JAVA用tess4j识别复杂的验证码,自定义字库,计算题验证码
- 场景
- JAVA用tess4j识别文本
- MAVEN依赖
- traineddata文件下载
- 识别英文
- 识别中文
- JAVA用tess4j识别验证码
- 常见验证码的类型
- 识别
- 自定义字库,提高识别率
- 下载jTessBoxEditor
- 解压
- 运行
- 准备素材
- 合并PNG为tif文件
- 生成box文件
- 使用jTessBoxEditor工具对tif文件进行校准
- 校正
- 生成tr文件
- 生成生成字符集文件unicharset文件
- 生成font_properties文件(不需要扩展名,切记)
- 生成shape文件
- 生成聚字符特征文件
- 生成字符正常化特征文件
- 把inttemp、pffmtable、shapetable、normproto四个文件命名为`[lang].xxx`
- 合并训练文件成成traineddata文件
- 使用自定义的字库进行识别
- 用脚本引擎识别计算出结果
- 其他注意事项
场景
在爬虫爬取数据的过程中可能会遇到各种验证码,导致爬虫无法继续。本文讲解如果在java中如何使用tess4j识别图片中的文本、自定义模型。
JAVA用tess4j识别文本
MAVEN依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.6.0</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.15</version>
</dependency>
等下需要用到脚本引擎计算表达式
traineddata文件下载
github下载地址:https://github.com/tesseract-ocr/tessdata
常用的语言及其traineddata文件对照表
| 语言 | 文件 |
|---|---|
| 简体中文 | chi_sim.traineddata |
| English | eng.traineddata |
识别英文
代码
package com.beiyoufamily;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author Yi Dai 484201132@qq.com
* @since 2023/6/3 15:25
*/
public class EnglishIdentification {
public static void main(String[] args) throws TesseractException {
//要是别的验证码图片
File captchaImageFile = new File("C:/Files/images/captcha/test/English.png");
//创建tesseract对象
Tesseract tesseract = new Tesseract();
//设置traineddata文件目录
tesseract.setDatapath("C:/Files/images/captcha/traineddata");
//设置语言(不需要写扩展名)
tesseract.setLanguage("eng");
String result = tesseract.doOCR(captchaImageFile);
System.out.println(result);
}
}
运行结果: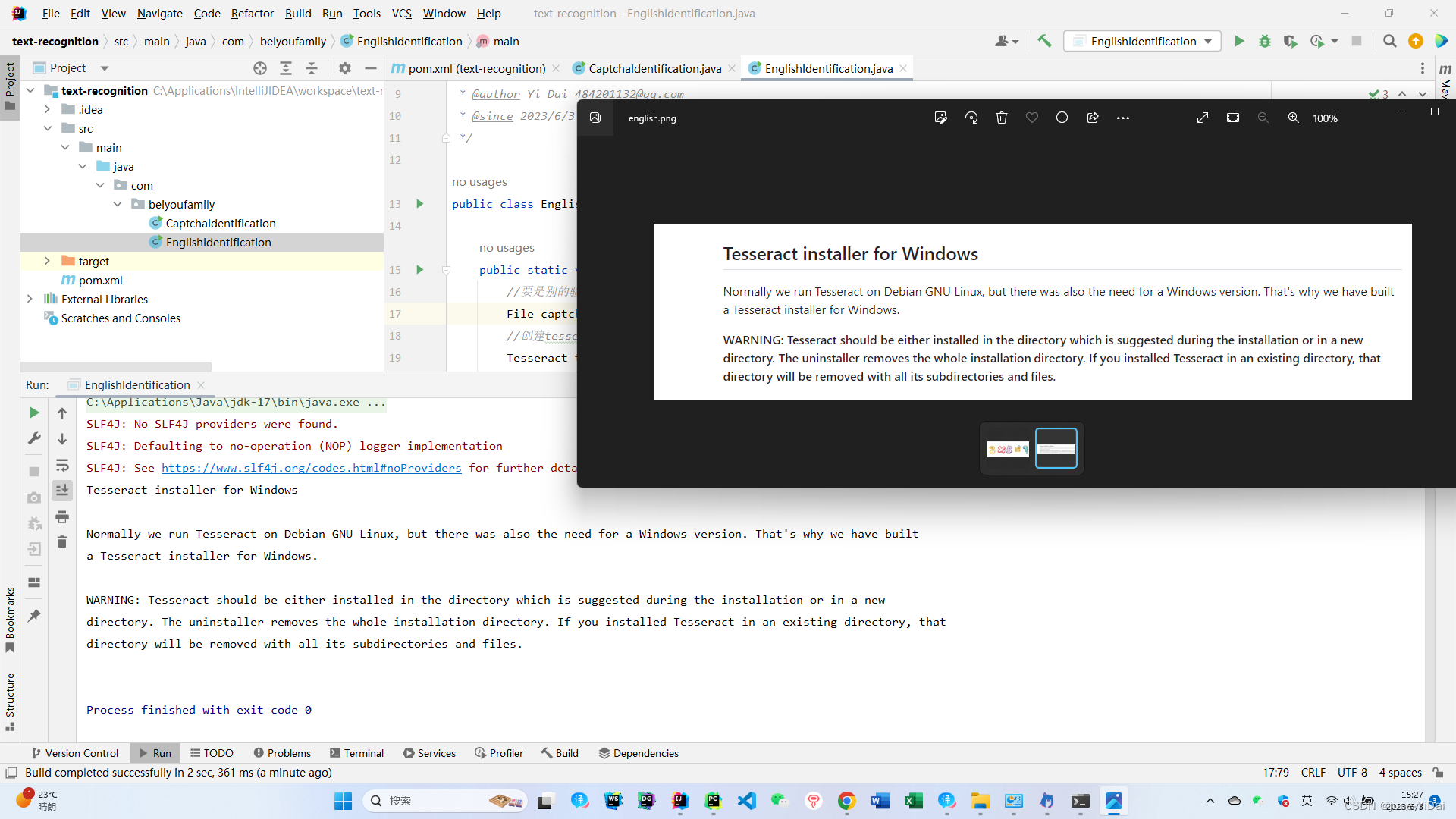
标准的英文字符识别率非常高
识别中文
代码
package com.beiyoufamily;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author Yi Dai 484201132@qq.com
* @since 2023/6/3 15:25
*/
public class ChineseIdentification {
public static void main(String[] args) throws TesseractException {
//要是别的验证码图片
File captchaImageFile = new File("C:/Files/images/captcha/test/Chinese.png");
//创建tesseract对象
Tesseract tesseract = new Tesseract();
//设置traineddata文件目录
tesseract.setDatapath("C:/Files/images/captcha/traineddata");
//设置语言(不需要写扩展名)
tesseract.setLanguage("chi_sim");
String result = tesseract.doOCR(captchaImageFile);
System.out.println(result);
}
}
运行结果

看了一下识别结果,不能说不太准确,只能说是非常糟糕。总所周知tess4j除了对中文不太友好以外,其他语言都挺准确的。
JAVA用tess4j识别验证码
常见验证码的类型
-
数字类型

-
滑块验证码
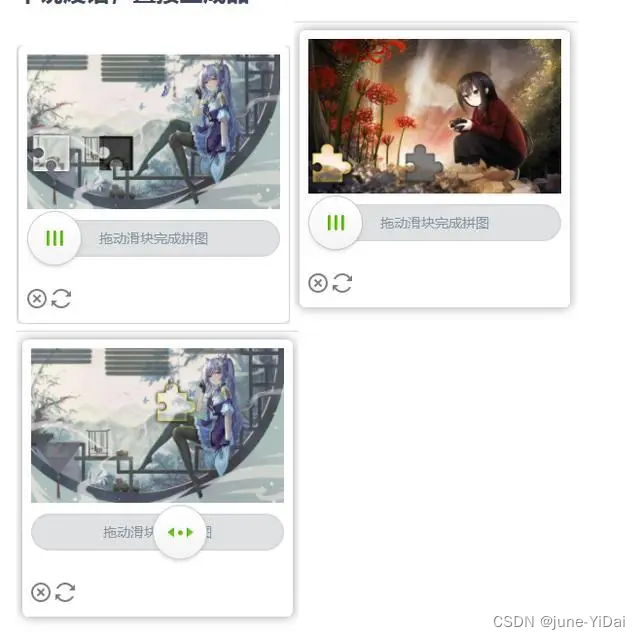
-
计算题

…
识别
上述验证码中,第一种数字类型的比较简单,只需要对图像做二值化之后进行识别,准确率还是很高的,第二种滑块的验证码比较恶心,今天暂时不讨论它;今天讨论的是第三种,计算题验证码(方法同样适用于第一种验证码)。
代码
package com.beiyoufamily;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author Yi Dai 484201132@qq.com
* @since 2023/6/3 15:09
*/
public class CaptchaIdentification {
public static void main(String[] args) throws TesseractException {
//要是别的验证码图片
File captchaImageFile = new File("C:/Files/images/captcha/test/captcha.png");
//创建tesseract对象
Tesseract tesseract = new Tesseract();
//设置traineddata文件目录
tesseract.setDatapath("C:/Files/images/captcha/traineddata");
//设置语言(不需要写扩展名)
tesseract.setLanguage("eng");
String result = tesseract.doOCR(captchaImageFile);
System.out.println(result);
}
}
运行结果
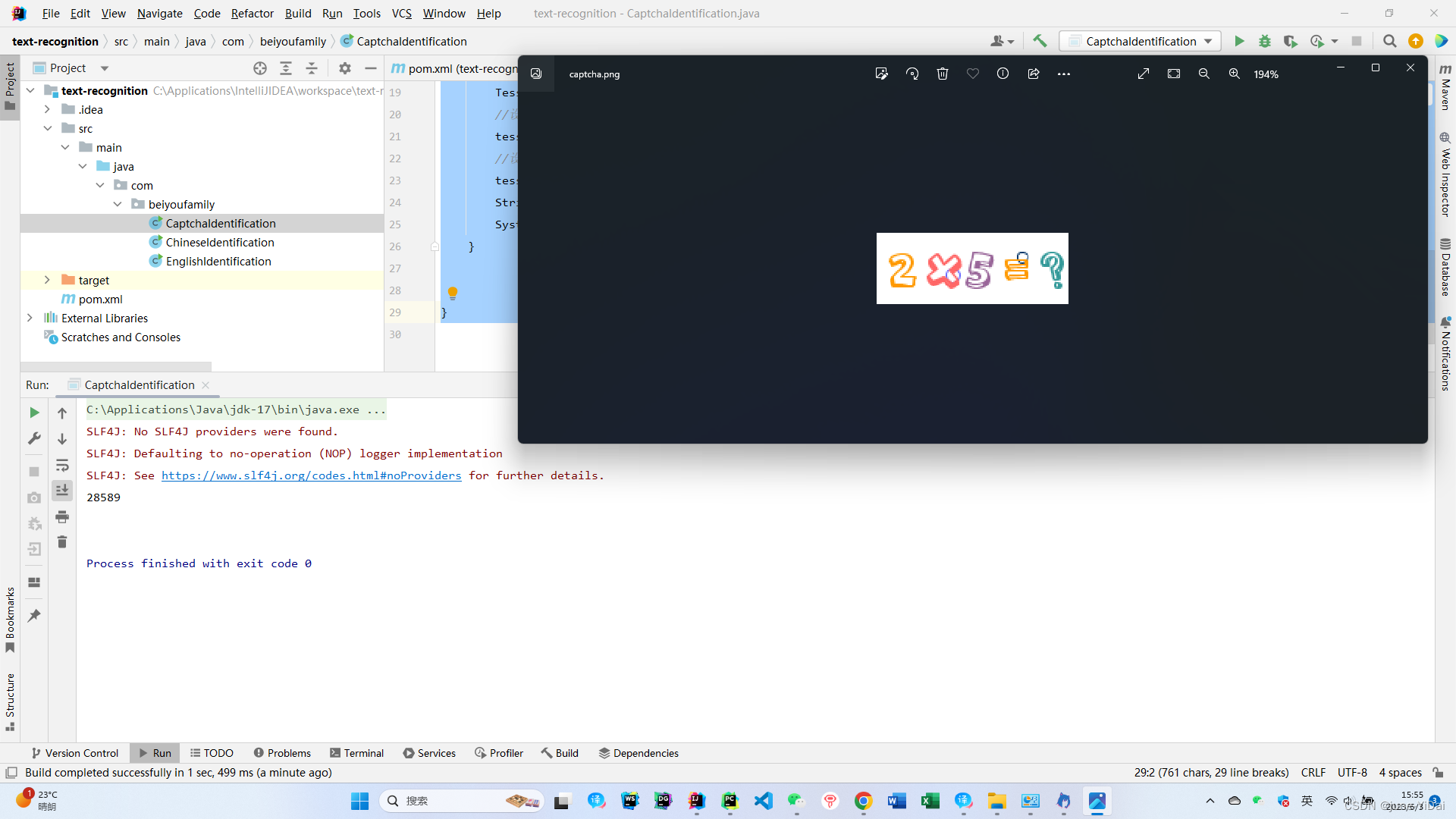
很尴尬,除了两个数字被正确识别之外,符号一个没识别出来,换成中文识别率更低,有兴趣的小伙伴可以试试其他语言。很显然这不是我们想要的效果,所以引出今天的重点——自定义字库
自定义字库,提高识别率
下载jTessBoxEditor
官网下载:https://udomain.dl.sourceforge.net/project/vietocr/jTessBoxEditor/jTessBoxEditor-2.4.1.zip
解压
运行
双击jTessBoxEditor.jar运行
准备素材
素材当然是越多越好,这样训练出来之后识别率会更高
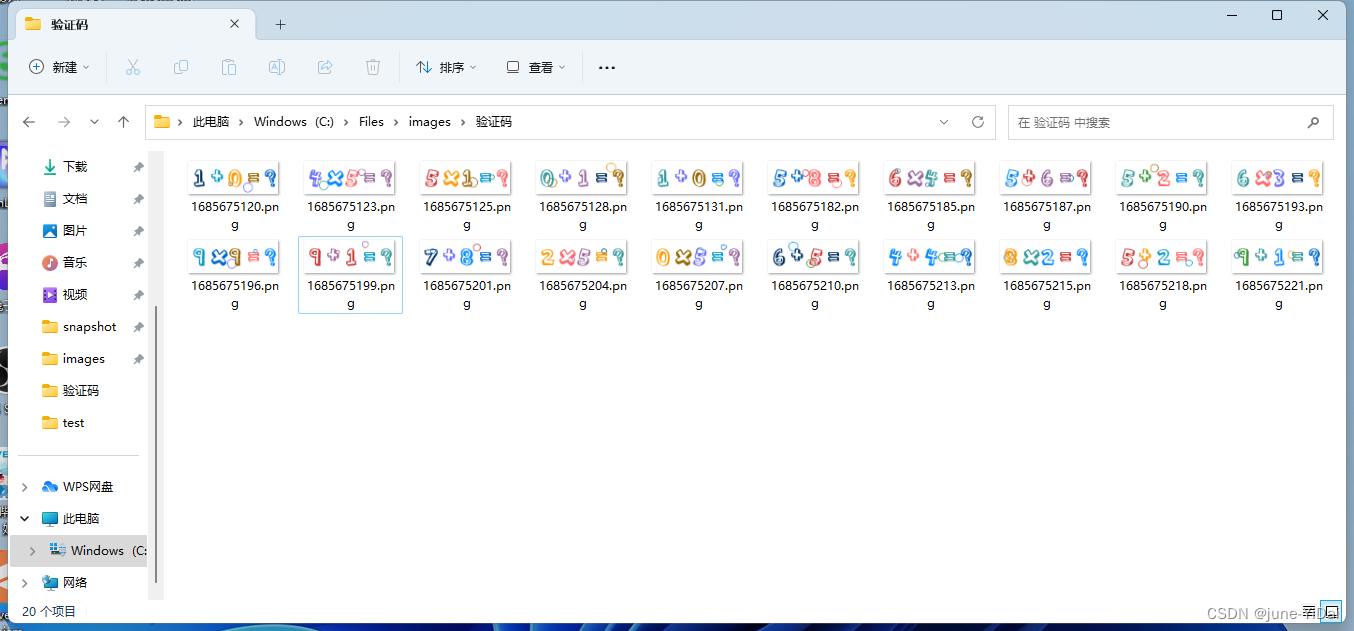
合并PNG为tif文件
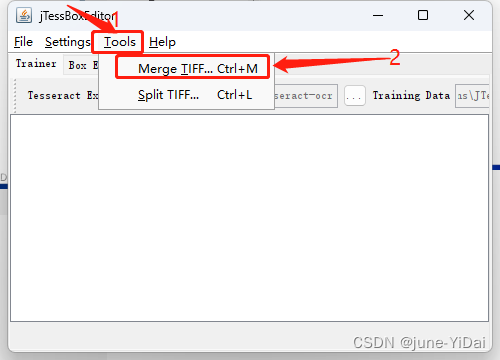
依次点击Tools - Merge TIFF...
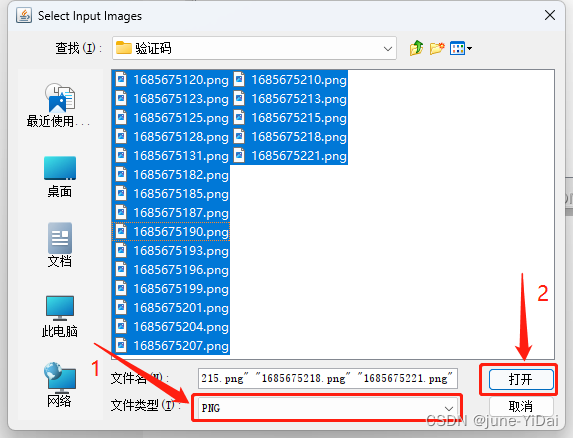
文件类型选为png(根据实际类型选择),不然看不到你的文件,全选素材,然后点击打开
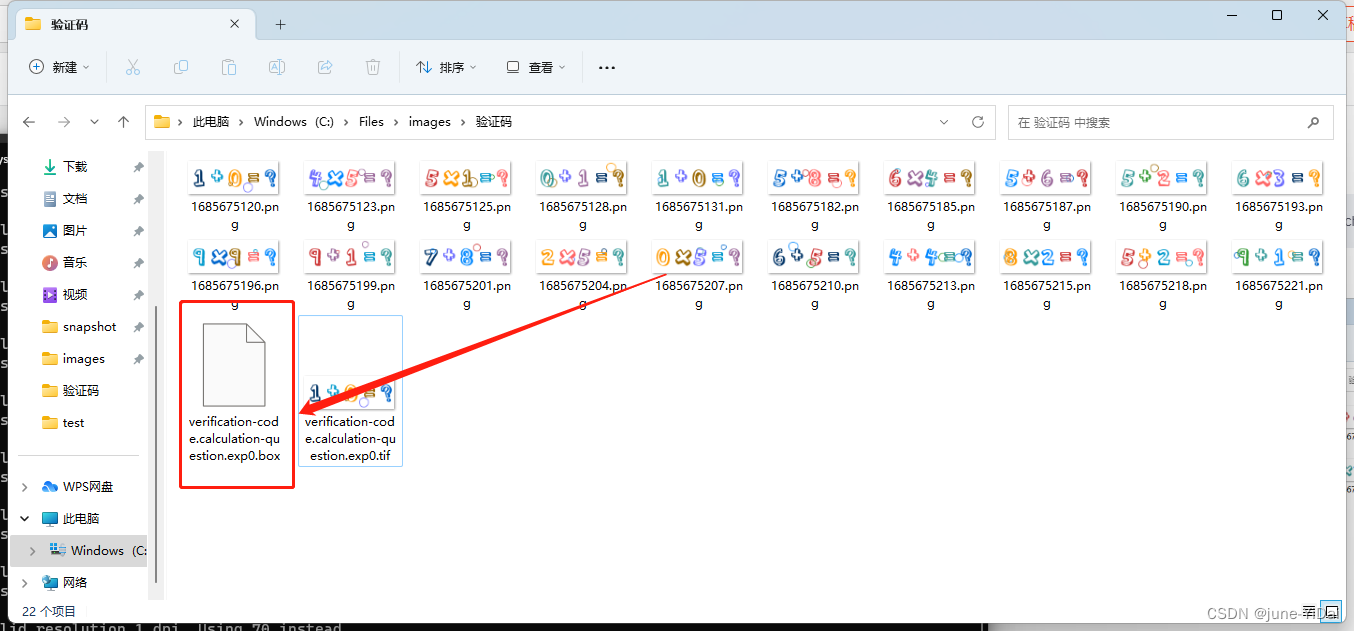
注意!!! 这一步的文件名是有讲究的,不能随意命名!
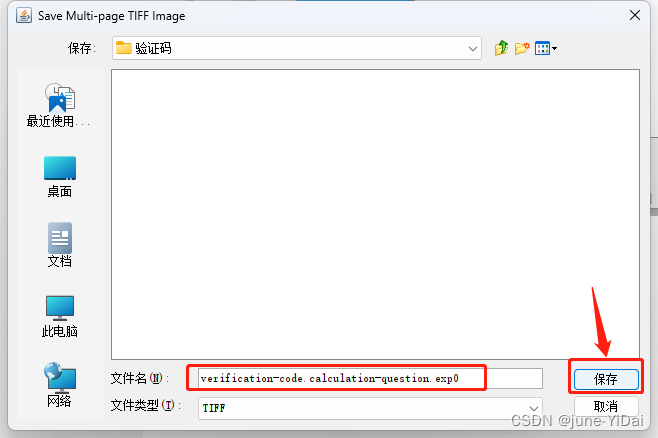
tif文件命名格式需规范,格式为[lang].[fontname].exp[num].tif,lang为语言名称,fontname为字体名称,num为序号。例如上图所示的:verification-code.calculation-question.exp0.tif(扩展名可以自动加,只要文件类型选对的)
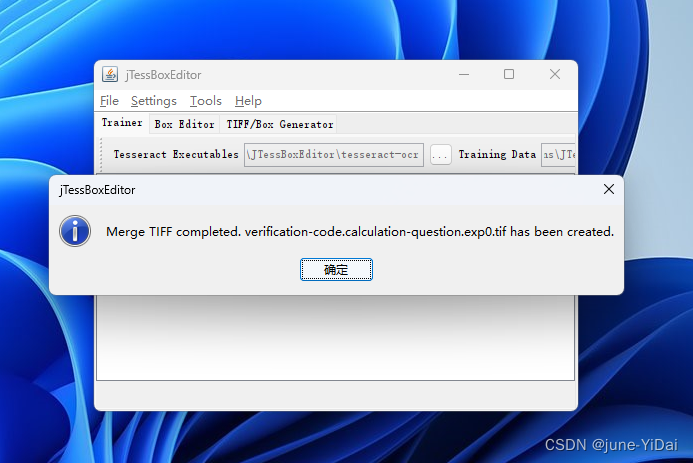
点击确定,即可合并完成
生成box文件
在刚才tif文件生成的目录执行命令:
tesseract verification-code.calculation-question.exp0.tif verification-code.calculation-question.exp0 batch.nochop makebox
执行结果:
使用jTessBoxEditor工具对tif文件进行校准
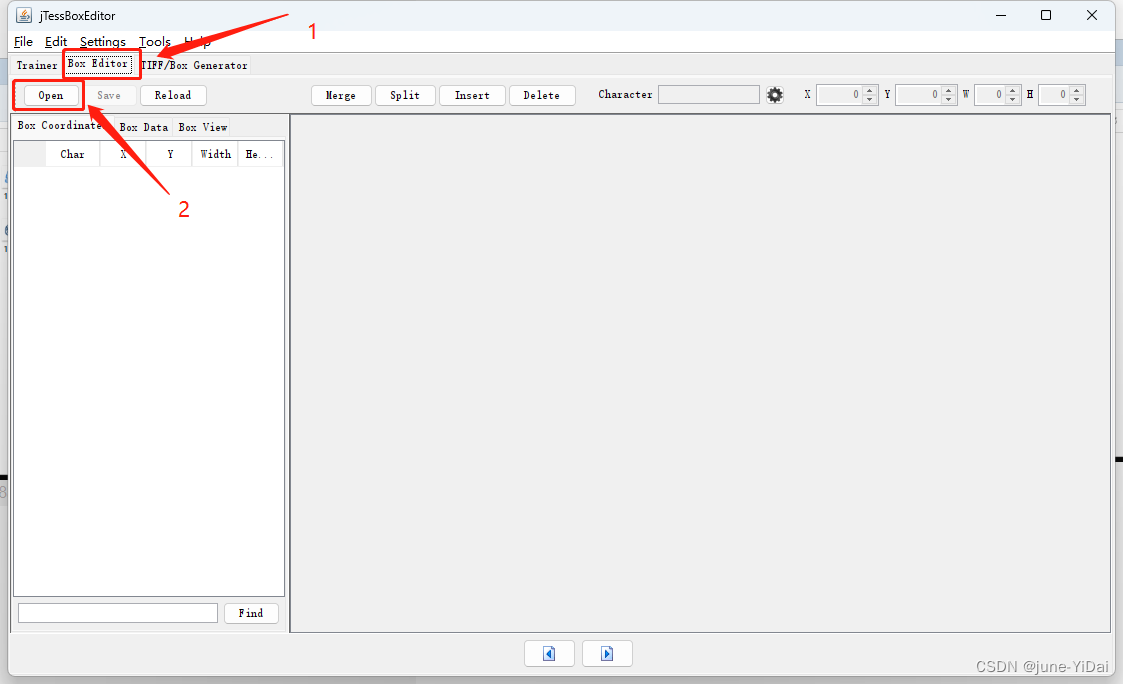
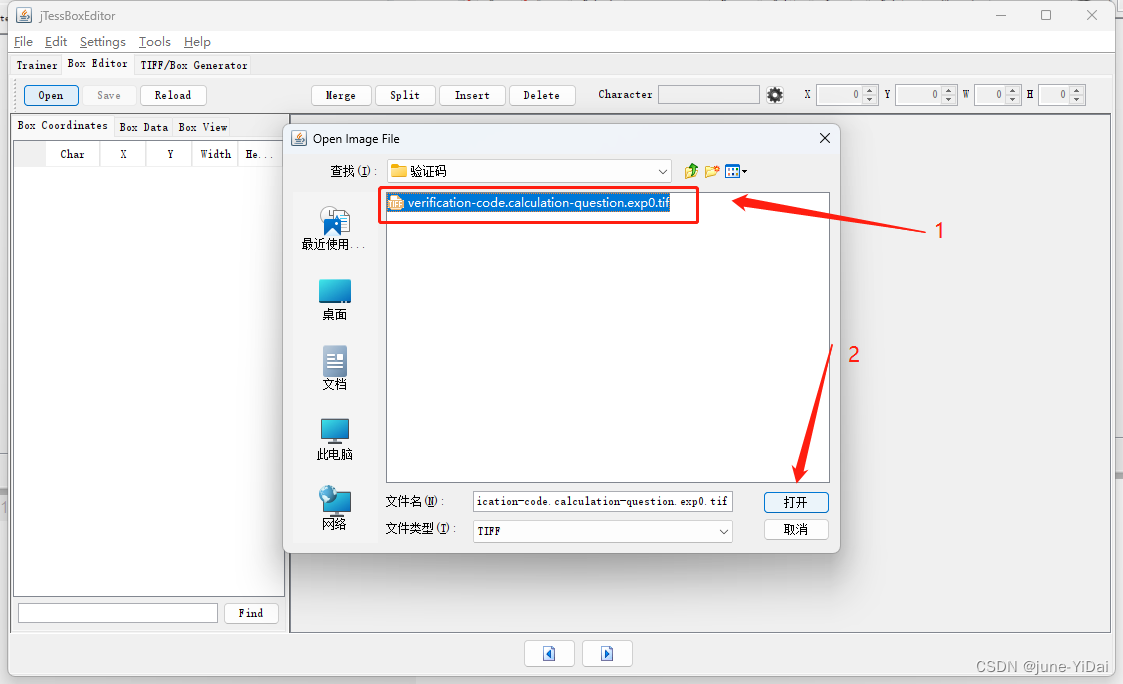
依次点击Box Editor - Open 然后选择刚才生成的tif文件,选择之后他会自动关联上对应的box文件
校正
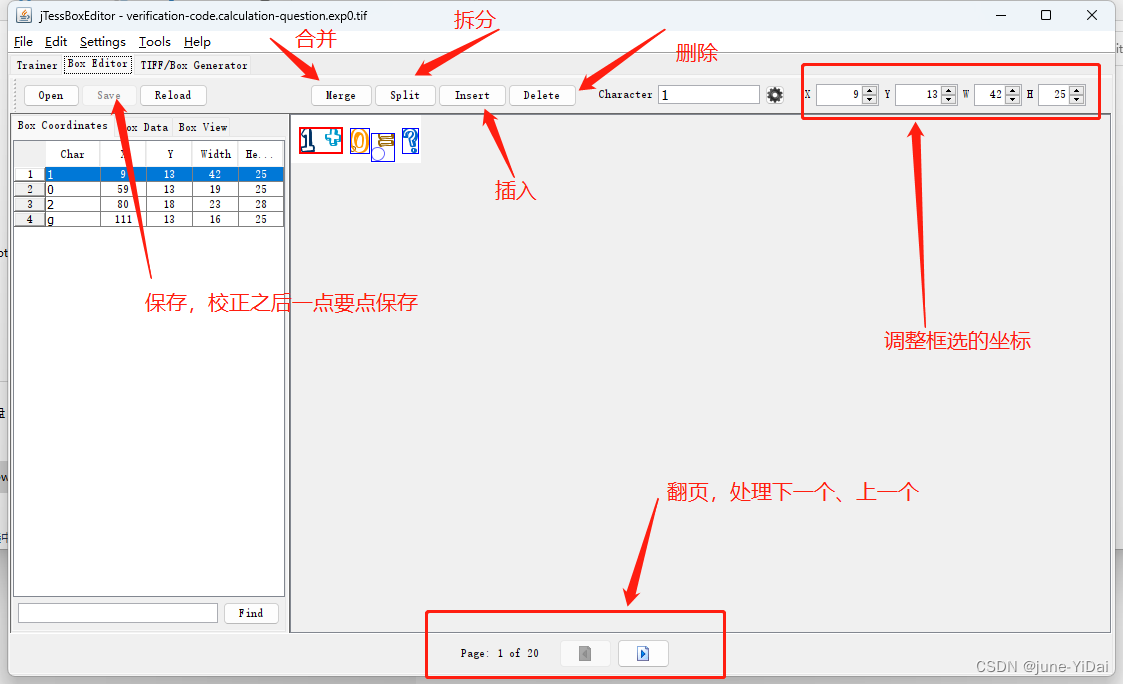
示例:
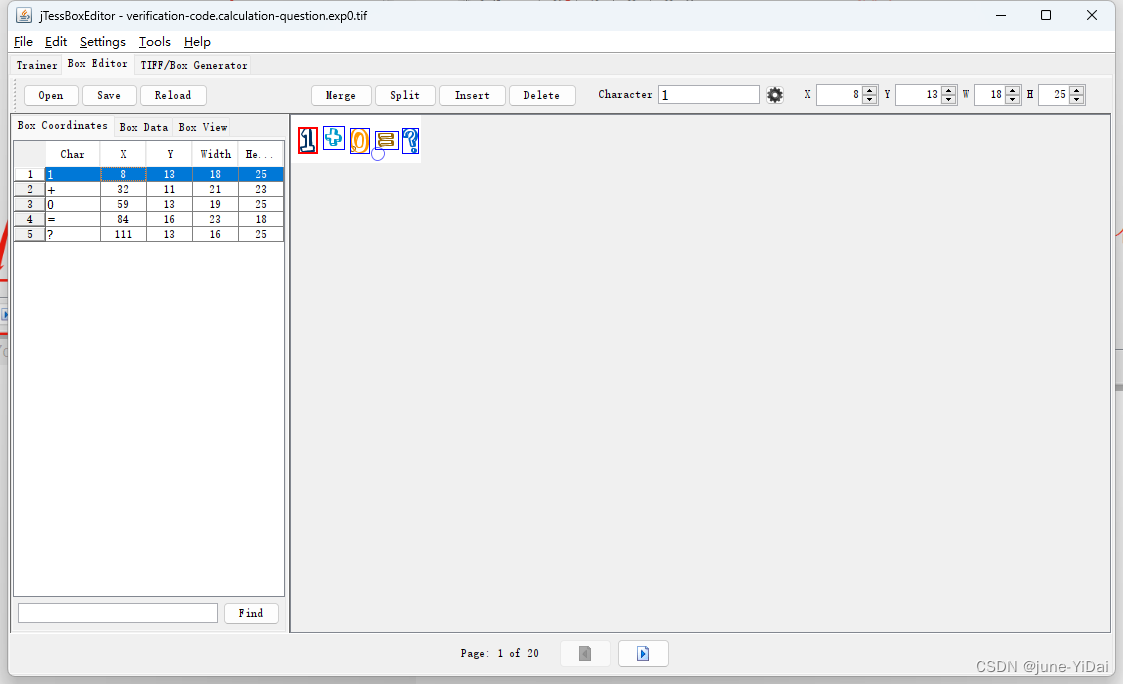
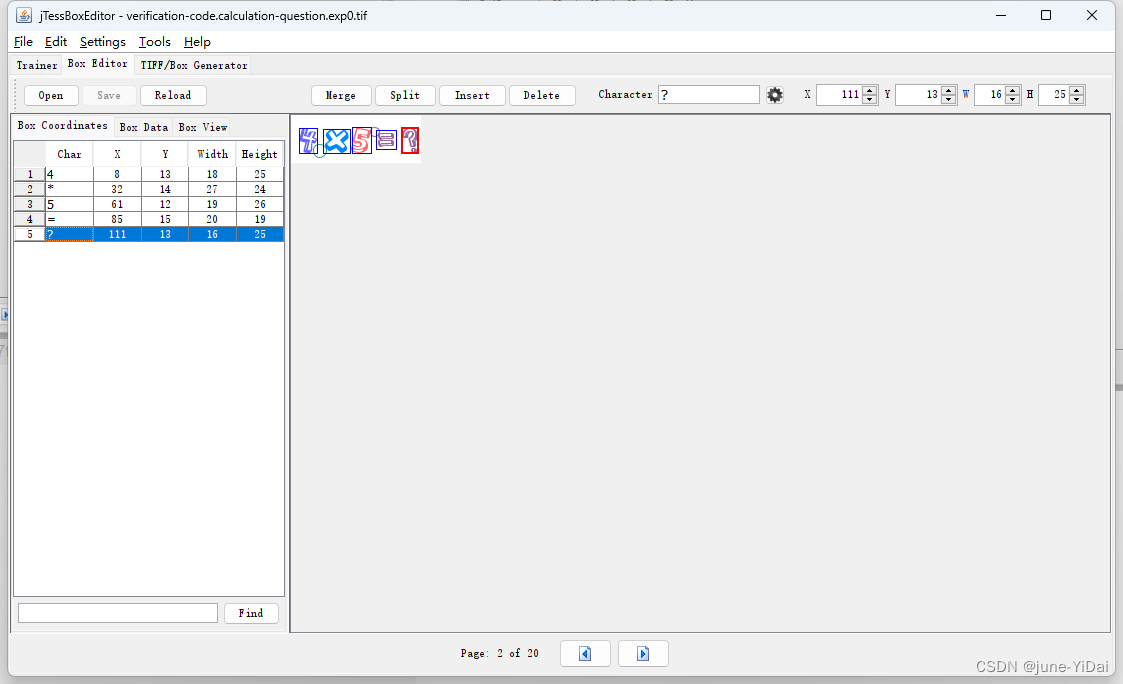
以此类推,把后面的字符和位置全部校正,这个过程有点枯燥
生成tr文件
在刚刚的tif文件所在目录执行命令:
tesseract verification-code.calculation-question.exp0.tif verification-code.calculation-question.exp0 nobatch box.train
执行结果:
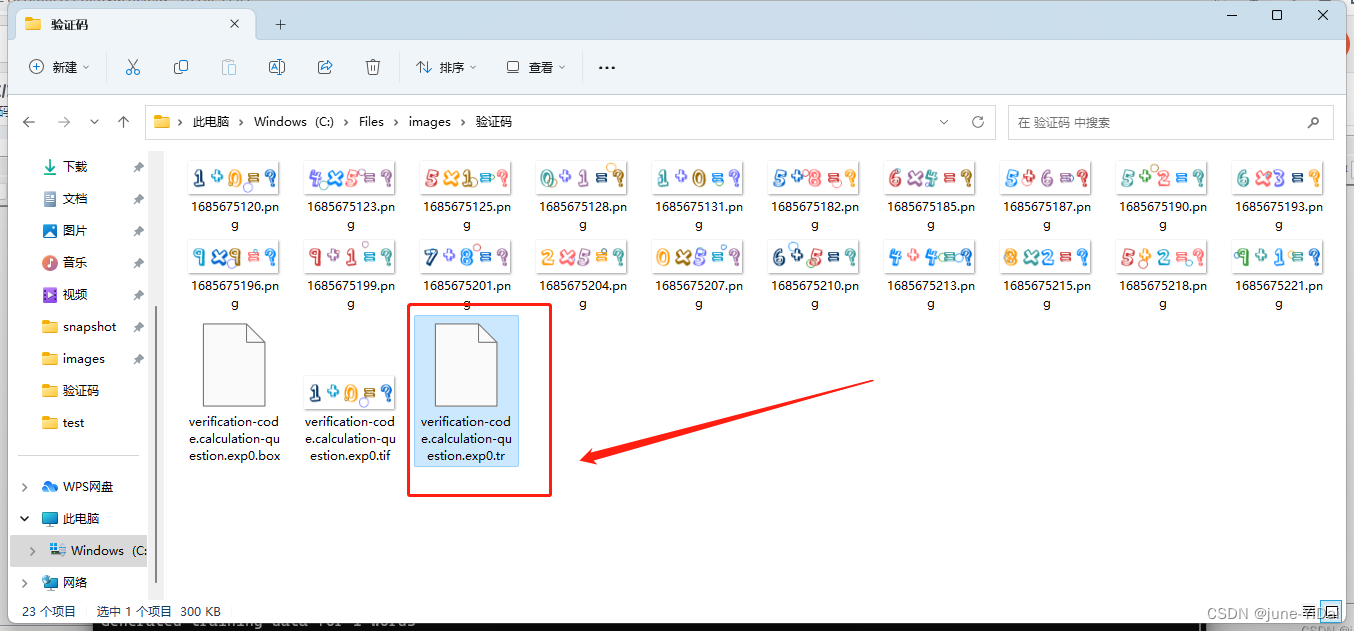
生成生成字符集文件unicharset文件
同样的目录中执行命令:
unicharset_extractor verification-code.calculation-question.exp0.box
执行结果:
生成font_properties文件(不需要扩展名,切记)
执行命令:
echo normal 0 0 0 0 0 > font_properties
执行结果:
生成shape文件
执行命令:
shapeclustering -F font_properties -U unicharset -O verification-code.unicharset verification-code.calculation-question.exp0.tr
执行结果:
生成聚字符特征文件
执行命令:
mftraining -F font_properties -U unicharset -O unicharset verification-code.calculation-question.exp0.tr
执行结果:
生成字符正常化特征文件
执行命令:
cntraining verification-code.calculation-question.exp0.tr
执行结果:

把inttemp、pffmtable、shapetable、normproto四个文件命名为[lang].xxx
分别执行下面四个重命名命令:
rename normproto verification-code.normproto
rename inttemp verification-code.inttemp
rename pffmtable verification-code.pffmtable
rename shapetable verification-code.shapetable
执行结果:

合并训练文件成成traineddata文件
执行命令:
combine_tessdata verification-code
执行结果:
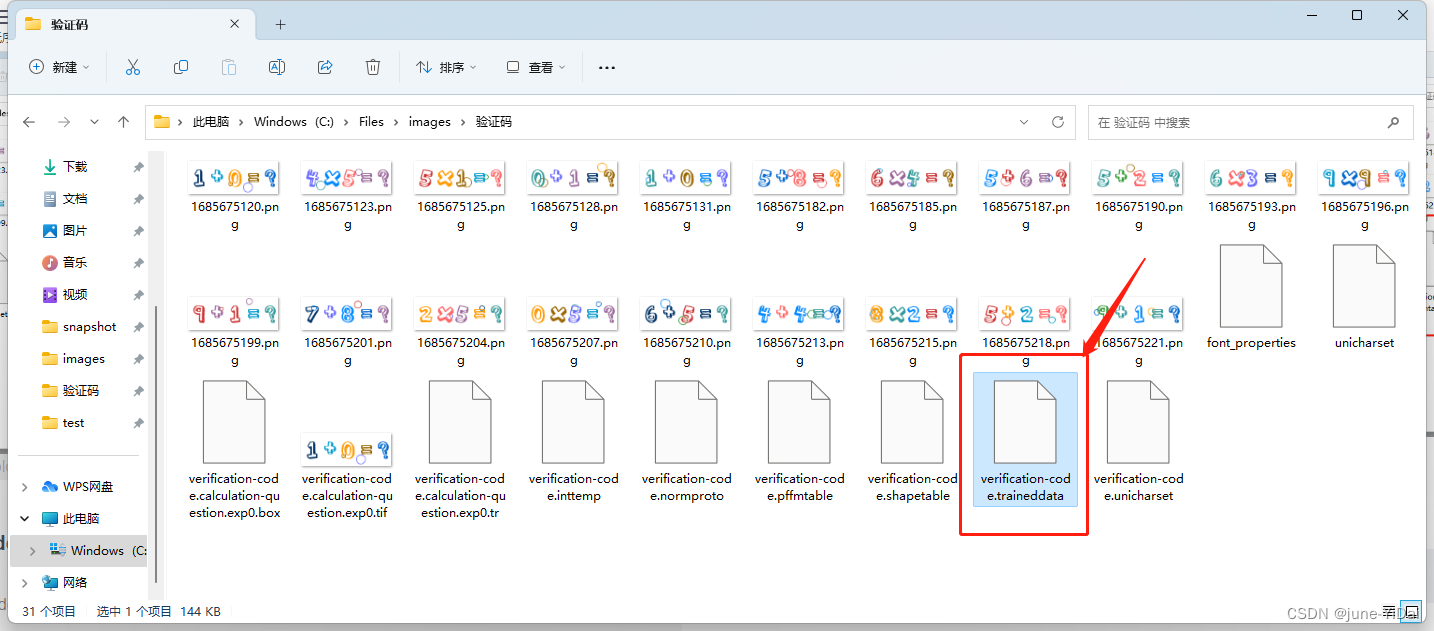
自此,训练完成!
使用自定义的字库进行识别
代码:(verification-code为刚才训练所得的)
package com.beiyoufamily;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author Yi Dai 484201132@qq.com
* @since 2023/6/3 15:09
*/
public class CaptchaIdentification {
public static void main(String[] args) throws TesseractException {
//要是别的验证码图片
File captchaImageFile = new File("C:/Files/images/captcha/test/captcha.png");
//创建tesseract对象
Tesseract tesseract = new Tesseract();
//设置traineddata文件目录
tesseract.setDatapath("C:/Files/images/captcha/traineddata");
//设置语言(不需要写扩展名)
tesseract.setLanguage("verification-code");
String result = tesseract.doOCR(captchaImageFile);
System.out.println(result);
}
}
运行结果:
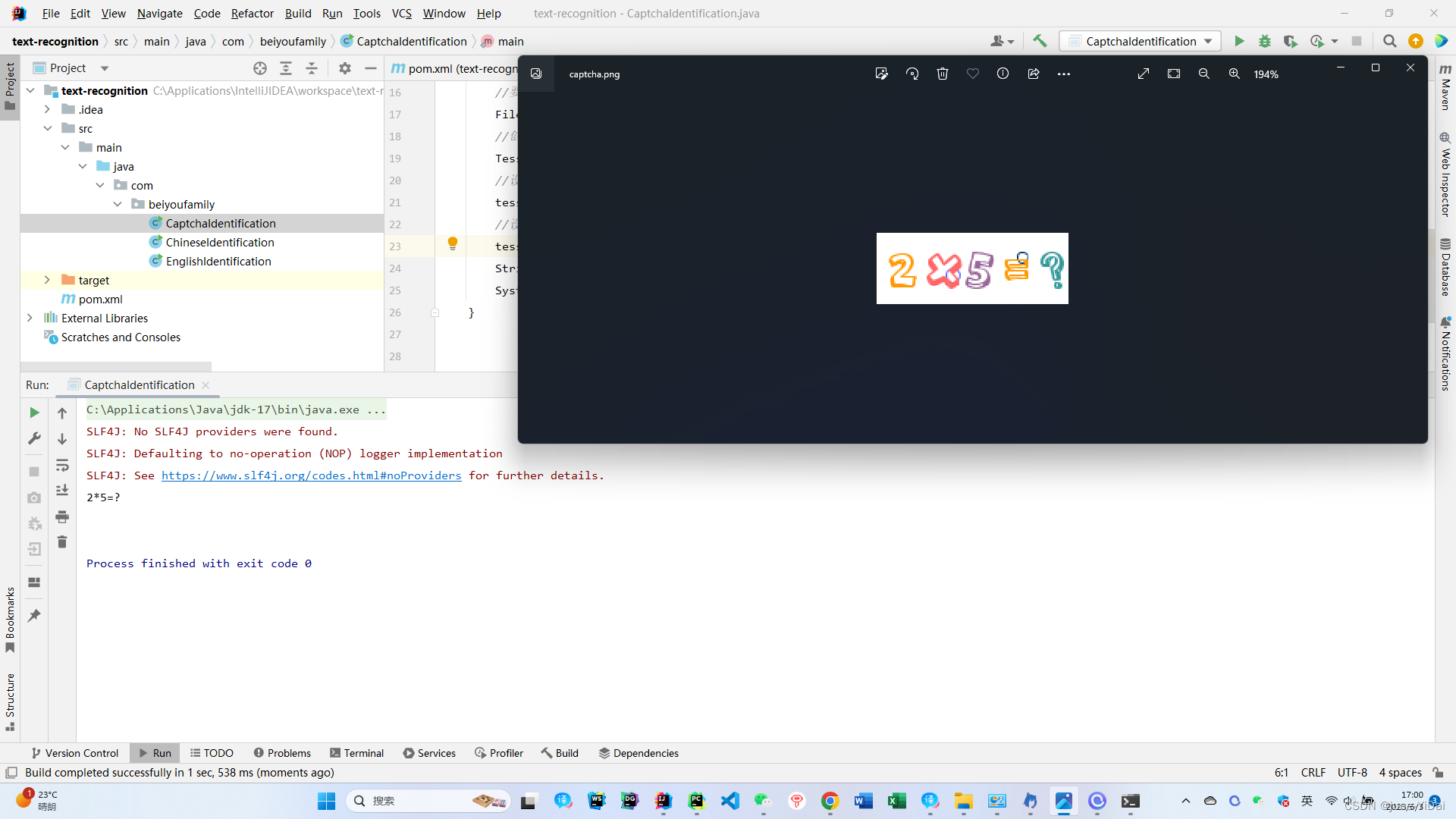
非常完美,精确的识别出了表达式!
用脚本引擎识别计算出结果
package com.beiyoufamily;
import cn.hutool.script.ScriptUtil;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
import java.util.Objects;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author Yi Dai 484201132@qq.com
* @since 2023/6/3 15:09
*/
public class CaptchaIdentification {
public static void main(String[] args) throws TesseractException {
//要是别的验证码图片
File captchaImageFile = new File("C:/Files/images/captcha/test/captcha.png");
//创建tesseract对象
Tesseract tesseract = new Tesseract();
//设置traineddata文件目录
tesseract.setDatapath("C:/Files/images/captcha/traineddata");
//设置语言(不需要写扩展名)
tesseract.setLanguage("verification-code");
String result = tesseract.doOCR(captchaImageFile);
if (Objects.nonNull(result)) {
//去除所有的空白字符
result = result.replaceAll("\\s*", "").trim();
String pattern = "\\d+[+\\-*/]\\d+=\\?";
//判断识别出来的表达式是否合法
if (Pattern.matches(pattern, result)) {
//提取表达式
Matcher matcher = Pattern.compile("\\d+[+\\-*/]\\d+").matcher(result);
if (matcher.find()) {
String expression = matcher.group();
System.out.println(expression);
System.out.println(ScriptUtil.eval(expression));
}
}
}
}
}
计算结果:
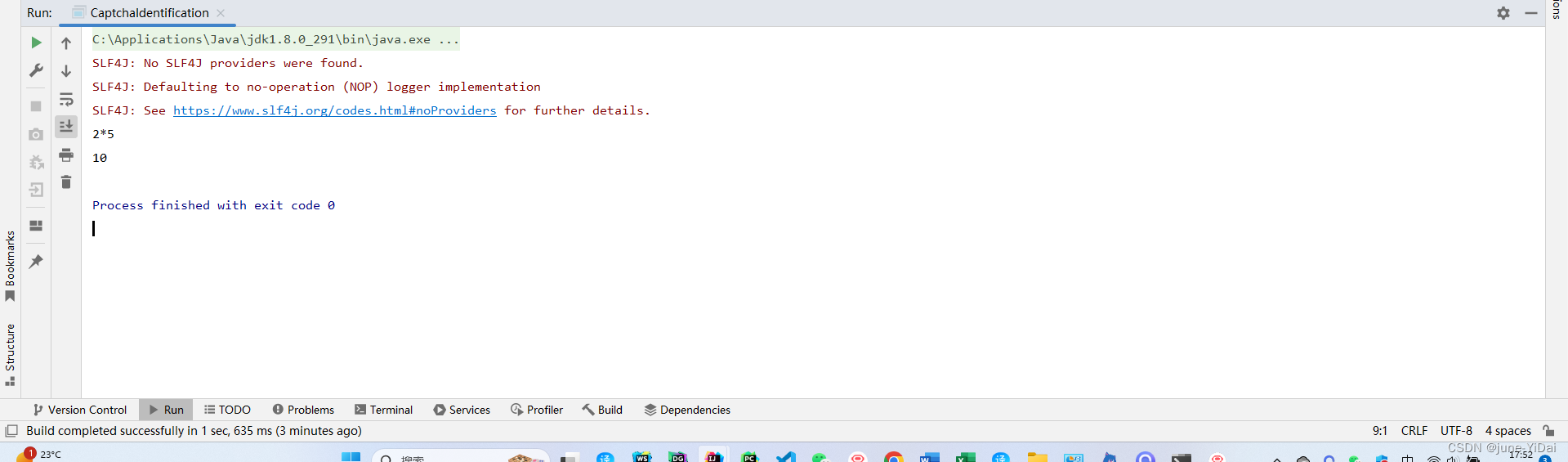
其他注意事项
本演示示例是在Java8环境中运行的,高版本的Java环境可能会没有脚本引擎,会报错





![[图表]pyecharts-3D柱状图](https://img-blog.csdnimg.cn/0cbebce1826541588b1fba100fb77082.png#pic_center)