注:csdn对图片有审核,审核还很奇葩,线稿都能违规,为保证完整的阅读体验建议移步至个人博客阅读
最近AI绘画实现了真人照片级绘画水准,导致AI绘画大火,公司也让我研究研究,借此机会正好了解一下深度学习在AIGC(AI Generated Content)----人工智能自动内容生成领域的应用。
AI绘画是AIGC领域的一个方向,AIGC有技术方向,其中比较火的有Txet-to-Image,Text-to-Video,Text-to-Speech技术,这三种技术都已经有了比较成熟的落地产品,但AIGC对算力的要求极高,一般的消费级显卡根本玩不起,而Stable-Diffusion模型的出现使Text-to-Image技术进入消费级显卡成为了现实,我自己测试过的最低配置是NVIDIA GeForce GTX 1660 Ti 6G + Intel® Core™ i7-9750H可以实现512x512图像分级的出图速度,即根据步数的不同3-5分钟出一张,测试的最高配置是NVIDIA GeForce RTX 3080 Ti 12G + Gen Intel® Core™ i7-12700K可以实现512x512秒级的出图速度,即根据步数的不同2-10秒出一张图。这已经是吊炸天级别的优化了。
我们讨论的就是基于Stable-Diffusion模型实现的NovelAI,一款开源软件。
我一直认为要想用好一个工具首先要知道它是怎么工作的,所以我们从AI绘画原理来入手,当然本人在接触NovelAI之前没有接触过AI,所以本文只是一些自己在学习的过程中的一些浅显的理解。
一、AI绘画原理
这里原理学习参考了:
【AI绘画】大魔导书:AI 是如何绘画的?Stable Diffusion 原理全解(一);
多模态预训练CLIP;
CompVis/稳定扩散:潜在的文本到图像扩散模型;
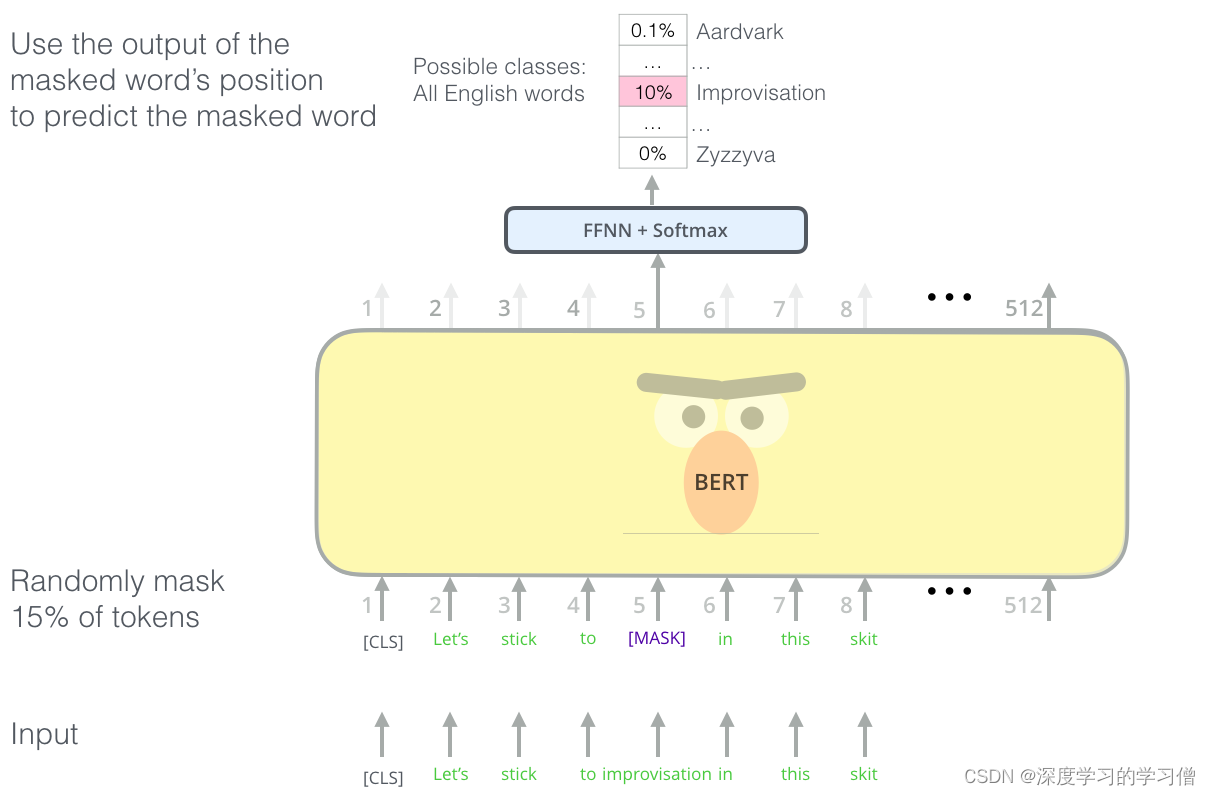
1.流程预览
NovelAI绘画的流程主要分三个步骤,TextEncoder(Clip),Diffusion(UNet+Scheduler),ImageDecoder(VAE),首先来看一下整体的流程:
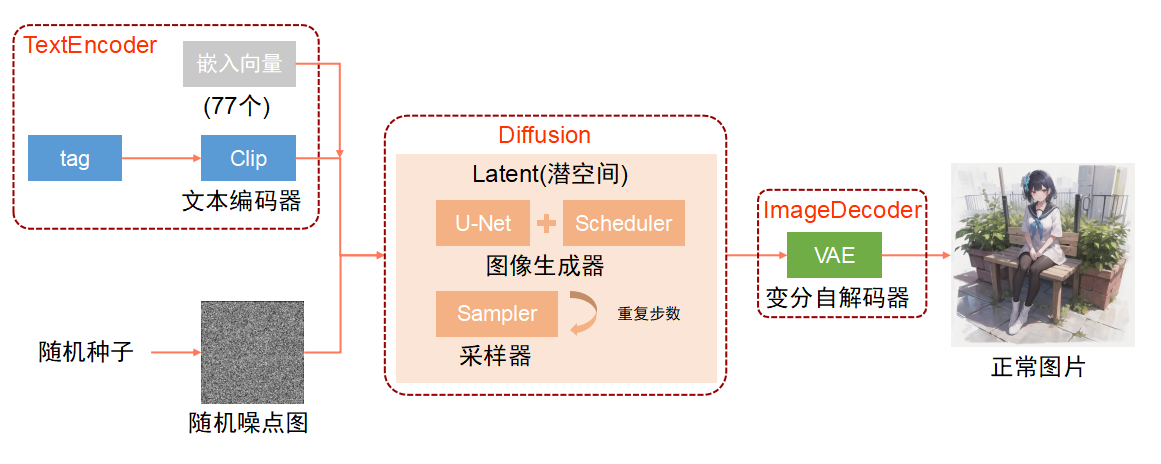
2.TextEncoder
学过编程的都知道,机器是无法直接理解自然语言的,而我们输入的描述tag是自然语言,机器自然无法直接理解,所以首先需要经过一次文本编码,将自然语言编程成机器能够理解的字节码,Stable-Diffusion模型采用了Clip中文本编码器,Clip(Constastive Language-Image Pretraining)是OpenAI开源的一个深度学习模型,由图像编码器和文本编码器组成,基于图像和文本并行的多模态模型,通过图像与文本两个分支的特征向量的相似度计算来构建训练目标,形成图像-文本对,以达到Text-to-Image的技术实现。
Clip将文本转换成的字节码在WebUI上的表现形式就是一串数字,在我使用的版本的WebUI上有一个词元分析器(Tokenizer)就是使用Clip的文本编码器,可以将文本编码成字节码并以数字的形式显示在WebUI上,也可以将数字编码成文本。这串数字是给Clip中的Text Transformer使用的,Text Transfomer会根据这串数字来解析文本对应的图像的生成条件。
通俗来说,Clip干的活就是将文本解析成机器能理解的语言,然后机器根据自己的理解搜索文本在机器的记忆中对应的画面图像,然后向Diffusion提供生成图像的条件。
这个过程中Clip有加入77个嵌入向量,Clip会固定占用两个,所以Clip所能接收的最大词元个数就是75个,这里说的是词元的数量,而不是tag的数量,比如我们在WebUI中输入3个字母dlg,Clip从中解析出来了两个词元,标签也会显示词元最大容量和当前使用数量。

我们通过词元分析器也可以分析出dlg对应的两个词元:

3.Diffusion
Stable Diffusion在Diffusion模块相对于以前的AI绘画的重大突破就是将扩散模型的核心计算从像素空间(即像素的集合)转换到了潜空间(图像的压缩数据),当模型计算一张512x512的图时,在潜空间中做核心部分的计算用的是一张更小的经过特殊编码的图,如64x64的特殊编码过的图,这可以使计算任务最重的核心计算的计算量大大的减小,并且出图速度提升100倍。
Stable Diffusion是以去噪的形式来绘制一张图片,在WebUI中的随机种子(seed)就是用来产生一张随机噪点图的,噪点图包含了大量的无规则的像素信息,Diffusion出图的过程就是将随机噪点图中按照Clip给出的出图条件给噪点图去噪的过程。
对于去噪可以阅读这边博客:图像处理——去噪 - E-Dreamer。
去噪的过程先是通过U-Net模型根据图像的生成条件从数据集中提取符合要求像素特征,一张图像的像素特征有很多的维度,如:像素的空间分布,像素颜色特征等,不同类型,不同场景的图像像素的特征也不一样,所以像素的特征提取是一项很复杂的任务,Scheduler就是用来异步处理这些任务的调度器。
然后在特征提取完成之后,通过Sampler(采样器)对特征相关的图像数据进行采样,完成一次采样之后模型就会根据采样结果来调整像素在噪点图中分布,经过多次采样调整的重复,一张符合文本描述的图片变产生了。
不同步数对图像的影响:

在WebUI中的采样方法(Sampler)调整的采样的算法,采样步数(Sampling steps)调整的就是采用重复的次数,提示词相关性(CFG Scale)调整的就采样的方向,数字越大就会越严格的按照提示词采样,越小则采样的随机性越强。
不同CFG Scale对图像的影响:

对于U-Net参考了:用U-Net做Auto-Encoder图像重建。
4.ImageDecoder
经过Diffusion的步骤,一张符合文本描述的图片实际上已经生成了,但是这张图片是在潜空间中进行计算得出的一张被特殊编码过的图片,是没办法直接进行观看的,所以需要ImageDecoder来进行图片解码,解码完成之后就得到了一张正常的图片了,然后将图片输出出来。
二、在本地部署(Win10)
首先AI绘画有很多的应用,比较有名的如:DALL-E 2、Midjourney、Stable Diffusion、Disco Diffusion、NovelAI、盗梦师、文心·一格,有的使用的自己的技术,但大部分都是使用的Stable Diffusion的开源技术,之前我还把NovelAI和Stable Diffusionr当成是一个东西了,惭愧。
我们能在自己的电脑上部署AI绘图首先要感谢Stable-Diffusion的开源。
Stable Diffusion的开源库:CompVis/stable-diffusion: A latent text-to-image diffusion model (github.com)。
1.环境部署
Stable Diffusion只是提供一个模型,提供基础的文本分析、特征提取、图片生成这些核心功能,但自身是没有可视化UI的,用起来就是各种文件加命令行。
所以很多牛人就为Stable Diffusion制作了UI界面,其中功能最强的,也是最火的就是大神AUTOMATIC1111制作的WebUI了。
WebUI原工程:AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)。
WebUI已经整合了Stable Diffusion模型,直接克隆下来配置好运行环境就可以使用了。
运行环境实际上就两东西,一个克隆代码仓库的Git,一个Python3.10以上的Python环境。
Git直接去Git官网下一个就好了,安装好之后,我们在任意文件夹内右键是可以看到Git bash here和Git GUI here两个右键菜单的。
我们选择Git Bash here,键入:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
就可以将源码下载到当前文件夹内了,下载速度很慢,毕竟WebUI本体有十几G,会科学上网的上梯子或者直接找一个国内镜像肯能更快一点。
这里推荐一个国内的镜像:Hunter0725 / Stable Diffusion Webui · 极狐GitLab (jihulab.com)。
然后去Python官网下载3.10以上的版本,WebUI作者推荐的是3.10.6,安装的时候记得勾选Add Python to PATH,否则WebUI会识别不到Python环境。
检测是否安装成功,可以在cmd中输入python -V,如果打印了Python的版本号则安装成功了。
然后我们双击WebUI根目录下的webui-user.bat就可以启动Stable Diffusion服务了。
如果此时提示还找不到Python环境或者电脑本地有Python环境,我们可以打开webui-user.bat文件,在Set PYTHON=之后填上自己安装的Python路径。
如果我们要跟换Python版本,或者电脑里装了多个Python版本,我们也可以修改webui-user.bat文件来指定使用的版本。
如果之前用其他的版本的Python跑过WebUI,现在想换另一个Python版本,操作和上面一样,并且需要将新版本的python.exe拷贝一份到venv/Scripts文件夹替换旧的exe。
这里我看一下webui-user.bat文件没一行的作用:
#设置python路径
set PYTHON=C:\Users\UserName\AppData\Local\Programs\Python\Python310\python.exe
#设置git的路径
set GIT=E:\git\bin\git.exe
#设置venv文件夹路径
set VENV_DIR=E:\stable-diffusion-webui\venv
#设置启动参数
set COMMANDLINE_ARGS=--deepdanbooru --xformers
在webui-user.bat第一次运行的时候,如果set PYTHON没有指定python路径会默认使用系统变量中的python来构建WebUI自己的虚拟环境,构建完之后,下次启动WebUI就会使用自己虚拟环境中的Python环境,位置在venv\Scripts。
下载完之后就可以双击webui-user.bat启动webui服务了,然后通过浏览器进入服务器地址就可以进入WebUI了。
但大多数时候很多库直接通过脚本基本下载不下来,这时候就只能手动下载下来了,具体可以参见第二小节。
由于墙的原因各种库总会出现链接不上库地址的情况,就算手动下载还要考虑webui使用的版本,所以建议还是使用整合包会方便很多。
我们可以在set COMMANDLINE_ARGS后添加--autolanch启用自动启动服务,在webui服务启动后会自动使用默认浏览器启动UI界面。
2.部署遇到的问题
在webui-user.bat下载依赖时经常会出现连不上git,导致下载失败,然后报Couldn’t install xxxx,没别的办法,我自己使用梯子也会出现连不上的情况,然后根据本地部署stable-diffusion-webui出现Couldn’t install gfpgan错误的解决方法 这个教程更改luanch.py中的源也一样。解决方法有两个,其一找到对应版本的依赖库,手动下载安装,其二多试几次,总有一次能成功,我就是跑了好几次成功了一次,就ok了。
当然想要更方便,解压即用的,推荐秋叶大佬的整合,秋叶大佬甚至提供了启动器,这是一个功能强大的管理器,其中为我们整合了很多优秀的模型、Lora、插件等,并且集成了UI汉化,甚至可以选择Stable Diffusion的版本等等,总之功能很强大,当然整合包和启动器都是Windows版本的,在其他的环境下使用还得自己来。
GFPGAN安装不上
gfpgan是腾讯ARC开源的一个库,也不知道为什么开不开梯子,WebUI都无法自行安装这个库,解决办法就是手动安装。
库地址:TencentARC/GFPGAN: GFPGAN aims at developing Practical Algorithms for Real-world Face Restoration. (github.com)。
使用git将库clone到stable-diffusion-webui\venv\Scripts目录下,然后进入GFPGAN目录,依次次执行
E:\stable-diffusion-webui\venv\Scripts\python.exe -m pip install basicsr facexlib
E:\stable-diffusion-webui\venv\Scripts\python.exe -m pip install -r requirements.txt
安装GFPGAN的依赖库,安装完之后执行
E:\stable-diffusion-webui\venv\Scripts\python.exe setup.py develop
安装GFPGAN,然后再启动webui时就会检测到已安装,从而跳过自动安装。
clip安装不上
原因也是自动连接时连接不上clip库,解决方法同样是手动安装,将open_clip库clone到stable-diffusion-webui\venv\Scripts目录下,然后进入open_clip目录,然后执行
E:\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install
再启动webui,如果还是提示要安装clip,说明clip没有安装上,上面的命令会构建并安装clip,但不知道为什么我没安装上,于是只能之际再手动安装一次了,可以执行
E:\stable-diffusion-webui\venv\Scripts\pip.exe install clip
然后再启动webui时就会检测到已安装,从而跳过自动安装。
缺少xxx模块
大多数情况都是WebUI在Installing requirements for Web UI时由于网络原因没装上,比较便捷的解决办法就是多跑几次,总有一次能安装上,或者也手动安装。
repositories中所用到的库下载失败
所有的库如果都下载不下载,就只能全部手动下载了,一共六个库
stablediffusion
这个是AI绘图的核心库,Stability-AI公司开源的stablediffusion,直接通过git克隆到repositories目录,克隆下来的库存在stablediffusion目录下,由于还有另一个库叫stable-diffusion,所有AUTOMATIC1111把库命名成了stable-diffusion-stability-ai,所以我们要把库的目录名改成stable-diffusion-stability-ai。
taming-transfomers
stable-diffusion
k-diffusion-sd
k-diffusion-sd库AUTOMATIC1111命名为了k-diffusion,同样也要把库目录名改过来。
CodeFormer
BLIP
启动时报ImportError:Bad git executeable
打开venv\Lib\site-packages\git\cmd.py文件在from git.compat import前一行加入一行os.environ['GIT_PYTHON_REFRESH'] = 'quiet'。
库的hash值不确定
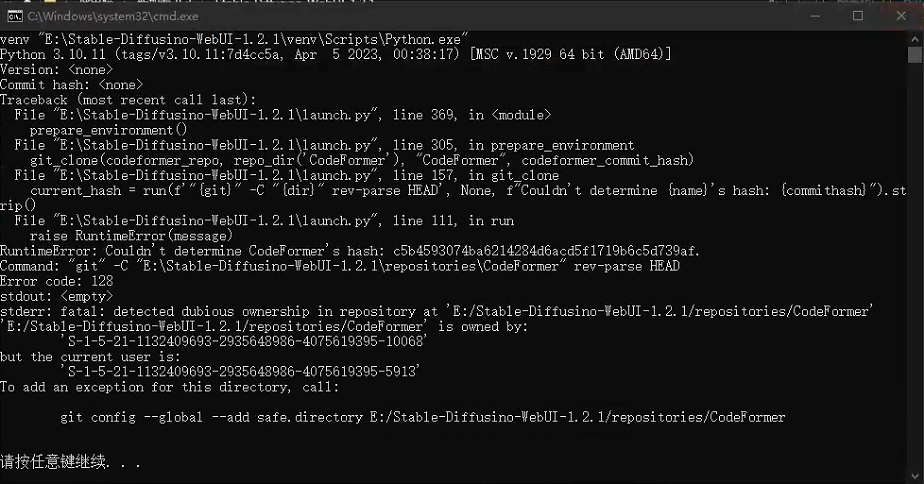
这种情况我只在迁移软件的过程中遇到,解决办法就是使用git,按照提示的命令把所有不确定hash值得库都执行一边就可以了,需要注意的是需要在电脑中安装git执行命令才生效,我没安装git的直接使用秋叶整合包里的git文件执行指令没效果。
3.注意事项
在开了梯子的情况下,UI界面有概率出现与服务器通信中断的问题。
三、WebUI文件夹功能
这里只说明一些我们会使用的文件夹的作用,不使用的就略过了。
-
embeddings:存放美术风格文件的目录,美术风格文件一般以
.pt结尾,大小在几十K左右; -
extensions:存放扩展插件的目录,我们下载的WebUI的插件就放在这个目录里,WebUI启动时会自动读取插件,插件目录都是git库,可以直接通过git更新;
-
extensions-builtin:存放WebUI内置的扩展;
-
models/hypernetworks:存放风格化文件的目录,风格化文件是配合Prompt使用的,以使AI会出对应风格的图片,风格化文件也以
.pt结尾,大小在几百MB左右; -
models/Lora:存放Lora的文件的目录,Lora文件是用来调整模型的,可以重映射模型文件的Prompt映射,使AI在相应的提示词下按照Lora的样式绘制,Lora文件一般以
.safetensors结尾,大小在几百MB左右; -
models/Stable-diffusion:存放模型的文件的目录,AI绘画时的采样基本从这个文件里采,影响图片的整体样式与画风,一般以
.ckpt或.safetensors结尾,大小在几个G左右; -
models/VAE:存放VAE文件的目录,VAE文件会影响图片整体的色调,如在刚开始玩WebUI时画出的图都比较灰,就是因为WebUI默认没有为我们设置VAE导致的,VAE文件一般以
.ckpt或.vae.pt结尾,大小在几百MB或几个G不等; -
outputs/extras-images:AI放大的原图的默认保存路径;
-
outputs/img2img-grids:批量图生图时的缩略图原图的默认保存路径;
-
outputs/img2img-images:图生图的原图的默认保存路径;
-
outputs/txt2img-grids:批量文生图时的缩略图原图的默认保存路径;
-
outputs/txt2img-images:文生图的原图的默认保存路径;
这些路径我们是可以在WebUI的设置界面修改成自定义路径的。
-
scripts:存放第三方脚本的目录;
-
venv:这个文件夹是WebUI首次运行时配置运行环境自己创建的,出现运行环境的问题时,可以删掉它让WebUI重新生成。
四、WebUI界面说明
这里以无第三方插件的原版的WebUI界面为例,使用了整合包或安装了第三方插件的界面会有所不同。
本节参考了:
AI绘画指南 stable diffusion webui (SD webui)如何设置与使用 — 秋风于渭水;
使用Automatic1111的WebUI的菜鸟指南:稳定扩散 ;
NovelAI模型各参数解析以及对应关系
1.文生图(txt2img)
-
Prompt:正向提示词;
-
Negative prompt:反向提示词;
-
在Generate(生成)下有一排按钮:

箭头(第一个按钮):从提示词中提取通用的提示词,一般用于使用别人的提示词时过滤掉一些别人个性化的提示词;
垃圾篓(第二个按钮):快速清除提示词;
图画(第三个按钮):打开Textual Inversion、Hypernetworks、Checkpoints和Lora的管理界面,点击文件可以往提示词中加入对应的风格化应用;
文件(第四个按钮):这个按钮的功能是配合第五个按钮一起使用的,可以选择下方Styles下拉列表中已经保存起来的提示词模板应用到提示词中;
存储(第五个按钮):存储当前Prompt和Nagetive prompt的提示词作为提示词模板,存储好的提示词模板命好名后可以在Styles下来列表中看到,提示词模板存储在WebUI根目录的
styles.csv文件中,目前WebUI没有提供在UI中删除提示词模板的功能,想要删除不需要的提示词模板,我们需要通过修改styles.csv文件。 -
Sampling method(采样方法):生成图片时的采样算法;
-
Sampling steps(采样步数):生成图片时的采样重复次数;
-
Restore faces(面部修复):主要用于生成真人图片时对人脸进行算法修复,让人脸更接近真实的人脸,当画二次元图人脸崩坏时也可以使用这个选项来修复;
在Settings(设置)/Face restoration(人脸修复)中可以选择人脸修复的算法,目前WebUI只整合了CodeFormer和GFPGAN两种算法,默认是没有启用任何算法的,需要我们自己手动去启用,Code Former weight parameter参数可以调整算法的权重,注意:0是最大权重效果,1是最小权重效果,和我们常见权重是反过来的。
-
Tiling:是一种优化技术,对于性能比较差的机器可以勾选上来降低显存的占用,提高出图速度,对于性能足够的机器就不用勾选了,勾选了反而会起到反作用;
-
Hires.fix(高清分辨率修复):用于提高分辨率的优化,最大可以将分辨率提升4倍,512x512可以直接提升到4K;
由于Hires.fix是在AI画完一张图之后再进行优化的,要对细节进行补充,所以会对图片进行一定维度的重绘,所以对原有的图会有一些改动,不过这对文生图来说没有任何影响。Hires.fix也有一些自己参数:
Upscaler(放大算法):优化采用的放大算法,其中提供了很多内置的算法,同时我们也可以在Settings(设置)/Upscaling(放大)中添加没有预制出来的ESRGAN算法,里面有一个算法R-ESRGAN 4x+ Anime6B据说对二次元图的放大效果比较好;
Hires setps(高清修复的步数):和采样步数的效果一样;
Denoising strength(重绘幅度):重绘幅度就是Hires.fix在重绘细节的时候,AI的自由发挥空间,值越大AI就越放飞自我,值越小,AI就越按照原图重绘。
Resize width to(将宽度调整至)/Resize height to(将高度调整至):直接将图片放大至指定分辨率,和放大倍率是冲突的。
-
Width(图片宽度)/Height(图片高度):设定图片的分辨率;
-
Batch count(生成批次):批处理次数,设定同时处理多少批图片生成;
-
Batch size(每批数量):每次批处理同时生成的图片数量,最大值为8,需要根据自己电脑的显存大小来调节,如我的12G显存就没办法同时出8张1024x1024分辨率的图,只能同时出4张;
-
Seed(随机种子):用来设置用于AI去噪的噪点图,一个随机数唯一对应一张噪点图,默认值是-1,表示使用随机数,也可以设置一个随机数,来规定AI画同样的图。
Seed也有两个自己的参数,勾选Seed后面的Extra复选框可以编辑。
Variation seed(差异随机种子):组要用于在确定好一个自己比较想要的图片结构之后,设置好随机种子,然后通过设置差异随机种子,让AI在这张图的基础上每次画出有一点点区别的图;
Variation streenght(差异强度):控制AI在一张图的基础上出图的差异变化的强弱。
Resize seed from width/Resize seed from hright:控制AI绘图时在当前分辨率往指定分辨率的图靠近,实际使用过程感觉没什么卵用。
差异随机种子的另一种用法是,在出了一张构图很好的图时,通过图生图锁定随机种子和差异随机种子,然后调整差异强度,使差异随机种子出现一些细微的变化,来细微的调整出图效果,可以随机生成构图类似而又不同的图片。
-
CFG Scale(提示词相关性):控制AI是否严格按照提示词来绘图,越小AI绘画越随意,越大AI就越严格的按照提示词出图;
-
Script(脚本):用来启动第三方脚本,WebUI内置了三个脚本。
X/Y/Z plot:可以用来批量处理同一提示词在不同维度之间的效果,如不同的采样方法,不同的采样步数或者不同的提示词相关性等,用来测试不同维度的参数变化对出图的影响,以寻找最佳的图片质量的参数配置。
如不同采样算法在不同采样步数的情况下对图片的影响:

具体的可以参考这篇博文:
Stable Diffusion WebUI 小指南 - X/Y/Z Plot。
Prompt matrix(提词矩阵):用来分割不同关键词对图片的影响,操作方法就是通过|来分割关键词,如:
(masterpiece:1.3), (the best quality:1.2), (super fine illustrations:1.2), (Masterpiece)|, 1girl,black hair|, Sailor suit,Pleated shirt|,huge breasts,white pantyhose
Prompt matrix就会按照分割的关键次一次组合来绘制不同组合的出图效果:

这里参考了这篇博客:
AI绘画教程(3)基础篇-SDWEBUI的基础功能,你都会用了吗?。
Prompts from file or textbox:用于批量出图的工具,我们可以在List of prompt inputs(提示词输入列表)中输入提示词,也可以从文本中输入提示词,脚本会自动将文本的提示词填入提示词输入列表,然后勾选Iterate seed every line(每行使用一个随机种子)或Use same random seed for all lines(每行使用相同的随机种子),来达成每一行作为一份提示词输入来生成对应的图片。
2.图生图(img2img)
图生图界面上半部分、下半部分和文生图基本一样,只有中间部分不一样,上半部分多了两个按钮。
-
Interrogate CLIP(CLIP反推提示词):使用CLIP模型从图片中反推图片用到的正向提示词;
-
Interrogate DeepBooru(DeepBooru反推提示词):使用DeepBooru模型从图片中反推图片用到的正向提示词;
-
img2imge(图生图):全局图生图,AI会根据重绘幅度和原图进行创作;
-
Sketch(绘图):就是最简单的局部重绘功能,可以通过画面图绘区域,让AI只重绘所图的区域;
-
Inpaint(局部重绘):功能稍微强大一点的局部重绘,可以对蒙版进行操作,蒙版就是我们用画笔图黑的部分;
-
Inpaint sketch(手涂蒙版):手绘蒙版又是一个更强大的局部重绘,可以拾取画面中的像素颜色,以让AI识别要重绘的像素分布,能更精准的进行局部重绘;
-
Inpaint upload(上传蒙版重绘):这个功能主要是解决WebUI在绘制蒙版是的不精确,对想要精确选区的重绘区域使用WebUI的画笔很难精确的图绘,上传蒙版重绘则是通过上传一张与原图大小一致的黑白的蒙版图片来匹配原图,从而对原图进行重绘,这里要注意的是这里的颜色和Sketch、Inpaint的颜色刚好相反,Sketch是黑色区域为蒙版区域,这里这是白色区域为蒙版区域,如:我这里想重绘一下女孩身后的栏杆,我们就可以用PS将栏杆精确的选区出来,然后制作蒙版图,传到WebUI上来进行重绘:

-
Batch(批量重绘):指定一个输入文件夹和一个输出文件夹,就可以进行图片的批量重绘,如果指定了蒙版文件夹,还可以批量的使用蒙版图精确的进行局部重绘。
局部重绘还有一些自有的参数:
Mask blur(蒙版模糊):值越大重绘出来的区域越清晰,值越小重绘出来的区域越模糊;
Mask mode(蒙版模式):可以选择是重绘蒙版区域还是非蒙版区域;
Masked content(蒙版蒙住的内容):可以选择蒙版要蒙什么东西,可以是原图也可以是噪点等;
Inpaint area(重绘区域):可以选择要重绘的区域,感觉和蒙版模式的功能是一样的;
Only masked padding,pixels(仅蒙版边缘的预留像素):设定蒙版边缘预留多少像素不进行重绘,实际使用中没感觉出有什么作用。
-
Dinoising strength(重绘幅度):控制整个图生图过程中AI重绘过程的自由发挥程度,值越大AI重绘越随意,值越小AI重绘越接近原图。
-
Script(脚本):图生图除了拥有文生图的脚本外,还拥有一些专用的脚本。
Lookback(回送):可以将这一次的生成图作为图生图的输入进行下一次绘制,这个功能对于线稿上色简直是神助攻。
启用后会多出几个设置选项:
Loops:控制回送的次数;
Final denoising strength:最终重绘强度,是叠加在图生图的重绘强度之上的,第一次回送使用的实际重绘强度=[重绘强度]×[最终重绘强度],之后每一次回送时使用的[实际重绘强度]=[上一次实际重绘强度]×[最终重绘强度];
Denoising strength curve:可以选择脚本重绘强度的变化曲线,脚本为我们内置了三个曲线;
Append interrogated prompt at each iteration:为每一次回送自动反推图片提示词并应用;
Outpainting mk2(向外绘制第二版):可以将图片进行一定像素方位内的扩展,实测,发现脚本与双语对照插件存在冲突,启用双语对照插件后,扩展绘制的效果很差,关闭之后,效果就会变得很好;
SD upscale(SD 放大):这就是一个依赖于图生图的分块放大算法,可以使用更少的显存达到4K图的放大效果,实测放大到最大的4K,只需要5G+显存,放大效果回收重绘强度影响和提示词影响;
controlnet m2m(ConteolNet视频转绘):视频生成的脚本,转的视频效果比较渣,就不过多累述了,可以参见这个视频:【AI绘画进阶教程】制作跳舞小姐姐 m2m和mov2mov哪家强?。
3.附加功能(Extras)
附加功能界面主要是用来做图片放大用的。
-
Scale by(等比放大):按原图长宽各乘以相同比例来放大图片;
-
Scale to(按分辨率放大):可以将原图放大成任何比例,如正方形图可以被放大成长方形图,勾选Crop to fit,AI会自动为我们裁剪,不勾选则不会按照指定的分辨率放大,会默认用回等比放大;
-
Upscaler 1(升频器1)/Upscaler 2(升频器2):AI做图片放大时会处理两次,两次可以分别采用不同的放大算法,不同的算法放大效果不一样,所以WebUI做两次放大,以便组合不同放大效果达到更好的放大效果。
-
Upscaler 2 Visibility(升频器2可见度):用于设置第二次放大时使用的算法在放大过程中的权重;
-
GFPGAN visibility(GFPGAN模型可见度)/CodeFormer visibility(CodeFormer模型可见度)/CodeFormer weight(CodeFormer权重):这三个选项都是用来调整图片放大时对图片的修复作用的,GFPGAN和CodeFormer模型在前面文生图的Hire.fix中也有用到,主要作用就是用来做图片修复的,调整可见度就可以调整两个模型混合使用的程度,CodeFormer还可以更精细的调整权重,0表示最大权重,1表示最小权重。在我自己的测试中,两个模型对二次原图片的修复效果基本一致,在相对拟真的图片中存在差异,我们可以看一下两个模型的修复效果:
GFPGAN visibility=1,CodeFormer visibility=0,CodeFormer weight=0:

可以看到GFPGAN对纹理的修复还是可以的,但是对皮肤的纹理修复有点过度磨皮的刚觉了。
GFPGAN visibility=0,CodeFormer visibility=1,CodeFormer weight=0:

CodeFormer则是对皮肤纹理的修复更真实自然,但对其他的物体的纹理修复就不如GFPGAN,并且对五官有过度修复。
GFPGAN visibility=0.5,CodeFormer visibility=0.5,CodeFormer weight=0.5:

将二者结合后的效果,要好很多。
-
Batch Process(批量处理)/Batch from Directory(从目录进行批量处理):两个都是对图片放大做批量处理的。
本节参考了帖子:
GFPGAN and CodeFormer - seperately and together. : StableDiffusion。
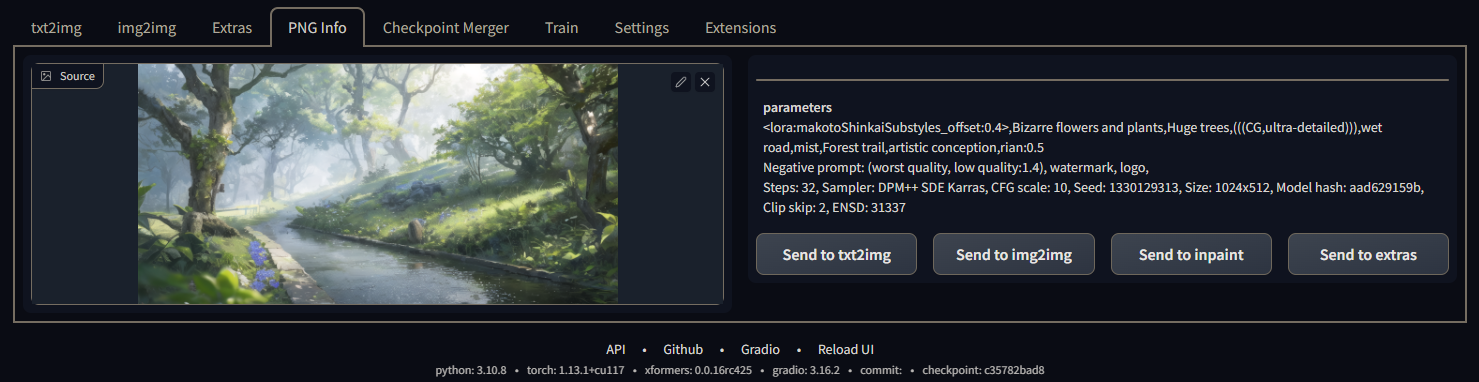
4.PNG图片信息(PNG Info)
PNG图片信息就是一个更强大的CLIP反推提示词,它可以将没有经过处理的AI生成的原图反推出生成这张图所有的所有参数,包括正反向提示词、采样步数、采样方法、提示词相关性、随机种子、尺寸、所用模型的hash值、Clip跳过的次数还有一个不知道有什么用的ENSD。
5.模型合并(Checkpoint Merger)
模型合并界面主要使用来合并模型的,具体参数后面在模型合并的章节一起讲。
6.训练(Train)
训练界面是专门用来做模型训练用的,具体参数也在后面模型训练的章节一起讲了。
7.设置(Settings)
设置界面的参数就太多了,建议弄一个汉化,或者用整合了汉化的整合包,大部分参数在汉化之后看一下名字就知道是作用了。
这里推荐安装这个汉化库:dtlnor/stable-diffusion-webui-localization-zh_CN: Simplified Chinese translation extension for AUTOMATIC1111’s stable diffusion webui 。
然后可以配合这个双译插件一起使用:sd-webui-bilingual-localization/README_ZH.md at main · journey-ad/sd-webui-bilingual-localization。
两个插件都安装之后的界面是这样的:
8.扩展(Extensions)
用来管理第三方插件的界面,所有安装的扩展,包括WebUI内置的都会在Installed(已安装)栏中显示,并且可以直接管理插件的更新。更新插件的时候需要确保自己的网络能连接得上github库,其实也没什么卵用,就算梯子没毛病,也经常连不上git库。
Available(可用):这是直接连接https://raw.githubusercontent.com/wiki/AUTOMATIC1111/stable-diffusion-webui/Extensions-index.md扩展列表,我们可以点击(加载自)来刷新扩展列表,然后从这里来下载列表里的第三方插件,实际测试基本上装不了。
Install from URL(从网址安装):用来安装扩展列表里没有的第三方库,就是用来给不会用git的人使用的。实际上也基本连不上git库,评价是不如直接用git来得舒服。
五、提示词原理
提示词不同的绘画程序会有所在区别,这里以webui为主。
本节参考了这几篇博文:
元素同典:确实不完全科学的魔导书
Tags基本编写逻辑及三段术式入门与解析v3
完整tags书写思路,从人工智能理论来了解如何绘画
1.提示词的顺序
对于提示词对画面的影响,我们首先想到,也是最直观看到的自然就是提示词的顺序,AI对越靠前的提示词就越重视,我们可以做个实验来看看效果:

图1作为参考图,
图2:深林(Forest)被放置在首位,AI绘制的画面开始着重数目,草丛的特征被稀释,同时落叶增加了;
图3:林间小道(Forest trail)被放置在首位,AI绘制的画面小路的细节被增加;
图4:落叶(fallen leaves)被放置在首位,AI绘制的画面中落叶的数量被大量增加;
图5:草丛(Grass)被放置在首位,AI绘制的画面草丛的特征被方法,树下均被绘制了茂密的草丛;
图6:秋天(Autumn)被放置在首位,AI绘制的画面开始大片的出现秋天的特征,树叶变得更黄了,落叶变得更多了,连女孩也开始套上了围巾,换上了秋季得衣服。
2.提示词的权重
在stable diffusion webui中提示词可以被增加权重,以提高AI对某些提示词的重视程度,sd webui支持两种为提示词加权重的方式,其一使用英文小括号(),括号可以无限叠加,如:((Autumn))其二使用英文小括号加权重,括号也可以叠加,如:(Grass,(Autumn:1.3)),一个括号代表为提示词增加1.1倍权重,叠加一个括号表示增加1.1*1.1倍的权重,依次类推,而指定了权重的方式则是直接为提示词增加指定的权重,如在(Grass,(Autumn:1.3))中,Grass被增加了1.1倍的权重,Autumn则被增加了1.1*1.1*1.3被的权重。使用指定式权重时必须使用一个括号括起来。
我们测试一下提示词权重

图2给秋天(Autumn)增加了1.1*1.1=1.21倍的权重,秋天的氛围变浓了;
图3给秋天(Autumn)增加了1.1*1.3=1.43倍的权重,秋天的特征变得更明显,连草地都变黄了。
需要注意的是在给提示词增加权重时也不是加高越好的,加得太高了反而会适得其反,而是要根据整个提示词组,相对权重来增加,比如图2的提示词组中秋天这个提示词加了两个括号后,相对权重已经是最高的了,就没必要再给秋天这个提示词加七八个括号上去了。
权重过高反而会使绘制的图崩坏:

3.提示词的形式
我们在使用提示词描述一个画面的时候,有多种形式,可以用单个的词语组合、可以用一段完整的句子、也可以用单词与短句的结合,不同的提示词形式又有什么影响呢?我们还是通过实验来看看。
我们来画一个“一个穿着白色运动衫和粉红色运动鞋的黄色短发的站在街上的女孩”,使用文生图的Prompts from file or textbox脚本分别生成三种类型的提示词的图。
单词组:
1girl,short yellow hair,white sweatshirt,pink sneakers,standing,in street,full body,looking at viewer,
完整长句:
A girl with short yellow hair in a white sweatshirt and pink sneakers standing in the street,full body,looking at viewer,
短语与单词组合:
short yellow hair,a girl in a white sweatshirt and pink sneakers,standing,in street,full body,looking at viewer,
出图结果:
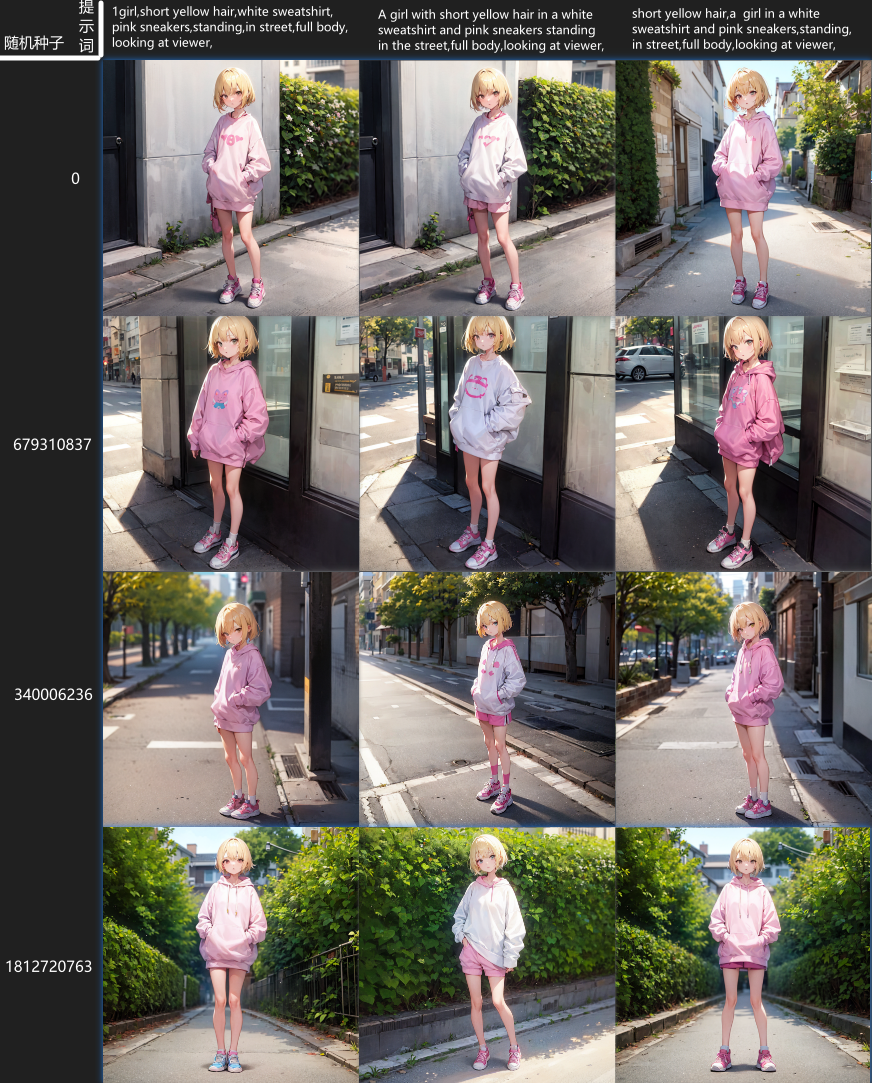
第一列:使用的是单词组提示词,画的四张测试图里面头发颜色都画对了,衣服颜色全部被子鞋子颜色污染没有一张是正确的,鞋子颜色也只有三张是正确的;
第二列:使用的是完整的长句提示词,画的四张测试图里面头发、衣服、鞋子颜色都正确;
第三列:使用的短句和单词组合的提示词,画的四张测试图里面头发颜色都正确,衣服杨色全部被鞋子颜色污染,鞋子颜色都正确。
现在不同类型的提示词的效果就出来了,很明显使用完整长句的提示词能很好的绑定物体的特征,短句与单词组合次之,单词组提示词绑定的最差。
不过大多数情况一个画面是很难使用一句完整的长句描述出来的,所以三种类型的提示词多数需要根据实际情况来选择使用。
4.分步描绘
stable diffusion支持多种分步绘制的语法,如:[a | b]、a | b、[a : b : 0.4]、[a : 10]、[a :: 10],a:0.5 AND b:0.6。
对主体的分步描绘
语法[a:b:0.4],假设采样步数为20,那么这个语法的意思就是前8步绘制特征a,后12步绘制特征b,分步描绘可以将多个提示词融合到一个主体上;
语法[a | b]和a | b,表示第一步画特征a,第二步画特征b,第三步画特征a,第四步画特征b,依次类推;
还是先来看一下实验:

不使用分步的(panda:0.4),(goblin:0.6)已经不知道在画什么了,使用可控分步的[panda:goblin:0.4]和均衡分步的[panda | goblin]的效果和我们先画大熊猫为整体画面定下结构然后往大熊猫身上添加哥布林的特征的预期比较接近,panda:0.4 AND goblin:0.6语法融合的感觉更加深入,有一种大熊猫和哥布林的杂交物种的感觉。
对修饰词的分布描绘
用于修饰某一主体的修饰词的混合和主体本身的混合又有一点细微的差别,我们渐变色头发为例,分步描绘渐变发色有两种方式,一种是分步描绘颜色,不分步头发,另一种是颜色和头发都分步描绘:

可以看到在不使用分步绘制1girl,red and blue hair,和1girl,red hair, blue hair,的情况下ai也能画出相应的颜色混合的头发,但是发色是直接硬拼接起来的,无论是只分步颜色还是颜色和头发都分步,效果是一样的;
在使用1girl,[red | blue] hair,和1girl,[red hair | blue hair],均衡分步绘制语法绘制的头发更接近正常的渐变色的染发 ;
在使用没有中括号的1girl,red | blue hair,和1girl,red hair | blue hair,均衡分步绘制语法绘制的头发 也有那么一点硬接的感觉,但是混合效果还可以,比不使用分步绘制的情况要好;
对于修饰词的分步描绘使用可控步数的语法1girl,[red:blue:0.5] hair,和1girl,[red hair:blue hair:0.5],则完全不起作用了;
使用AND语法的分步描绘1girl,red AND blue hair,和1girl,red hair AND blue hair,在只有分步颜色的情况下,AI直接做了红色和蓝色的混合,用混合后的颜色来作为头发的颜色了,在颜色和头发都分步描绘的情况下, 效果和使用中括号的均衡分步描绘的效果差不多了。
在我自己的使用过程中,分步描绘的混合效果很大程度上取决于大模型,比如测试发色混合时同一套提示词使用abyssorangemixAOM3模型混合的效果就很差,使用revAnimated模型混合的效果就很好。
指定开始步数和结束步数的分布描绘
语法[a : 10],表示从第10步开始画特征a;
语法[a :: 10],表示从第10步开始结束画特征a;
二者还可以结合[[a :: 16] : 4],表示从第4步开始,到第16步结束画特征a;
三者在出图效果上差别不大:

5.占位符
占位符指的是一些模型无法理解的符号或词语,这些符号或词语在模型中没有明确的特征与它们相关联,所以ai画不出这些符号或词语的特征,但是它们又会占用词元数量,这样的符号或词语对ai来说就是占位符,常见的占位符符号有:\ * + _等,词语可以是任何模型不理解的自造词。
占位词的一大作用就是拉开一个词元与另一个词元之间的距离,最常见的用法就是通过拉开词元距离来减少颜色污染,如:画一个一个穿着白色运动衫和粉红色运动鞋的黄色短发的站在街上的女孩,在使用的单词组的情况下颜色污染很严重,我们就可以使用占位词来拉开不用颜色词元之间的距离来避免颜色污染。

可以看到在使用占位符将white sweatshirt和pink sneakers的词元距离拉开之后,颜色污染被有效的避免了。
6.Emoji表情
Emoji表情也在stable diffusion webui的支持当中,并且能很精准的识别,比如在想让ai画出一些不太好描述的表情的时候,就可以使用emoji表情来控制。
(((😥))),1girl,Head Close-up,complete face,
(((😤))),1girl,Head Close-up,complete face,
(((🥺))),1girl,Head Close-up,complete face,
😥:失望但又如释重负;
😤:傲慢;
🥺:恳求;
出图的结果从左往右一次是😥、😤、🥺:

当然除了描述表情的emoji表情,一些描述节日的也很好用:
((🎃)),1girl,full body,standing,
((🎄)),1girl,full body,standing,
((🎁)),1girl,full body,standing,

7.提示词分类
提示词也是分很多种类的,比如有专门描述画面质量的、有专门描述画面氛围的、有专门描述光照的、有专门描述渲染的、有专门描述镜头的、绘制画面主体的等等。
描述词数量巨大,这里就不分类列出来了,提供几个我常用提示词收录网址:
Danbooru 标签超市 (novelai.dev)
魔咒百科词典 (aitag.top)
从零开始的魔导书 元素法典 - AI绘图指南wiki (aiguidebook.top)
NovelAI tag在线生成器 (wolfchen.top)
Danbooru: Anime Image Board (donmai.us)
六、模型文件
Stable-diffusion支持五种模型文件,Checkpoint、Embedding、Hypernetwork、Lora和VAE。
1.Checkpoint
Checkpoint是深度学习领域模型训练中保存模型参数的一种术语,一个模型的训练是循序渐进的,训练到一定的阶段就可以使用Checkpoint来保存当前的训练结果,这个训练结果也就是我们常说的模型。
Checkpoint模型就是我们在webui的Stable Diffusion checkpoint中选择的模型。Checkpoint模型我把它理解为AI的记忆,它控制着AI能画出什么,画出的东西长什么样。
Checkpoint模型一般分为两种,一种是Stability.AI官方为Stable Diffusion训练的通用超大型模型,目前已经更新到v2.1版本,这种模型都非常大,基本是4-5G往上。
官方提供的基础通用模型可以到HuggingFace下载:
1.5版本:runwayml (Runway) (huggingface.co);
2.1版本:stabilityai (Stability AI) (huggingface.co)。
另一种则是在通用模型的基础上训练的针对某一方面的定制化模型,也是我们最常使用的、在各大模型网站下载的模型,都属于这个种类。Checkpoint在存储训练参数的同时也提供参数的载入,进行再训练,个人训练的Checkpoint模型都是基于官方提供的Checkpoint模型再训练得出的。
定制化模型可以到C站下载:Civitai。
大模型的使用
大模型的使用就比较简单了,直接点击左上角的Stable Diffusion Model就可以切换大模型,也可以通过点击右上角的show/hide extra networks按钮通过点击预览图切换。
2.Lora
Lora模型是一种生成对抗网络模型,主要用对Checkpoint模型进行定向的微调。个人理解是用来做Checkpoint模型提示词重映射的。比如,在一个Checkpoint模型中,提示词“猫”对应形象是“加菲猫”,那么Lora就可以将“猫”这个提示词重映射,使其对应的形象变成HelloKitty,那么在加持Lora模型的Checkpoint模型上输入“猫”这个提示词后AI将不再生成加菲猫,而全部生成HelloKitty。
Lora的使用目前有两种方式,一种是使用直接通过webui的Lora管理界面点击对应的Lora来应用,点击后webui会在正向提示词中添加一个形如:<lora:[lora名称]:[lora权重]>的标签,权重最大为1,最小为0,多个lora可以混合使用。
另一种是通过sd-webui-additional-networks插件来使用,通过这个插件来使用lora就不会像正向提示词中添加标签了,并且插件支持xyz plot脚本,可以很好的对比不同lora文件对画面的影响,尤其是在自己训练lora时对比不同epoches下的lora效果时很好用,但是使用这个插件需要将lora从webui的默认位置移动到插件位置中。
Lora的使用
Lora的使用可以通过点击右上角的show/hide extra networks按钮在Lora标签中点击相应的预览图来使用,添加成功后webui会向正向提示词中添加一个类似 <lora:lihui-repro-32-1e-4-noflip-re2-nonoise:1>的提示词,这个就表示使用了对应的lora,默认权重为1,Lora的使用权重最小为0最大为1,一般不使用两个极值,权重为0则Lora完全不会生效,权重为1则严重影响到出图效果,甚至可能会直接图lora训练时的原图。在C站上lora作者一般都会给出lora的最佳使用权重,最好根据作者的推荐权重来使用。
有的lora会有触发词,有的lora没有触发词,触发词一般时lora作者的自创词,使用触发词能够有效的触发lora效果,触发词的具体使用和lora的不同有所差异,有的lora有触发词,但不使用也能触发效果,有的lora则必须使用触发词才能触发效果。
多个不同的lora可以混合使用,lora和Embedding、Hypernetworks之间也可以混合使用
Lora的分层控制
后续更新计划
3.Embedding
Embedding(嵌入层)也是深度学习中的一种模型,主要用来做编码映射,更深入的可以看这篇博文:一文读懂Embedding的概念,以及它和深度学习的关系。
在Stable diffuion中,Embedding模型提供了一种向已有模型嵌入新内容的方式,Embedding模型可以使用很少的图片数据,来生成一个具有新的风格或者人物形象的模型,并且可以使用特定的提示词来映射这些特征。如,某一天有一个新猫猫形象叫git cat被创造出来,而原来的旧模型可能只有加菲猫或者HelloKitty,没有git cat这只猫猫的数据,那么我们想通过原有的模型让AI画出git cat那是做不到的,于是我们可以git cat的数据训练一个Embedding模型,在使用的时候将Embedding模型嵌入到原模型上,这样我们使用原模型就可以让AI画出git cat这只猫了。
Embedding模型有两种称呼,国内大多就叫Embedding模型,也有叫TextualInversion模型,webui也是用TextualInversion来称呼。
Embedding技术官网:图像胜过一个词:使用文本反转个性化文本到图像生成 。
现在embedding模型已经很少使用了,目前最常用embeding模型就是用于配合三视图lora使用的CharTurner V2 、用于反向提示词集合的EasyNegative和用于美化脸部的PureErosFace_v1。
4.Hypernetworks
Hypernetworks又叫超网络,Hypernetworks模型是一种风格化文件,可以为AI生成的图像应用指定画风。如,同样是画一个HelloKitty,在没有应用Hypernetworks模型的情况,画出来的HelloKitty就是一只正常的HelloKitty,如果给AI应用一个金享泰画风的Hypernetworks模型,那么AI画出来的HelloKitty就变成一只油腻的HelloKitty。
5.VAE
VAE的作用就是在第一章中讲到的将图片从潜空间的压缩数据解码变成一张正常的图片,不同的VAE会影响AI出图的色调,如果当我们不使用VAE时,AI生成的图片均会有一层灰蒙蒙的感觉,使用VAE会使图片的饱和度有所区别。
目前网络上公开的VAE熟练还是比较少的,主要的来源有三个:
Stability.AI官方提供的:stabilityai/sd-vae-ft-mse-original ;
NovelAI模型泄露的:这个就没有网址了,可以使用秋叶的启动器下载;
Reimu Hakurei提供的:wd1-4-anime-release。
6.AestheticGradients
AestheticGradients(美学渐变)是以插件的形式存在一种模型修改技术,AestheticGradients模型需要依赖AestheticGradients插件才能使用,效果和Hypernetworks差不多,但是基于AestheticGradients插件提供了更多的可调节参数,而Hypernetworks的参数是已经定死了不可更改的。
AestheticGradients模型以.pt最为后缀,一般只有几K的大小。
stable-diffusion-webui-aesthetic-gradients插件库地址:AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients: Aesthetic gradients extension for web ui ;
AestheticGradients库:stable-diffusion-aesthetic-gradients/aivazovsky.pt at main · vicgalle/stable-diffusion-aesthetic-gradients。
在AestheticGradients库的aesthetic_embeddings文件夹下,作者提供了一些作者预制的AestheticGradients模型。
七、AI绘图的用法拓展
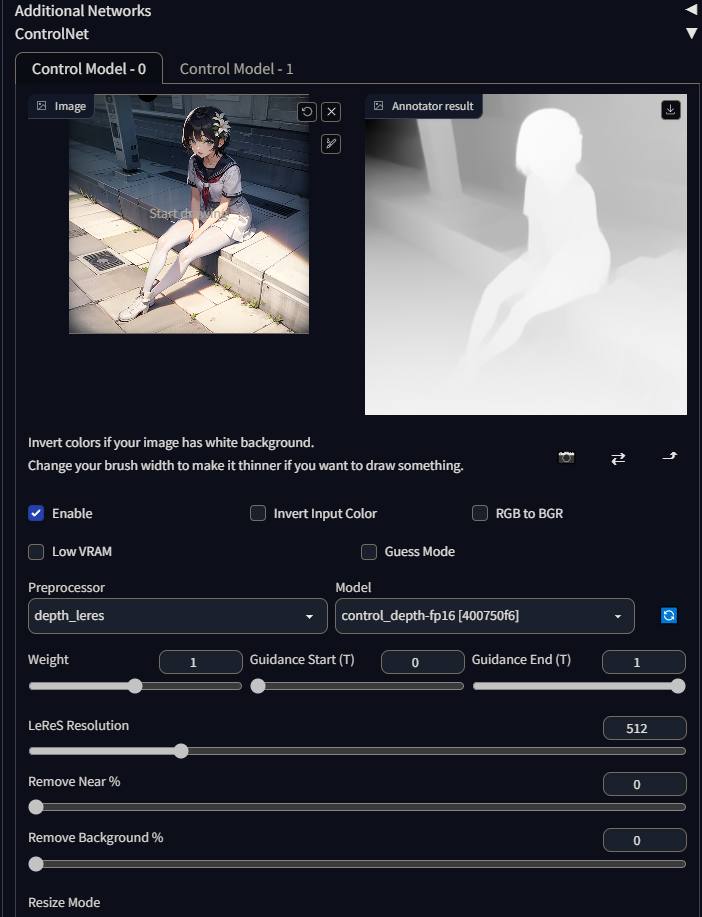
1.ControlNet
ControlNet可以提供AI一个参考图,ControlNet会对参考图先做一次预处理,如识别参考图中人物的骨骼特征点或者物体的边缘线,然后再将检测出来的结果图给AI参考,让AI按照参考的姿势或边缘线来绘制图像。这有点类似图生图,只是二者底层原理不一样,图生图主要是通过噪点采样来学习图片的像素分布,而ControlNet则是通过机器视觉来进行智能识别再给AI学习。
ControlNet的原理主要是使用OpenCV的一些识别算法,如姿势识别、手势识别、边缘检测、深度检测等,先对参考图做一层机器视觉方面的预处理,生成身体骨骼特征点、手势骨骼特征点、描边图、深度图等中间图,然后再让AI参考这些中间图进行创作。
想要更细致的了解ControlNet可以看这篇文章:精确控制 AI 图像生成的破冰方案,ControlNet 和 T2I-Adapter 。
ControlNet的库地址:Mikubill/sd-webui-controlnet: WebUI extension for ControlNet;
直接用git克隆到插件目录,重启WebUI就安装好了,安装好之后在文生图界面会多出一个ControlNet栏。
ControlNet有很多自己的参数,参数的作用可以看这位up主的视频,他已经讲的很详细了:【赛博Coser】《超详细》ControlNet拆解教学,让你彻底理解AI绘画的精髓。
-
Image(图像):用于传入参考图的原图;
-
相机按钮:在Image下方的相机按钮是用来打开电脑的默认摄像头的;
-
Enable(启用):启用ControlNet;
-
Invert Input Color(反转输入颜色):用于以白色为背景的参考图,需要勾选这个选项,可能是因为不同的算法、模型对蒙版的处理不一样导致的吧,比如前面提到的局部重绘就有出现蒙版颜色不一致的情况,有的用黑色作为蒙版颜色,有的用白色作为蒙版颜色;
-
RGB to BGR:这个选项大多数情况我们应该用不到,这个选项的主要目的是我们平常的图片使用的RGB通道,但是OpenCV默认使用则是BGR通道;
-
Low VRAM(低显存模式):在显存不够的时候可以勾选上,虽然作者并没有说明使用低显存模式对出图质量会有什么影响,在我自己的测试中,在同一显存条件下,勾选低显存模式会降低出图质量和出图速度,所以在显存够用的情况下,这个选项就不要勾选了;
-
Guess Mode:这个模式按作者的说法是勾选上以后AI会忽略提示词,在ControlNet的约束范围内自由发挥,但我实际使用的情况是如果我们不手动清空提示词,AI并没有忽略提示词,AI生成的图里依然严格包含提示词的内容,值得注意的是这个模式是不适用于所有预处理器,比如描边用的canny就无法只用这个模式,强行使用会报错;
-
Preprocessor(预处理器):预处理器我个人理解就是用于对参考图做预处理的算法,不同预处理器对应不同的图像处理算法;
预处理器中用的比较多的住主要是:
这些预处理器的算法是没有内置在插件里的,当我们使用了一个本地没有的预处理器时,插件会自动为我们下载对应的算法。
canny-边缘检测,处理效果是:

depth-深度计算,处理效果是:

depth_leres-更进精确的深度计算,depth_leres能更准确检测原图的环境,具体可以看:Add support for LeReS depth by cmeka · Pull Request #167 · Mikubill/sd-webui-controlnet;处理效果是:

openpose-姿势检测,处理效果是:

Hed-更柔和边缘检测,处理效果是:

Hed算法描边更柔和能够记录更多的细节。
mlsd-适用于建筑物的边缘检测,处理效果为:

mlsd算法对棱角的描边处理很优秀。
normal_map-法线图检测,处理效果是:

法线图的优点在于,它即保留了图像一定的深度信息,又能够保留一部分图像的细节信息,对于想要使用深度图控制图片生成,但是又想要保留一些人物细节的时候可以使用。
pidinet-更粗糙的边缘检测,处理效果是:

pidinet描边保留的细节比canny更少,所以对AI出图约束也更小。
scribble-分割检测,处理结果是:

scribble算法是一种图片分割算法,可以使用黑白色块将图片分成不同的部分。
fake_scribble-超级粗糙的边缘检测,处理效果是:

fake_scribble算法基本上就只做了外边缘的检测,内部的边缘线基本就抛弃了,保留的细节比pidinet更少。
segmentation-语义分割,处理效果是:

语义分割可以将像素分类成不同模块,如哪些像素属于人物,哪些像素属于地板,哪些像素属于植物,然后将这些像素连成一个一个的色块,这个算法更适用于场景类的图片生成。
以下是在撰写Lora训练时WebUI更新的新的预处理器
Openpose_hand-带手势的姿势检测,也使用openpose模型,需要使用人物的脸和手比较清晰的图片才能识别的比较好;

下面三个预处理器是ControlNet融合了T2i-adapter的一些能力,T2i-adapter是北大和腾讯ARC开源的一个扩散模型引导算法,是和ControlNet齐名的引导算法,所以预处理器使用的模型也由T2i-adapter提供,地址是:TencentARC/T2I-Adapter at main,模型下载下来后也放入extensions\sd-webui-controlnet\models文件夹下。
clip_vision(风格转移)-可以传入一张图,使AI学习图片的风格,让AI绘制出风格相近的图片,配个Style模型使用,我自己在使用的过程中webui加载coadapter-style-sd15v1.pth模型时会报错,需要使用t2iadapter_style_sd12v1模型才能正常使用。
这里我使用了一张暗调的图给AI进行风格化学习,出图效果如下:

可以看到AI绘制出来的图片基本都是偏暗色调的了,实际测试中发现,AI对风格化的学习很大程度上会受到提示词的影响,当提示词的控制的画面是一个很亮的画面时,AI学习了风格化也不一定能稳定的出暗调的图。
color(色彩)-可以传入一张图片,生成像素分布,然后让AI根据像素分布来绘制图片,需要配合t2iadapter_color_sd12v1模型使用,就我自己实际使用后的感想是:没什么乱用,看到网上有人用这个模型通过图生图来精细的控制画面中物品的颜色,就我个人的实际使用来看,效果一言难尽。
-
Model(模型):模型就是作者针对不同的预处理器训练的用于对应机器视觉的神经网络模型,这些模型作者在huggingface上分享了出来:lllyasviel/ControlNet at main ,不过吧,作者分享的模型有点冗余是融合了一下其他的模型在里面的,实际模型没那么大,作者也在Git页面有提供说明和萃取精简模型的方法,我就没有自己去萃取了,已经有大佬为我们萃取好了,这里推荐秋叶大佬萃取的:【AI绘画】controlnet安装/使用教程 动作控制 景深 线稿上色;
(最近发现作者自己也萃取了模型分享了出来,地址是:webui/ControlNet-modules-safetensors at main)
各种类型的算法都有对应的训练模型,这些模型能有优化ControlNet辅助AI出图的效果,我们下载的模型有两种,一种是放在
extensions\sd-webui-controlnet\models文件夹下的,这种模型比较大,纯净版都有一G多,原作者给的甚至有五个多G,个人理解这种模型应该是有点类似Lora的感觉,用于辅助出图的;另一种是放在对应的算法文件夹下的,如作者提供的用于openpose的body_pose_model.pth和hand_pose_model.pth,这种比小一般在100多MB,这种模型个人理解是有点类似OpenCV使用的caffemodel模型,用来辅助ControlNet出中间图的。当然也可以不使用模型,我自己实际使用中使不使用模型效果感觉没什么区别; -
Weight(权重):ControlNet根据生成的中间图给出Difusion生成图片的条件,以使AI创作图片时符合ControlNet的约束,这和Clip给出的图片生成条件就会出现拟合,所以需要一个权重来分配两组条件的占比,Weight就是来控制两组生成条件的权重的。

- Guidance Start(T)/Guidance End(T):这两个选项是用来控制ControlNet在Smapler重复采样过程中的干预程度的,Guidance Start设置的是从第几次采样开始进行干预,Guidance End设置从第几次采样开始停止干预,如在一个采样步数为20步的绘画过程中,我们设置Guidance Start=0.2,Guidance End=0.8,那么在这20步得采样中,ControlNet的干预从第4步开始到第16步结束。

-
Resize Mode(缩放模式):缩放模式控制的是生成图与参考图之间的适配方式;
-
Canvas Width(画布宽度)/Canvas Height(画布长度):控制的是ControlNet对原图采用多大分辨率来进行图像识别,主要使用来解决当传入的原图很大的时候显存吃不消的问题,我实际测试中,这两个选项的设置对出图几乎没有影响。
-
Create blank canvas(创建空白画布):ControlNet除了可以输入图片作为原图来生成中间图,也可以通过手绘一张原图来生成中间图,这个按钮就是用来创建手绘的空白画布的;
-
Preview annotator result(预览预处理结果)/Hide annotator result(隐藏预处理结果):用来预览和隐藏中间图。
对于不同预处理器,还有各自的自有参数,这里就挑最常用的三个记录一下:
Canny:
Annotator resolution:控制ControlNet生成中间图的精细度;
Canny low threshold(描边最低阈值)/Canny high threshold(描边最高阈值):影响描边预处理器生成描边图时的边线精确程度。
Depth:
Midas Resolution:这选项没摸明白有什么用。
Openpose:
只有一个Annotator resolution参数。
有一点需要注意,ControlNet生成的中间图都会存储在C:\Users\[用户名]\AppData\Local\Temp系统临时文件夹下,不仅如此很多webui的插件生成的一些中间文件也都会存储在这个目录下,使用时记得时不时清理一下这个目录,避免C盘爆炸。
ControlNet功能十分强大,可以做很多骚操作,比如:
角色改姿势
有时我们出图时,可能会碰到有的图角色姿势很好,有的图角色设计的很好,ControlNet就可以让我们把二者结合起来,主要就是在图生图中运用ControlNet的深度图来限制角色各个关节的空间位置关系,然后AI根据姿势的约束和原图的约束来生成一张新图。

这里放一张我的参数图:

不过吧,即使随机种子也是一样的,新生成的图和部分元素依然是会有一些差别的,如果这个差异在可接受范围内,这个功能也是一个相当不错的功能了。
骨骼控制姿势
骨骼控制需要配合Openpose Editor插件一起使用,插件地址是:fkunn1326/openpose-editor: Openpose Editor for AUTOMATIC1111’s stable-diffusion-webui。
Openpose Editor提供了我们在WebUI中进行人体骨骼特征点位置的编辑功能,界面操作十分简单,看一眼就会了,这里我就只展示一下效果就可以了,比如我要画一个半鸭子坐的女孩,我们就可以在Openpose Editor中将骨骼编辑成这样:

然后我们可以点击Send to txt2img将编辑好的骨骼发送到文生图,然后启用ControlNet,Preprocessor选择none,Model选择control_openpose。
然后就可以出图了:

不过吧,我个人感觉效果上还是没有想象中那么优秀,大体上能够控制出图的姿势,对于一些比较难画的姿势,如跪姿,鸭子坐,脚还是很容易画崩,要想出好图还得大力出奇迹。
使用骨骼出三视图
Openpose Editor支持多骨骼编辑,我们点击Add按钮可以往骨骼编辑视图中添加骨骼,这就给绘制人物三视图提供了条件,如我们制作一个这样的三视图骨骼:

然后使用ControlNet来根据骨骼绘制,就可以得到这样的图:

也就乐乐就好了,效果嘛,是可以画出各个角度的姿势,但是每个人物几乎控制不了让他们都长一样,服装也控制不了。
使用线稿草图快速出三视图
使用骨骼出三视图的一个难点是很难使三视图的角色都画的一样,另一种思路是使用线稿草图来约束AI绘制的角色轮廓,使AI绘制我想要想要的角色的三视图,如果再搭配对应的人物Lora效果就可以做到十分完美。
首先我们需要一张草图,如我要绘制一个角色的头部的45度侧面,正侧面和正面三个视角的三视图,首先我们出一张用于约束AI的草图:

这里我是专门训练了这个人物的Lora的,输入我们想要效果的提示词,启用ControlNet,由于草图是白色背景,所以需要勾选反色模式,选择Canny边缘检测,调好权重和画布,然后就可以开始选图了,这是生成的效果图:

手部修复
AI画手一直是个老大难的问题了,如今ControlNet给出了解决方案。原理也很简单,就是使用ControlNet进行局部控制,如我们生成了一张各方面都挺满意的图,然后AI把手给画崩了,我们就可以使用手部修复来按照我们的想法把手修复成正常的样子,如我们有这样一张图:

女孩右手的手指有点画崩了,这里用ControlNet修一下。
首先我们需要制作一张符合我们要求的手部姿势图,可以使用简单的描边图,也可以使用深度图,手部姿势图分辨率要保证和原图一致,并且手部姿势要放在正确的位置上,如:

然后使用图生图的局部重绘以尽可能的保留画面的其他细节,将参数设置的和原图的参数一致,随机种子也设置成一样的,重绘幅度设置在0.5以下,启用ControlNet约束AI的手部绘制,如果手部姿势图是白色背景记得勾选反转输入颜色,预处理器选择none,模型选择适合自己原图的画布,其他的参数可以根据自己的需求微调,然后我们来看一下效果:

Multi-ControlNet
多层ControlNet是ControlNet最近新出的功能,ControlNet插件默认是只使用一层的,要开启多层我们需要在设置/ControlNet/多重ControlNet的最大模型数量选项设置我们要启动的最大层数,目前最大支持10层。我们启动的层数越多,对图像生成的控制就越细,AI所吃的显存也越高,以我的12G3080ti为例,我启用了两层,一层控制人物骨骼姿势,一层控制背景场景结构,跑512x512,勾选hires.fix倍数2倍就直接爆显存了。
人物骨骼姿势:

背景构图:

出图效果:

Seg语义分割
Seg语义分割实际就是使用ControlNet的segmentation算法,通过处理色块拉达到控制图片生成的目的,segmentation算法的语义分割符合ADE20K语义分割数据库的标准分割规则,所以我们可以根据ADE20K标准语义色块来向控制图片生成指定的物体,不过ADE20K的标准色块语义更多的是适合建筑设计和室内设计领域,所以使用segmentation也就更适合用于这两个方面。
ADE20K色块图可以到这位Up的视频下下载:【AI绘画】强大的构图工具:Seg(ControlNet)语义分割控制网络;
就我实际的使用效果来说,WebUI的Seg语义分割没有想象中那么强,首先webui内置的segmentation算法识别出来的色块不够精准,对于很平滑的直线,它能识别成破损的曲线,不建议使用内置的识别算法,可以选择使用hanggingface提供的工具:OneFormer,Task Token Input选the task is panotic,Model选ADE20K,Backbone随意,这个工具生成出来的Seg图要比webui内置算法的好,对于这样一张原图:

二者的语义分割效果是
OneFormer:

WebUI的Seg图:

能够很明显的看出差距。
对于使用色块来控制图像生成,也没有想象中的那么强,比较明显的就是AI总是喜欢往墙上绘制一些没有意义的纹理,并且对于一些不符合逻辑的要求,AI基本不会满足我们的述求。如下图,我使用色块在地毯边上放了一个盆花草(ADE20K的RGB值为:#CCFF04),然后将墙上的代表图片的红色色块换成了代表窗户的灰白色色块(ADE20K的RGB值为:#E6E6E6),就得到了这样一张Seg图:

即使我们重点强调了窗户,但AI依然不会绘制窗户。

使用蒙版控制灯光氛围
ControlNet可以配合图生图使用灯光蒙版可以进行简单的出图灯光氛围的控制,要控制灯光氛围有三个要点需要注意的,其一,我们需要保证图生图的参数与原图出图参数一致,其二,使用ControlNet深度图控制画面,其三,使用灯光蒙版控制灯光氛围。
首先我们使用文生图来生成一张测试示例:
然后将生成的图片放入PNG Info标签页,识别原图的参数配置,然后点击Send to img2img,这样原图的完整参数配置,包括随机种子,就都发送到图生图标签页了。
然后启用ControlNet,使用深度图控制画面,这样我们就可以使用图生图生成和原图"整体上一样"的图了,注意这里我用的是"整体上一样",因为除非我们把重绘幅度设置成0,否则出图或多或少都会有一点细微的差别。
最后在图生图标签页的img2img中放入灯光蒙版图片,调整好灯光范围,然后出图看一下效果:

可以看到灯光氛围效果已经根据灯光蒙版图改变了,但是这里有一个矛盾,我们想要好一点的效果,重绘幅度至少要在0.6以上,而重绘幅度高了之后,原图就会出现较为明显的变化,如上面的示例中,领结的颜色变了。如果不是很在一细节就无所谓,如果在意细节,就只能去PS里做一些简单修改了,效果图:

不过对于被光影影响到的细节,没有一点美术功底基本就很难修了,如上面示例的“发花”。
2.制作全景图
使用WebUI制作全景图需要一个Lora和一个插件,Lora是LatentLabs360,插件是asymmetric-tiling-sd-webui,安装好插件后在文生图和图生图界面下会出现一个Asymmetric tiling栏,这是用来并接360图片的。
首先输入关键词:
<lora:latentlabs360_v01:1>,((a 360 equirectangular panorama)) , modelshoot style, (extremely detailed CG unity 8k wallpaper),
room,girl's room,Pink princess bed,Tiled floors,walls,Pot picking,Bright sunlight,
第一行是对360图片进行描述的关键词,必填,第二是对内容进行描述的关键词,可以自由发挥,我自己测试使用latentlabs360这个Lora只能用来画场景,画人会出现很奇怪的图。
反向关键词随意。
采样算法我测试了全部的算法,只有Euler a的效果还算行,步数也是只有在20左右效果好,太低或太高都会画不出360图。
然后就是重点,分辨率必须是横纵比2:1的比例,否则画不出360图,然后需要勾选Asymmetric tilling插件的Active和Tile X选项。
生成的图还需要经过放大,分辨率太低用全景图片查看器看图时效果会很差。
然后我们可以出图来看一下效果:


然后我们用全景图片查看器来看看效果:
由于csdn不能上传超过10mb的gif,可以到这里查看,或移步至个人博客阅读。
想要制作一张优秀的全景图,需要花很多时间去打磨关键词和局部重绘,没经过处理的全景图,乍一看感觉还可以,但是一细看就全是破绽。
3.制作视频
使用ControlNet来使用AI生成视频有两种方式,一种是使用批量图生图配合ControlNet控制姿势来生成视频,另一种就是通过mov2mov插件配合来制作视频。
这里使用的原视频是:https://www.bilibili.com/video/BV1i24y1p7iZ/?spm_id_from=333.1007.top_right_bar_window_history.content.click。
采用了视频的前五秒来作为原视频。
批量图生图
先将一段视频使用视频编辑工具导出序列帧,每一帧就是一张png,然后启用ControlNet,Preprocessor选择hed,hed能够尽可能多的记录原图的人物形态和环境要素,model选择对应的模型,然后使用批量图生图的形式让AI更具序列帧一张图一张图的绘制,为了使制作的视频效果尽可能的好,我们应该尽可能使视频中的环境要素尽可能的简单,以使AI绘制的图片的背景尽可能的不变,我们也可以设置蒙版,使AI在绘制时只对人物所在区域进行绘制,同时配上一些尽量匹配原视频的关键词,这样可以将输出的图片之间的差异减到最小,然后我们再将AI绘制过一遍的图片序列作为输入,配合负面关键词来去除在第一遍生成时出现的一些我们不希望在视频中出现的元素,如果配置满足的话,可以配合Multi-ControlNet对人物形态,场景等做进一步约束。
来看一下效果:

AI制作视频最大的难点依然是无法控制每张图尽可能的不变。
mov2mov插件
mov2mov插件是一个国人制作的sd-webui插件,插件地址是:Scholar01/sd-webui-mov2mov: 适用于Automatic1111/stable-diffusion-webui 的 Mov2mov 插件。
安装好插件后在标签栏会出现一个mov2mov标签页,然后直接将视频拖入mov2mov视图,Width和Height设置为和视频一样的分辨率,Generate Movie Mode选择自己想要的视频输出格式,Noise multiplier设置成0,Movie Frames可以按自己喜好设置,也可以按原视频的帧率设置,Max Frames默认-1就好了,然后ControlNet和批量图生图配置的一样,使用和对应的模型,然后就可以生成了。
mov2mov插件原理和批量图生图是一样的,只是插件为我们做了将视频导出为序列帧,将序列帧制作成视频这两步,虽然方便了不少,但同时也蒙版精确控制的能力。
效果:
由于csdn不能上传超过10mb的gif,可以到这里查看,或移步至个人博客阅读。
这也是使用mov2mov生成两遍的效果,效果上感觉不如使用了蒙版控制的批量图生图的方式。
更稳定的视频输出
前面的视频制作都会出现跳动的问题,在开始撰写第九章时,一项新的AI视频制作技术出来了,已经可以很好的解决视频跳帧的问题了,不得不说AI的技术进步真是肉眼可见。
这个方法需要三个插件一个脚本,分别是:
ControlNet插件:Mikubill/sd-webui-controlnet: WebUI extension for ControlNet;
Ebsynth Utility插件:s9roll7/ebsynth_utility: AUTOMATIC1111 UI extension for creating videos using img2img and ebsynth;
WD14-tagger插件:toriato/stable-diffusion-webui-wd14-tagger:Automatic1111 的 Web UI 的标签扩展 ;
multi_frame_rendering脚本:enhanced-img2img/scripts at main · OedoSoldier/enhanced-img2img 。
这个脚本可也一使用大江户战士U修改过的脚本:multi_frame_render.py;
B站教程地址:【AI动画】多帧渲染法 介绍及使用。
Ebsynth Utility插件用于提取视频中的关键帧,除此之外这个插件还可以批量为关键帧生成蒙版图片,可以自动提取变化较大的关键帧节点。
WD14-tagger插件用于批量从关键帧图片中提取提示词,并批量生成对应的提示词文本。
multi_frame_rendering脚本使用多帧渲染技术就是使AI生成的视频稳定的关键技术,玩AI绘图一段时间后都会发现一个现象就是在同一批次生成的图片中,人物的脸大都是一样的,multi_frame_rendering就是运用了这个原理,在出图时使用三张图并接的方式出图,并且后一张图的出图时会参考前一张图,配合Multi-ControlNet的精确控制,这样就可以使AI出的图趋于稳定。
但也真是因为进行诸多环节对AI出图的画面进行控制,导致了AI绘制视频帧的速度大大减缓,我生成一批(164帧)的序列帧,使用RTX3080TI-12G绘制也足足需要花费近3个小时,视频时长总共才5秒钟。
下面使操作步骤:
安装ControlNet
首先我们需要安装插件和脚本,ControlNet插件前面已经有提过,就略过了。
安装Ebsynth Utility
Ebsynth Utility插件依赖一个视频处理库ffmpeg,这是官网地址:FFmpeg。
我们需要下载windows版本,下载下来的库就是一个已经编译好了的库文件夹,库里面主要的文件夹有bin、include和lib,include和lib主要是给编程开发用的,这里插件主要是使用bin文件夹,把bin文件夹添加到系统环境变量中,库就安装好了,然后可以通过cmd键入ffmpeg -version来查看库是否安装完毕:
然后使用git把Ebsynth Utility库克隆到webui的插件目录,Ebsynth Utility插件就安装好了。
批量提取视频帧
Ebsynth Utility插件的功能有很多(各个选项的作用,作者已经在ui上注明),我们这里主要使用的是它的stage 1。

选择stage 1,Project directory输入存放序列帧的目录,Original Movie Path输入视频路径,也可以将视频拖到下方的输入框,拖视频到输入框插件会拷贝一份视频到C:\Users\[用户名]\AppData\Local\Temp系统临时文件夹中。stage 1的configuration的设置是在需要同时提取关键帧的蒙版图片时才需要配置,如果不需要提取蒙版图片的话,直接默认就好了。
有一点需要注意,Ebsynth Utility插件没有权限向webui的outputs目录输入文件,所以我们设置的输入输出文件夹不能放到webui的outputs目录下。
安装WD14-tagger
使用git把WD14-tagger库克隆到webui的插件目录,WD14-tagger插件就安装好了,我更新到最新的2023.3.13的webui发现,安装好插件直接从扩展选项卡重启界面后webui有时并不能识别到新安装的插件,不知道是不是bug,最好直接重启服务器。
批量生成序列帧提示词

这里我们主要使用批量操作,输入目录输入我们生成的序列帧所在的目录,输出目录可以不填,不填默认将识别到提示词文本存储到输入目录。勾选使用空格代替下划线、转移括号和完成后从显存卸载模型,不卸载模型,模型会一只占用部分显存。
在使用的过程中发现插件有一个bug,即使用批量操作时,单张图片下不能放入图片,否则批量操作不会执行,而只执行单张图片的提示词识别。
其实这一步也可以通过图生图的提示词反推功能代替。
安装multi_frame_rendering
将multi_frame_rendering脚本下载到webui的script目录,multi_frame_rendering脚本是依赖于ControlNet的,所以我们需要在webui的设置中勾选ControlNet下的允许其他脚本对此扩展插件进行控制。
multi_frame_rendering脚本只适用于图生图界面,所以我们只能在图生图界面中找到这个脚本。
使用ControlNet进行图像控制
这里我们使用两层控制网络(如何启用多重ControlNet可以查看第五章第一节Multi-ControlNet),第一层使用hed边缘检测进行控制,第二层使用发现贴图进行控制,参数可以根据自己的实际需求进行调整。
使用图生图确定要绘制的风格
我们可以使用提示词、Lora等风格化模型控制AI对视频的人物,画风等进行定制,对于人物需要专门的人物Lora才能有比较好的效果。这样AI就可以根据提示词和Lora绘制出我们想要的人物和画风的序列帧。
确定好输出序列的分辨率,步数,采样算法,基础模型后就可以锁定随机种子,进行最后的多帧渲染了。
因为我们使用了多层控制手段来控制AI出图,所以重绘幅度我们可以调高一点。
多帧渲染
启用multi_frame_rendering脚本,输入目录选择Ebsynth Utility插件的序列帧输出目录,输出目录自行设定,Third column(refernce) imge有三个选项FirstGen-使用处理后的第一帧作为参考图,OriginalImg-使用原始的第一帧作为参考图,Historical-使用当前帧之前的倒数第二帧作为参考图,这里我选择使用FirstGen,Loopback source也有三个选项,Previous-从上一帧生成帧,Current-从当前帧生成帧,First-从第一帧生成帧,我这里选择Current,然后勾选Read tags from text files,勾选后脚本会自动从同名的提示词文本中提取提示词来控制图片的生图。
其实multi_frame_rendering脚本自己也提供了每帧提取提示词并应用的功能,在Append interrogated prompt at each iteration中选择webui内置的文本编码器,脚本就可在渲染时使用对应的编码器提取输入图片的提示词,但这样会增加渲染的时间,所以我们使用WD14-tagger插件来提前将提示词提取出来。
等待漫长的渲染过程之后,将序列帧转成视频,就可以看到效果了:
由于csdn不能上传超过10mb的gif,可以到这里查看,或移步至个人博客阅读。
效果是相当不错的,只是我在出图的时候忘记添加脸部的描述,AI把脸给画崩了,再画生成一次又要花4个小时,就将就着用着了。
生成奇特的缩放视频
先来看一下效果:
由于csdn不能上传超过10mb的gif,可以到这里查看,或移步至个人博客阅读。
要制作这样的一个视频依赖于Infinite Zoom插件,安装好插件就可以在标签栏看到Infinite Zoom标签。
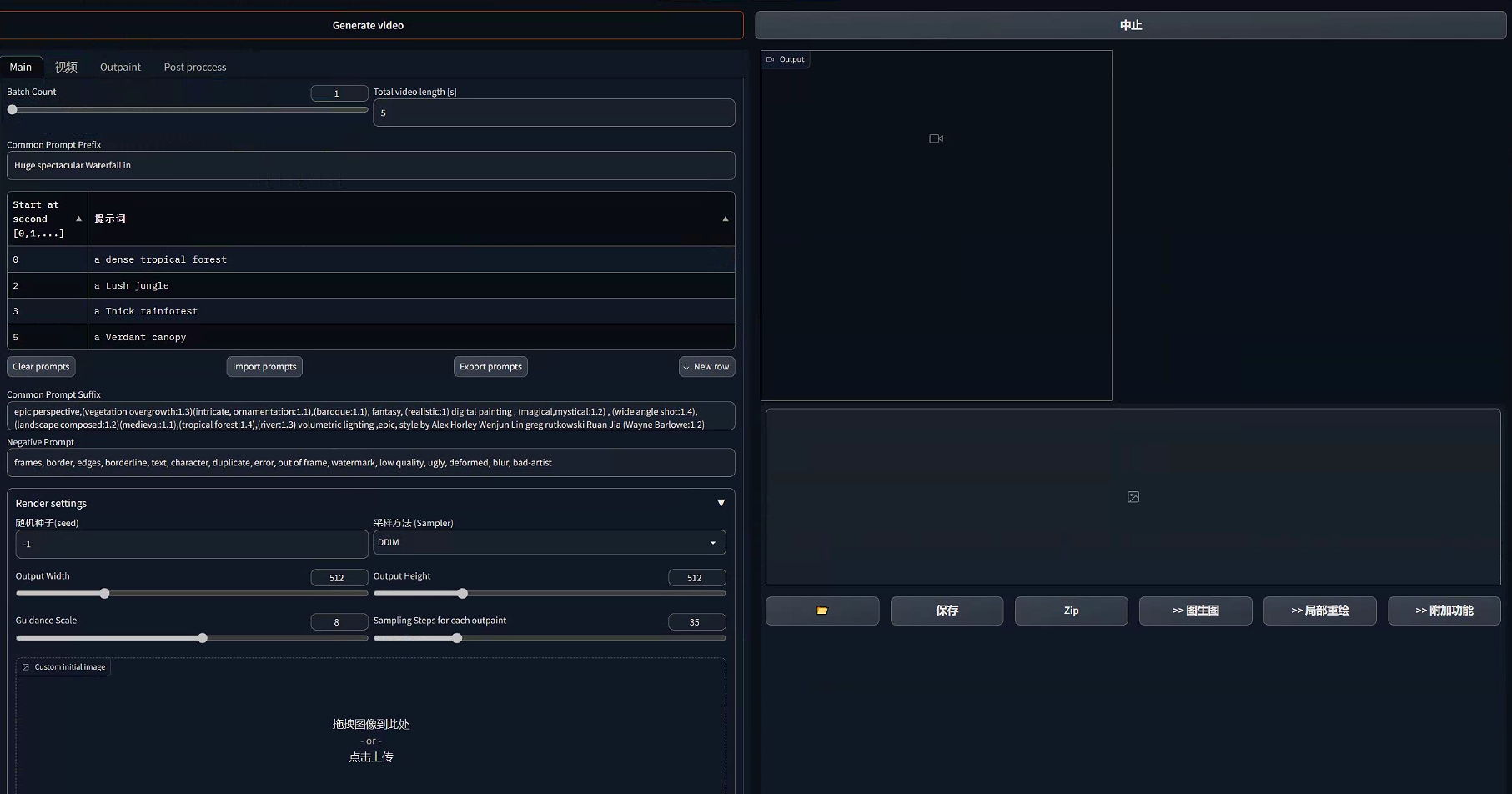
整个界面有四个标签页,main,video,outpaint和post proccess。
Main标签页是我们主要的操作页面:
-
Batch Count:要生成的视频批次,一次可以渲染多批视频;
-
Total vido length:生成视频的时长,默认为5秒;
-
Common Prompt Prefix:通用的图像生成前缀,可以放一些对组成视频的所有图片都需要的一些需要放在前面关键词,如一些对画面整体质量、风格的描述;
-
表格:中间的表格就是对每个画面的内容的关键词描述了,
Start at second:对应画面图像要出现的时刻;
Prompt(提示词):画面要表现的内容提示词;
Clear prompts:清空所有提示词;
Import prompts:快速导入提示词;
Export prompts:导出提示词,导出的提示词会以json文件的形式存储;
New row:新增行;
-
Common Prompt Suffix:所有画面通用的提示词后缀,可以放一些对所有生成图像的氛围描述,如:时间段、光影效果、渲染模式等;
-
Negative Prompt:通用的反向描述词;
-
seed(随机种子):生成图片时所使用的噪点种子;
-
Sampler(采样方法):生成图片时所使用的采样方法;
-
Output Width/Output Height:输出图片的长宽;
-
Guidance Scale:提示词相关性;
-
Sampling Steps for each outpaint:每张图片的采样步数;
-
Custom initail image:初始图片,图片可以先在文生图中生成,在zoom-out(缩小)模式下初始图片将作为第一帧的图片,在zoom-in(放大)模式下初始图片将作为最后一帧的图片。
Video标签页主要是对整个视频的操作设置:

- 每秒多少帧:设置视频帧数;
- Zoom mode:缩放模式,zoom-out:缩小,zoom-in:放大;
- number of start frame dupe:视频开始时要冻结的帧数;
- number of last frame dupe:视频结束时要冻结的帧数;
- Zoom Speed:缩放速度,单位为秒;
Outpaint标签页设置图像的重绘:

内容很少,一般页不用修改。
Post proccess标签页设置图像的放大:
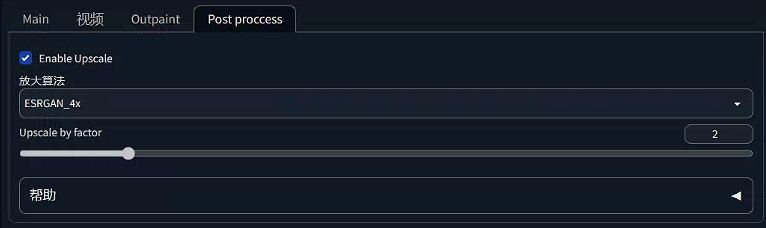
这个方法也没啥好说的了,设置都非常直观。
所有设置都设置好之后,就可以点击Generate video按钮开始生成视频了,生成视频的时间比较长,我4070ti的配置生成一个9秒的视频大概在700秒左右。
生成的视频可以在右侧预览,和下载,在output/infinite-zoom文件夹下也存有所有的生成的视频。
4.OutPainting
outpainting是官方提供的一项AI图像扩展技术,AI可以根据已有的图像来扩展图像之外的画面。
outpainting需要配合官方提供的inpainting模型使用才能够对图像进行补全,inpainting模型有两个版本,1.5和2.0下载地址分别是:
sd-v1-5-inpainting:runwayml/stable-diffusion-inpainting · Hugging Face;
512-inpainting-ema:stabilityai/stable-diffusion-2-inpainting · Hugging Face。
下载好模型之后放入models/Sable-diffusion文件夹中。
修改webui-user.bat文件,在set COMMANDLINE_ARGS=之后添加--api --cors-allow-origins=https://www.painthua.com参数。
然后启动webui,进入https://www.painthua.com网址,网址连的我们本地的stable diffusionu服务,在网页的Config选项中设置服务器的地址,画布的大小以及选区的最小尺寸,一般我们没有修改过服务器地址和端口的话,默认是127.0.0.1:7860就不需要修改了。
用法就比较简单了,在Prompt选项我们可以设置正方向提示词,要使用的模型、采样算法、采样步数等,原理和文生图是一样的,然后通过绘制选区来生成指定分辨率的图片,也可以使用Ctr+O上传本地图片来扩展。
当一个张图片生成好之后,我们就需要切换模型到inpainting模型,然后绘制任意大小的选区进行图片扩展,选区要和图片有重合,一边AI学习原图的风格。
如:我们可以将这样一张图:

扩展成这样一张图:

其他的功能也很简单,玩个一两分钟基本就会了,在Help选项作者也提供了视频教程。
5.人物换装
人物换装说来也比较简单,主要就是运用图生图的局部重绘功能搭配指定服装的提示词来达到换装的效果。
首先使用文生图出一张示例图:

然后使用图生图的局部重绘,将我们想要换装的区域涂上蒙版。
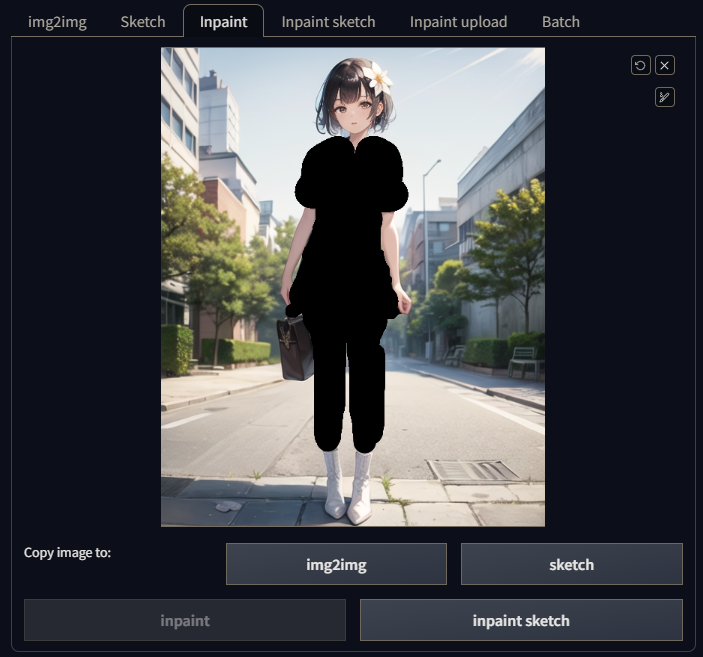
然后就改服装的提示词,就可以做到这样的效果,提示词可以直接使用Prompts from file or textbox脚本批量控制,也可以使用动态提示词插件,这个插件bug还挺多,还要安装一堆依赖,我个人还是更倾向于使用内置的脚本,插件教程可以看这个视频:Stable Diffusion 自定义提示词组 一键生成分类图像 万用提示词。然后就可以抽卡出图了:

6.基于SadTalker的唇型同步
SadTalker开源库地址:https://github.com/OpenTalker/SadTalker
SadTalker有独立的运行版本,也有Stanble Diffusion Webui的插件,由于SadTalker自身就要吃到5个多G的显存,使用Stable Diffusion Webui插件的话,多显存的要求极高,所以我这里主要使用的是独立运行版本。
SadTalker运行环境部署
SadTalker的运行基于Python3.10.6和Stable Deffusion WebUI的依赖版本一致,如果已经安装了SD就可以跳过这一步了。
安装ffmpeg,这是一个专门用于处理视频的库,我们可以直接使用
pip install ffmpeg
来安装,也可以直接到
https://www.gyan.dev/ffmpeg/builds/ffmpeg-git-full.7z
地址手动安装,我个人建议直接手动下载,解压到SadTalker的根目录中,然后到Path中配置
E:\SadTalker\ffmpeg-2023-05-08-git-2d43c23b81-full_build\bin
路径到环境变量。
下载预训练模型
SadTalker的运行需要用到10个预训练模型,可以到
https://github.com/OpenTalker/SadTalker/releases
地址单独手动下载,官方也提供了百度云地址:
https://pan.baidu.com/s/1nXuVNd0exUl37ISwWqbFGA?pwd=sadt
如果是单独手动下载,则在SadTalker的根目录创建一个checkpoints目录,并将所有文件拷贝到这个目录中,如果是百度云下载,则解压后将目录中的checkpoints目录拷贝到SadTalker根目录,然后解压checkpoints目录中的BFM_Fitting.zip和hub.zip两个压缩到checkpoints目录,解压的时候需要注意一下解压目录,有的解压文件会以文件命创建一个目录,此时可能会出现两个BFM_Fitting或hub目录。
安装虚拟环境
前置安装完成之后,就可以双击根目录中的webui.bat运行SadTalker,程序会自行下载所需运行库并生成虚拟环境。
下载运行库的时候经常会出现连接不上库地址而导致超时错误却不提示是哪个库连不上,这就没有其他办法解决了,只能挂上梯子多试几次了,我大概也是试了五六次才成功把虚拟环境创建好。
生成唇型动画
虚拟环境创建好之后,就可以通过webui.bat启动服务,服务器会给出一个本地地址http://127.0.0.1:7860,浏览器打开地址即可进入SadTalker的UI界面,UI界面非常简洁,就两个输入,三个设置,一个输出。

-
Upload image:上传要用于生成动画的图片,建议点击文件夹上传,直接拖过去,程序会将图片先拷贝到c盘临时目录再使用。
-
Upload OR TTS:上传要用于生成动画的语音,建议点击文件夹上传,直接拖过去,程序会将图片先拷贝到c盘临时目录再使用。文字转语音推荐使用这个网址:Text To Speech - 在线文本转语音 (text-to-speech.cn),个人用着刚觉效果非常不错,主要是免费无广告。
-
Seetings:
crop:将图片裁剪成256x256再生成动画;
resize:
full:保留原图尺寸生成动画,同时也会生成裁剪成256x256的动画。
-
Still Mode(fewer hand motion,works with preprocess ‘full’):静滞模型,生成动画时程序会尽量减少对手部的影响,适合再full下使用;
-
GFPGAN as Face enhancer:使用面部增强修复,使用这个选项程序会再去下载一个模型。
生成的动画可以直接在网页端下载到本地,也可以直接到程序根目录的results目录中提取。
来看一下效果,我这里直接使用官方提供的音频:

picgo不能上传视频,这里成了gif,没有了声音。
7.ControlNet 1.1
文章还没写完,插件又更新了…
ControlNet1.1算是ControlNet得一个很大的版本更新,插件变得更强了,也变得更大了,
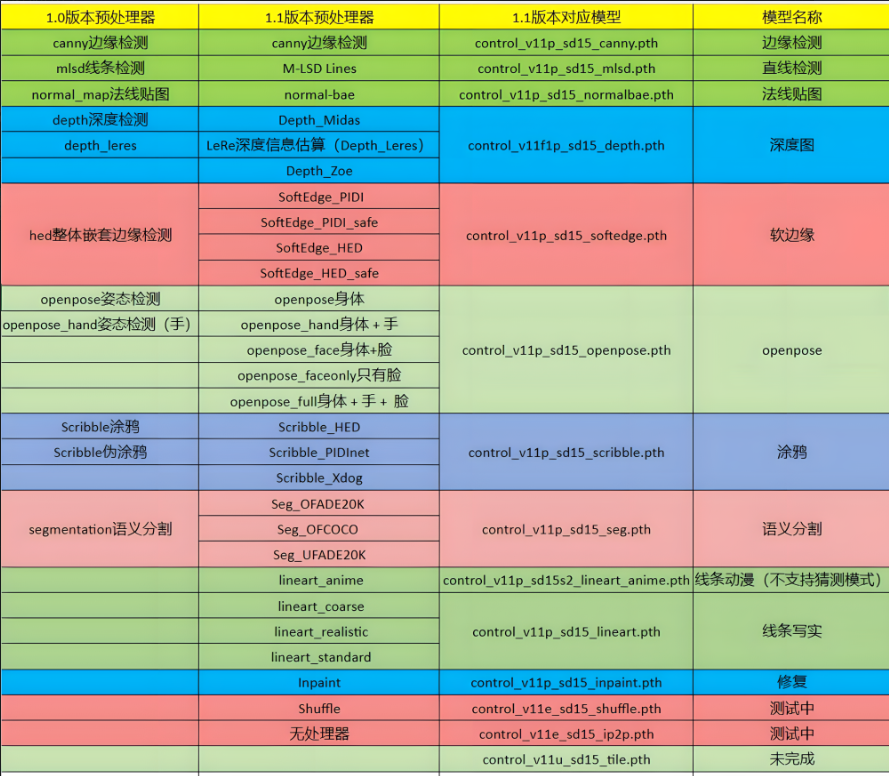
ControlNet1.1新增了很多很多的新算法和新模型,新算法与模型的对应关系这里直接从Controlnet 1.1新版本功能详解,14个控制模型+30个预处理器讲解,Stable diffusion AI绘图教程|Preprocessor使用教程_哔哩哔哩_bilibili这个up的视频中借过来用了:
ControlNet1.1的更新
更新方式比较简单,直接使用WebUI更新、使用git手动pull或者重新安装插件即可。
下载新的模型
ControlNet1.1之后所有的模型都被官方更新了,所以我们需要重新下载模型,模型下载官方网址:lllyasviel/ControlNet-v1-1 at main (huggingface.co),总共有11个模型,每个模型1.45GB是真的大,然后官方也推出了模型的命名规则:

新版本的模型都搭配一个.yaml配置文件使用,所以下载时需要将模型文件和配置文件一并下载,一并放置到extensions\sd-webui-controlnet\models目录下。
除此之外再使用的过程中有些第一次使用的算法还需搭配一个额外的模型使用,这个模型会在使用时自动下载,下载后会存放在extensions\sd-webui-controlnet\annotator\downloads目录的对应算法目录下。
新算法的使用
新算法多大39种,这里就只调几个功能比较强大,用得比较多的算法来说说了。
-
depth_leres++:depth_leres++是一个更精确的深度图,这个算法能保留更多的深度细节,可以看一下和之前的深度算法的对比:

可以看到depth_leres++能保留的细节信息更多。
-
inpaint_global_harmonious:inpaint是一个重绘预处理器,需要配合control_v11p_sd15_inpaint模型使用,可以对蒙版区域进行重绘,局部重绘一直是图生图的专属功能,但是图生图无法进行大分辨率绘图,导致很多时候重绘功能很鸡肋,重绘出来的画面细节不够,使用inpaint_global_harmonious就可以在文生图中进行重绘了,并且配合文生图的高清修复,可以直接重绘高分辨率的大图,比如我们将下图的阶梯换成平路:

除此之外,我们通过手动扩充原图尺寸,也可以使用inpaint模型进行图像扩展,功能类似Outpainting,不同的是我们需要将需要重绘的区域涂成黑色,如我们将一个512x1024的图扩展为1024x1024的图:

-
lineart_anime:lineart算法是Controlnet推出的专门用于线稿上色的描边算法,lineart_anime算法则是lineart算法家族种更适合于二次元的上色算法,lineart算法除了会进行描边之外,还会基于绘画的手法使用线条对阴影进行绘制,使得线稿更加精致;

-
lineart_realistic:lineart_realistic算法和lineart_anime算法相对,是专门针对真实照片进行描边的算法,lineart_realistic算法对真实照片的描边能绘制更多的细节;

-
openpose_full:openpose_full是整合了姿势、手势和表情的算法,可以生成同时控制姿势、手势和表情的控制图,第一次使用时会下载多个模型。

-
reference_only:reference_only预处理器有点类似腾讯的style预处理器,可以使AI参照指定图片的风格来生成图片,如:

配合inpaint_global_harmonious预处理器,可以使AI根据指定图片的风格对原图进行重绘或扩展,如:

-
tile_resample:tile模型算是这次controlnet的重磅更新了,功能十分强大,tile_resample预处理器配和control_v11f1e_sd15_tile模型使用,主要的作用有生成类似的图、为简笔画补充细节纹理、将小图进行高清重绘和用于配合图生图脚本SD upscale图片进行超清重绘。
生成类似的图:这个功能在通过photoshopP图之后,使用AI来融合P图中的看起来比较违和的元素时非常有用,有了这个功能我们就可以快速的使用PS往图中加入我们想要的元素,然后使用AI来融合,当然出图的效果还是取决于大模型;
为简笔画补充细节纹理:先直接看图

tile模型甚至为我们修复了简笔画中不合理的结构。
小图高清重绘:基于tile模型自动补充细节的能力,可以通过输入一张很模糊的小图,使用tile模型在文生图配合高清修复功能进行高清重绘,如:

超清放大:图生图有一个SD upsacle脚本可以将输入的图片进行分块放大,但是脚本只会根据使用方法算法补充像素,最终形成色块,配合tile模型使用则可以达到放大的同时西东补充一些合理的细节,从而避免形成色块。
使用方法就是将要放大的图拖入图生图,然后启动controlnet并使用tile预处理器和tile模型,特别注意controlnet不需要再放入图片,然后重回幅度调到0.2以下,当然如果想要变化大一点也可以调高,然后脚本选择SD Upscale,即可进行超清放大。
-
ip2p:ip2p即control_v11e_sd15_1p2p模型,这是个模型不是算法,这个模型没有对应的算法,使用时预处理器选择none,这个模型可以通过指令修改对图片进行调节,比如左边的原图使用ip2p使用
It turns into winter(变成冬天)的指令,生成了右边这样的图:
不过,模型只能生成一些简单的效果,对于比较复杂的修改效果很差,并且生成图的效果非常依赖大模型的出图效果。
8.基于Regional Prompter的分区域绘制
Stable Diffusion WebUI有好几款分区域绘制的插件,其中个人觉得比较好用的就是Regional Prompter插件。
安装好插件后,会和controlnet一样在文生图和图生图下方出现一个下来选项,展开就是Rgional Prompter插件的设置选项了:

设置项很多,这里就不单独展开了,在后面讲应用的时候再顺带讲了。
Regional Prompter的分割语法
Regional Prompter插件支持一维分割和二维分割,插件使用,(英文逗号)进行一维分割,使用,和;(英文逗号和英文分号)进行二维分割。
一维分割在水平分割模型下会将画面分割成一根根的柱状:
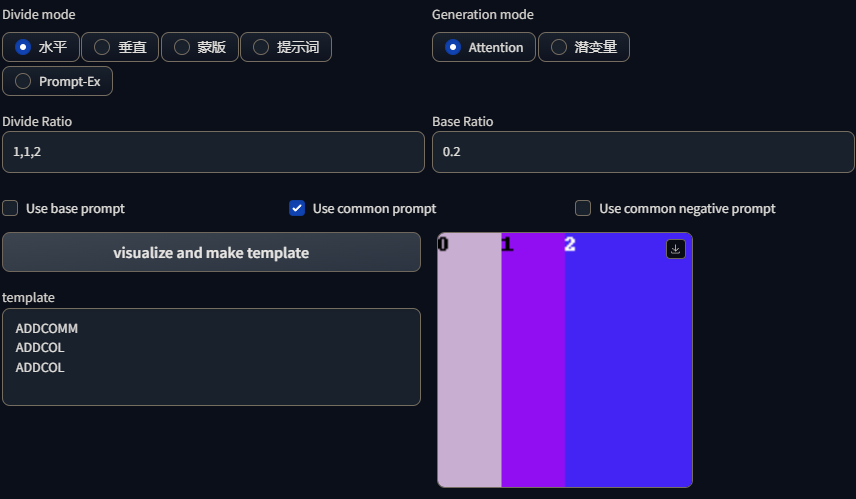
在垂直分割下会将画面分割成一条条的条状,同时插件也支持使用小数的形式进行画面分割,如1:1:2的分割比例也可以写成0.25,0.25,0.5只要小数之合等于1即可:
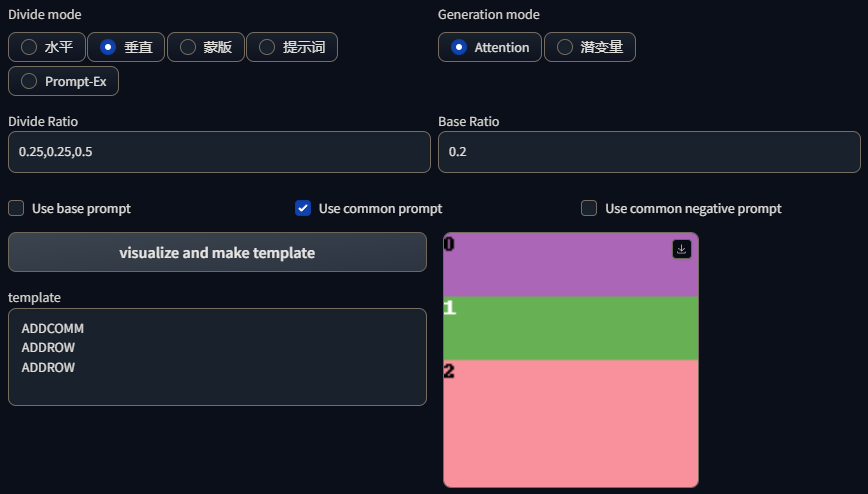
二维分割是先使用;进行垂直模式分割,然后再在条状分割画面的基础上使用,进行水平模式分割,如这样的一个分割语法1,1,1;3,2,1,2分割效果为:

整个语法可以理解为,先使用;进行垂直模式分割,语法为:1;3,画面将被分割成上下比例为1:3的两部分,然后再在1对应的区域使用,水平分割成对半的两部分,语法为:1,1,1;3,再然后在3对应的区域使用,水平分割成2:1:2的三部分,最终语法为:1,1,1;3,2,1,2。
需要注意的是二维分割由于是使用;来表示垂直分割的,所以在垂直模型下使用二维分割会识别不到;,所以上面的分割语法1,1,1;3,2,1,2在垂直模型下只能识别成1,1,1,2,1,2,于是分割就变成了这样:

Regional Prompter的分割词原理
Regional Prompter插件将整段提示词分类为Common prompt、Base prompt和Region prompt三类,其中Common prompt和Base prompt是可选的类型,Region prompt则是必须类型,一般Common prompt指的是描述画面质量、渲染方式、光影等提示词,Base prompt指的是不涉及分区域绘制的画面中的其他特征的提示词,如我们上面的例子画一个女孩,那么Base prompt就可以是1girl、姿势、年龄、场景、表情等提示词,Region prompt则是用于分区域绘制的提示词了。
- ADDROW:垂直分割时使用的分割词,垂直分割把画面分割成一行一行条状,每一个分割线对应一个ADDROW分割词,只能在正向提示词中使用;
- ADDCOL:水平分割时使用的分割词,水平分割把画面分割成一列一列的柱状,每一个分割线对应一个ADDCOL分割词,只能在正向提示词中使用;
- ADDCOMM:用于分割Common prompt类型提示词的分割词,需要勾选Use common prompt选项才能生效;ADDCOMM也可以用于反向提示词,用于分割反向提示词中的Common prompt类型的提示词,一般配合BREAK分割词使用,需要在反向提示词中使用ADDCOMM需要勾选Use common negative prompt选项才能生效;
- ADDBASE:用于分割Base prompt类型提示词的分割词,需要勾选Use base prompt选项才能生效,只能在正向提示词中使用;
- BREAK:用于分区域绘制时为不同区域的Region prompt提示词指定反向提示词的分割词,和Region prompt的分割词一一对应,只能在反向提示词中使用;
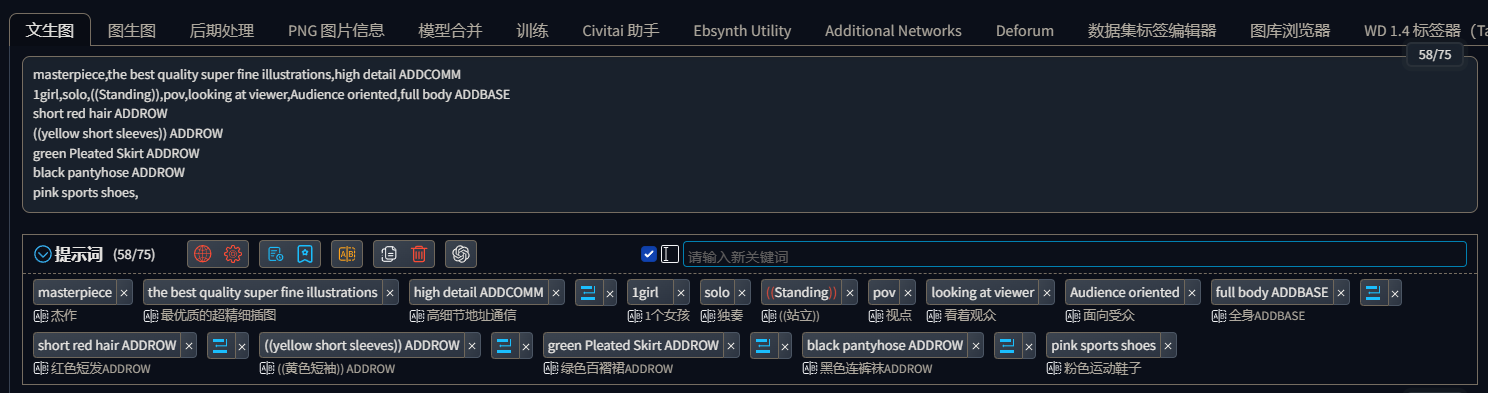
各区域的提示词与分割词之间可以使用,也可以不使用,可以换行也可以不换,如
masterpiece,the best quality super fine illustrations,high detail ADDCOMM 1girl,solo,((Standing)),pov,looking at viewer,Audience oriented,full body ADDBASE short red hair ADDROW ((yello wshort sleeves)) ADDROW green Pleated Skirt ADDROW black pantyhose ADDROW pink sports shoes,
masterpiece,the best quality super fine illustrations,high detail,ADDCOMM,
1girl,solo,((Standing)),pov,looking at viewer,Audience oriented,full body,ADDBASE,
short red hair,ADDROW,
((yellow short sleeves)),ADDROW,
green Pleated Skirt,ADDROW,
black pantyhose,ADDROW,
pink sports shoes,
masterpiece,the best quality super fine illustrations,high detail ADDCOMM
1girl,solo,((Standing)),pov,looking at viewer,Audience oriented,full body ADDBASE
short red hair ADDROW
((yellow short sleeves)) ADDROW
green Pleated Skirt ADDROW
black pantyhose ADDROW
pink sports shoes,
这三种形式最终控制效果都是一样的,不过插件有一个问题,就是插件为了在规定区域绘制指定的物体,可能会改变画面的一些特征导致有些特征和提示词的描述不一致,如我上面的提示词描述的是一个站着的女孩,但是插件为了保证指定区域出现指定颜色的物体,可能会改变绘制角色的姿势,同时尽管我们使用了分区域绘制也无法100%的保证每个区域都能按照我们的预想来绘制,如我上面的提示词偶尔会出现黄色短袖绘制成白色短袖,所以我为黄色短袖增加了权重,才能保证出来的图都是穿黄色短袖的女孩,这些都需要我们在实际调控中根据需求调整。
分区域颜色控制
很多时候我们在画一个画面颜色比较多的图时,只通过提示词来描述物体颜色通常情况都会出现颜色污染,如我们要画一个这样的女孩:

然后我们的出来的结果是这样的:

可以看到颜色基本上很难和提示词对应上,尤其是黄色的短袖和绿色的百褶裙很难画出来,颜色污染非常严重,然后我们用Rgional Prompter插件进行分区控制一下。
首先勾选启用(active)启动插件,由于我们画人竖版的,所以分割模式(Divide Mode)选择垂直(Vertical),然后分割比例(Divide Ratio)按照我们想要的颜色区域分布设定,我这里设定为1,1,1,2,1,这样整个画面就被垂直分割成了1:1:1:2:1的五个部分,除了使用比例式外,插件也支持小数形式,如1,1,1,2,1也可以写成0.2,0.2,0.2,0.4,0.2,然后点击visulize and make template按钮可以生成分割预览,并提供了对应数量的分割词;

然后在提示词中加入分割词,将不同类型的提示词按区域分割开来。
然后可以看一下控制效果:

可以看到基本上颜色分布已经正常了。
分区域多人绘制
多人绘制一直是AI绘图的弱点,包括C站上绝大部分模型对多人绘制支持的都不是很好,所以尽管使用Regional prompter进行控制,出图效果也极大程度的受到大模型的影响,出图效果十分不稳定。
这里的测试,我们对图像进行左右的对半分割,左边画一个健美男,右边画一个舞女,进行如下控制:


然后出图效果:

在我自己的测试中发现revAnimated-1.2.2这个大模型对多人绘制效果还可以。
分区域画面绘制
这里以上面的1,1,1;3,2,1,2的分割比例为例。
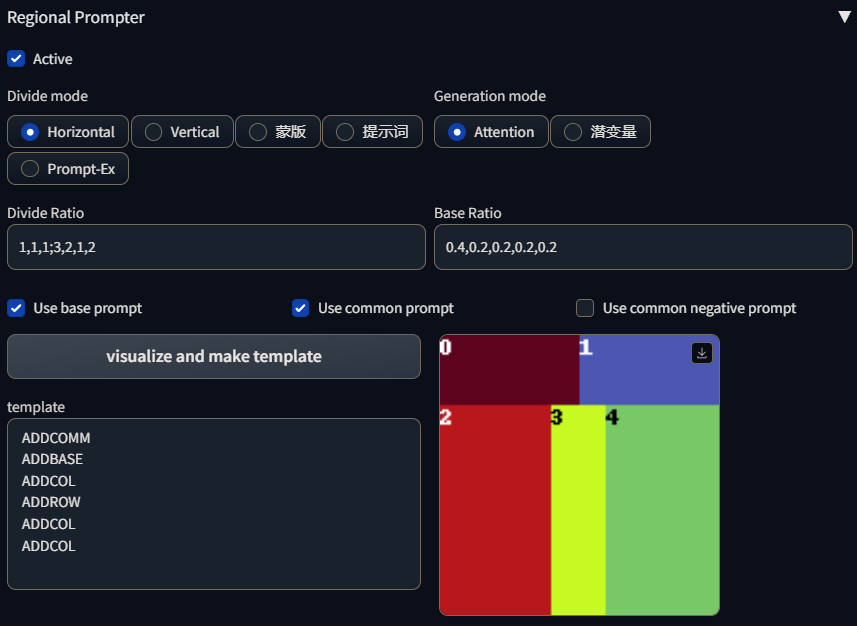
这里我使用了基础比率(Base Ratio),这个设置可以控制Base prompt和Region prompt之间的控制权重,第一个权重是Base prompt的权重,后面跟着的权重是Region prompt的权重,数量和分割的区域对应。默认值是0.2,表示Base prompt权重为0.2,Region prompt整体权重为0.8
左上角绘制一个红色的月亮,右上角绘制密布的乌云,左下角绘制一个钟楼教堂,中间绘制一辆红色的汽车,右下角绘制一个白衣女孩。

出图效果:

尽管对于元素比较多的画面部分特征会被AI忽略,但总体上各个特征绘制的位置还算控制到位。
除此之外,插件还支持使用蒙版来进行区域分割控制,不过使用起来还挺复杂,并且还只支持HSV的颜色格式,另一个个人感觉功能比较强的是分割模式中的提示词,可以根据提示词来确定分割区域,不过我使用的2023.5.22 commit为673801c3ef9f50fa29406400a4d9c4b5464d73b2版本的插件在stable diffusion webui 1.3.0版本中使用这个模式完全不起作用,估计是插件还没有兼容1.3.0的webui吧,所以这两个功能也不过多累述了,具体可以看这个up的视频:【AI绘画】Stable Diffusion画面分区控制:Regional Prompter,从入门到……_哔哩哔哩_bilibili
八、在PS中使用AI绘图
1.环境配置
想要在PS中使用Stable Diffusion,首先我们电脑本地必须安装了可用的SD-WebUI,然后我们需要安装Photoshop2023,因为stable.art插件只支持Photoshop2023 v23.3.0以上的版本。
2.安装Photoshop2023
这里分享一个Photoshop2023 v24.1.0版本的下载地址:Adobe PhotoShop 2023 v24.1.0。
下载完之后,双击解压文件夹中的setup.exe文件安装,安装完之后拷贝解压文件夹/Crack/Photoshop.exe覆盖Adobe/Adobe Photoshop 2023/Photoshop.exe文件。
这样Photoshop就安装好了。
3.安装Stable.art插件
插件的安装就比较简单了,插件是开源的,插件地址:isekaidev/stable.art:Photoshop插件,用于以Automatic1111作为后端的稳定扩散。
这个插件就需要像webui的插件一样克隆整个git库了,我们只需要下载ccx文件就好了,在readme文件里,作者已经提供了下载连接,也可以直接点击这个链接下载:CCX,下载下来后将文件名改成.zip,然后解压,将整个文件夹拷贝到Adobe/Adobe Photoshop 2023/Plug-ins文件下。
这样Stable.art插件就安装好了。
4.启用插件
Stable.art插件的运行依赖于sd-webui的api,所以我们需要以api模型启动webui,打开webui-user.bat文件在set COMMANDLINE_ARGS=之后加上--api启动参数,然后再启动webui,这时的webui就是以api模式启动了。
然后打开ps,在增效工具/stable.art,就可以看到插件了,在Endpoint栏输入webui服务器地址,插件就连接上了webui了,界面的是使用和webui基本是一样的。
stable.art插件使用的所有的设置都是webui的设置,插件目前支持更换模型、简单的文生图、基于选区的图生图,和基于选区的局部重绘,并且生成的图片会自动转换成图层。
stable.art还有一个扩展(Explore),能够提供一些预制的tag关键词,点击之后会自动填充到关键词中。
stable.art插件目前还处于0.0.1的beta版本,功能还很不完善,如果插件能兼容ControlNet,那么这个插件将变得无比强大。
5.Auto-Photoshop-SD插件
这个插件是我在撰写Lora模型训练章节时新发现的一个PS插件,功能要比Stable.art插件强大,而且已经支持了ControlNet,Auto-Photoshop-SD的安装方法和Stable.art一样,并且也只支持2023以上的PS版本,连接Stable Diffusion服务也和Stable.art一样,在设置中设置好地址就可以,然后其他的用法基本就和使用webui一样了。
插件git库地址:AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin:一个用户友好的插件,可以使用Automatic1111-sd-webui作为后端,在Photoshop中轻松生成稳定的扩散图像。
九、模型融合
后续更新计划
十、模型训练
本章参考的资料:
【AI绘画】LoRA训练全参数讲解
lora训练进阶教程,不要再瞎填参数了
零基础 Dreambooth 使用教程
一些基本术语
不收敛
不收敛就是AI在学习图像特征时没有将图像特征学习到模型中。
泛化性
泛化性即泛用能力,是一个模型能否适应多种情况的标准,如一个服装模型,在泛化性差的情况,AI绘制出来的服装可能就都是穿在训练集中的人物身上,或者只能画出服装,不能穿到人的身上,泛化性好的情况就是服装可以指定给任意人物穿上。
欠拟合
欠拟合就是图像特征和提示词关联的不好,使用特定的触发提示词却不能很好的使AI绘制出指定特征的对象,简单的说就是AI学了,但没怎么学会,一般来说欠拟合很少在模型训练中出现。
过拟合
过拟合则和欠拟合相反,即学会了,但是是死读书,不会变通,就如第六章第二节所说的,使用了HelloKity的Lora之后,模型将很难再画出加菲猫,这种情况就是过拟合,即AI学会了新知识却忘记了旧知识。
过拟合的好坏视情况而论,如果是功能性模型过拟合,那么模型就缺乏泛用性,致使模型无法适应各种各样的情况,如一个通过其他猫的体态绘制加菲猫的模型,如果过拟合了,如果数据集只有真实的猫,那么模型就只能从真实的猫来绘制加菲猫,换成HelloKity模型就绘制不出来了。
但是对于人物模型来说,尤其是二次元人物Lora,人物特征就是和服装,发型发色等绑定的,这种情况适当的过拟合又是有好处的,能够很容易的还原人物特征。
然而如果这个二次元人物又有换装的需要,那么过拟合又会影响到泛用性,此时过拟合又是有坏处的。
所以过拟合的好坏应该视情况而论。
训练步数
训练步数就是在使用powershell训练时这里显示的数字:

训练步数 = [epoches] × [图片数] × [图片重复次数] ÷ [batch size]
epoches和batch size是训练脚本中对应参数设置的值,图片重复次数是训练文件夹下划线前的数字,具体可以看第三小节Lora。
1.Checkpoint
后续更新计划
2.Lora
Lora模型可以说是最好用的微调模型了,C站上大家分享的大都是Lora模型,对于想要AI绘制特定的人物,服装或者画风时,训练自用Lora是一个很不错的方式。
训练Lora前我们应该充分的了解Lora的工作原理,以便更好的掌控Lora的配置细节。
Lora模型的训练主要基于Lora-Script。
安装Lora-Script
Lora-Script库地址:Akegarasu/lora-scripts: LoRA training scripts use kohya-ss’s trainer, for diffusion model.;
原生的库是国外大神制作的,里面是全英文,对于一些配置的使用还是会有些不便,这里推荐使用秋叶大佬修改过的版本,大佬对训练脚本的一些配置作了中文注释。
可以到秋叶大佬的视频地址出下载:【AI绘画】最佳人物模型训练!保姆式LoRA模型训练教程 一键包发布。
然后我们需要知晓几个文件夹和文件的作用:
- output:输出文件夹,训练好的模型和保存的中间模型都存在这;
- sd-models:放置基础模型的地方,基础模型就是训练lora所使用的checkpoint模型;
- train:用于存放训练数据的文件夹,没有这个文件夹的话,要手动创建;
- venv:lora-script的运行环境配件,在配置运行环境时,由lora-script程序自动生成;
- intall.ps1:一键配置运行环境的powershell脚本,如果使使用秋叶的整合,还有一个使用国内镜像源的intall-cn.ps1脚本;
- train.ps1:一键训练模型脚本;
配置运行环境
Lora-Script依赖python 3.10.8和git,通过第二章的本地部署,这两个环境应该是已经安装好了的。
然后右键intall.ps1选择使用PowerShell运行,脚本会自动为我们安装好程序的依赖。
这个过程中我有碰到xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl安装不上的问题,我是直接从网上去下了一个同版本的whl文件到本地,手动安装解决的。
文件我也自己上传百度云了:https://pan.baidu.com/s/1C5tEo-LdS2n_1smYlEIjfg?psw=4unx
当然还有一种方法,可以拷贝webui的venv\Lib\site-packages\xformers文件夹到lora-scripts\venv\Lib\site-packages目录。
整理训练数据集
首先我们需要明确一个要点,训练使用的数据集的图片的质量决定了AI出图时的图片质量上限,所以对于数据集的整理应尽可能的保证完整,如我们要训练一个人物,那么数据集应尽可能包含这个人物各个角度的图片,各种景深的图片(特写,近景,中景,远景等),各种姿势的图片,对于训练人物还可以包含一些局部特写图片,如脸部特写,服饰特写,腿部特写等,尽量减少重复的或高度相似的图片,以避免过拟合。
对于数据集中图片的数量没有明确规定数量的上下限,广大网友的经验是20-50左右为宜。
图片的尺寸也有要求,不是什么分辨率的都可以用的,图片的分辨率必须是64的倍数,并且不宜超过1024,因为Stable Diffusion 1.5的底模基本都是使用512x512尺寸的图片训练的,这使得AI在绘制1024x1024图片时的效果很差,所以当我们的训练图片超过1024x1024之后,不仅不会对训练效果有什么提升反而会成倍的提升训练时长,当然图片也不能过小,最小不要小于512x512,太小的图片包含的特征信息太少,AI将很难学习到图片中的特征。网上总结的比较优质的图片尺寸是512、768和1024,可以证据自己的显卡配置选择不同的尺寸。
在webui的训练/图像预处理选项卡已经为我们提供了图片的批量裁剪功能,可以批量的修改图片到指定分辨率。

视情况勾选创建镜像副本,程序在处理图片时将为每一张图片创建一个水平翻转过的镜像图片,一般在图片数据较少或缺乏某个角度图片时使用,以增加图片数量,完善数据集;
勾选自动交点裁剪,程序会自动判断画面主体,以画面主体为中心修改图片分辨率,可以有效的避免在裁剪图片时将画面主体裁碎;
最后两个自动打标的选项不建议勾选,webui的自动打标识别出来的提示词不是很准确,推荐使用Tagger插件打标,图片打标将在后面的章节介绍。
图片处理好之后,就可以将图片集放到对应的文件夹下了。
在train文件夹下新建一个以模型名命名的文件夹,比如我训练的模型我取名为bocai,那么我的文件夹就命名为bocai,这不是必须的,只是为了规范。
在bocai文件夹下新建若干以[数字]_[概念]格式命名的文件夹,数字代表AI在学习这些图片时的重复次数,概念就是这个文件夹下的图片代表的对象,比如我们想让AI学习唐装的样式,那么文件夹就可以命名为8_tanzhuang,tanzhuang这个词也将会作为我们将来使用训练出来的Lora控制AI绘制唐装时需要使用的触发提示词,对于下划线前的数字网上还没有明确得出设置的标准,一般来说根据文件夹放置图片的数量设置为4~8左右,具体多少图片设置多少的重复次数,目前网上没有明确的标准,根据经验就是根据概念文件夹内放置的图片数量占总图片数量的百分比来设置,最少的设置成4最多的设置成8。AI在学习图片特征时,图片数量很少而重复次数很高的话,AI就会反复学习少量的图片中的特征,使得AI在绘制图片时很难跳出这些图片的约束,而图片数量多设置重复次数高是因为图片数量多时承载的信息量也大,AI要学习图片中的特征就要多学几次,现象上和人的学习有点类似。
训练时AI会依次学习bocai文件下的若干特征数据集。
正则化数据
正则化是一种用来防止数据过拟合的技术,通过对参数进行惩罚来减少模型的复杂度,提高模型的泛化性,正则化是机器学习中监督学习的一种方法。
正则化数据可以将AI已经学过的旧知识与要学习的新知识分隔开,使之互不影响,这在训练画风Lora、功能性Lora这些对模型泛化性有着极高要求的Lora时是十分必要的,对于训练人物Lora则没有那么必要了。
在train目录下新建一个reg目录,在reg目录下新建一个和训练概念同名的文件夹,如我们训练一个根据真实猫绘制卡通加菲猫的功能性Lora,那么我们应该在train目录下新建一个加菲猫的概念文件夹,加入命名为8_JiafeiCat,并根据图片数量设定重复次数并放置40张各种体态的加菲猫图片数据到文件夹中,然后再在train目录新建reg文件夹,在reg文件夹下新建一个同名文件夹6_JiafeiCat,设定的重复次数应略少于概念重复次数,并向文件夹中放入大于等于概念文件夹图片数量的正则图片,正则图片是和训练的概念—加菲猫相似但有不同的对象,如HelloKity,真实的猫等,正则图片可以从网上找,也可以直接从基础模型生成。
如果我们要使用正则化数据进行模型训练,那么在训练参数中我们需要在训练参数中指定正则化路径,如果路径为空则表示不启用,然后我们可以通过--prior_loss_weight参数(训练脚本中的一个参数)来控制正则化数据对概念的影响程度,默认为1表示100%影响。
提示词打标
图片数据处理好之后,我们还需要处理提示词数据,每一张数据图片都应该有一个提示词文本,提示词文本描述对应图片包含的具体特征。
这里推荐使用Tagger插件来打标,Tagger插件从图片反推提示词要比Webui自带的功能要更准确。插件的用法就不累述了,如果装了汉化插件的话,各个选项的功能基本看名字就知道怎么用了。需要留意在附加标签中添加我们需要触发Lora功能的提示词。
为每张图片生成了tag文本之后,我们需要对文本进行整理,这一步操作主要是删去一些我们需要让AI学习的特征和补全一些插件没有识别上的特征,比如,我们要训练一个明日香这个角色的人物Lora,那么在tag文本中我们需要删除与红色的紧身衣、橘黄色的头发、眼罩这些有着角色明显特征的提示词,这样AI学习的时候才能将这些特征学习到Lora模型中,否则AI就会将这些特征学习到对应的特征提示词中,这种情况我们使用这个Lora时只要输入红色的紧身衣,AI就会绘制明日香的衣服,这样Lora的泛化性就很差,当然如果不重视泛化性也可以不删。如果提示词文本中插件没有识别到图片中的一些表情或姿势特征,我们应该手动补全,不然AI也会把这些表情和姿势特征学习进入模型中,AI在使用模型绘制人物时会有极大的可能出现表情、姿势固定的问题。
当然对于单概念模型,即一个Lora只训练一个角色的一种形象,触发词就不是必须的了,但对于一个Lora训练了多个角色或一个角色的多种形象时,触发词就很有必要了,触发词可以使在使用Lora时对这些概念的掌控性更强,并且可以使用触发词来控制权重。
提示词文本中描述特征的提示词越多,AI学习到Lora中的特征就越少,使用Lora还原对象时就需要更多的提示词,模型的泛化性就越高,相对的,提示词文本中描述特征的提示词越少,AI学习到Lora中的特征就越多,使用Lora还原对象时需要的提示词也就越少,模型泛化性就越低。
对于删除提示词,我们可以直接通过文本手动删除,不过更推荐使用数据集标签编辑器这个插件来批量操作。

在数据集目录输入带有提示词文本的数据集目录路径,点击载入就可以读取所有的提示词到Select Tags栏下,然后到Batch Edit Captions/移除功能框,勾选想要移除的提示词后点击Remove selected tags,然后点击Save all changes保存修改,如果勾选了backup original text file则会在原目录下新增原提示词文本的备份。
配置训练参数
训练参数指就是train.ps1脚本中的一些参数,我们一个个看:
-
pretrained_model:设置我们训练lora所使用的基础模型,可以是官模,也可以是基于官模训练的定制化模型;
-
train_data_dir:设置训练数据集的路径;
-
reg_data_dir:设置正则化数据路径;
-
resolution:设置图片的分辨率;
-
batch_size:设置AI在一次学习过程中同时学习的图片数量,根据自己的显存大小设置,数值越大吃的显存越多;
-
max_train_epoches:epoches是机器学习中的一个重要概念,一次epoches表示AI对整个数据集进行一次完整的训练,如我们设置成10那么AI就会对我们的数据集进行10次完整的训练,一般来说epoches数越大,模型的训练效果越好,训练所需要的时长也越长,但epoches数会影响到训练步数,过大也会导致数据过拟合;
-
save_every_n_epochs:设置每隔多少次epoches保存一次模型,主要用于对比不同epoches下的模型效果。
-
network_dim:设置AI学习的深度,就是AI在一张图片中学习的特征数量,会直接影响输入数据的维度,从而很大程度的影响lora的质量,数值越大,输出的lora模型也就越大。dim数值不宜过大也不宜过小,过大容易照成过拟合,过小则学习的特征不够,效果不佳,有人说32很合适,也有人说128很合适,个人认为应该根据自己的实际情况来调整。
-
network_alpha:这个数值是用来调整正则化程度的,值越大,正则化程度越高,模型复杂度就越小,模型泛化性越强,一般设置成和network_dim一样的数值,或者使用小数来使用百分比的形式,使用小数的话一般设置成0.25~0.5。
-
train_unet_only:是否只训练U-Net;
-
train_text_encoder_only:是否只训练文本编码器;
train_unet_only和train_text_encoder_only两个选项除非有修改代码或者有预先训练的需求,一般都设置为0,不启用。
-
noise_offset:设置AI在训练是往训练结果中添加的噪声偏移量,用来改良在生成非常暗或非常亮的图片时的生成效果;
-
keep_tokens:是否打乱AI读取提示词文本中提示词的顺序,打乱提示词的读取顺序有利于提高模型的泛化性,设置数值表示在第几个提示词之后开始打乱读取顺序;
-
lr:设置训练lora模型的学习率,学习率是指控制模型在每次迭代中更新权重的步长。学习率的大小对模型的训练和性能都有重要影响。如果学习率设置得太小,模型收敛速度会很慢,训练时间会变长;如果学习率设置得太大,模型可能会在训练过程中出现震荡,甚至无法收敛。默认1e-4是调试过的数值;
-
unet_lr:设置训练U-Net的学习率;
-
text_encoder_lr:设置训练文本编码器的学习率;
-
lr_scheduler:设置学习率调度器,学习率调度器是一种在模型训练的过程中进行动态调节学习率的技术,lora-script已经为我们内置了
linear-学习率线性下降;
cosine-余弦退火,使用余弦函数来逐渐降低学习率;
cosine_with_restarts-余弦退火重启,在cosine的基础上没过几个周期重启一次;
polynomial-使用多项式函数来调整学习率;
constant-学习率保持恒定不变;
constant_with_warmup-恒定预热,在开始时学习率会略微增大,然后逐渐退回学习率恒定不变;
这六个调度器。
-
lr_warmup_steps:在学习率调度器启用constant_with_warmup时生效,设置恒定预热调度器在开始学习时学习率增大的幅度,一般设置成总步数的1/10或1/20的数值。例如总步数是1000,就设置成50或者100;
-
lr_restart_cycles:在学习率调度器启用cosine_with_restarts启用,设置重启的间隔;
-
output_name:输出模型的名称;
-
save_model_as:输出模型的格式,可以是ckpt,pt和safetensors,建议都使用safetensors安全格式;
-
network_weights:设置是否需要重已有的Lora模型继续训练,需要则设置成Lora模型的路径,不需要则设置成空字符;
-
min_bucket_reso:设置训练数据集中图片的最小分辨率;
-
max_bucket_reso:设置训练数据集中图片的最大分辨率;
min_bucket_reso和max_bucket_reso需要根据自己整理的数据集的情况设置,设置不对训练时会报错;
-
persistent_data_loader_workers:是否保留加载训练集的worker,减少每次epoch的停顿,显存不高的不建议启用,容易爆显存;
-
clip_skip:设置文本解析时跳过的神经网络的层数,一般训练三次元lora设置成1,训练二次元lora设置成2,具体的作用可以看这里:clip_skip到底是什么? ·自动1111 稳定扩散 ·;
-
use_8bit_adam:是否启用8bit优化器,可以在不影响模型精度的情况下大幅减少显存的使用量节,默认启用;
-
use_lion:是否启用Lion优化器,可以让模型更快的收敛,具体可以看这里:Google新搜出的优化器Lion:效率与效果兼得的“训练狮”;
-
enable_locon_train:启用LoCon训练,LoCon是由Lora演变而来的改进模型,具体可以看这里:LoCon相对于LoRA的改进,但是现在Lora模型使用得更广泛,所以一般不启用;
-
conv_dim:设置训练LoCon模型时的学习率;
-
conv_alpha:设置训练LoCon模型时的正则化程度;
-
–prior_loss_weight:设置正则化数据对概念的想象程度。
把参数按照自己的需求设置好,就可以右键train.ps1使用powershell运行,来训练模型了。
这些参数的设置对于Lora类型,风格强度,使用场景等均有不同设置,目前网上没有明确的设置标准,大都需要根据经验设置,通过不断的测试来确定一组效果比较好的参数组。
后续更新计划
杰克艾米立 - YouTube
人物Lora训练
人物的lora训练和前面的lora训练参数基本基本一致,需要关注的是数据集,如果想要Lora训练出来的人物有较好的泛用性,那么训练集中,人物应尽可能多的多几套服装、多几个角度,多集中动作,多余一些比较重要的配饰应该有特写图片,然后人物图片数据集应该将人物单独扣出来,去除背景,并使用白色背景填充,这样在出图时不会受到数据集背景的影响。
服装Lora训练
画风Lora训练
功能性Lora训练
3.Embedding
【AI绘画】Embedding & Hypernetwork使用及训练(Stable Diffusion)(自用) - 哔哩哔哩 (bilibili.com)
stable diffusion训练embedding和hypernetwork详解_哔哩哔哩_bilibili
4.Hypernetworks
5.AesthticGradients
十一、脚本开发
十二、插件开发
十三、ComfyUI
ComfyUI是最近新出的一款stable diffusion操作UI,特点是可以使用节点的形式对出图流程进行精确控制,作者制作这款UI的初衷就是可以使用stable diffusion进行复杂的工作流,目前ComfyUI还在快速的迭代中。
我实际使用之后的感受是,ComfyUI出图是真的快,我的3080ti显卡使用ComfyUI批量出8张2K图只需要几秒钟,换做WebUI,起码得半分钟。
1.本地部署
环境部署
直接使用git克隆ComfyUI库到本地或下载zip包解压到本地,相比于WebUI,ComfyUI就小了很多,到我写这个章节的日期为止,整个ComfyUI库只有6.75MB。
ComfyUI依赖python3.10环境,作者有在readme中提及,目前ComfyUI不支持python3.10以上环境,这里我们可以直接使用WebUI的虚拟环境中的Python就好了,正好前面部署WebUI时使用的python是3.10.6。
在ComfyUI目录中在地址栏输入cmd,回车就可以直接在ComfyUI目录启动cmd
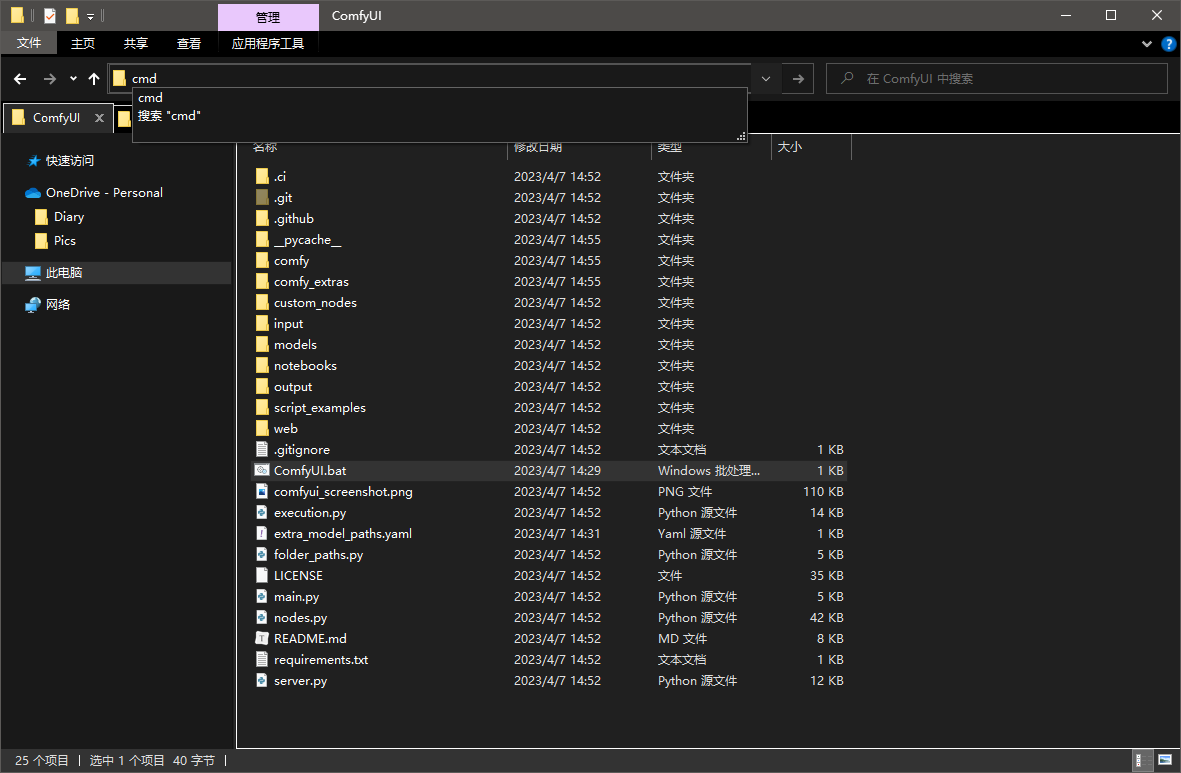
进入WebUI的1venv/Scripts目录找到python.exe拖入cmd,然后运行main.py脚本就可以运行ComfyUI服务了。
E:\WebUI\venv\Scripts\python.exe main.py
在浏览器打开控制台给的地址,就可以进入ComfyUI了。
为了启动方便,我们可以写一个.bat脚本写入上面这条指令,下次启动就可以直接双击.bat脚本运行。
不过现在UI还是不能出图的,我们还需要安装一些依赖
安装依赖项
ComfyUI需要使用torch、xfirmers工具库,我们已经在WebUI中安装过这些库了,所以可以不用再安装,按照前面的运行方式我们已经使用了WebUI的虚拟环境运行ComfyUI,所以这些库ComfyUI都已经识别上了。
如果没有安装WebUI的话,通过cmd使用这个命令安装
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 xformers
这是英伟达显卡的版本,AMD显卡安装这个版本
https://download.pytorch.org/whl/rocm5.4.2
运行之后,需要下载2.6G的工具库。
然后运行
pip install -r requirements.txt
安装ComfyUI的依赖。
自己安装torch和xformers的话经常会和cuda出现各种版本问题,需要自己去调,所以有安装WebUI的话建议还是直接使用WebUI的虚拟环境无脑运行。
配置模型
对于已经安装了WebUI的人可以修改ComfyUI根目录下的extra_model_paths.yaml.example文件,
- base_path:设置WebUI的根目录
- checkpoints:设置WebUI的大模型目录
- vae:设置WebUI的VAE目录
- loras:设置WebUI的lora目录
- upscale_models:设置WebUI的放大算法目录
- controlnet:设置controlnet库目录
可以参考我的设置:
#Rename this to extra_model_paths.yaml and ComfyUI will load it
#config for a1111 ui
#all you have to do is change the base_path to where yours is installed
a111:
base_path: E:/WebUI
checkpoints: E:/WebUI/models/Stable-diffusion
configs: E:/WebUI/models/Stable-diffusion
vae: E:/WebUI/models/VAE
loras: E:/WebUI/models/Lora
upscale_models: |
E:/WebUI/models/ESRGAN
E:/WebUI/models/SwinIR
embeddings: E:/WebUI/embeddings
controlnet: E:/WebUI/extensions/sd-webui-controlnet
#other_ui:
# base_path: path/to/ui
# checkpoints: models/checkpoints
设置好之后,将文件重命名为extra_model_paths.yaml,在下次启动时ComfyUI会加载配置文件的模型。
当然我们也可以将模型放到ComfyUI/models目录的对应文件夹下。
2.操作与界面
-
长按鼠标左键:移动视图;
-
单击节点:选中指定节点;
-
双击鼠标左键:打开快捷节点搜索;
-
右键空白视图:跳出右键菜单,右键菜单得根目录只有两个选项:

Add Node:添加节点;
Add Group:添加组,可以为节点打组,这个功能现在还有点鸡肋,可以忽略。
-
按住Ctrl+鼠标左键:框选选区内节点;
-
鼠标放在节点右下角:可以修改节点的大小;
-
右键节点:打开节点菜单,
Properties:
Title:修改节点的名称;
Mode:更改节点的模式,
Resize:重置节点的尺寸到默认值;
Collapse:缩略节点;
Pin:
Colors:更改节点的颜色;
Shapes:更改节点的形状;
-
菜单界面:
在左上角长按左键:拖动菜单;
Queue Prompt:将当前节点的组合任务加入队列;
Extra options:勾选可以启用批量出图;
Queue Front:将当前队列的任务再执行一次;
See Queue:查看队列信息,可以在这里删除指定的任务,以终止图片生成;
See History:查看历史信息;
Save:保存当前页面的节点信息到一个Json文件中;
Load:从Json文件加载页面节点信息;
Refresh:刷新页面;
Clear:清空页面;
Load Default:加载默认页面节点信息;
3.常用节点
由于ComfyUI还处于快速迭代中,节点可能会有变化,这里以撰写这个章节日期:2023.4.7更新的最新版本为例。
打开ComfyUI,UI界面已经
十四、InvokeAI
InvokeAI
十五、扩展阅读
AI绘画Stable-diffusion扩展最新全面使用指南 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/583677438
如何使用AI绘画技术生成360度全景图? (qq.com)
NovelAI模型各参数解析以及对应关系 - 知乎 (zhihu.com)
AI 绘画神器 Stable Diffusion 玩法大测评 - 知乎 (zhihu.com)
【AI绘画模型大全】超全的模型资源汇总! - 知乎 (zhihu.com)
AI绘画第二步,抄作业复现超赞的效果!_托尼不是塔克的博客-CSDN博客
TencentARC/T2I-Adapter: T2I-Adapter (github.com)
精确控制 AI 图像生成的破冰方案,ControlNet 和 T2I-Adapter_创业者西乔的博客-CSDN博客
ControlNet如何为扩散模型添加额外模态的引导信息 - 知乎 (zhihu.com)
扩散模型与受控图像生成-脉络梳理 - 知乎 (zhihu.com)
CLIP, VQGAN, VQGAN-CLIP, Stable-Diffusion - 知乎 (zhihu.com)