么我们进行下一步。先看看各个值的分布。

玩微博的还是女性多一些,约为男性的2.5倍。
看看上个月Top10的签到位置。

不懂就问,西湖热度很高可以接受,这个下沙是个什么地方?

之前我们分享了上海的AOI数据,那么我们再来展点试试。
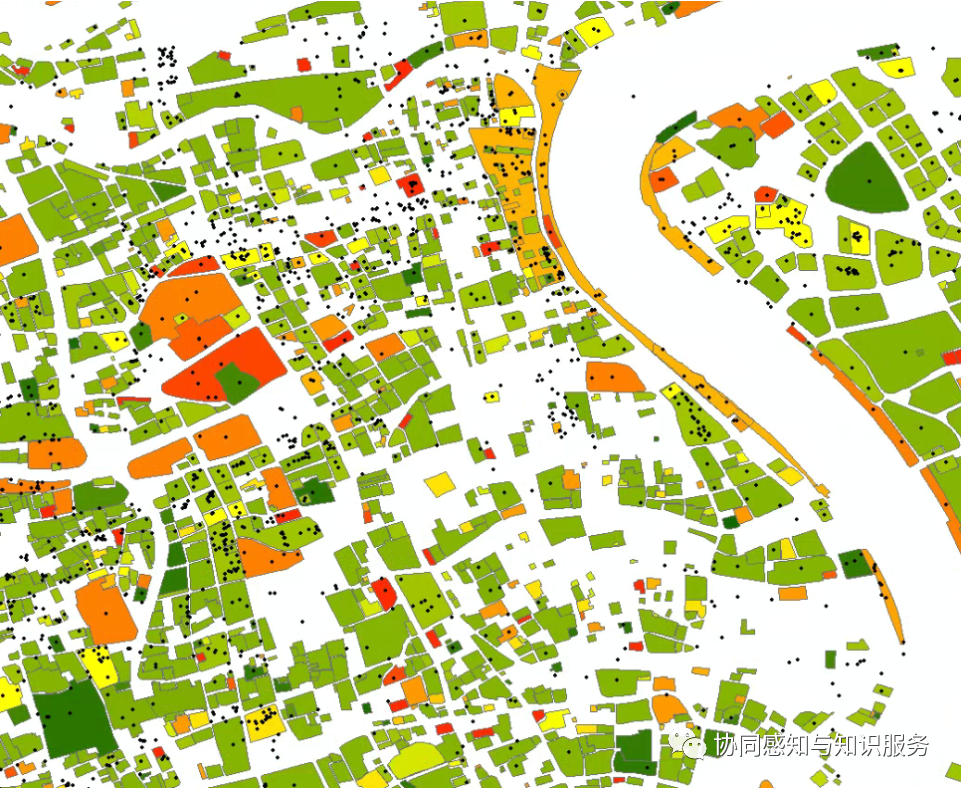
借助这种时间序列数据,完全可以做城市活力的研究了。它的分布格局也与街景均匀感知不同,属于高度的空间有偏感知。
点击阅读原文获取坐标纠偏代码,我们分享了8个城市的POI数据,公开版分享了部分数据并删除了个人敏感信息,回复:
南京POI 获取南京市签到数据
天津POI 获取天津市签到数据
深圳POI 获取深圳市签到数据
广州POI 获取广州市签到数据
上海POI 获取上海市签到数据
杭州POI 获取杭州市签到数据
成都POI 获取成都市签到数据
福州POI 获取福州市签到数据
好啦,我们下期见,分享我们录用在 Journal of Environmental Management 上的碳排放空间平等和空间正义的研究。
如果您觉得有帮助,请引用以下至少一篇文章。
1.Zhang Y, Chen Z, Zheng X, et al. Extracting the location of flooding events in urban systems and analyzing the semantic risk using social sensing data[J]. Journal of Hydrology, 2021, 603: 127053.
2.Chen N, Zhang Y, Du W, et al. KE-CNN: A new social sensing method for extracting geographical attributes from text semantic features and its application in Wuhan, China[J]. Computers, Environment and Urban Systems, 2021, 88: 101629.