文章目录
- 背景
- 1 存算分离
- 2. 统一的表存储 (行列混存)
- 2.1 二级索引
- 2.2 行锁
- 3. 自适应查询引擎
- 3.1 Segment skipping 实现
- 3.2 Filtering 选择
- 4 性能
- 总结
背景
上篇看了 PolarDB-IMCI 在HTAP的实践,其中提到了其也有借鉴 SingleStore 的实现思路 并加以改进。所以又翻出来了 SingleStore 在 2022 SIGMOD上的论文 学习一下,原文 google 或者 sci-hub一下就好了。
数据库行业 HTAP 大背景就不再赘述了,主要两方面的原因:
- 云基础架构的弹性、灵活、低成本(用户 + 开发者)
- 数据存储访问需求的多样性,既要、又要、还想要 AP(高性能) + TP(低延时)
SingleStoreDB 论文中简称 S2DB,即 一个DB 服务两种数据库场景 TP + AP。
S2DB 实现HTAP 能力的 主体设计有在三方面:
- 存算分离,数据集主要存储在对象存储上,上层的primary节点 负责数据的读写 只读节点负责 AP以及 TP的数据查询,它们本地盘都能提供 数据缓存能力;并且在此基础上实现了 PITR 即 time-travel能力。
- 统一的表存储(行列混存)。行存和列存的区分不会对用户暴露(不需要用户指定使用行存还是列存),实现细节在内核内部,默认同时支持行存和列存的存储格式。实现上是 完全in-memory的行存 以及 持久化到 blob storage 的列存。
- 自适应的执行引擎。根据用户的query 选择合适的成本评估模型 来生成对应的plan,并且支持了基于 LLVM 的 JIT。
接下来看一看论文中介绍的 S2DB 在这三方面背后的细节
1 存算分离
在存储架构上 S2DB 既支持 shared-everything 即底层是共享存储,又支持 shared-nothing 即底层是单个的服务器节点。
其存储设计主要是利用计算节点的本地盘做缓存,Blob Storage 作为冷数据的存储仓库(类似冷热分离),数据通过 primary 节点 写入到本地之后会异步同步到 Blob Storage。利用本地盘的目的主要是降低事务的commit 延时(还是成本受限啊,Polar IMCI 所有计算以及存储节点都是 RDMA,就可以直接在共享存储上玩了)。
事务的 Durability 特性的保障是通过其存储架构完成的,一个 S2DB 集群内部会有多个副本,数据写入到内存之后无需等待 commit 就可以直接复制到任何一个持久化的的副本中,当一个事务的所有数据在多副本中的一个副本上完成持久化就可以标识这个事务是commit状态,且整个复制过程在 cache节点 支持乱序复制,即无需等待长事务,这样复制的延时在高并发下会非常低。事务的提交则是需要在持久化节点上来完成,通过LSN 保序提交。
基本数据的写入以及同步流程架构如下:
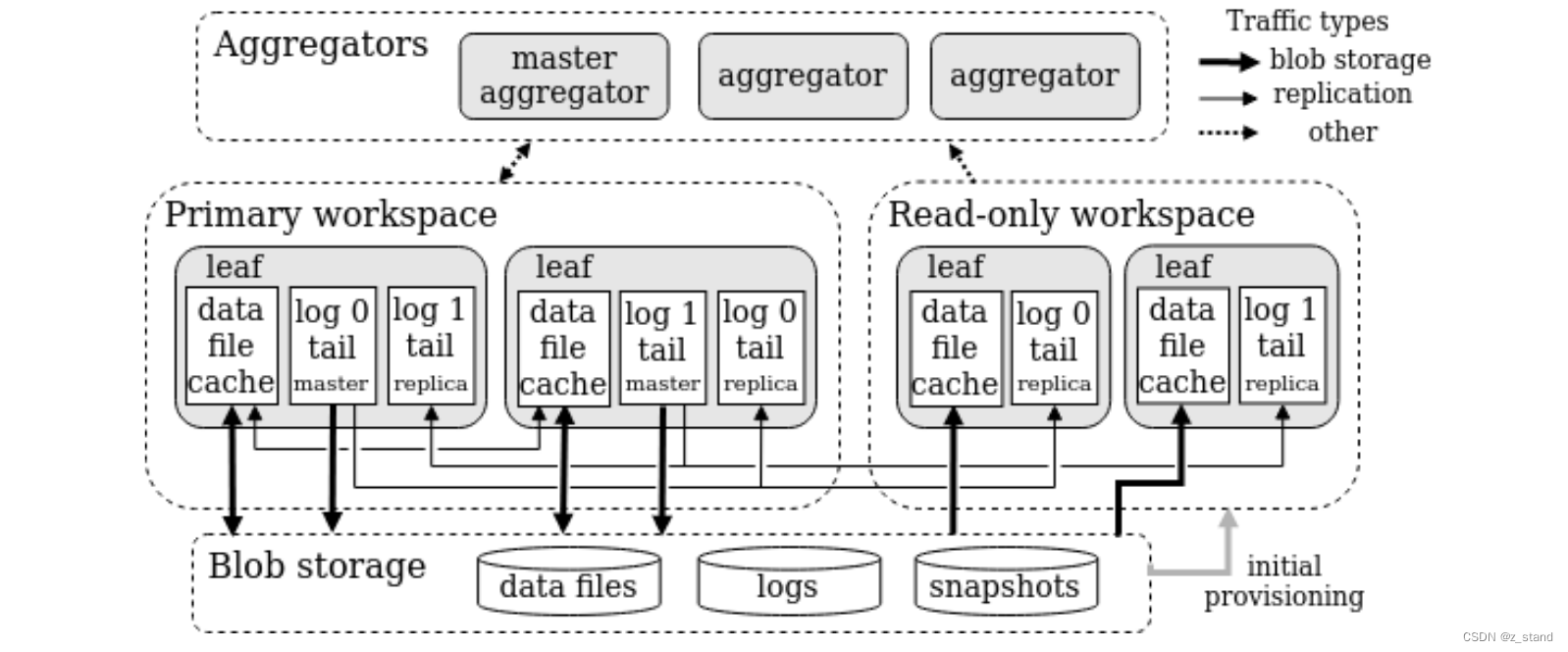
-
数据通过Aggregators( 类似 polardb-IMCI 中的 proxy节点) 聚合节点做完路由以及 负载均衡之后落入 PrimaryWorkspace 的一组主机中的一个服务器(hash 分片),为了降低本地写入的延时,本地存储都采用 较快的SSD – (冷热分离的目的)。
-
在当前服务器内存中构建行存以及列存相关的信息之后写入到 本地的redo log中,比如 上图中的 leaf log0 tail - master ,写入方式是 append-only。
-
此时虽然是本地盘已经持久化了,但是还不能提交事务,因为云上的高可用以及真正的持久化是一个计算节点下线不会导致数据丢失,但是S2DB 为了 TP的低延时借用了节点的本地盘,所以需要将 当前数据复制到其他 任意 leaf节点的当前log副本,比如 log0-replica, 才能向客户端返回事务提交。这样有一个数据的备份节点来做背书,就能实现高可用了。当然,这个复制策略可以实现为跨机房、数据中心 以及 大洲。
因为数据需要复制,所以commit / abort 之前需要持久化的数据允许同步 且 支持乱序同步,这样就能降低因为数据复制而增加的延时。 -
完成 commit 需求的复制之后, 持久化的数据文件会异步上传到 Blob Storage,而redo-log文件则会按照文件 chunk ,上传某一个lsn/offset之前的数据页到 Blob Storage中,做一个truncate,这个日志的 末尾还会继续接受新的写入。
-
因为 Primary workspace 允许读写,为了从计算资源层面分离 AP 和 TP的workload,降低 AP 对 TP的影响,S2DB支持 创建只读工作区,即 Read-Only Workspace(也是一组服务器主机) ,会通过同步机制 从Primary workspace中的 master 服务器 拉取最新写入的 log 文件到自己的 leaf 服务器本地做AP 数据的缓存,这是为了保证数据的新鲜度(没有RDMA,没有数据的实时同步,显然只读副本的数据新鲜度并不高);剩余的历史数据如果有读需求,则会从 Blob Storage上拉取。
只读 workspace 中的副本节点不会参与保障 commit 操作的数据同步,commit 需要的数据同步都是在 Primary Workspace 的服务器组中完成的。
-
为了实现 PITR (Point-In-Time-Recovery),当前时间点内存行存数据快照备份会直接写入到BlobStorage中,创建快照的过程只需要在 Primary WorkSpace完成。之所以需要为 in-memory的行存打快照,是因为其保存了当前集群当前时间点的全量状态的版本数据,只需要保证blobstorage的历史数据不真删除,就能实现 time-travel 到历史快照时间点的数据库状态。
2. 统一的表存储 (行列混存)
S2DB 实现行列混合存储的目的是为了降低用户使用的复杂度,任何workload都能很好的被处理,用户不需要自己分析自己的workload来做复杂的配置调研,S2DB AP TP workload都能适应,直接无脑使用就好了。
在 接受写入的计算节点中,整个行列混存的形态可以看作是一个 LSM-Tree 的实现。

- 常驻内存的部分的 row-store 是一个无锁跳表,可以看作 LSM-tree 的 In-Memory数据结构。
- 当内存中的行较多达到某一个阈值的时候 可以 flush 为列存存储的 segmemt 文件,flush 操作一行则从skiplist中删除改行记录(无锁跳表,页为了防止内存无限膨胀),对于数据文件中某一行的删除则也是 利用bitmap标识某一行被删除 并存储到 segment文件的元数据区域中,方便后续compaction进行清理或者读的时候只需要加载当前segment文件的 meta数据到内存就知道其内部哪一些数据被删除。这其实是为 LSM-tree 的 append-only delete做的改进,因为 delete版本过多本身会影响scan 以及 compaction的性能,现在只需要利用in-memory的 bitmap就能加速这个过程。
- 为了避免磁盘的频繁写入(本质上不想和传统的LSM tree一样所有的版本都是append-only,不需要这么强的写入,会造成巨量的compaction从而影响读性能;宁愿牺牲写也需要保证 TP 的读),所以这里对于update 和 delete 都会更新 segment 文件的 metadata,这样就避免了过多的版本的写入;但是metadata 并发更新的原子性可能会对写入性能产生影响。
论文中没有详细介绍列存文件的存储格式,不过和IMCI row-group 列存文件格式 差异不大,一个segment文件每一列是一个block,一行的所有列保存到一个 segment文件中。
2.1 二级索引

为了提升点 TP场景的 查性能,需要在 Segment基础上实现二级索引,S2DB 主要在两方面发力:
-
内部索引结构:segment 文件级别的 bloom filter,能高效判断要查的数据行的某一个列索引是否一定不存在于当前segment
-
外部索引结构,在主键索引基础上实现一个外部索引结构(比如 spanner/ wiredtiger)加速查找。比如构造另一个 lsm-tree 或者 btree,有序存储多个segment中相同 主键的offset。首先每一个segment内部构造一个按主键倒排序的主键索引,存储当前索引行的列内偏移。
如上图的左边部分,segmemt 列存文件内部 的inverted-index,其中存储了 foo: 1, 3 表示 主键列 为 fool 的 行有两个value,其在其他column 存储的便宜地址分别是 1, 3。如果我想查询主键为foo 的正行数据时,只需要找其他列的 1, 3 号偏移地址的内容就能读出 两行foo 的结果了。
其次,在多个segment 文件之间基于 每一个文件的倒排索引构造一个 global index (可以是lsm-tree 或者 b-tree),其内部节点中保存主键列在不同文件的倒排索引内的偏移地址。比如,对于foo列,能够hash映射到 0x24行,其内容 s1:offset 1, s3: …,则表示 foo 这一行的内容可以先去 s1号segment文件的 inverted-index 的 offset1 去拿段内偏移地址;再去 s3号segment文件的 indverted-index 的 offset…去拿 s3内存储 foo 所在行数据的偏移地址。
global-index 这里有一个细节是说其lsm-tree 节点有序存储 主键的hash值 以及 行的物理偏移地址。但是会受到 segment 文件 compaction的影响,因为compaction 会更改行的偏移地址。这个时候就需要对global-index 中存储的节点进行修改,但是因为 列存有效减少了 update/delete的版本写入,本身compaction量就比较少,这样global-index 更新频率也就比较少了,这也是降低lsm-tree写入的一个额外优势了。加速了TP的读性能。
inverted-index 以及 global-index 实际都可以被放在内存中,寻址很快,能够极位高效得为 TP 场景实现点查功能。
后续S2DB 索引相关的部分介绍了多列索引 如何加速多filter的过滤 以及 如何利用当前二级索引的实现方式支持唯一性检查的(segment文件内部并没有实现LSM-tree的按主键排序)。
2.2 行锁
也是前面提到的 为了减少compaction 而将 update/delete的追加写方式变更为 segment metadata 中 bitmap的标记。这样简单的实现在update/delete场景较多时会出现改bitmap的竞争问题,所以需要通过行锁来保护 update/delete的原子操作,多用户并发操作同一行场景时只能保证一位用户commit/abort之后其他用户才能操作。
S2DB 实现方式较为独特,不是直接去修改 segments的metadata,而是构造一个移动事务,将对segment-metadata 的操作转为对in-memory row-store的操作,这样修改可以立即commit并生效(多了一个版本),不影响用户的读。后续再用行锁来保护对segment-metadata 中bitmap的修改。针对内存 row-store 构造的 一个移动事务 可以batch多个客户端对当前行的操作,减少增加的版本数量。
3. 自适应查询引擎
由于 HTAP的 workload 对 AP 和TP 的界限区分并不明显,查询引擎需要结合不同的访问方式来提供不同workload的最佳性能。比如,一个query 的一个filter可能会使用二级索引,而另一个则可以使用 encoded 的filter。S2DB 不需要用户介入,能够自适应得为用户做出最佳的数据访问决策。
一个 query 从 S2DB 输入到拿出数据会大体经历三个步骤:
- 找到要读取的 segments 列表
- 运行filter,从每一个segment文件中找到要读取的行
- 有选择得解码并输出对应行
论文中介绍的 查询引擎的工作主要集中在前两步,如何动态决策选择要读取的segments列表 以及 选择filter。
3.1 Segment skipping 实现
主要通过全局二级索引 以及 segment-metadata 来尝试跳过要访问的 segments。
- 先访问 全局二级索引(global index) 或者 segment metadata 中的 min/max来跳过某一些segment。
- 如果要查的键的数目过多,则会动态禁用二级索引。二级索引的自适用禁用在 join场景非常重要,因为join的过程涉及多表数据,会急速增加索引键的数量从而增加索引查找的成本。
3.2 Filtering 选择
选择合适的 Filter也非常重要 (col1 =val1),S2DB 提供了四种 Filter类型用于评估:
- Regular filter, 有选择得为上一个filter decode col1,拿着decode 之后的value 去匹配当前filter
- Encoded filter 可以直接在压缩数据上执行,比如字典编码场景,可以在不decode的情况下过滤所有可能是col1 的行。不过仅使用tuple 较少的场景。
- Group filter,先decode 所有拿到的列,将filter作为小条件(短小的内部循环),不是每一行数据都经历完整的匹配逻辑,方便利用cpu-cache。这个场景对 满足group filter条件的场景优势较大,如果大多数行都不满足filter,其效果还不如regular filter。
- Secondary index filter. 利用 global 二级索引的查找,筛选满足filter 的 row-offset;在以 val1为primary-index 的 global-index中,如果有较多的行需要过滤,二级索引filter 效率肯定比regular filter好,行数较少,可能构建二级索引的过程+访问比regular filter 直接顺序遍历segment-metadata 拿对应行 效率更低。
这四种Filter 如何选择,对于两个filter 语句 A AND B则是遵循如下公式:
1
−
P
(
B
)
c
o
s
t
(
B
)
<
=
1
−
P
(
A
)
c
o
s
t
(
A
)
\frac{1-P(B)}{cost(B)} <= \frac{1-P(A)}{cost(A)}
cost(B)1−P(B)<=cost(A)1−P(A), 其中
cost(X)为 optimizer 为 X 子句评估的costP(X)是为当前语句选择的 filter 计算的选择性
满足以上等式,则建议优先 eval A 子句。
至于P(X) 以及 cost(X) 到底如何计算得出来的,论文中基本没说,本身这个也是优化器的核心,论文对optimizer 基本没提,毕竟受篇幅影响以及是核心竞争力,而且项目没有开源,没必要为了顶会全盘抖出来,让大家知道我们牛逼就好了。
因为优化器我也不懂,对于给出的公式以及这一些计算属性也不好推导,也就只能放在这里等日后或者懂的同学解惑:)
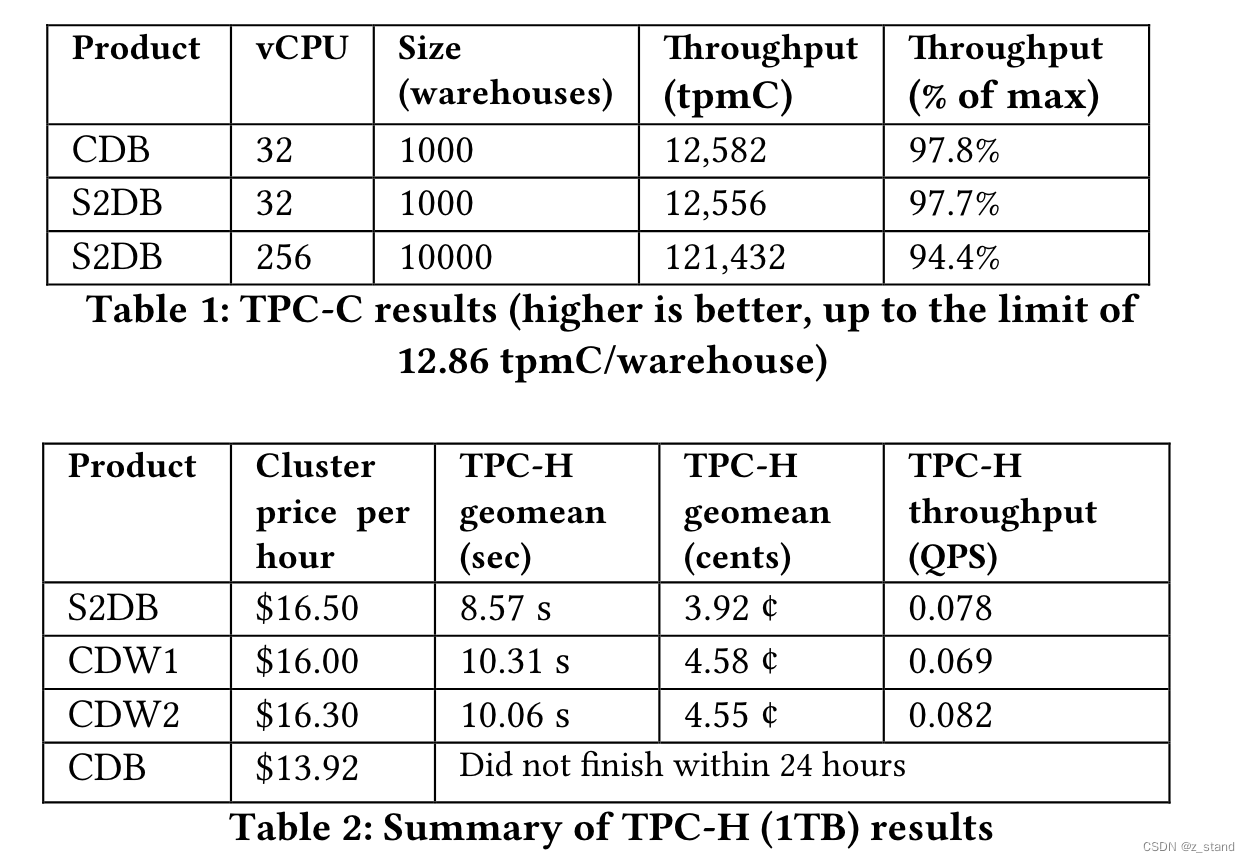
4 性能
感觉数据没有特别全面,比如没有详细的混合 workload中 TPC-H 对 TPC-C的影响,polardb-IMCI 今年的数据就测的比较好,毕竟HTAP 大家还是很关注这一方面的影响;还有就是数据新鲜度的测试,Primary workspace的数据多久才能被 Read-only workspace读到呢?
直接看 TPC-C 和 TPC-H(1T)各自的数据如下,也还不错:
总结
SingleStoreDB 总体架构是 in-memory rowstore + columnstore,单节点行列混存 并用LSM-tree 以及 Global-index 加速数据的更新和读取。利用本地节点缓存降低事务commit 延时,在不同节点之间允许乱序同步redo-log 加速同步效率。
首先与成本 以及 云基础设施,没法像 PolarDB-IMCI 全链路 rdma降低延时,为了 TP 的commit性能 S2DB 在实现过程中也是煞费苦心。本地盘SSD缓存 + 乱序同步 redo-log 到一个副本本地 才能提交, polardb-IMCI 今年将同步部分的实现在论文中详细展开了,只是polardb 因为直接rdma 持久化到共享内存,是异步同步实现的,保证了极高的数据新鲜度。




![CodeForces..最新行动.[中等].[遍历].[判断]](https://img-blog.csdnimg.cn/f3c43c741a80456a9cb2a5ac52d7a08b.png)

![2023《中国好声音》全国巡演Channel[V]歌手大赛广州赛区半决赛圆满举行!](https://img-blog.csdnimg.cn/img_convert/476a1dab1cb6a9d07d4997b2d14983e8.jpeg)