一个有趣的问题:Unbounded memory usage by TCP for receive buffers, and how we fixed it
引出一个 kernel patch:[PATCH] Add a sysctl to allow TCP window shrinking in order to honor memory limits
但这 patch 把一个问题变成了两个问题:关闭 tcp_shrink_window,则未修复内存占满问题,打开 tcp_shrink_window,如下图所示:
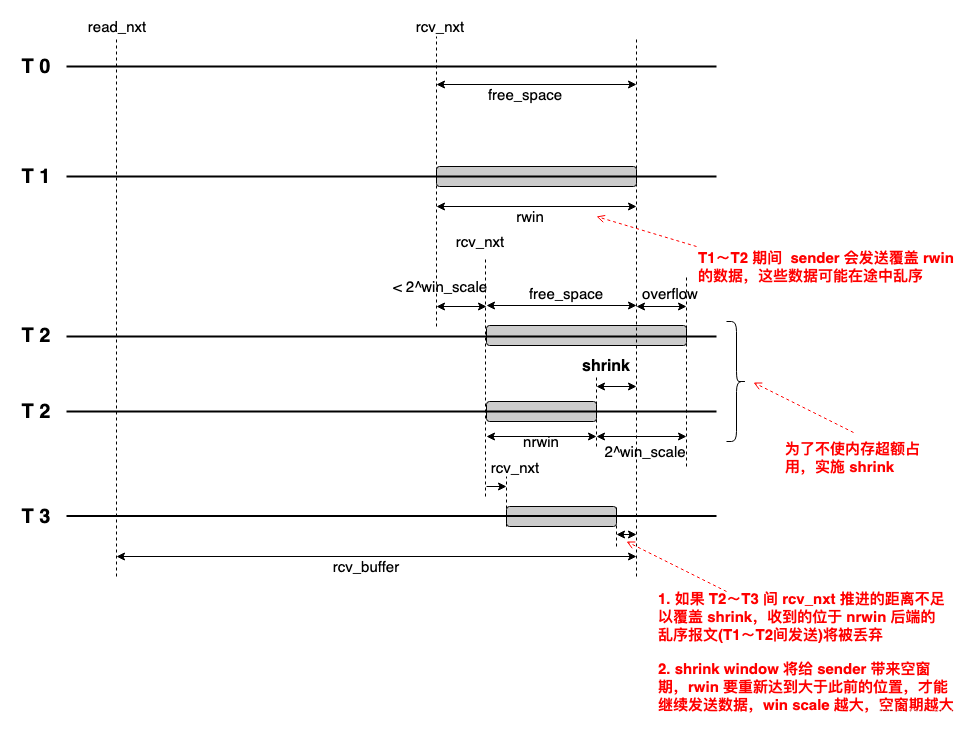
RFC 7323 附录 F 明确了这个问题有两种做法,把两个方法结合最高尚,而不是彻底解决一个引入另一个:只允许 rcvbuff 超额一次,直到 read_nxt 腾出的空间大于 overflow 额度。做法很简单:
- tcp_select_window 检测到 overflow(即需要 shrink),记录 over_quota = rwin_curr - free_space,anch = read_nxt,返回实际 2^win_scale 下取整后的 rwin,不改变 tcp_sock: rcv_wnd。
- 当 read_nxt - anch <= over_quota 时,返回减去推进值后的实际剩余 rwin(2^win_scale 下取整),不改变 tcp_sock: rcv_wnd。
- 当 read_nxt - anch > over_quota 后,恢复正常。
简单总结就是,通告给 sender 的 rwin 按 shrink 方式,receiver 端验证的 rwin 按 overflow 方式。
多说一句,对于 sender,如收到 shrink,就不要重传 rwin 外已发出的数据,因为这是由于 shrink window 丢的,而不是网络拥塞丢的。这件事告诉我们,得到一个明确的信息,对辅助判断决策是多么有意义。
直到 Linux kernel v6.3-rc5,这个问题依然存在,谁来解一下?
下面段落是短评。
So ?都是反馈惹的祸,反馈需要时间,这个时间很久,夜长梦就多,别指望反馈才能彻底解决问题,同时又避免了 burst,用 pacing 替代 rwin,就像用 pacing 替代 cwnd 一样,作为 primary controller,把反馈的时间平滑掉。
反馈慢也是个背锅的。本质原因是 receiver 的 rcvbuff 按 byte 推进,而 rwin 按 2^win_scale 倍数推进,一开始引入 win_scale option 的时候这问题就没有考虑到,以至于事情变得越来越复杂,TCP 几乎所有问题都因此而来,而 QUIC 作为 another TCP,它几乎就是 TCP 的影子,QUIC 的优势在于它比 TCP 更容易快速迭代,它在应用程序尺度更新,而无需照顾泛化。
但这不能否认 TCP 作为一个极简协议开始的功劳,TCP/IP 不完美,永远也不会完美,但这正是它的成功之道,立命之本,TCP/IP 和以太网一样,在完备的标准化前先大量部署,成为既成事实,而不是反过来先追求标准化,反例请参考 OSI 模型。
不多说。
浙江温州皮鞋湿,下雨进水不会胖。