文章目录
- 数据定义语言 DDL
- 表的设计
- 范式
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 创建表
- 修改表
- 删除表
- 截断表
数据定义语言 DDL

前面我们学习的 DML 语言,主要实现对数据的增、删、改等基本操作。而数据定义语言(Data Definition Language,DDL)则是实现对数据结构、操作等的定义。 例如,对数据库、数据表、索引等的设计、创建、修改、删除等操作,都属于 DDL 范围。接下来,就让我们一起进入 DDL 的学习之旅。
表的设计
表是数据库中最重要的对象,是数据库的基本存储单元,由行(记录)和列(字段)组成。 表名和 Java 语言中的变量名一样,有自己的命名规则:
- 英文字母、数字和下划线 _ 组成,命名简洁明确,多个单词用下划线 _ 连接;
- 英文全部使用小写,禁止出现大写;
- 禁止使用数据库关键字,如:name,time ,datetime,password 等;
- 表名称不应该取得太长(一般不超过三个英文单词);
- 表的名称一般使用名词或者动宾短语;
- 使用英语名词时,用单数形式表示名称,而不用复数,例如,使用 employee 表示员工表,而不是 employees。
设计表时应遵循一个基本原则:只将实体的直接属性纳入。举例说明:已考虑公民表有姓名、年龄、联系方式、国籍四个字段,国籍对应国家,那么国家信息(如名称、代码、语言等)是否该放入这个表?
一种考虑是,直接在该表中增加国家信息的多个字段,该表中既有个人信息,也有国家信息。但这会产生一个问题,以中国为例,该表至少有 13 亿条记录,个人直接属性是不同的,但国家信息部分会重复 13 亿次,造成了存储空间的极大浪费。
第二种方法就是拆分,把个人信息和国家信息拆分成两个表。如此国家信息表中只需要一条记录就可以表示中国的信息。在此基础上,利用我们前学习的连接查询可同时得到个人信息和国家信息。
单表的字段设计,多表的关系设计,这些都需要数据库设计范式的指导。
范式
关系型数据库目前有 6 种范式,数据库设计好坏的判断标准就是看它满足了第几范式。通过企业项目对数据库的使用来看,一般情况下我们只要满足前三个范式即可,所以笔者也重点介绍前三范式。
第一范式(1NF)
指在关系模型中,数据库表的每一列都是不可分割的原子数据项。即实体中的某个属性有多个值时,必须拆分为多个属性。
| 学号 | 姓名 | 专业/学院 | 课程名 | 分数 |
|---|---|---|---|---|
| 1 | 小张 | 大数据专业/计算机学院 | HTML | 98 |
| 1 | 小张 | 大数据专业/计算机学院 | JAVA | 95 |
| 2 | 小李 | 大数据专业/计算机学院 | Python | 100 |
| 2 | 小李 | 大数据专业/计算机学院 | MySQL | 90 |
| 3 | 小王 | 金融管理专业/财经学院 | 经济学 | 85 |
在上表中,“专业/学院”这个字段包含了专业和学院两个值,根据 1NF 的要求,必须把“专业/学院”拆分为“专业”和“学院”两个字段。拆分后的表如下表所示:
| 学号 | 姓名 | 专业 | 学院 | 课程名 | 分数 |
|---|---|---|---|---|---|
| 001 | 小张 | 大数据专业 | 计算机学院 | HTML | 98 |
| 001 | 小张 | 大数据专业 | 计算机学院 | JAVA | 95 |
| 002 | 小李 | 大数据专业 | 计算机学院 | Python | 100 |
| 002 | 小李 | 大数据专业 | 计算机学院 | MySQL | 90 |
| 003 | 小王 | 金融管理专业 | 财经学院 | Linux | 85 |
此时该表符合了第一范式。
第二范式(2NF)
在 1NF 的基础上,2NF 要求表必须有主码,非码属性必须完全依赖于主码。要完全理解 2NF 的含义,需要先弄清楚几个概念:
-
函数依赖:设有属性 A、B,如果通过 A 属性(或属性组)的值可以确定唯一 B 属性的值,则可以称为 B 依赖 A 或者 A 决定 B,用 “->” 来表示决定(依赖)关系,记作 A->B。例如,可以通过身份证号来确定学生姓名。
函数依赖又分为三种:分别是完全函数依赖、部分函数依赖、传递函数依赖。- 完全函数依赖:如果 A 是一个属性组(由多个属性组成),则 B 属性值的确定需要依赖 A 属性组中的所有属性值。例如:把学号和课程名作为属性组,分数的确定就必须要同时知道学号和课程名才行。少了学号,不知道是谁的成绩;少了课程名,只知道谁的成绩而不知道是哪门课的成绩。所以该属性组的两个值必不可少,这就是完全函数依赖。
- 部分函数依赖:如果 A 是一个属性组,则 B 属性值的确定只需要依赖 A 属性组中的部分属性值。例如:把学号和课程名作为属性组,姓名的确定只需要 A 中的学号即可,和课程名无关。这就是部分函数依赖。
- 传递函数依赖:即依赖的传递关系,通过 A 可以确定 B,记作 A->B;通过 B 可以确定 C,记作 B->C;可得出 A->C;这就是传递依赖关系。
-
候选码:如果表中,一个属性或属性组,被其它所有属性完全函数依赖,则称这个属性或属性组为该表的候选码,简称码。成绩表中有学号、课程名、分数三个属性,分数的确定完全依赖学号和课程名,所以学号和课程名组成的属性组就是该表的候选码。
-
主属性码:主属性码也叫主码,在多个候选码中挑选一个做主码,也即是我们常说的主键。
-
非主属性码:除主属性码以外,其余的叫做非主属性码。
理解了这些概念以后,再来判断上表是否符合 2NF 的标准。
步骤如下:
- 找出数据表中所有的候选码;
- 根据候选码,找出主属性码;
- 得到非主属性码;
- 查看非主属性码对主属性码是否完全依赖(不存在部分函数依赖)。
具体实现:
第一步:
- 查看每一个单一属性,当它的值确定了,剩下的所有属性值是否都能确定。该表中单一属性都没法确定其它属性的值。如:以学号为主键,对应的课程名却出现了多个,所以学号不是候选码。
- 查看所有两两属性的属性组,当属性组确认后,剩下的所有属性值是否都能确定。
依次类推,最后得到该表的候选码只有一个,即(学号,课程名)。
第二步:
因为候选码只有一个,所有主码也就确定了。
第三步:
非主属性码就是(姓名,专业,学院,分数)
第四步:
判定非主属性码是否部分函数依赖主码?
对于主码(学号,课程名)->姓名,只需要学号即可确定姓名,所以存在非主属性码姓名,对主码(学号,课程名)的部分函数依赖。此时我们可以判定之前的表不满足 2NF。
为了让之前的表满足 2NF,我们需要消除表中部分函数依赖,办法只有一个,那就是拆分表。将之前的表拆分为两个表。一个叫做选课表,包含的属性有学号、课程名、分数;另一个叫做学生信息表,包含的属性有学号、姓名、专业、学院,如下选课表和学生信息表所示。
选课表
| 学号 | 课程名 | 分数 |
|---|---|---|
| 001 | HTML | 98 |
| 001 | JAVA | 95 |
| 002 | Python | 100 |
| 002 | MySQL | 90 |
| 003 | Linux | 85 |
学生信息表
| 学号 | 姓名 | 专业 | 学院 |
|---|---|---|---|
| 001 | 小张 | 大数据专业 | 计算机学院 |
| 002 | 小李 | 大数据专业 | 计算机学院 |
| 003 | 小王 | 金融管理专业 | 财经学院 |
对于选课表,学号和课程名是主码,唯一的非主属性分数对主码完全函数依赖。所以该表符合 2NF;对于表 学生信息表,学号是主码,该码只有一个属性,所以不存在非主属性对码的部分函数依赖,符合 2NF。 达到 2NF 还会出现什么问题呢?请看第三范式。
第三范式(3NF)
在 2NF 的基础上,3NF 要求不存在传递依赖。也即是,如果存在非主属性码对于码存在传递函数依赖,则不符合 3NF。
如学生信息表,主码为学号,非主属性码为姓名、专业、学院。因为学号->专业,专业->学院,所以学生信息表存在传递函数依赖,不符合 3NF。为此我们需要把学生信息表拆分成两个表,如学生专业表与专业信息表。
学生专业表
| 学号 | 姓名 | 专业 |
|---|---|---|
| 001 | 小张 | 大数据专业 |
| 002 | 小李 | 大数据专业 |
| 003 | 小王 | 金融管理专业 |
专业信息表
| 专业 | 学院 |
|---|---|
| 大数据专业 | 计算机学院 |
| 金融管理专业 | 财经学院 |
拆分以后,当再想删除某个专业的所有学生信息的时候,专业信息不会一起被删除。满足 3NF 后,我们所设计的表就具有较好的规范了,同时降低了数据冗余。
创建表
创建表,使用的 SQL 语句是 CREATE TABLE,其基本语法形式如下:
CREATE TABLE table
(colname1 type1, colname2 type2…colnamen typen)
其中,table 表示表名,colname1,colname2,…表示表的字段名,type1,type2,…是字段的数据类型。 创建表 6-7,其 SQL 语句如下:
create table student
(student_id int,
student_name varchar(20),
student_specialty varchar(20)
);
输出结果:
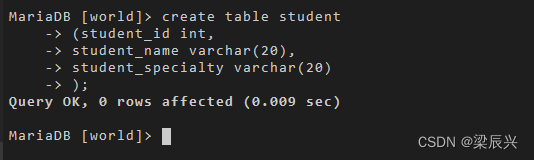
提醒:SQL 语句以 ;表示结束,上述例子虽然写了四行,但是仅表示一条语句;且每个字段与字段类型之间用空格隔开,字段与字段之间用 , 分隔,最后一个字段的类型后面可以不加 ,。
使用 show tables 命令列出所有表。如下所示:
show tables;
输出结果:
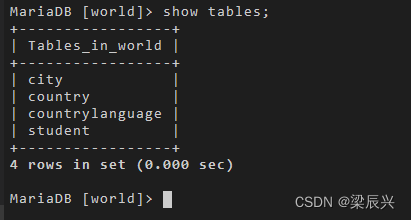
也可以使用 desc 命令查看某个表的结构,如下所示:
desc student;
输出结果:
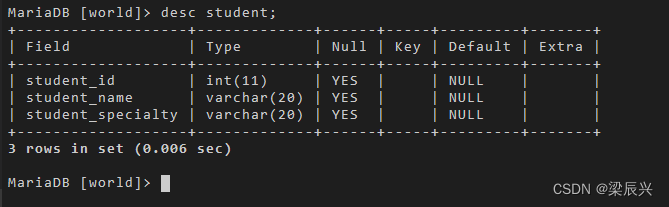
我们主要关心 Field 和 Type 两列即可,后面的四列我们会在下一节 MySQL 约束控制中介绍。 细心的朋友可能已经发现,我们将 student 表中的 student_id 定义为 int 时,没有指定长度,而查看表结构的时候,int 的长度显示为 11。这是因为 int 默认长度为 11(也是其默认长度)。
修改表
如果我们需要对表结构进行更改,比如添加或者删除一个字段,或者重命名某个字段等等。在改动不大的前提下,可以在原表的基础上进行修改。
修改表使用的 SQL 语句是 ALTER TABLE,有 3 种形式,分别是修改字段、添加字段、删除字段。
其中修改字段分两种:
只改字段名而不改字段类型,其 SQL 语法如下:
ALTER TABLE table CHANGE oldcolname newcolname type;
不改字段名而只修改字段类型,其 SQL 语法如下:
ALTER TABLE table MODIFY colname newtype;
添加字段语法如下:
ALTER TABLE table ADD colname type;
删除字段语法如下:
ALTER TABLE table DROP colname;
以 student 表为例:
增加一个名为 age 的年龄字段,类型为 int,实现的 SQL 语句如下:
alter table student add age int;
输出结果:

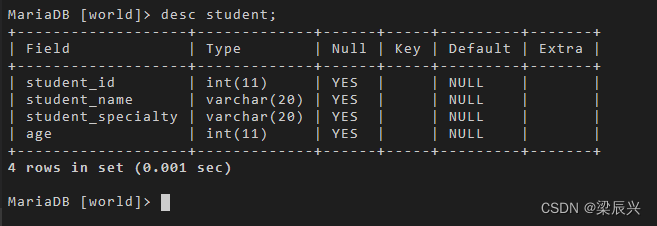
使用 desc 命令查看表结构的变化:
desc student;
输出结果:
修改表字段,原属性都是以 student 为前缀。为保持命名风格的统一,现修改 age 字段为 student_ age,实现的 SQL 语句如下:
alter table student change age student_age int;
输出结果:

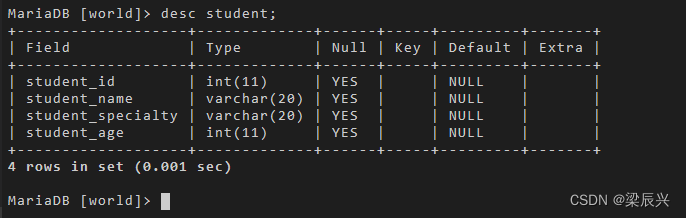
使用 desc 命令查看表结构的变化:
desc student;
输出结果:
change 只修改字段名,modify 修改的是字段的类型,其 SQL 语句如下:
alter table student modify student_age float;
输出结果:

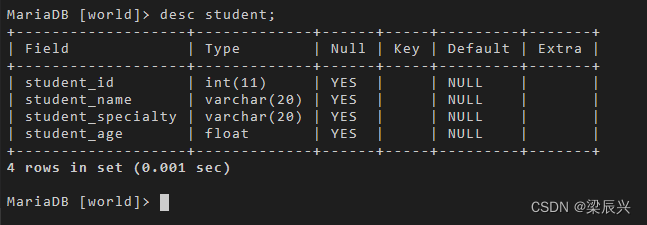
使用 desc 命令查看表结构的变化:
desc student;
输出结果:
删除字段则比较简单,在 drop 后面跟上字段名即可,不用指出字段类型。现把添加的 student_age 字段给删除,其 SQL 语句如下:
alter table student drop student_age;
输出结果:

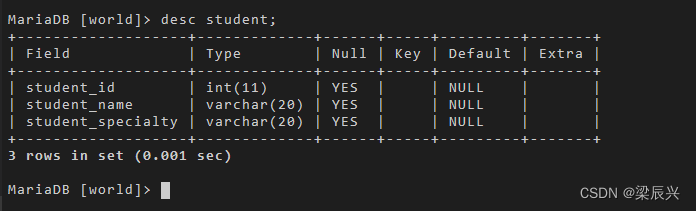
使用 desc 命令查看表结构的变化:
desc student;
输出结果:
删除表
在 MySQL 中,表的删除操作有三种,这里我们先说两种。分别是利用 DROP TABLE 语句实现表的删除,以及前面提过的 DELETE FROM table 。
两者的区别在于:
- DROP TABLE 不仅仅删除表的内容、而且会删除表的结构并释放空间。通俗的讲就是,整个表没了,想操作这张表已不可能,只有重新去创建一个。
- DELETE FROM table 删除的是表中的数据,就是清空表。系统需要一行一行的去删除,效率低下。
现有一张 student 表,表中数据如下结果所示:
select * from student;
输出结果:

使用 delete from student 对表进行删除操作,结果如下:
delete from student;
输出结果:

使用 show tables 命令,结果如下:
show tables;
输出结果:
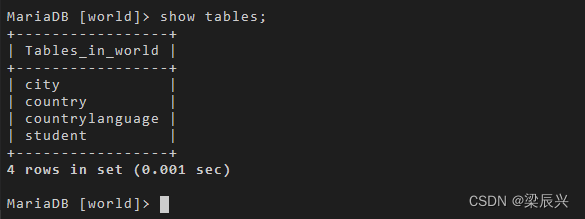
结果显示 student 表还在,然后查看表中数据。
select * from student;
输出结果:

说明 delete from 语句确实只删除了数据。接下来使用 drop table 对表进行删除操作,其 SQL 语句如下:
drop table student;
输出结果:

使用 show tables 命令,结果如下:
show tables;
输出结果:
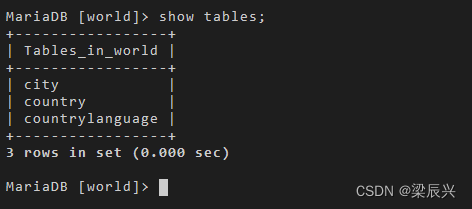
结果显示表已经删除,数据也丢失。
截断表
截断表的作用和 delete from 语句类似,删除表中所有的数据。截断表使用的语句是 TRUNCATE TABLE 。它和 delete from 区别在于,TRUNCATE TABLE 语句是数据定义语句,提交后不会产生回滚信息,所以它的速度更快。 其语法如下:
TRUNCATE TABLE table;
现有新建同样一张 student 表:
create table student
(student_id int,
student_name varchar(20),
student_specialty varchar(20)
);
insert into student
values
(1,'小章','大数据专业'),
(2,'小李','大数据专业'),
(3,'小蓝','计算机专业');
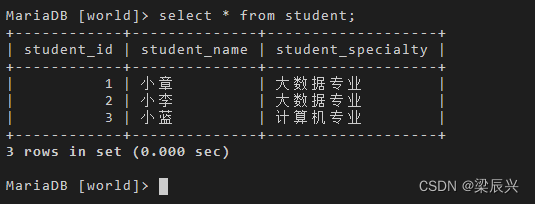
表中数据如下结果所示:
select * from student;
输出结果:
使用 TRUNCATE TABLE 后结果如下:
truncate table student;
输出结果:

查看表中数据,结果如下:
select * from student;
输出结果:

可以看出此时表仍然存在,和 delete from 实现的效果差不多,真正的差别只有当我们要清空的表数据量庞大的时候才能体现出来。