给自己的每日一句
不从恶人的计谋,不站罪人的道路,不坐亵慢人的座位,惟喜爱耶和华的律法,昼夜思想,这人便为有福!他要像一棵树栽在溪水旁,按时候结果子,叶子也不枯干。凡他所做的尽都顺利
本文内容整理自《孙哥说Mybatis系列课程》,B站搜孙帅可以找到本人
前言
上次课讲完之后,所有一级缓存的地方分析到位了,但是一级缓存问题是不少的因为不能跨SqlSession共享。这个时候对于实战来讲意义不大,毕竟对于缓存来讲我们是希望跨SqlSession共享。
第一章:二级缓存前提
二级缓存默认关闭,开启二级缓存是有几个前提条件。
一:Mybatis-config.xml当中配置
此操作可有可无
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
因为在核心配置文件当中配置的在Configurantion类当中
protected boolean cacheEnabled = true;
所以核心配置文件当中配置或者不配置都可以。
二:Mapper文件中引入二级缓存Cache标签
此操作必须有!
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.dashu.dao.UserDAO">
//Cache标签
<cache/>
<select id="queryAllUsersByPage" resultType="User" useCache="true">
select id,name from t_user
</select>
</mapper>
三:属性
可配置可不配置
四:事务存在
此操作必须有!
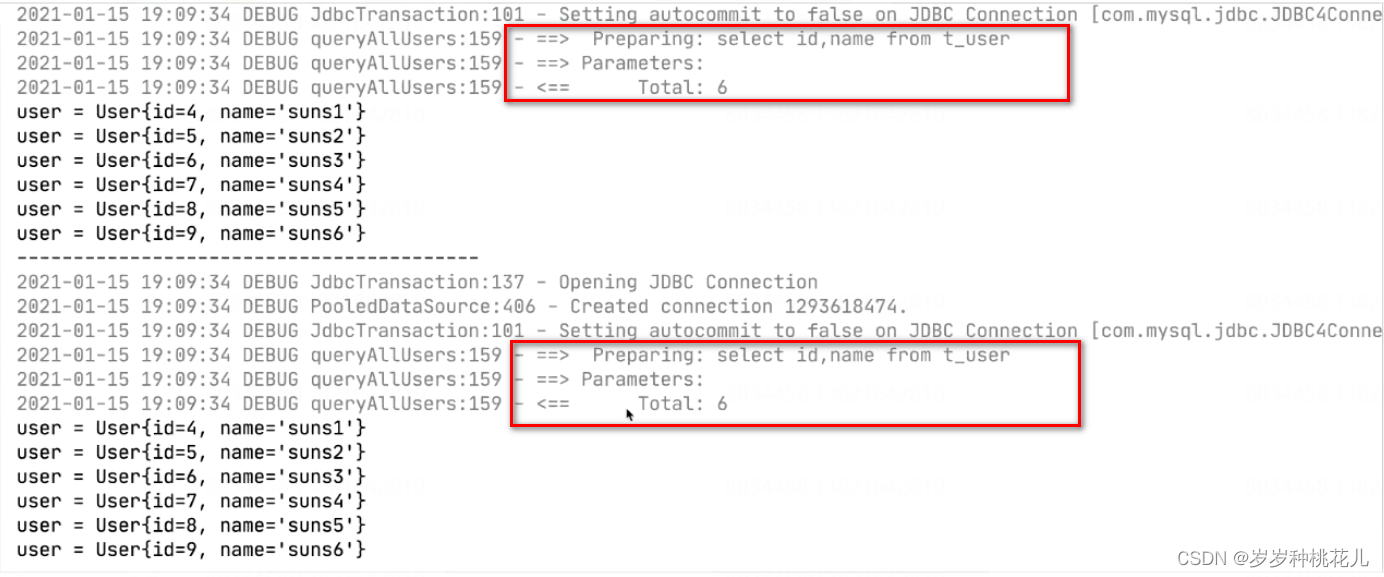
没有使用缓存:
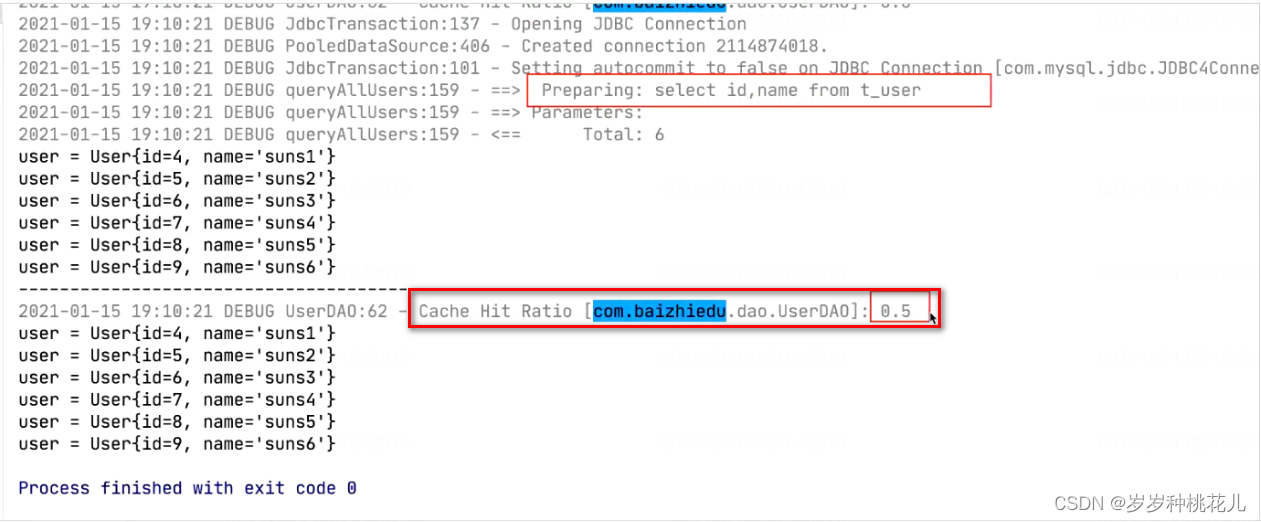
此图使用了缓存,并且第一次查询数据库,第二次命中缓存,缓存命中率0.5:
第二章:二级缓存如何在Mybatis当中实现的
一:二级缓存在Mybatis当中的整个流程
不论是怎么实现的,一定会使用Cache接口和核心实现类PrepetualCache,还有他们各种装饰器。
二级缓存Mybatis运行当中起作用的呢?或者说如何接入的呢?我们首先回顾下一级缓存,一级缓存接入是在BaseExecutor当中做的,基于PrepretualCache作为缓存对象,query方法进行数据查询,缓存有直接返回,缓存没有查询数据库放到缓存中在进行返回。
二级缓存和以及缓存的接入有这本质上区别,二级缓存使用的Excutor是CachingExecutor(Executor接口的实现类),CachingExcutor是SimpleExecutor和ReuseExecutor和BatchExecutor的装饰器。
装饰器:为目标增强核心功能,就是为了SimpleExecutor和ReuseExecutor和BatchExecutor增强他们的缓存这个核心功能的。这三个Executor是访问数据库的,CachingExcutor作为他们的装饰器就是为了增强他们的查询功能、提升查询效率。CachingExcutor在这里也是采用了一种套娃的方式:
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
}
所以二级缓存使用的时候一定是:
CachingExecutor CachingExecutor = new CachingExecutor(SimpleExecutor);
那么这一步创建操作是在哪里做的呢?Configuration当中。Configuration这个核心类一方面封装核心配置文件和MappedStatements,他还需要创建Mybatis当中所有的核心对象:Executor和StatementHandler
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {//setting里边或者是Configuration当中的cacheEnabled = true的那个。
//这个属性是在Configuration当中被保存并且被使用。
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
CachingExecutor是在Configuration当中的newExecutor方法里边,基于cacheEnabled判断是否被创建。
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
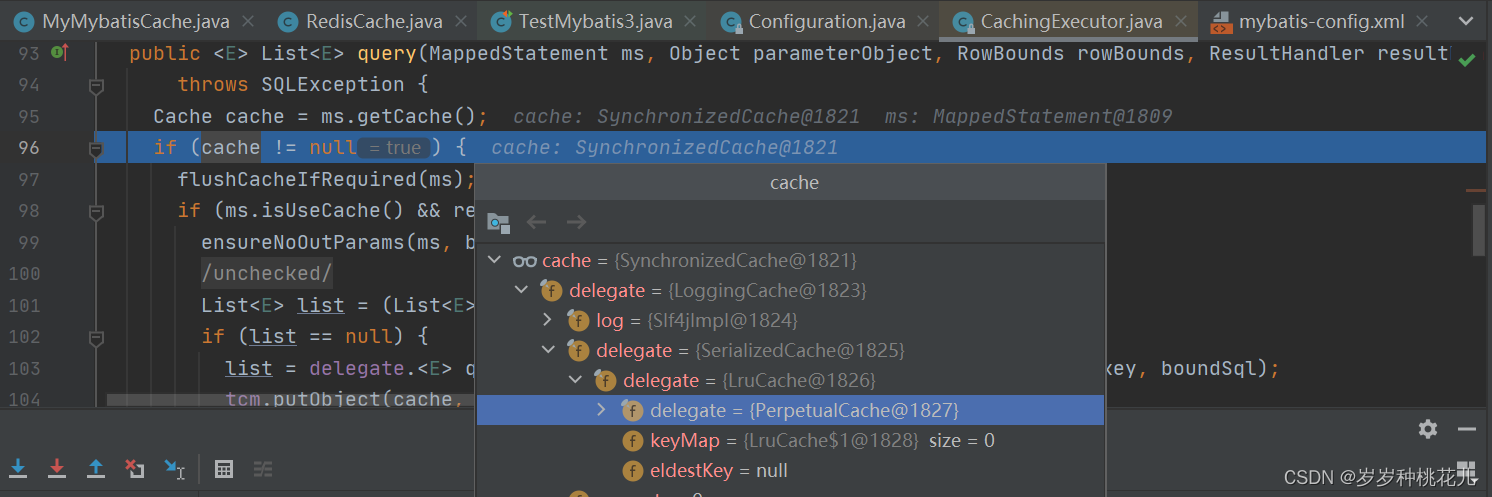
Cache cache = ms.getCache();
//写没写Cache标签。
if (cache != null) {
//<SELET标签当中配置flushCache=true属性,有了这个上次的查询缓存就不生效了>
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);//缓存中有数据
if (list == null) {
//写Cache标签,但是第一次查询缓存中没有数据。
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//放到二级缓存当中。
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//Mapper文件中写没写Cache数据库
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
补充:
我们设计一个查询方法的时候能够涵盖所有的查询可能,返回值设计成List是最合理的。那为什么不能用Set呢?是因为List是有序的,为什么一定要体现到顺序性能?想想有没有需要排序的场景就知道了。那用treeSet行么?treeSet不也是有序的么?也是不行的,TreeSet是排序,List是有序,有序是先来后到,排序是排序规则。
二:级缓存对于增删改的操作
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
设计到对于数据的增删改之后,会首先清除二级缓存,避免脏数据的产生。
第三章:二级缓存的创建
我们的缓存数据是放到了Cache接口对应的实现类当中,那么这这些接口的实现类的实例是在什么时候创建的?以及怎么创建的呢?这是我们接下来要解决的问题。
我们可以搜索一个源码:useNewCache方法,这个方法是在:MapperBuilderAssistant这个类当中。MapperBuilderAssistant这个类是MappedStateMent的创建助手。那么这个方法都会被谁来调用呢?快捷键ctrl+alt+h查看方法的被调用路径。
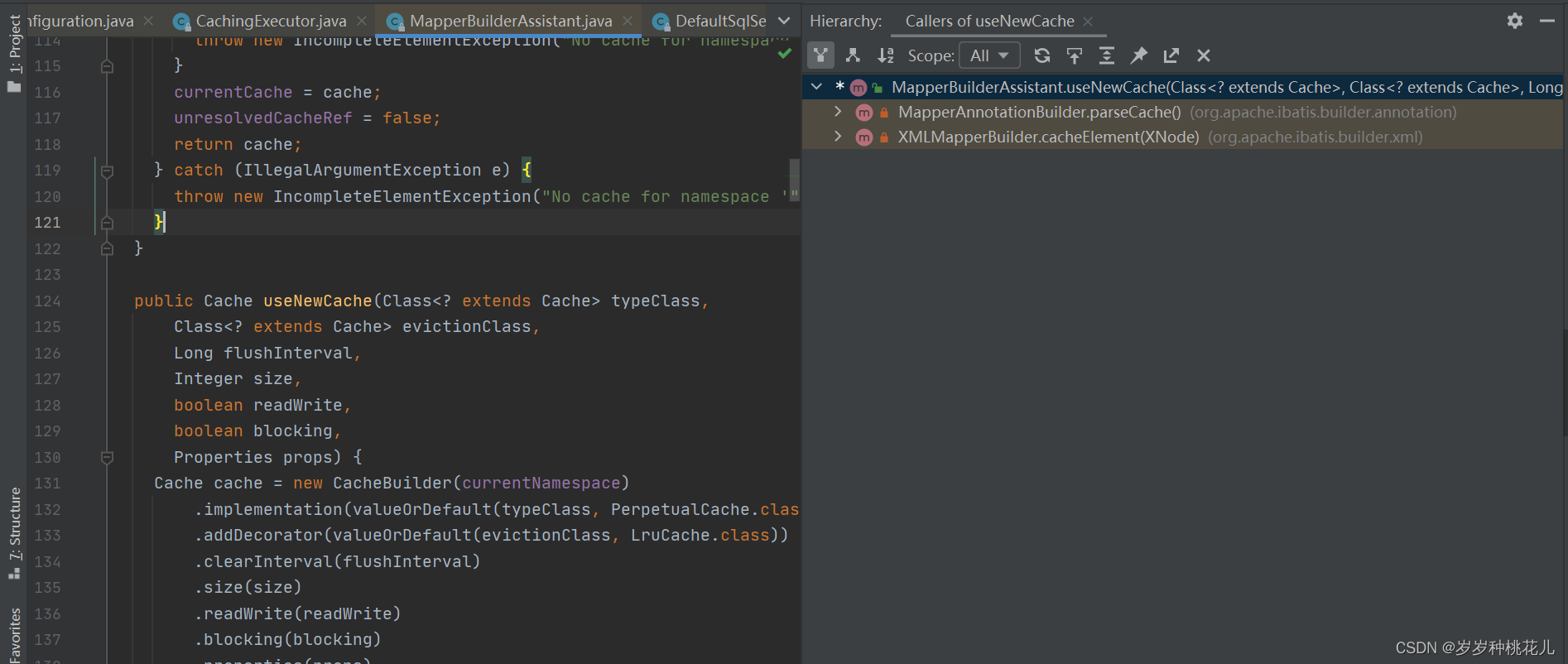
这两个方法都会调用useNewCache方法,那么有什么区别呢?XMLMapperBuilder对应的XML文件这种形式,MapperAnnotaionBuilder对应的注解的这中形式。
知识补充:
Mybatis当中映射是有两种方式的。一种是基于注解,一种是基于xml文件。
一:什么时候创建?
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
//当解析到cache标签之后就会帮我们创建Cache
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
当代码解析到Mapper.xml文件中的Cache标签之后就会创建Cache对象。调用的方法就是useNewCache
二:如何实现呢?
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
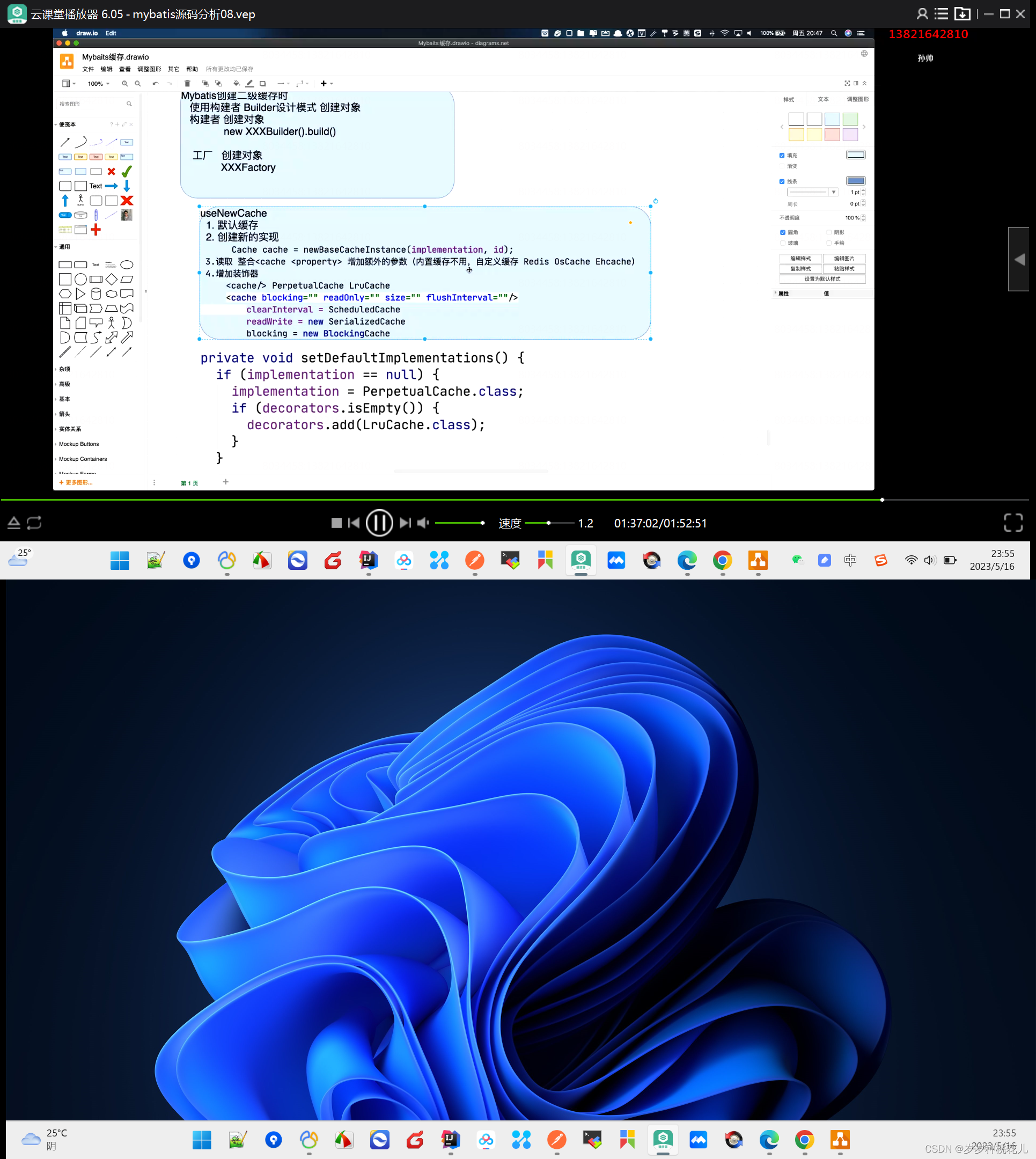
上述代码中是一个典型的构建者设计模式,构建者设计模式有两个约定,1:一定是什么xxxAdapter,2:最终进行操作一定是他的build方法。构建者设计模式最终的目的就是为了创建一个对象。这就很类似我们的工厂。
Mybatis在创建我们的二级缓存的时候,在useNewCache构建者设计模式,使用构建者和工厂创建对象有什么区别呢?
工厂一般是Factory.xxx(),构建者设计模式一般是new xxxBuilder().build();
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build();这里应用的也是构建者设计模式。
构建者设计模式强调的是零件组装成一个整体对象。接下来我们去研究一下build方法。
public Cache build() {
//设置默认Cache.
setDefaultImplementations();
//解决自定义Cache
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
//<cache eviction="FIFO" blocking="" readOnly="" size="" flushInterval=""/>
//有了这些配置属性,这个方法当中才会加上对应的装饰器。
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
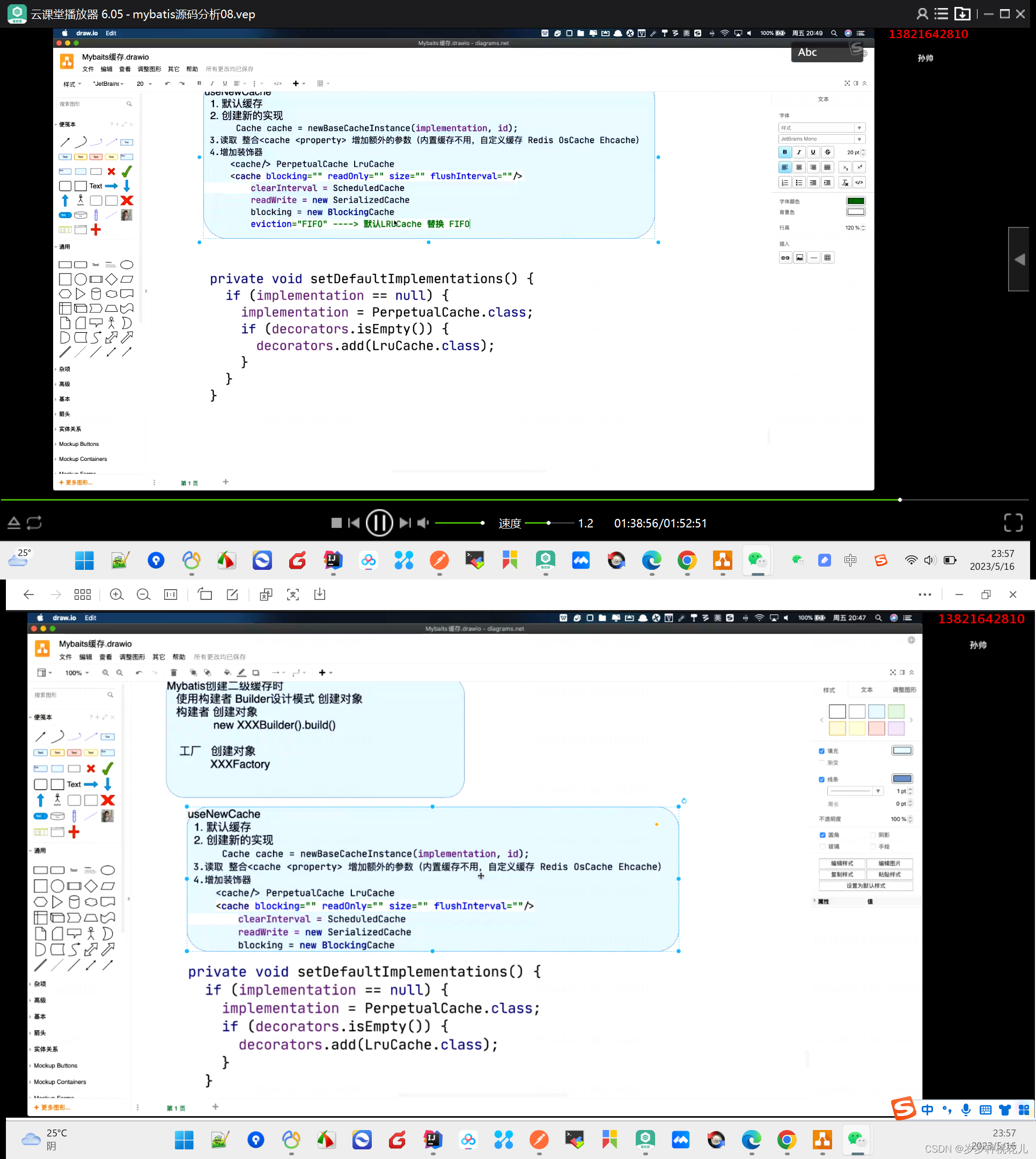
setDefaultImplementations方法揭晓
private Class<? extends Cache> implementation;
private final List<Class<? extends Cache>> decorators;
private void setDefaultImplementations() {
if (implementation == null) {
implementation = PerpetualCache.class;
if (decorators.isEmpty()) {
decorators.add(LruCache.class);
}
}
}
这个方法还是很简单的,设置了默认的实现,如果我们不做任何配置的话,二级缓存使用的是PerpetualCache,装饰器只有一层,只用的是LruCache
Cache cache = newBaseCacheInstance(implementation, id);方法解决自定义Cache
<cache type="org.mybatis.caches.ehcache.EhcacheCache">
<property name="" value=""/>
<property name="" value=""/>
<property name="" value=""/>
<property name="" value=""/>
<property name="" value=""/>
</cache>
private Cache newBaseCacheInstance(Class<? extends Cache> cacheClass, String id) {
Constructor<? extends Cache> cacheConstructor = getBaseCacheConstructor(cacheClass);
try {
return cacheConstructor.newInstance(id);
} catch (Exception e) {
throw new CacheException("Could not instantiate cache implementation (" + cacheClass + "). Cause: " + e, e);
}
}
本质上就是基于反射创建了一个对象
第四章:二级缓存的存储
接下来我们要研究明白的问题是创建好的Cache对象是要放到哪个位置呢?
答案是显而易见的存放在了MappedStatement当中。通过MappedStatement.getCache()方法来获取缓存Cache对象。
CacheExcutor二级缓存操作时从MappedStatement获取Cache对象,并获取缓存数据。
问题:
Mybatis当中存在一级缓存也存在二级缓存,那么Mybatis进行查询的时候是先查一级缓存还是二级缓存呢?
Configuration创建Excutor的时候,走newExcutor方法。返回给我们的Executor方法是CachingExecutor,源码如下:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
cacheEnabled默认开着呢,返回的是CachingExecutor,然后里边返回的是SimpleExecutor做他的娃。我们又知道SimpleExecutor extends BaseExecutor,SimpleExecutor部分内容是交给BaseExecutor完成的,
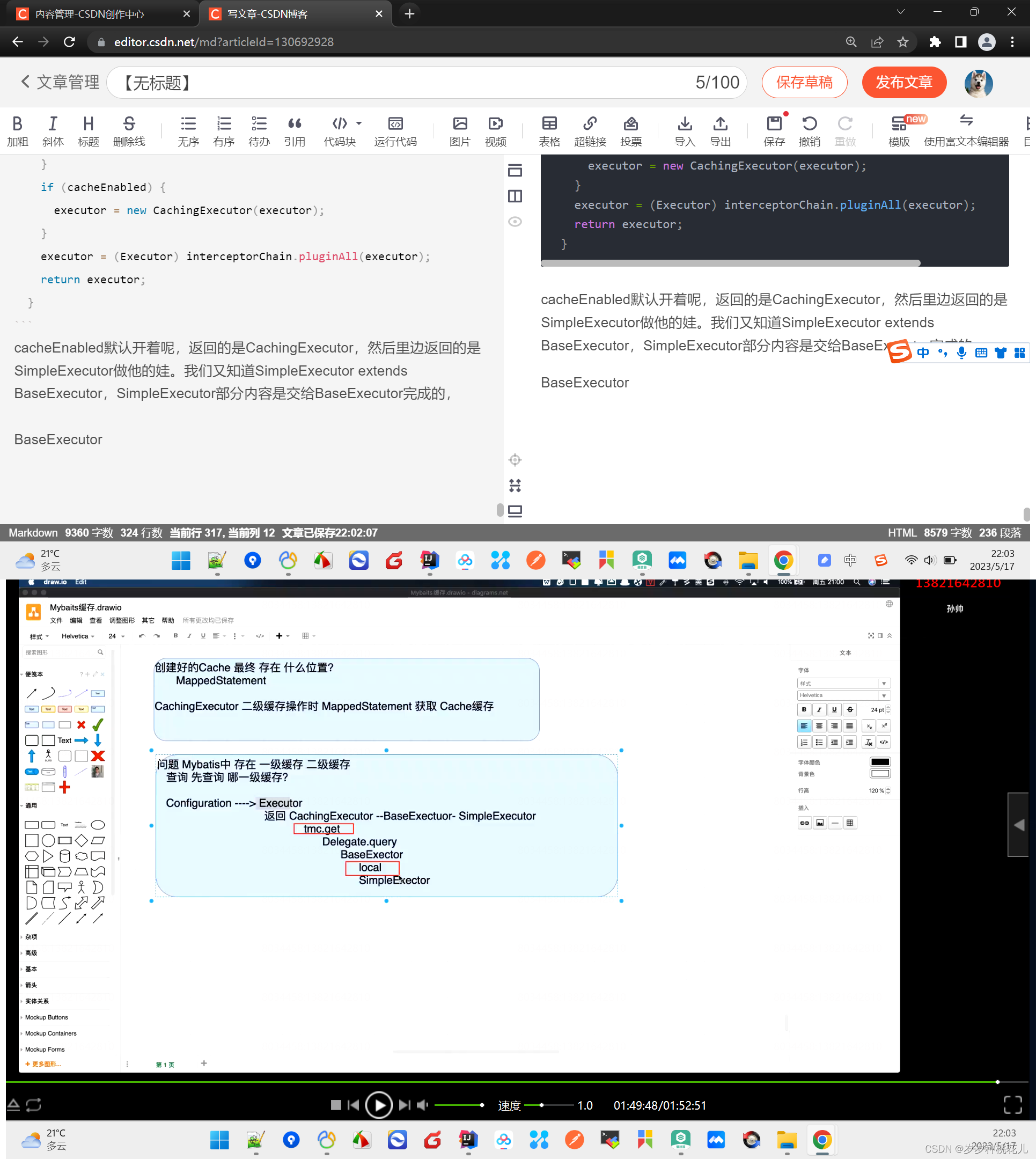
tmc.get是二级缓存,local是一级缓存。所以是先走二级,在走一级缓存
debug证明我们分析的是正确的。
去看CachingExecutor当中的query方法即可。
![CodeForces..最新行动.[中等].[遍历].[判断]](https://img-blog.csdnimg.cn/f3c43c741a80456a9cb2a5ac52d7a08b.png)

![2023《中国好声音》全国巡演Channel[V]歌手大赛广州赛区半决赛圆满举行!](https://img-blog.csdnimg.cn/img_convert/476a1dab1cb6a9d07d4997b2d14983e8.jpeg)

![[图表]pyecharts模块-日历图](https://img-blog.csdnimg.cn/ebf7e5b242b44bce97b4f06b6afd53dd.png#pic_center)





![[图表]pyecharts模块-柱状图2](https://img-blog.csdnimg.cn/c8b3348eeb34417cb2d867db12632e15.png#pic_center)
![【群智能算法改进】一种改进的算术优化算法 改进算术优化算法 改进AOA[1]【Matlab代码#37】](https://img-blog.csdnimg.cn/8e085f0699494594a1e2dad205f2b5a0.png#pic_center)