BERT 模型由 Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova在BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding中提出。它是一种双向变换器,使用掩码语言建模目标和对包含多伦多图书语料库和维基百科的大型语料库的下一句预测的组合进行预训练。
BERT 旨在通过联合调节所有层中的左右上下文来预训练未标记文本的深度双向表示。因此,预训练的 BERT 模型只需一个额外的输出层即可进行微调,从而为广泛的任务(例如问答和语言推理)创建最先进的模型,而无需大量任务 -具体的架构修改。
BERT 接受了掩码语言建模 (MLM) 和下一句预测 (NSP) 目标的训练。它在预测掩码标记和一般 NLU 方面是有效的,但对于文本生成来说并不是最佳的。
2018年是自然语言处理(NLP)领域中机器学习模型取得重大突破的关键时刻。我们对于如何更好地捕捉单词和句子的潜在含义和关系的概念性理解正在不断演进。同时,NLP社区不断推出令人惊叹的强大组件,这些组件可以免费下载和应用于自己的模型和流程中。这一进展被称为NLP领域的ImageNet时刻,类似于几年前计算机视觉领域机器学习的发展情况。
BERT的发布是其中的一个重要里程碑,被认为是开启了NLP新时代的标志性事件。BERT突破了处理语言相关任务的模型在多个方面的记录。不久之后,BERT模型的代码被开源,并提供了在大规模数据集上预训练的模型版本供下载。这个发展具有重要意义,因为任何想要构建涉及语言处理的机器学习模型的人现在都可以将这个强大的引擎作为现成的组件使用,从而节省了训练语言处理模型所需的时间、精力、知识和资源。
BERT是在NLP社区中出现的许多创新想法基础上构建起来的,这些想法包括但不限于以下几个方面:半监督序列学习(由Andrew Dai和Quoc Le提出)、ELMo(由Matthew Peters以及来自AI2和UW CSE的团队提出)、ULMFiT(由fast.ai的创始人Jeremy Howard和Sebastian Ruder设计)、OpenAI Transformer(由OpenAI研究人员Radford、Narasimhan、Salimans和Sutskever设计)、以及Transformer模型(由Vaswani等人提出)。
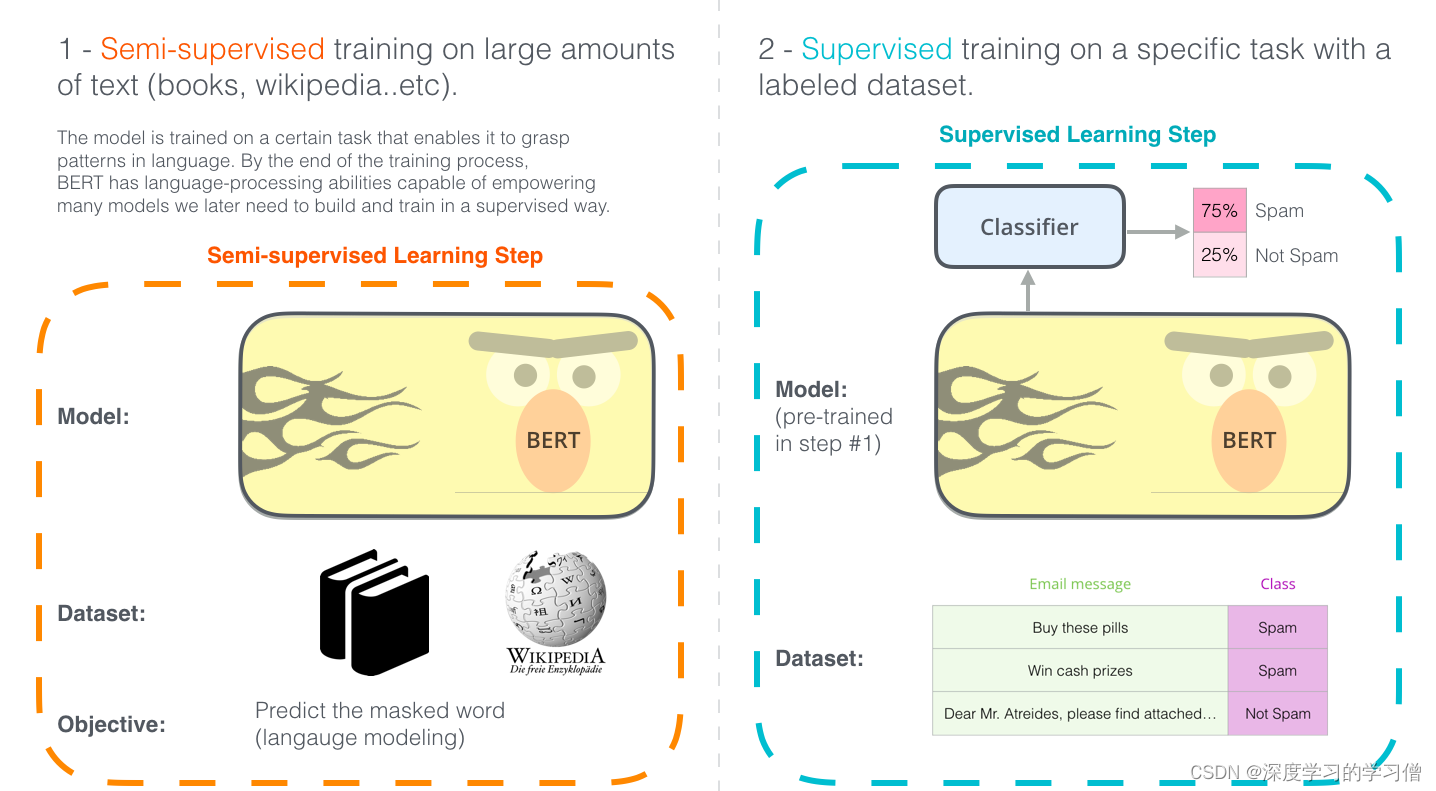
BERT 开发的两个步骤。您可以下载在步骤 1 中预训练的模型(在未注释的数据上训练),只需担心在步骤 2 中对其进行微调。
该论文为 BERT 提供了两种模型大小:

BERT BASE——在大小上与 OpenAI Transformer 相当,以便比较性能
BERT LARGE——一个大得离谱的模型,达到了论文中报道的最先进的结果
BERT 基本上是经过训练的 Transformer 编码器堆栈。现在是指导您阅读我之前的文章The Illustrated Transformer 的好时机,其中解释了 Transformer 模型——BERT 的基本概念以及我们接下来将讨论的概念。
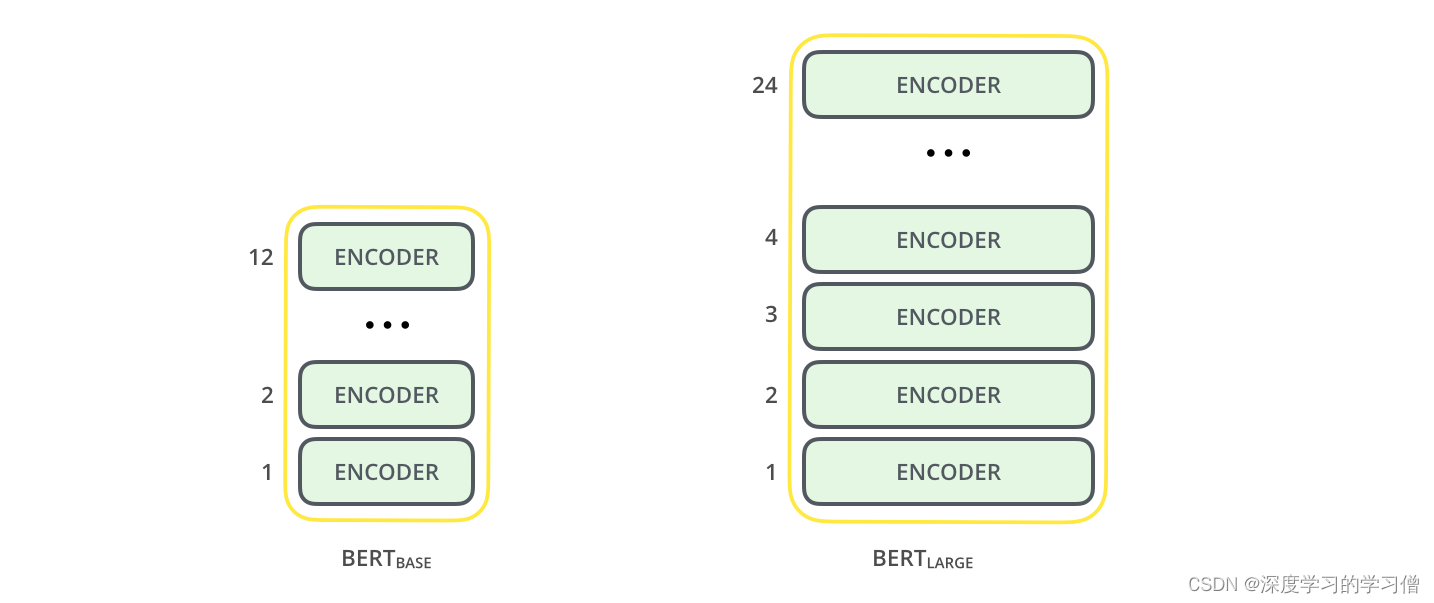
两种尺寸的 BERT 模型都有大量的编码器层(本文称之为 Transformer Blocks)——Base 版本有 12 个,Large 版本有 24 个。与初始论文中 Transformer 参考实现中的默认配置(6 个编码层、512 个隐藏单元、和 8 个注意力头)。
模型输入
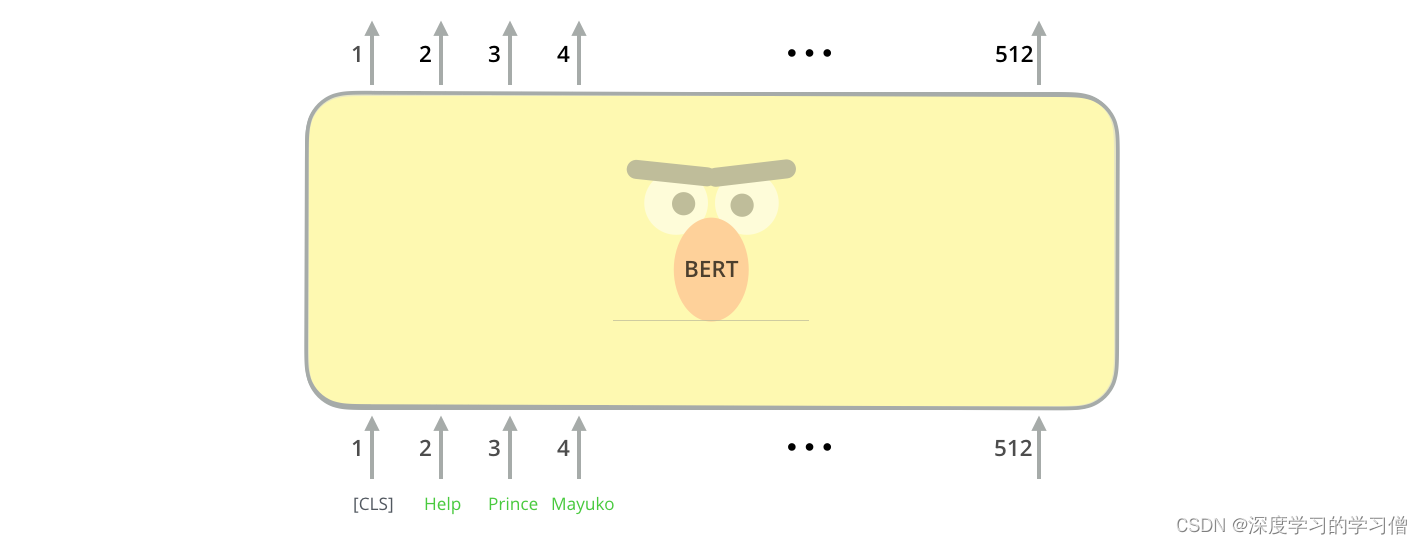
第一个输入令牌提供了一个特殊的 [CLS] 令牌,原因稍后会变得明显。这里的 CLS 代表分类。
就像 transformer 的普通编码器一样,BERT 将一系列单词作为输入,这些单词不断向上流动。每一层都应用自注意力,并通过前馈网络传递其结果,然后将其传递给下一个编码器。
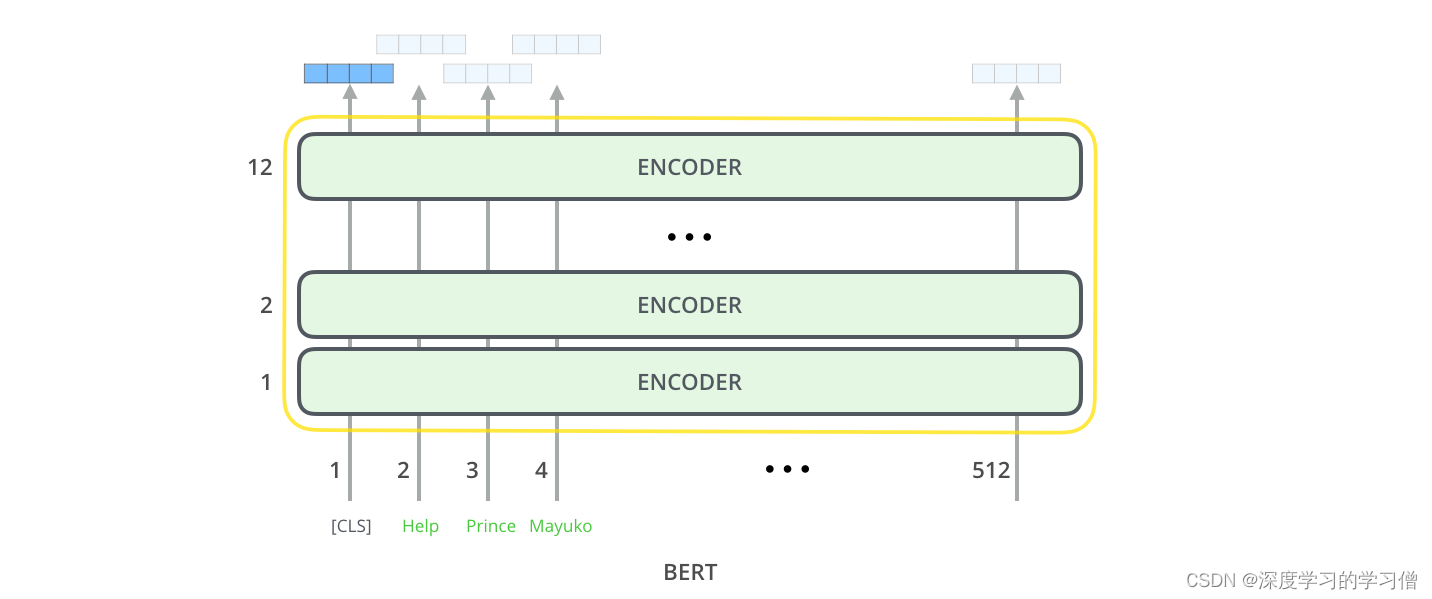
在架构方面,到目前为止,它与 Transformer 完全相同(除了大小,这只是我们可以设置的配置)。正是在输出中,我们首先开始看到事情是如何分歧的。
模型输出
每个位置输出一个大小为hidden_ size 的向量(在 BERT Base 中为 768)。对于我们上面看到的句子分类示例,我们只关注第一个位置的输出(我们将特殊的 [CLS] 标记传递给)。
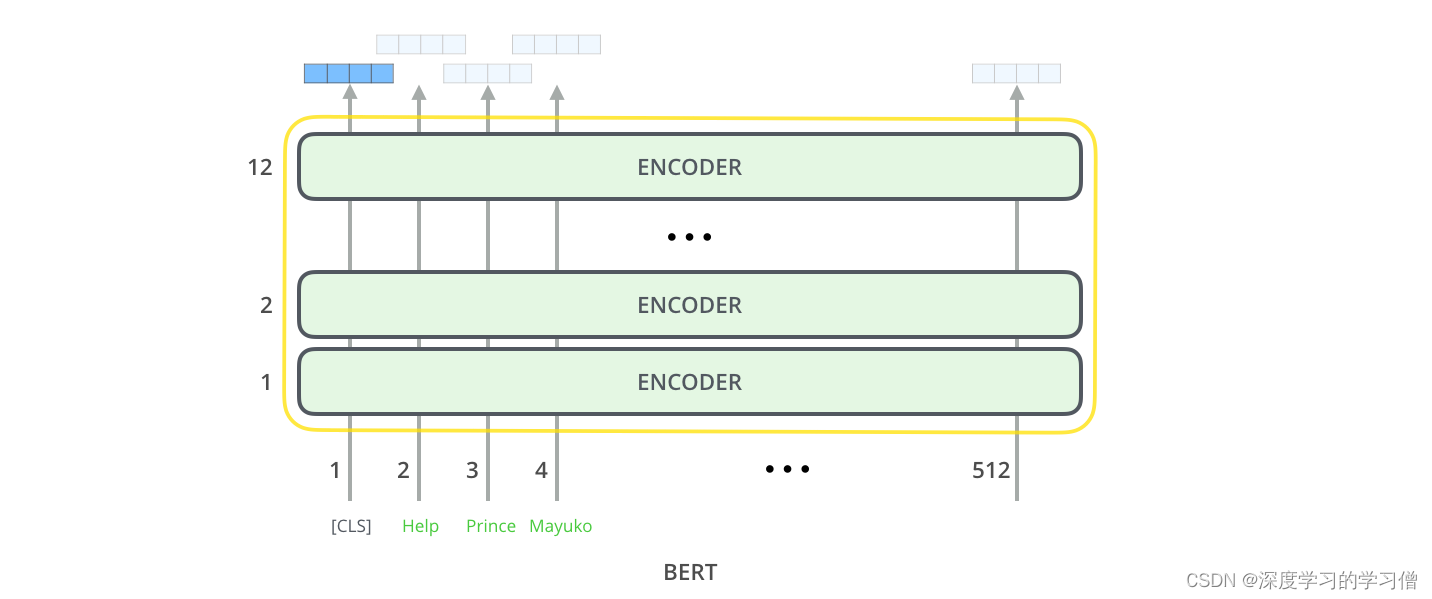
该向量现在可以用作我们选择的分类器的输入。该论文仅使用单层神经网络作为分类器就取得了很好的效果。
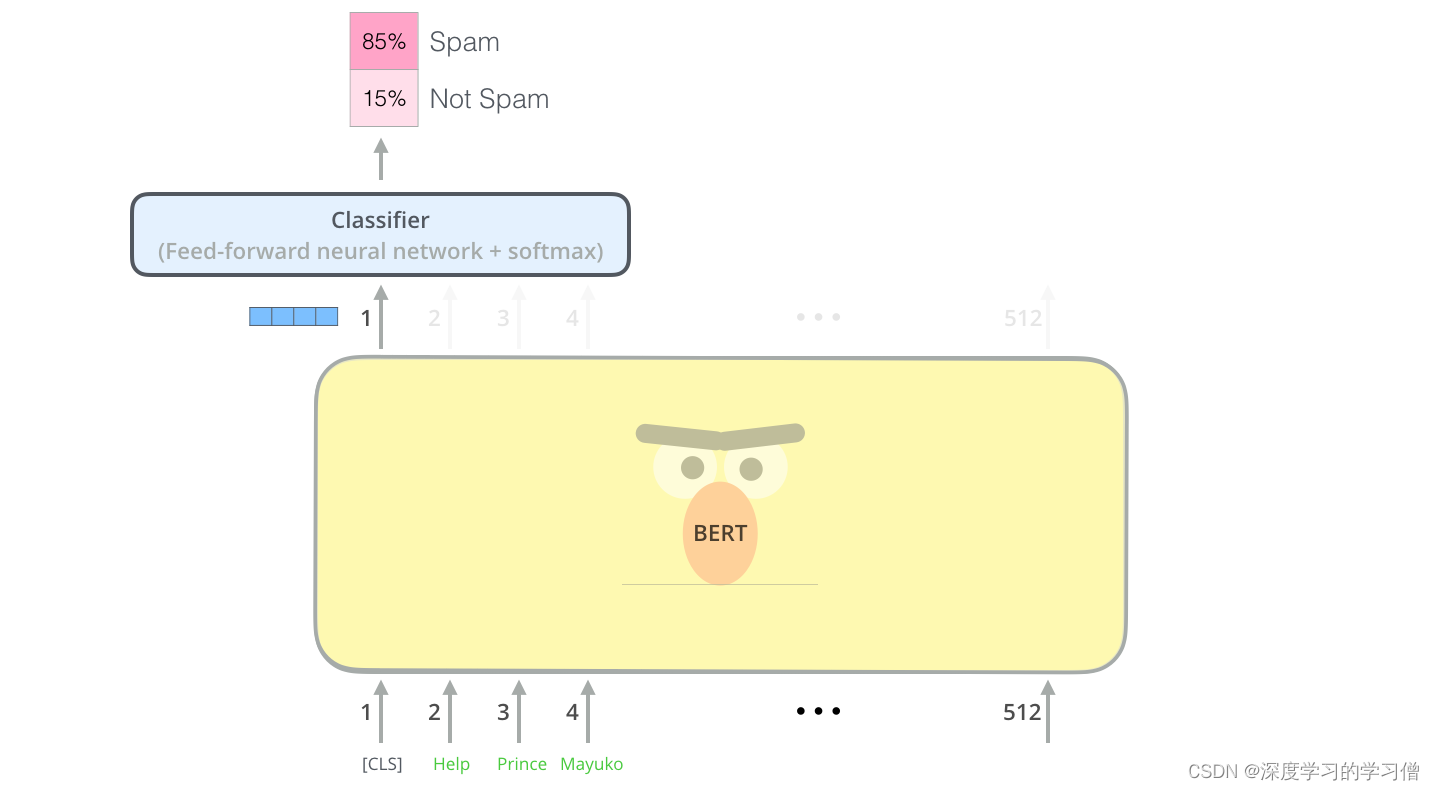
如果你有更多标签(例如,如果你是一个电子邮件服务,用“垃圾邮件”、“非垃圾邮件”、“社交”和“促销”标记电子邮件),你只需调整分类器网络以获得更多输出神经元然后通过softmax。
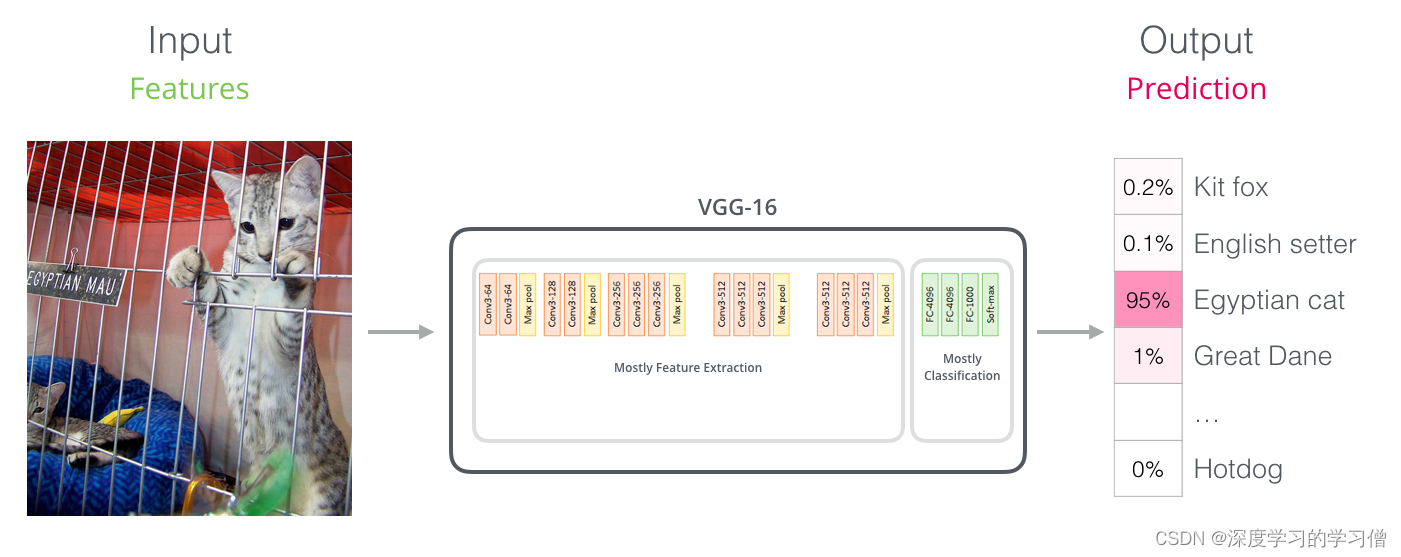
与卷积网络的相似之处
对于那些有计算机视觉背景的人来说,这种向量切换应该让人想起像 VGGNet 这样的网络的卷积部分和网络末端的全连接分类部分之间发生的事情。
嵌入的新时代
这些新的发展带来了单词编码方式的新转变。到目前为止,词嵌入一直是领先的 NLP 模型处理语言的主要力量。Word2Vec 和 Glove 等方法已广泛用于此类任务。在指出现在发生的变化之前,让我们回顾一下它们是如何使用的。
词嵌入回顾
对于机器学习模型要处理的单词,它们需要模型可以在计算中使用的某种形式的数字表示。Word2Vec 表明我们可以使用向量(数字列表)以捕获语义或意义相关关系的方式正确表示单词(例如,判断单词是否相似或相反的能力,或者一对单词像“Stockholm”和“Sweden”之间的关系与“Cairo”和“Egypt”之间的关系相同)以及句法或基于语法的关系(例如“had”和“has”之间的关系是与“是”和“是”之间的相同)。
该领域很快意识到使用在大量文本数据上预先训练的嵌入而不是在通常是小数据集的模型上训练它们是一个好主意。因此,可以下载单词列表及其通过 Word2Vec 或 GloVe 预训练生成的嵌入。这是单词“stick”的 GloVe 嵌入示例(嵌入向量大小为 200)

单词“stick”的 GloVe 词嵌入 - 一个包含 200 个浮点数的向量(四舍五入到两位小数)。它持续了 200 个值。
ELMo:上下文很重要
如果我们使用这个 GloVe 表示,那么无论上下文是什么,单词“stick”都将由这个向量表示。“等等”一些 NLP 研究人员说(Peters 等人,2017 年,McCann 等人,2017 年,还有Peters 等人,2018 年在 ELMo 论文中),“ stick ”有多个含义取决于它的使用位置。为什么不根据它所使用的上下文给它一个嵌入——既捕获该上下文中的单词含义,又捕获其他上下文信息?”。因此,语境词嵌入诞生了。
语境词嵌入可以根据单词在句子上下文中的含义赋予不同的词嵌入。另外,RIP 罗宾·威廉姆斯
ELMo 不是为每个单词使用固定的嵌入,而是在为其中的每个单词分配一个嵌入之前查看整个句子。它使用针对特定任务训练的双向 LSTM 来创建这些嵌入。
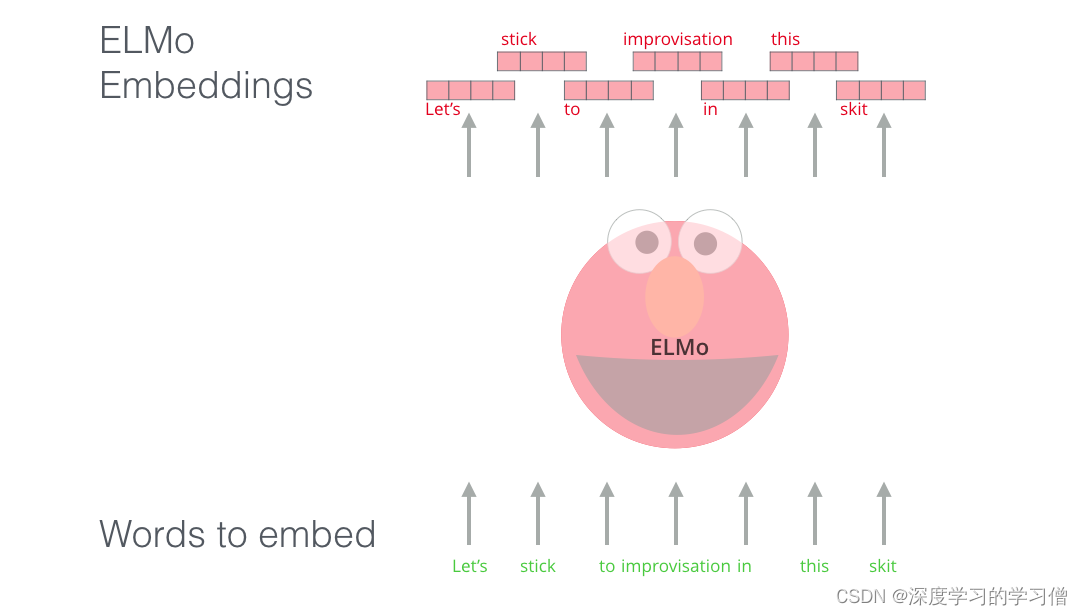
ELMo 在 NLP 的背景下向预训练迈出了重要一步。ELMo LSTM 将使用我们数据集的语言在海量数据集上进行训练,然后我们可以将它用作其他需要处理语言的模型的组件。
ELMo 的秘密是什么?
ELMo 通过接受训练来预测单词序列中的下一个单词,从而获得了对语言的理解——一项称为语言建模的任务。这很方便,因为我们拥有大量文本数据,这样的模型无需标签即可从中学习。
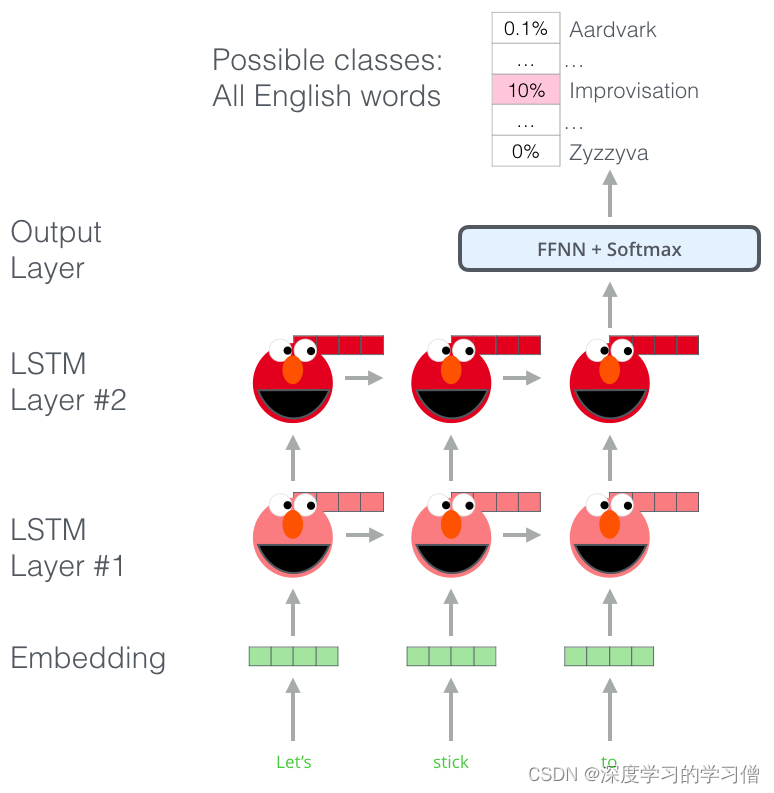
ELMo 预训练过程中的一个步骤:给定“Let’s stick to”作为输入,预测下一个最有可能的词——语言建模任务。当在大型数据集上进行训练时,模型开始识别语言模式。在这个例子中,它不太可能准确地猜出下一个词。更实际的是,在诸如“hang”之类的词之后,它会为“out”(拼写为“hang out”)之类的词分配比“camera”更高的概率。
我们可以看到每个展开的 LSTM 步骤的隐藏状态从 ELMo 的脑袋后面突出。完成预训练后,这些在嵌入过程中会派上用场。
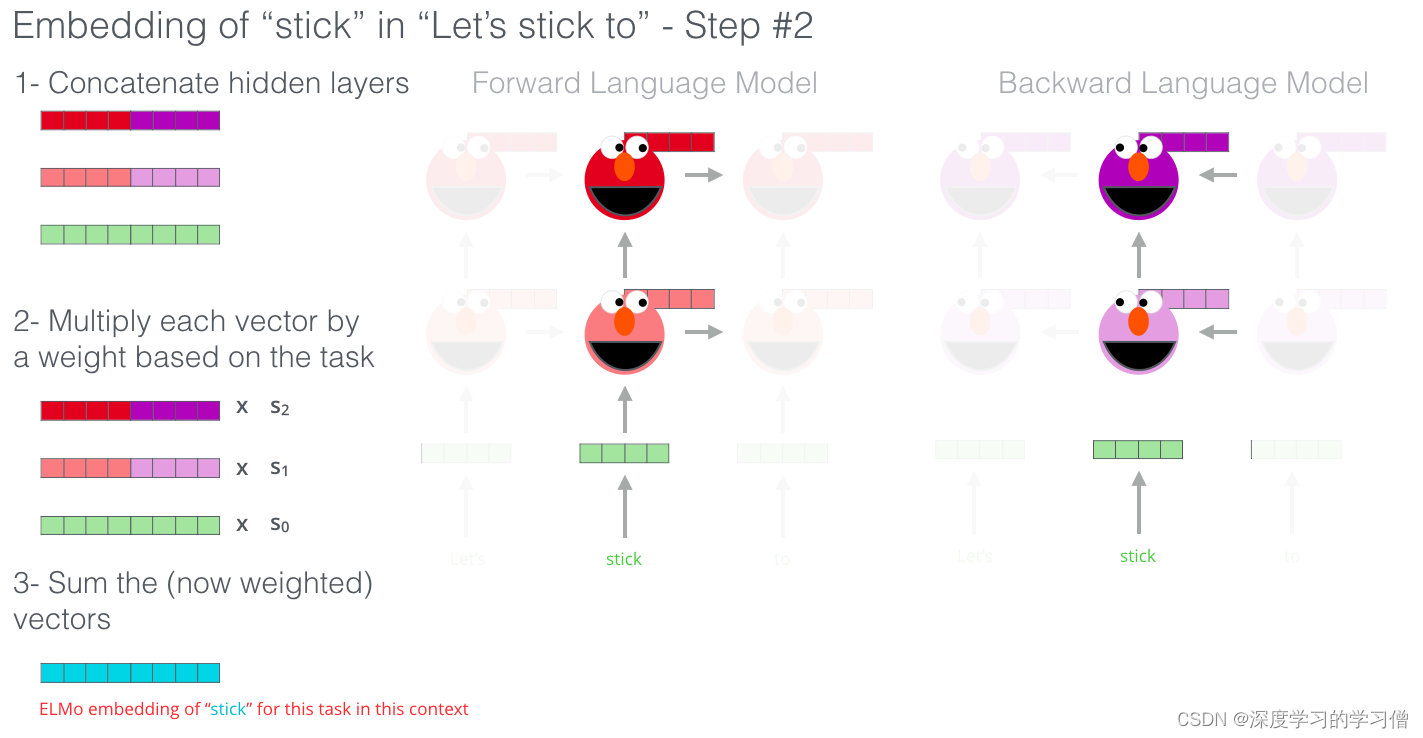
ELMo 实际上更进一步,训练了一个双向 LSTM——这样它的语言模型不仅能感知下一个词,还能感知前一个词。
ELMo 上 很棒的幻灯片
ELMo 通过以某种方式(连接后加权求和)将隐藏状态(和初始嵌入)组合在一起,提出了上下文嵌入。
ULM-FiT:确定 NLP 中的迁移学习
ULM-FiT 引入了一些方法来有效地利用模型在预训练期间学到的很多东西——不仅仅是嵌入,也不仅仅是上下文嵌入。ULM-FiT 引入了一个语言模型和一个过程,可以针对各种任务有效地微调该语言模型。
NLP 终于有一种方法可以像计算机视觉一样进行迁移学习。
Transformer:超越 LSTM
Transformer 论文和代码的发布,以及它在机器翻译等任务上取得的成果,开始让该领域的一些人认为它们是 LSTM 的替代品。Transformer 比 LSTM 更好地处理长期依赖性这一事实使情况更加复杂。
Transformer 的 Encoder-Decoder 结构使其非常适合机器翻译。但是你会如何用它来进行句子分类呢?您将如何使用它来预训练可以针对其他任务进行微调的语言模型(下游任务是该领域所说的那些利用预训练模型或组件的监督学习任务)。
OpenAI Transformer:预训练用于语言建模的 Transformer 解码器
事实证明,我们不需要整个 Transformer 来采用迁移学习和 NLP 任务的微调语言模型。我们可以只使用Transformer的解码器。解码器是一个不错的选择,因为它是语言建模(预测下一个词)的自然选择,因为它是为了掩盖未来的标记而构建的——当它逐字生成翻译时,这是一个很有价值的特性。

OpenAI Transformer 由来自 Transformer 的解码器堆栈组成
该模型堆叠了十二个解码器层。由于此设置中没有编码器,因此这些解码器层不会像 vanilla transformer 解码器层那样具有编码器-解码器注意力子层。然而,它仍将具有自我注意层(被屏蔽,因此它不会在未来的标记处达到峰值)。
使用这种结构,我们可以继续在相同的语言建模任务上训练模型:使用大量(未标记)数据集预测下一个单词。就是,把7000本书的课文丢给它,让它学!书籍非常适合此类任务,因为它允许模型学习关联相关信息,即使它们被大量文本分隔——例如,当您使用推文或文章进行训练时,您无法获得这些信息.
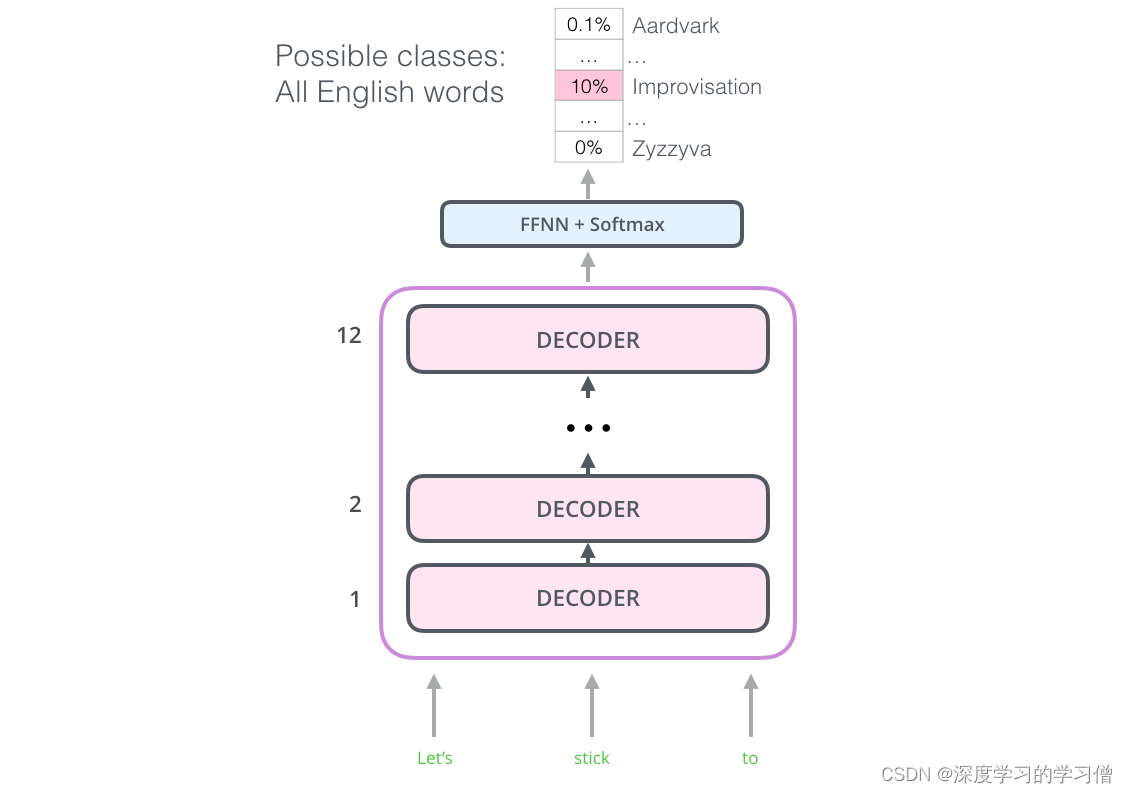
OpenAI Transformer 现在已准备好接受训练,以预测由 7,000 本书组成的数据集上的下一个单词。
将学习迁移到下游任务
现在 OpenAI transformer 已经过预训练并且其层已经过调整以合理处理语言,我们可以开始将它用于下游任务。让我们首先看一下句子分类(将电子邮件分类为“垃圾邮件”或“非垃圾邮件”):
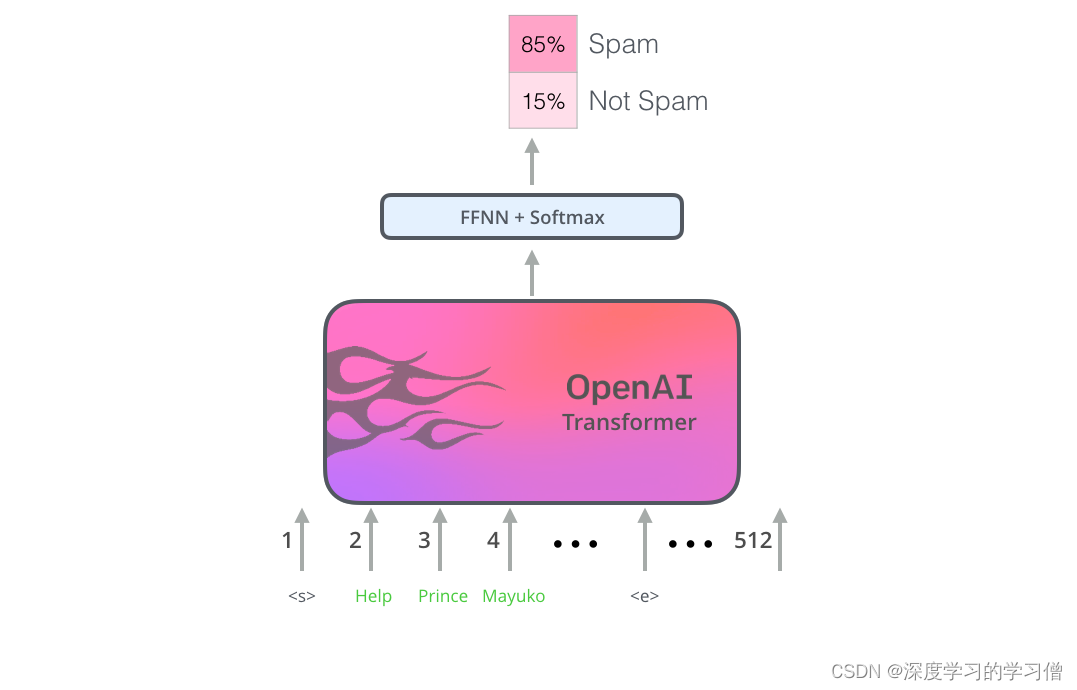
OpenAI 论文概述了一些输入转换来处理不同类型任务的输入。论文中的下图显示了执行不同任务的模型结构和输入转换。
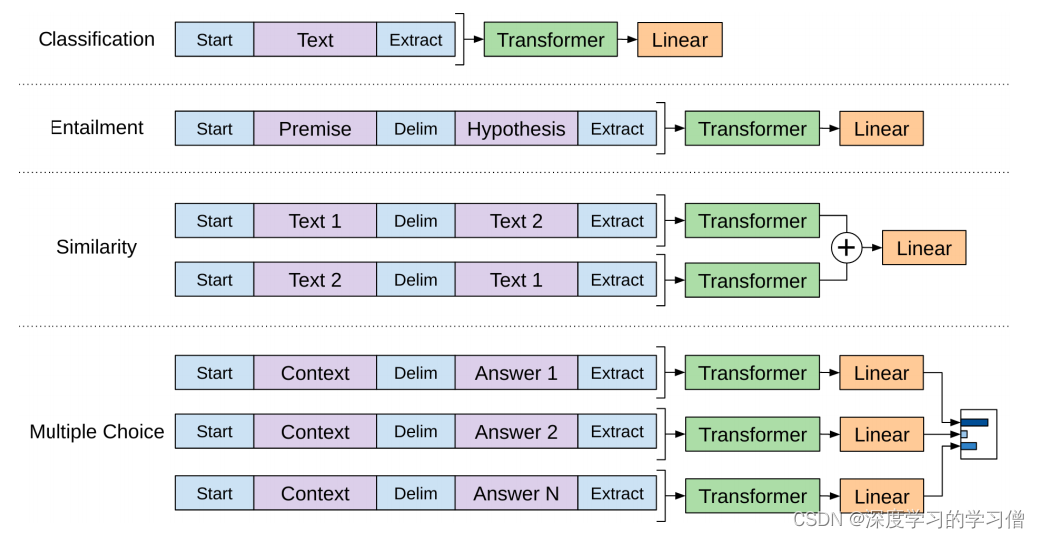
这不是很聪明吗?
BERT:从解码器到编码器
openAI Transformer 为我们提供了一个基于 Transformer 的微调预训练模型。但是在从 LSTM 到 Transformers 的转变过程中缺少了一些东西。ELMo 的语言模型是双向的,但 openAI transformer 只训练前向语言模型。我们能否构建一个基于Transformer的模型,其语言模型既向前看又向后看(用技术术语来说——“以左右语境为条件”)?
“拿着我的啤酒”,R 级 BERT 说。
掩码语言模型
“我们将使用Transformer编码器”,BERT 说。
“这太疯狂了”,厄尼回答说,“每个人都知道双向调节会让每个词在多层上下文中间接地看到自己。”
“我们将使用MASK”,BERT 自信地说。
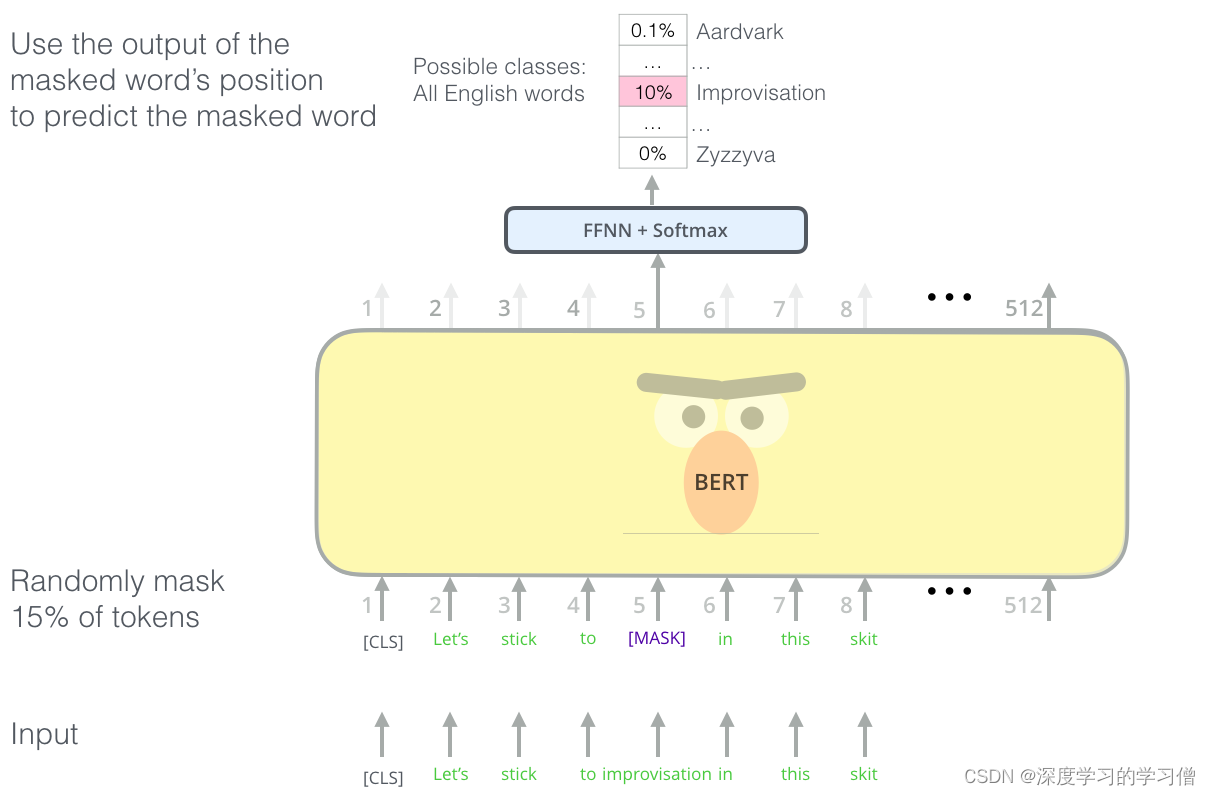
BERT 巧妙的语言建模任务屏蔽了输入中 15% 的单词,并要求模型预测缺失的单词。
找到正确的任务来训练 Transformer 编码器堆栈是一个复杂的障碍,BERT 通过采用早期文献中的“掩码语言模型”概念(在其中称为完形填空任务)解决了这一障碍。
除了屏蔽 15% 的输入之外,BERT 还混合了一些东西,以改进模型后来的微调方式。有时它会随机用另一个词替换一个词,并要求模型预测该位置的正确词。
两句话任务
如果您回顾一下 OpenAI Transformer为处理不同任务所做的输入转换,您会注意到某些任务需要模型说出关于两个句子的一些智能信息(例如,它们只是彼此的释义版本吗?给定一个维基百科条目作为输入,以及关于该条目作为另一个输入的问题,我们可以回答这个问题吗?)。
为了让 BERT 更好地处理多个句子之间的关系,预训练过程包括一个额外的任务:给定两个句子(A 和 B),B 是否可能是 A 之后的句子?
BERT 预训练的第二个任务是双句子分类任务。这张图中的标记化被过度简化了,因为 BERT 实际上使用 WordPieces 作为标记而不是单词——所以一些单词被分解成更小的块。
任务特定模型
BERT 论文展示了将 BERT 用于不同任务的多种方法。
用于特征提取的 BERT
微调方法并不是使用 BERT 的唯一方法。就像 ELMo 一样,您可以使用预训练的 BERT 创建上下文词嵌入。然后,您可以将这些嵌入提供给您现有的模型——该论文显示的过程产生的结果与在命名实体识别等任务上微调 BERT 相差不远。
哪个向量作为上下文嵌入效果最好?我认为这取决于任务。该论文检查了六个选择(与得分为 96.4 的微调模型相比):
试用 BERT
查看BERT 存储库中的代码:
该模型在modeling.py ( )中构建class BertModel,与普通的 Transformer 编码器几乎相同。
run_classifier.py是微调过程的一个例子。它还为监督模型构建分类层。如果您想构建自己的分类器,请查看create_model()该文件中的方法。
几个预训练模型可供下载。这些涵盖了 BERT Base 和 BERT Large,以及英语、中文等语言,以及一个涵盖 102 种语言的多语言模型,在维基百科上进行了训练。
BERT 不会将单词视为标记。相反,它查看 WordPieces。tokenization.py是分词器,可以将您的单词转换为适合 BERT 的 wordPieces。
#导入Python库并准备环境
!pip install transformers seqeval[gpu]
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score
import torch
from torch.utils.data import Dataset, DataLoader
#从Transformer导入BertConfig、BertModel
from transformers import BertTokenizer, BertConfig, BertForTokenClassification
#判断是否使用GPU算力
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
print(device)
BertConfig
这是用于存储BertModel或TFBertModel的配置的配置类。它用于根据指定的参数实例化 BERT 模型,定义模型架构。使用默认值实例化配置将产生与 BERT bert-base-uncased架构类似的配置。
# 初始化一个 BERT bert-base-uncased 风格的配置
configuration = BertConfig()
# 从 bert-base-uncased 样式配置初始化模型(具有随机权重)
model = BertModel(configuration)
# 访问模型配置
configuration = model.config
参数解释:
vocab_size ( int, optional , defaults to 30522) — BERT 模型的词汇表大小。inputs_ids定义调用BertModel或TFBertModel时传递的可以表示的不同标记的数量 。
hidden_size ( int, optional , defaults to 768) — 编码层和池化层的维数。
num_hidden_layers ( int, optional , defaults to 12) — Transformer 编码器中的隐藏层数。
num_attention_heads ( int, optional , defaults to 12) — Transformer 编码器中每个注意力层的注意力头数。
intermediate_size ( int, optional , defaults to 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维数。
hidden_act ( stror Callable, optional , defaults to “gelu”) — 编码器和 pooler 中的非线性激活函数(函数或字符串)。如果支持字符串、“gelu”、 “relu"和"silu”。“gelu_new”
hidden_dropout_prob ( float, optional , defaults to 0.1) — 嵌入、编码器和池化器中所有完全连接层的丢失概率。
attention_probs_dropout_prob ( float, optional , defaults to 0.1) — 注意概率的丢失率。
max_position_embeddings ( int, optional , defaults to 512) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。
type_vocab_size ( int, optionaltoken_type_ids , defaults to 2) —调用BertModel或TFBertModel时传递的词汇表大小。
initializer_range ( float, optional , defaults to 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。
layer_norm_eps ( float, optional , defaults to 1e-12) — 层归一化层使用的 epsilon。
position_embedding_type ( str, optional , defaults to “absolute”) — 位置嵌入的类型。“absolute"选择, “relative_key”,之一"relative_key_query”。对于位置嵌入,请使用"absolute". 有关 的更多信息"relative_key",请参阅 Self-Attention with Relative Position Representations (Shaw et al.)。有关 的更多信息"relative_key_query",请参阅Improve Transformer Models with Better Relative Position Embeddings (Huang et al.)中的方法 4。
is_decoder ( bool, optional , defaults to False) — 模型是否用作解码器。如果False,则该模型用作编码器。
use_cache ( bool, optional , defaults to True) — 模型是否应返回最后的键/值注意事项(并非所有模型都使用)。仅当config.is_decoder=True.
classifier_dropout ( float, optional ) — 分类头的丢弃率。
BertTokenizer
构建一个 BERT 分词器。基于WordPiece。
这个 tokenizer 继承自PreTrainedTokenizer,其中包含大部分主要方法。用户应参考该超类以获取有关这些方法的更多信息。
参数
vocab_file ( str) — 包含词汇表的文件。
do_lower_case ( bool, optional , defaults to True) — 标记化时是否将输入小写。
do_basic_tokenize ( bool, optional , defaults to True) — 是否在 WordPiece 之前进行基本标记化。
never_split ( Iterable, optional ) — 在标记化过程中永远不会拆分的标记集合。仅在以下情况下有效 do_basic_tokenize=True
unk_token ( str, optional , defaults to “[UNK]”) — 未知令牌。不在词汇表中的标记无法转换为 ID,而是设置为此标记。
sep_token ( str, optional , defaults to “[SEP]”) — 分隔符,在从多个序列构建序列时使用,例如两个序列用于序列分类或用于文本和问题回答的问题。它也被用作用特殊标记构建的序列的最后一个标记。
pad_token ( str, optional , defaults to “[PAD]”) — 用于填充的令牌,例如在批处理不同长度的序列时。
cls_token ( str, optional , defaults to “[CLS]”) — 进行序列分类时使用的分类器标记(对整个序列进行分类而不是按标记分类)。当使用特殊标记构建时,它是序列的第一个标记。
mask_token ( str, optional , defaults to “[MASK]”) — 用于屏蔽值的标记。这是使用掩码语言建模训练此模型时使用的标记。这是模型将尝试预测的标记。
tokenize_chinese_chars ( bool, optional , defaults to True) — 是否标记汉字。
对于日语,这可能应该被停用(请参阅本期 )。
strip_accents ( bool, optional ) — 是否去除所有重音。如果未指定此选项,则它将由 for 的值确定lowercase(与原始 BERT 中一样)。
以下是该类的方法:
build_inputs_with_special_tokens
参数:
token_ids_0 ( List[int]) — 将添加特殊标记的 ID 列表。
token_ids_1 ( List[int], optional ) — 可选的第二个序列对 ID 列表。
return:
List[int]
具有适当特殊标记的输入 ID列表。
通过连接和添加特殊标记,从一个序列或一对序列为序列分类任务构建模型输入。BERT 序列具有以下格式:
单序列:[CLS] X [SEP]
序列对:[CLS] A [SEP] B [SEP]
get_special_tokens_mask
( token_ids_0 : typing.List[int]token_ids_1 : typing.Optional[typing.List[int]] = Nonealready_has_special_tokens : bool = False ) → List[int]
参数
token_ids_0 ( List[int]) — ID 列表。
token_ids_1 ( List[int], optional ) — 可选的第二个序列对 ID 列表。
already_has_special_tokens ( bool, optional , defaults to False) — 标记列表是否已经使用模型的特殊标记格式化。
return:
List[int]
[0, 1] 范围内的整数列表:1 表示特殊标记,0 表示序列标记。
从没有添加特殊标记的标记列表中检索序列 ID。使用 tokenizer 方法添加特殊标记时调用此方法prepare_for_model。
create_token_type_ids_from_sequences
( token_ids_0 : typing.List[int]token_ids_1 : typing.Optional[typing.List[int]] = None ) → List[int]
参数
token_ids_0 ( List[int]) — ID 列表。
token_ids_1 ( List[int], optional ) — 可选的第二个序列对 ID 列表。
return:
List[int]
根据给定序列的令牌类型 ID列表。
从传递的两个序列创建掩码以用于序列对分类任务。一个 BERT 序列
对掩码具有以下格式:
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| 第一个序列 | 第二序列 |
如果token_ids_1是None,此方法仅返回掩码的第一部分 (0s)。
save_vocabulary
( save_directory : strfilename_prefix : typing.Optional[str] = None )
保存词汇
class transformers.BertModel
( configadd_pooling_layer = True )
#参数
#config ( BertConfig ) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看from_pretrained()方法加载模型权重。
这个模型是基于Bert Model的,它输出原始的隐藏状态,没有特定的头部。
这个模型继承自PreTrainedModel。你可以查看超类的文档,了解库实现的通用方法,比如下载或保存模型、调整输入嵌入的大小、修剪头部等等。
这个模型也是一个PyTorch的torch.nn.Module子类。你可以像使用普通的PyTorch模块一样使用它,并参考PyTorch文档了解与常规使用和行为相关的事项。
该模型可以作为编码器(只使用自注意力)或解码器运行。当作为解码器时,在自注意力层之间添加了一层交叉注意力,遵循Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser和Illia Polosukhin在《Attention is all you need》中描述的架构。
若要作为解码器运行,模型的配置参数中的is_decoder参数需要设置为True。若要在Seq2Seq模型中使用该模型,则需要将is_decoder参数和add_cross_attention参数都设置为True,并且在前向传递中需要提供encoder_hidden_states作为输入。
forward
参数:
input_ids ( torch.LongTensorof shape (batch_size, sequence_length)) — 词汇表中输入序列标记的索引。
attention_mask ( torch.FloatTensorof shape (batch_size, sequence_length), optional ) — 避免对填充标记索引执行注意力的掩码。在以下位置选择的掩码值[0, 1]:
1 对于未屏蔽的标记,
0 表示被屏蔽的标记。
token_type_ids ( torch.LongTensorof shape (batch_size, sequence_length), optional ) — 段令牌索引以指示输入的第一部分和第二部分。指数选择于[0, 1]:
0对应一个句子A token,
1对应一个句子B token。
position_ids ( torch.LongTensorof shape (batch_size, sequence_length), optional ) — 位置嵌入中每个输入序列标记的位置索引。在范围内选择[0, config.max_position_embeddings - 1]。
head_mask(torch.FloatTensor形状为(num_heads,)or (num_layers, num_heads),可选)— 使自注意力模块的选定头部无效的掩码。在以下位置选择的掩码值[0, 1]:
1表示头部没有被遮盖,
0 表示头部被屏蔽。
inputs_embeds ( torch.FloatTensorof shape (batch_size, sequence_length, hidden_size), optionalinput_ids ) — 可选地,您可以选择直接传递嵌入表示而不是传递。input_ids如果您希望比模型的内部嵌入查找矩阵更多地控制如何将索引转换为关联向量,这将很有用。
output_attentions ( bool, optional ) — 是否返回所有注意力层的注意力张量。attentions有关更多详细信息,请参阅返回的张量。
output_hidden_states ( bool, optional ) — 是否返回所有层的隐藏状态。hidden_states有关更多详细信息,请参阅返回的张量。
return_dict ( bool, optional ) — 是否返回 ModelOutput而不是普通元组。
encoder_hidden_states ( torch.FloatTensorof shape (batch_size, sequence_length, hidden_size), optional ) — 编码器最后一层输出的隐藏状态序列。如果模型配置为解码器,则用于交叉注意。
encoder_attention_mask ( torch.FloatTensorof shape (batch_size, sequence_length), optional ) — 避免对编码器输入的填充令牌索引进行注意的掩码。如果模型配置为解码器,则此掩码用于交叉注意。在以下位置选择的掩码值[0, 1]:
1 对于未屏蔽的标记,
0 表示被屏蔽的标记。
past_key_values(每个元组tuple(tuple(torch.FloatTensor))的长度有 4 个形状的张量)——包含注意块的预计算键和值隐藏状态。可用于加速解码。config.n_layers(batch_size, num_heads, sequence_length - 1, embed_size_per_head)
use_cache ( bool, optional ) — 如果设置为True,past_key_values则返回键值状态并可用于加速解码(参见 past_key_values)。
return transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions或tuple(torch.FloatTensor)
from transformers import AutoTokenizer, BertModel
import torch
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
BertForPreTraining
class transformers.BertForPreTraining
参数
config ( BertConfig ) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看from_pretrained()方法加载模型权重。
在预训练期间完成的顶部有两个头的 Bert 模型:一个masked language modeling头和一个next sentence prediction (classification)头。
该模型继承自PreTrainedModel。检查超类文档以了解库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入的大小、修剪头等)
这个模型也是 PyTorch torch.nn.Module 的子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以了解与一般用法和行为相关的所有事项。
from transformers import AutoTokenizer, BertForPreTraining
import torch
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = BertForPreTraining.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
prediction_logits = outputs.prediction_logits
seq_relationship_logits = outputs.seq_relationship_logits










![深度学习应用篇-计算机视觉-图像增广[1]:数据增广、图像混叠、图像剪裁类变化类等详解](https://img-blog.csdnimg.cn/img_convert/0dacfa2d1614c59f191480d8ed48c719.png)
