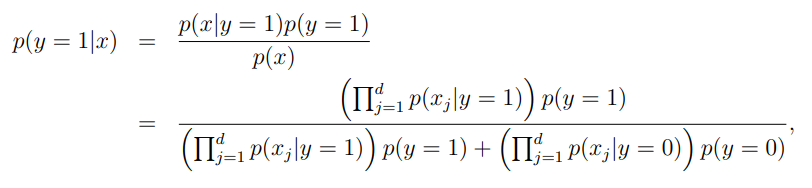最近几个月,整个AI行业的LLM(大语言模型)蓬勃发展,除了过去传统的纯文字的多模态能力的视觉语言模型,如 GPT-4,ImageBind等表现令人印象深刻。
ChatGLM-6B是中文用户使用非常舒服的一个开源中文LLM。2023年5月17日,智谱AI和清华大学KEG实验室开源了基于ChatGLM-6B的多模态对话模型VisualGLM-6B——不仅可以进行图像的描述及相关知识的问答,也能结合常识或提出有趣的观点。智谱在 ChatGLM-6b基础上,开源了多模识别的大模型 VisualGLM-6b。VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 依靠来自于 CogView 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练,中英文权重相同。该训练方式较好地将视觉信息对齐到ChatGLM的语义空间;之后的微调阶段,模型在长视觉问答数据上训练,以生成符合人类偏好的答案。
今天我们就简单安装使用一下VisualGLM-6b,然后再了解一下其背后核心工作原理。
VisualGLM-6b 使用安装
系统环境(我的环境)
GPU:NVIDIA A30 24G
OS:Windows 11
Python: 3.8.13
PyTorch: 1.12.1+cu113
Transformers: 4.29.1
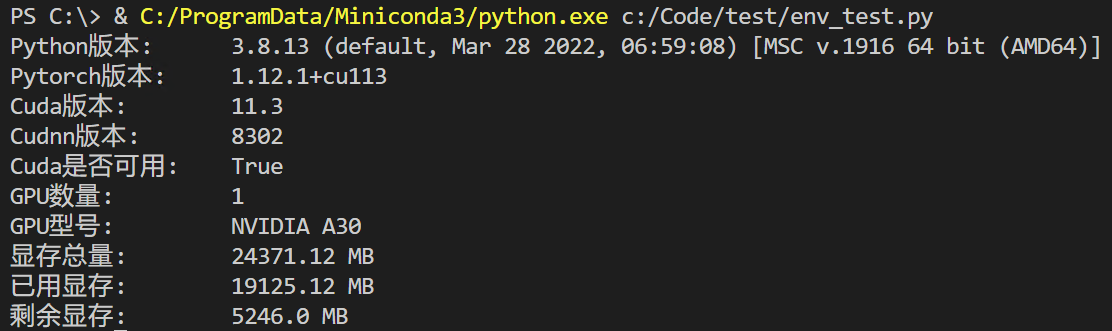
附:读取环境信息代码:
import sys
import torch # pip install torch
import pynvml # pip install pynvml
# 获取GPU信息
def get_gpu_info(gpu_id=0):
pynvml.nvmlInit()
handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
gpu_name = pynvml.nvmlDeviceGetName(handle)
handler = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handler)
gpu_mem_total = round(meminfo.total / 1024 / 1024, 2)
gpu_mem_used = round(meminfo.used / 1024 / 1024, 2)
gpu_mem_free = round(meminfo.free / 1024 / 1024, 2)
print("GPU型号:\t", gpu_name)
print("显存总量:\t", gpu_mem_total, "MB")
print("已用显存:\t", gpu_mem_used, "MB")
print("剩余显存:\t", gpu_mem_free, "MB")
# 输出env信息
print("Python版本: \t", sys.version)
print("Pytorch版本: \t", torch.__version__)
print("Cuda版本: \t", torch.version.cuda)
print("Cudnn版本: \t", torch.backends.cudnn.version())
print("Cuda是否可用:\t", torch.cuda.is_available())
print("GPU数量: \t", torch.cuda.device_count())
get_gpu_info()如果想要顺利使用VisualGLM,建议Python版本3.6+,个人推荐 3.8.x或者3.10.x 更稳妥,然后依赖的cuda版本最好是11.3以上;GPU显存不能低于16G,否则无法正常运行。
操作系统推荐 Windows 或 Ubuntu 比较稳妥。
如果要监测NVIDIA显卡的内存情况,使用nvidia-smi命令:(每隔10秒显示一次显存剩余)
nvidia-smi -l 10
安装使用VisualGLM-6b
如果只是简单直接在命令行里测试VisualGLM-6b,可以直接下载调用源码和基础模型就可以了。如果想要运行web界面,还会依赖一个SAT模型,会自动下载安装。
调用源码:GitHub - THUDM/VisualGLM-6B: Chinese and English multimodal conversational language model | 多模态中英双语对话语言模型
基础模型:THUDM/visualglm-6b · Hugging Face
SAT模型:https://cloud.tsinghua.edu.cn/f/348b98dffcc940b6a09d
快速安装步骤:(以为Windows环境为例)
git clone https://github.com/THUDM/VisualGLM-6B cd VisualGLM-6B pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.3.6"
VisualGLM-6b 效果测试
手工模型测试代码:
from transformers import AutoModel, AutoTokenizer
import torch
# 模型文件和图片路径
# model_name = "THUDM/visualglm-6b"
model_path = "C:\\Data\\VisualGLM-6B\\visualglm-6b"
# pic_path = "C:\\Users\\mat\\Pictures\\test\\kld00.jpg"
# pic_path = "C:\\Users\\mat\\Pictures\\test\\cat00.jpg"
# pic_path = "C:\\Users\\mat\\Pictures\\test\\sl00.jpg"
# pic_path = "C:\\Users\\mat\\Pictures\\test\\kh00.jpg"
pic_path = "C:\\Users\\mat\\Pictures\\test\\code00.jpg"
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
image_path = pic_path
# 进行提问
response, history = model.chat(tokenizer, image_path, "描述这张图片。", history=[])
print(response)
response, history = model.chat(tokenizer, image_path, "这张图片可能是在什么场所拍摄的?", history=history)
print(response)代码中的 pic_path 就是需要测试的图片文件路径,可以支持 JPG/PNG/WEBP 等格式,提前把文件下载好指定目录。
如果基础模型下载到了本地,在Windows系统上面记得 model_path 必须后面路径中斜线必须是 \\,如果是 / 则无法找到模型文件。
模型代码调用测试
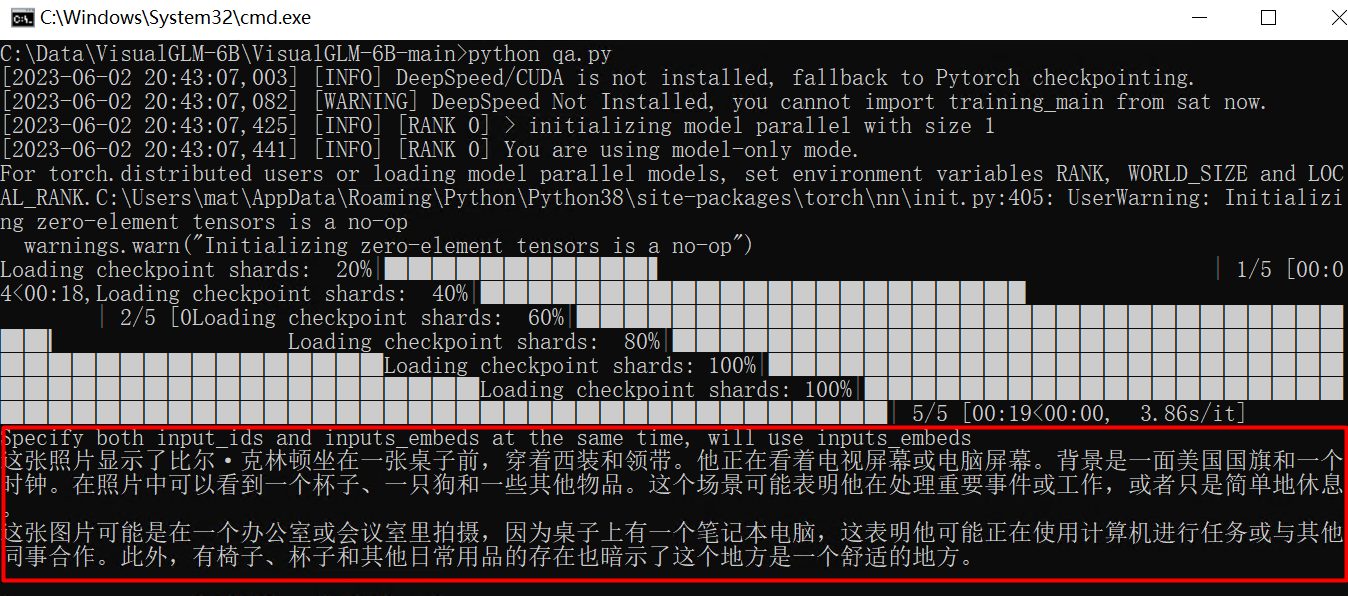
人物识别:

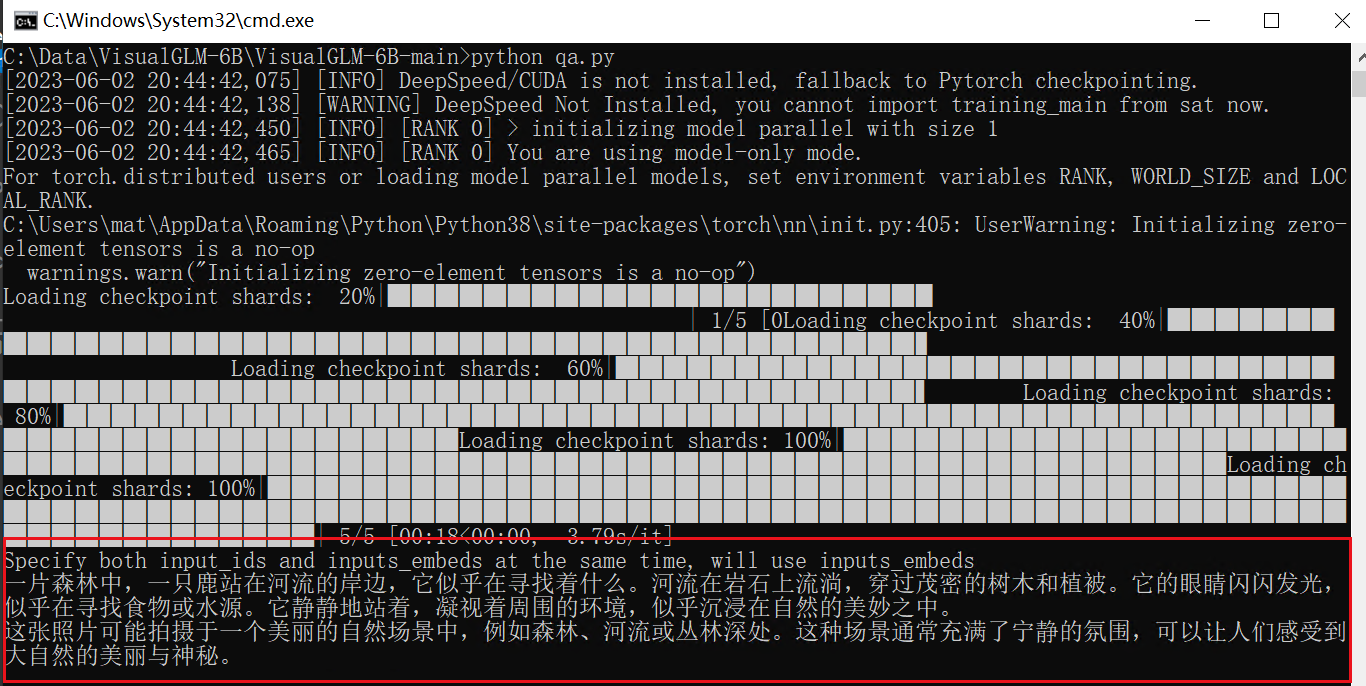
动物环境识别:

猫咪识别:


室内场景识别:


代码识别:
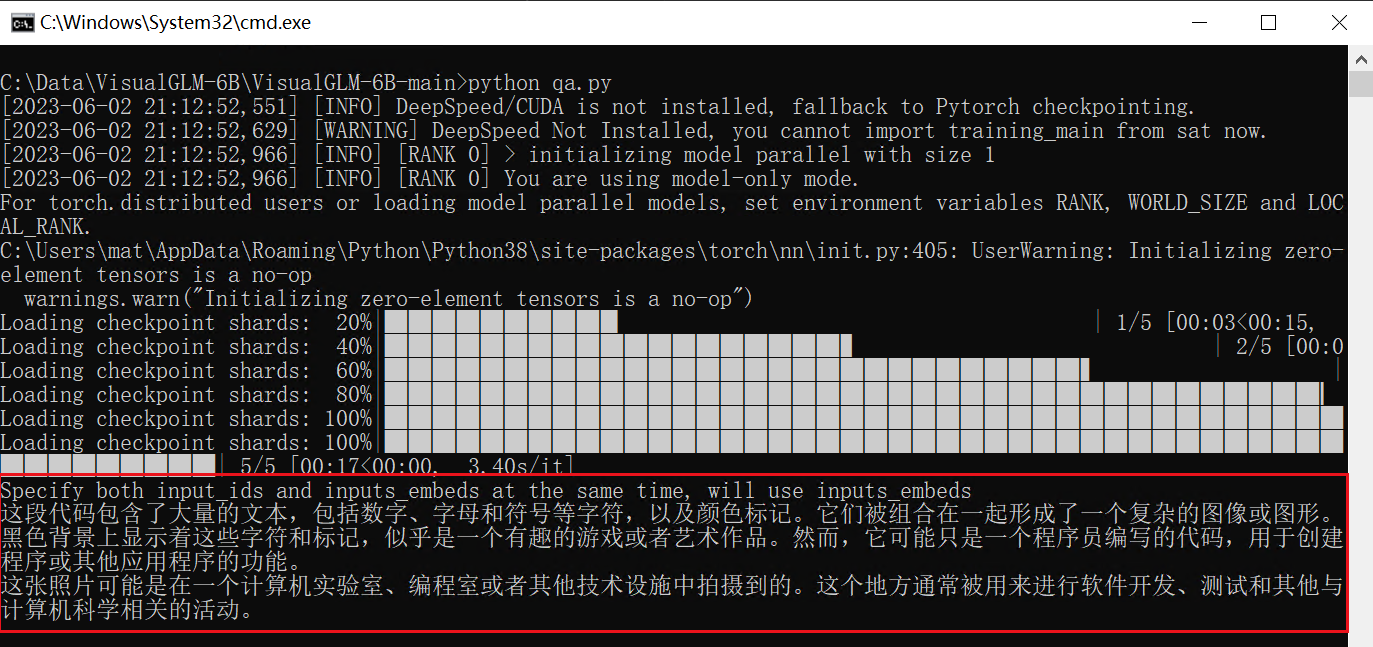
Web界面交互测试
执行步骤代码:
git clone https://github.com/THUDM/VisualGLM-6B cd VisualGLM-6B pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.3.6" python web_demo.py
然后等待自动下载安装SAT模型,完成后就会自动加载了,然后访问本地的:
http://127.0.0.1:7860
就可以通过Web界面访问本地的 VisualGLM 了,如果交互很多次,可能GPU显存占用很大,记得点击“清除”清理一下,能够减少显存占用。
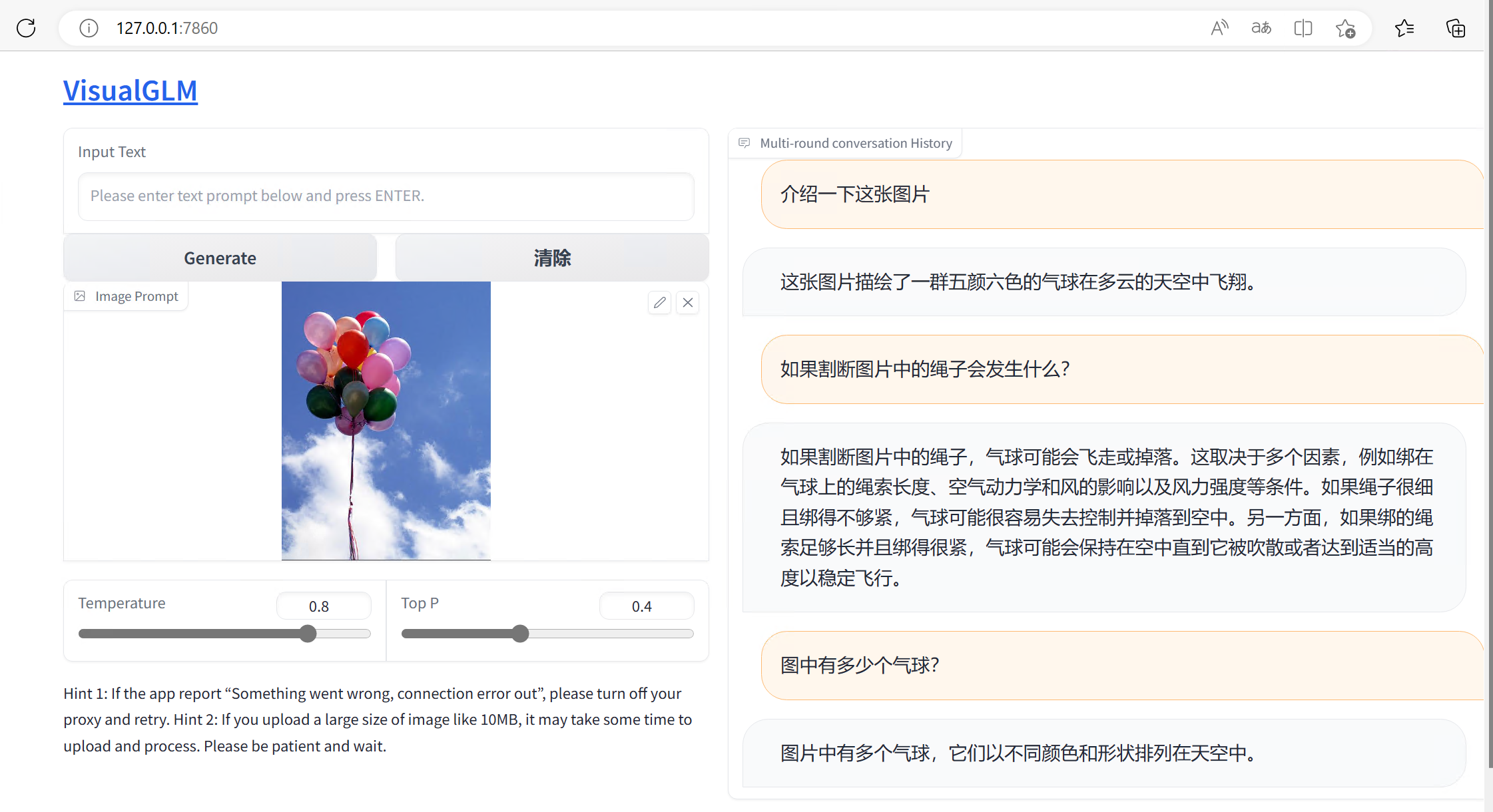
动物识别:
名人识别:

代码识别:

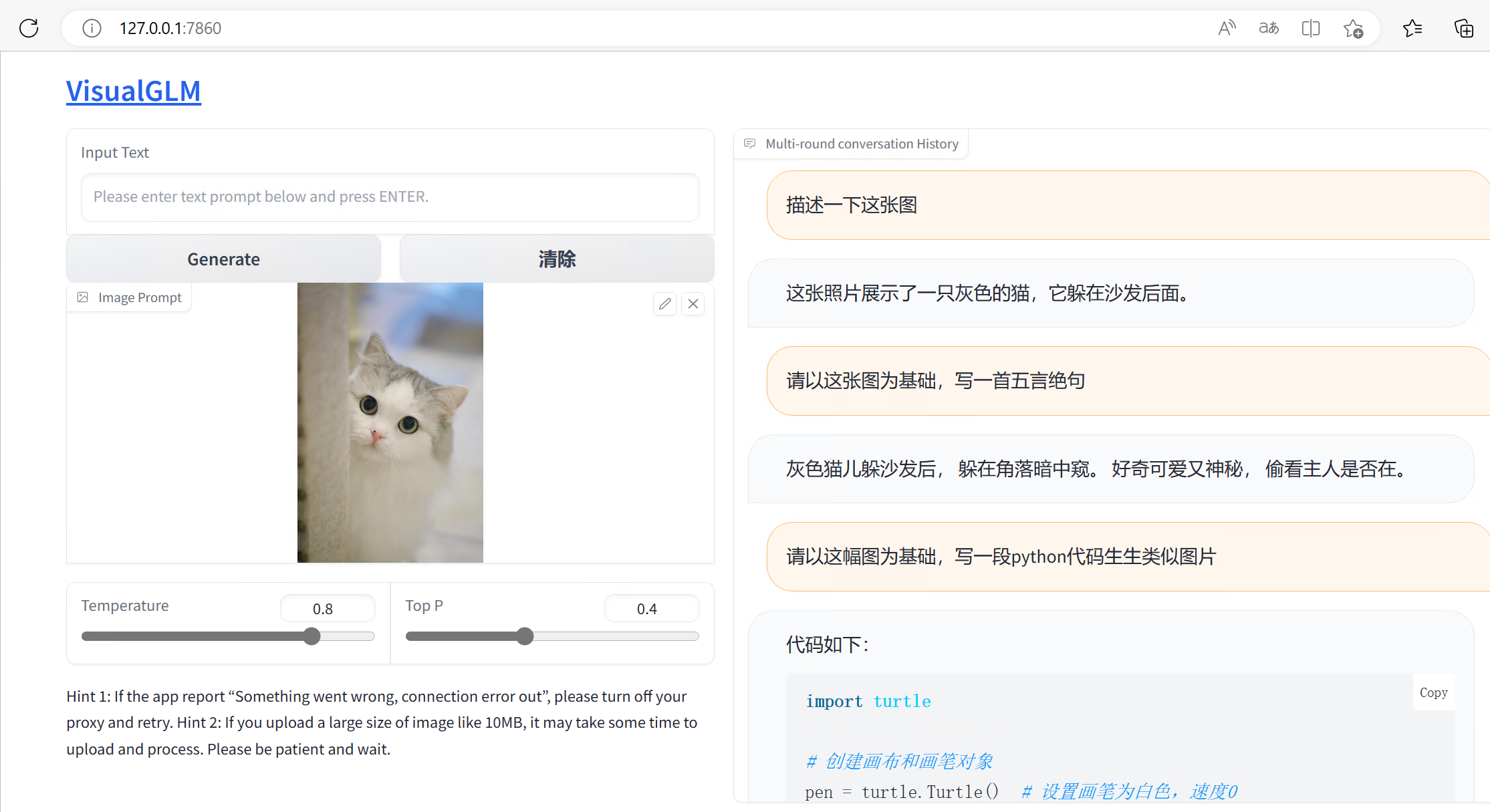
图片推理:
人物着装识别:

VisualGLM背后的技术原理
VisualGLM 能够进行图像的识别和针对图像进行相关 交互,本质也是一个LLM(大语言模型),但是整个基于图像的大语言模型,跟传统的的ChatGPT这种还是有点不同,要了解神奇之处,就需要关注背后的核心技术:BLIP-2。
对于多模的大语言模型,除了常规的基于Transformer的LLM学习,VisualGLM中比较重要的是图像-文本的对应关系处理,有点类似于Stable Diffusion中的CLIP的关系,而VisualGLM-6b中主要使用的技术是 BLIP-2的训练方法来进行图片-文本的处理。
BLIP(Bootstrapping Language-Image Pre-training),引导式语言图像预训练方法,主要属于视觉语言预训练(Vision-language pre-training)的方式。
传统的视觉模型和方法还存在两个主要的缺陷:
1、从模型角度来看,大多数方法要么采用基于编码器的模型,要么采用编码器-解码器模型。然而,基于编码器的模型不太容易直接迁移到文本生成的任务中,如图像标题(image captioning)等;而编码器-解码器模型还没有被成功用于图像-文本检索任务。
2、从数据角度来看,大多数sota的方法,如CLIP, ALBEF, SimVLM 都是对从网上收集的图像-文本对(image-text pair)进行预训练。尽管可以通过扩大数据集的规模来获得性能上的提高,但研究结果显示,有噪声的网络文本对于视觉语言学习来说只能得到次优的结果。
为此,Junnan Li等人提出了一个新的模型BLIP(Bootstrapping Language-Image Pre-training)。
BLIP-2 一种通用的、计算效率高的视觉-语言预训练方法,它利用了冻结的预训练图像编码器和LLM,性能优于Flamingo、BEIT-3等网络。
BLIP2大概由这么几个部分组成,图像(Image)输入了图像编码器(Image Encoder),得到的结果与文本(Text)在Q-Former(BERT初始化)里进行融合,最后送入LLM模型。
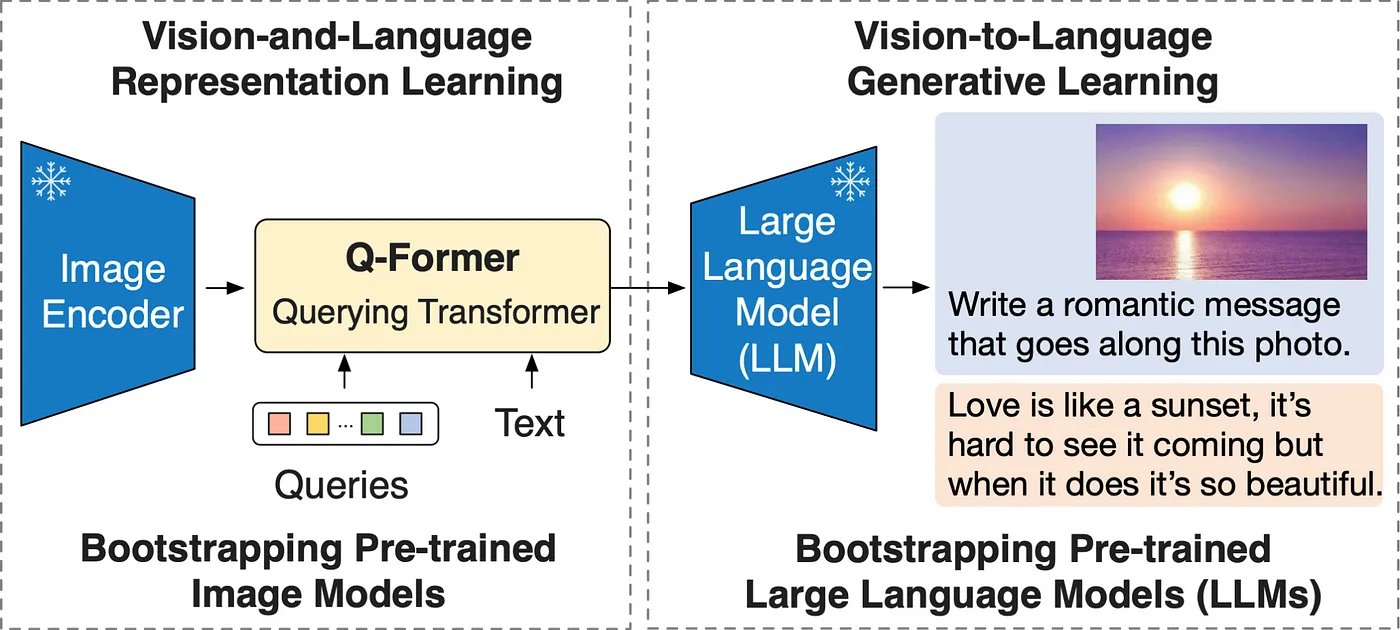
BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
LLM(比如GLM和GPT)本质上是个语言模型,自然无法直接接受其他模态的信息。所以如何把各个模态的信息,统一到LLM能理解的特征空间,就是第一步要解决的问题。为此,BLIP中就提出了Q-Former。
其中的Q-Former 是一个 transformer 模型,为了融合特征,那Transformer架构是最合适不过的了,Q-Former它由两个子模块组成,这两个子模块共享相同的自注意力层:
与冻结的图像编码器交互的图像 transformer,用于视觉特征提取文本 transformer,用作文本编码器和解码器。
对于Q-Former模型的训练,就是由以上三个任务组成,通过这几个任务,实现了对于特征的提取与融合,但现在模型还没见过LLM。
Q-Former的三个训练任务分别是:
Image-Text Contrastive Learning (ITC),图片文本对比学习
Image-grounded Text Generation (ITG),基于图像的文本生成
Image-Text Matching (ITM),图像文本的匹配

这几个任务都是以Query特征和文本特征作为输入得到的,只不过有不同的Mask组合。图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过相同的自注意力层与文本进行交互。
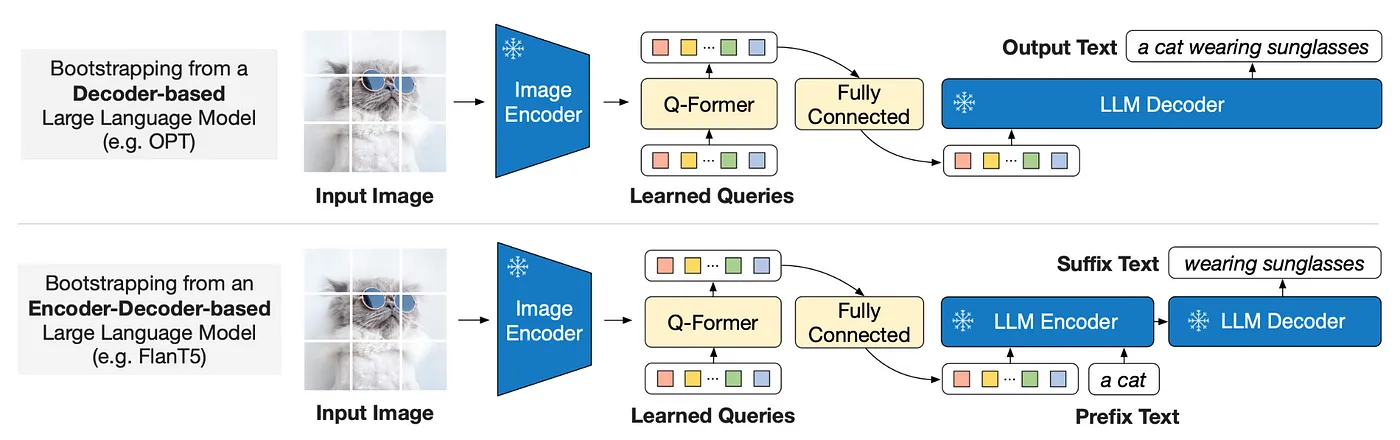
通过第一阶段的训练,Query已经浓缩了图片的精华,现在要做的,就是把Query变成LLM认识的样子。
为什么不让LLM认识Query,而让Query变成LLM认识呢?这里的原因有两:
(1)LLM模型的训练代价有点大;
(2)从 Prompt Learning 的观点来看,目前多模态的数据量不足以保证LLM训练的更好,反而可能会让其丧失泛化性。如果不能让模型适应任务,那就让任务来适应模型。
BLIP-2针对两类不同LLM设计了不同的任务:
(1) Decoder类型的LLM(如OPT):以Query做输入,文本做目标;
(2) Encoder-Decoder类型的LLM(如FlanT5):以Query和一句话的前半段做输入,以后半段做目标;
经过整个训练过程,最后形成了图片-文本的核心关联关系模型,就能够“图文交互”了。
本质来说,BLIP-2 是一种零样本视觉语言模型,可用于各种含图像和文本提示的图像到文本任务。这是一种效果好且效率高的方法,可应用于多种场景下的图像理解,特别是当训练样本稀缺时。
该模型通过在预训练模型之间添加 transformer 来弥合视觉和自然语言模态之间的隔阂。这一新的预训练范式使它能够充分享受两种模态的各自的进展的红利,也算是一种非常好的模型算法的创新。
结束
今天概要学习了国内最新开源的 VisualGLM-6b,体验了一下多模的大语言模型,虽然很多人没法体验GPT-4,但是通过本文的基本学习,对于一般LLM的文本交互、图文交互 有了直观感觉,也可以进行自己的更深入的学习。
目前也有人基于VisualGLM-6b在医疗行业进行了深度学习探索,做出了可以自动识别X片和进行诊断报告的模型开源项目XrayGLM,也算是让VisualGLM-6b产生跟过价值贡献。
也希望本文能够带给你进入多模大语言模型,给自己技术学习和工作应用一些帮助,或者按照自己业务场景,迭代自己的中文多模大模型。
##End##
想关注更多技术信息,可以关注"黑夜路人技术” 公众号,后台发送“加群”,加入GPT和AI技术交流群