水善利万物而不争,处众人之所恶,故几于道💦
目录
1. 使用Sqoop脚本将MySQL中的数据迁移到HDFS
2. 在Hive中建立与之对应的表
3. 将HDFS中的数据load到 Hive 数仓的ODS层的表中
1 . 使用Sqoop 将 MySQL中的数据导入到HDFS上
#! /bin/bash
sqoop=/opt/module/sqoop/bin/sqoop
#do_date默认为前一天的时间
do_date=`date -d '-1 day' +%F`
#如果第二个参数没有指定导入哪天的数据,默认为前一天的数据
if [[ -n "$2" ]]; then
do_date=$2
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 000000 \
#指定导出数据的目录路径
--target-dir /origin_data/gmall/db/$1/$do_date \
#如果该目录已经存在,则删除该目录。设定此参数可以保证每次导入数据不会覆盖之前的数据。
--delete-target-dir \
#使用 SQL 查询语句导入数据,有的sql会加一个where 1=1是为了满足语法
--query "$2 and \$CONDITIONS" \
#Sqoop 并行的任务数,默认值为 4。因为它底层运行的实际上是MR中的Map,没有Reduce,默认是4个MapTask。数据导入时,建议并行度设为1
--num-mappers 1 \
--fields-terminated-by '\t' \
#启用压缩
--compress \
#设置压缩算法-lzop压缩
--compression-codec lzop \
#Hive中的Null在底层是以\N来存储的,而MySQL中的NULL就是NULL,为了导入数据的一致性
--null-string '\\N' \
--null-non-string '\\N'
#导入后立即建立lzo索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
# 导入指定的表,省略了,所有的表都应该列出来
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
#......
#所有的表,因为第一次导入为全量导入
;;
"all")
import_comment_info
import_coupon_use
#以后每次是增量导入,有些表就不用导入了
;;
esac
- 使用示例:
mysql_to_hdfs.sh all 2021-02-01 - 导出的数据用lzo压缩,并且在导出每一张表后,都立即生成lzo索引文件,因为lzo文件的切片依赖其索引文件,存放在指定的路径下
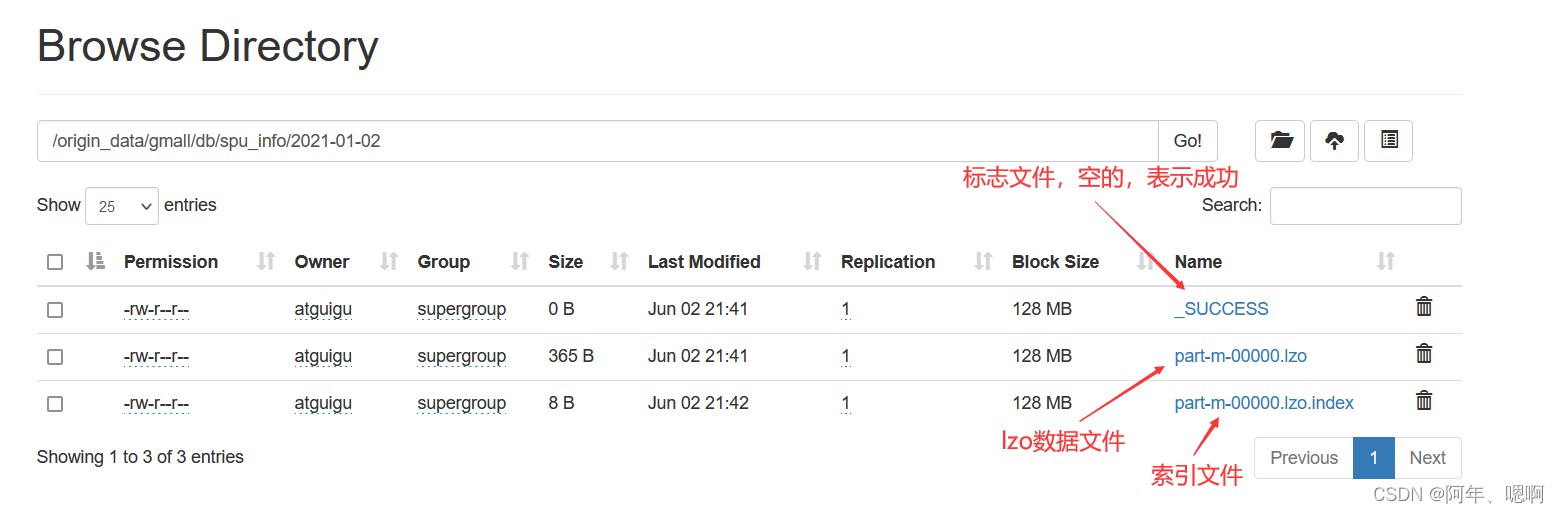
2. 在Hive中建立与之对应的表
常用的数据类型有下面这几个:
string - - - 字符型
bigint - - - 数值类型
decimal(10,2) - - - 商品的金额
decimal(16,2) - - - 支付、退款金额
数仓中一般创建的都是外部表,防止数据被误删(因为这个表的数据实际上是存储在HDFS上,并不属于Hive的数据集,所以当我们删除这个外部表的时候,只会删除它在Hive元数据中的记录,而不会删除HDFS上的数据文件,因此比较安全)
drop table if exists You_HiveTable_Name;
CREATE EXTERNAL TABLE You_HiveTable_Name (
`field_name1` string,
`field_name2` bigint,
`field_name3` decimal(10,2)
)
PARTITIONED BY (`dt` string) --分区字段
row format delimited fields terminated by '\t' --指定列分割符
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log'; --外部表的存储路径,一建表这个路径就会被创建
以上SQL是创建一个外部表,支持lzo压缩,也就是声明这个表要读取的是lzo文件,比如我进行一个查询,(如果是MapReduce)实际上底层是通过MR去读数据,然后将结果输出,MR读数据会用到FileInputFormat,那么用LzoTextInputFormat就可以读到数据了。
Hive - Lzo压缩的详细介绍及配置 - Hive官网
3. 将HDFS中的数据 load 到 Hive 数仓的ODS层的表中
#!/bin/bash
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
sql1="
load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');
"
#每张表都要load,这里省略了
sql2="
load data inpath '/origin_data/$APP/db/base_province/$do_date' OVERWRITE into table ${APP}.ods_base_province;
load data inpath '/origin_data/$APP/db/base_region/$do_date' OVERWRITE into table ${APP}.ods_base_region;
"
case $1 in
"first"){
$hive -e "$sql1$sql2"
};;
"all"){
$hive -e "$sql1"
};;
esac
这里的两个sql字符串的意思是:有的表只需要在第一次导的时候导入,导入后基本不改变,所以以后就不用导入,所以分开了。
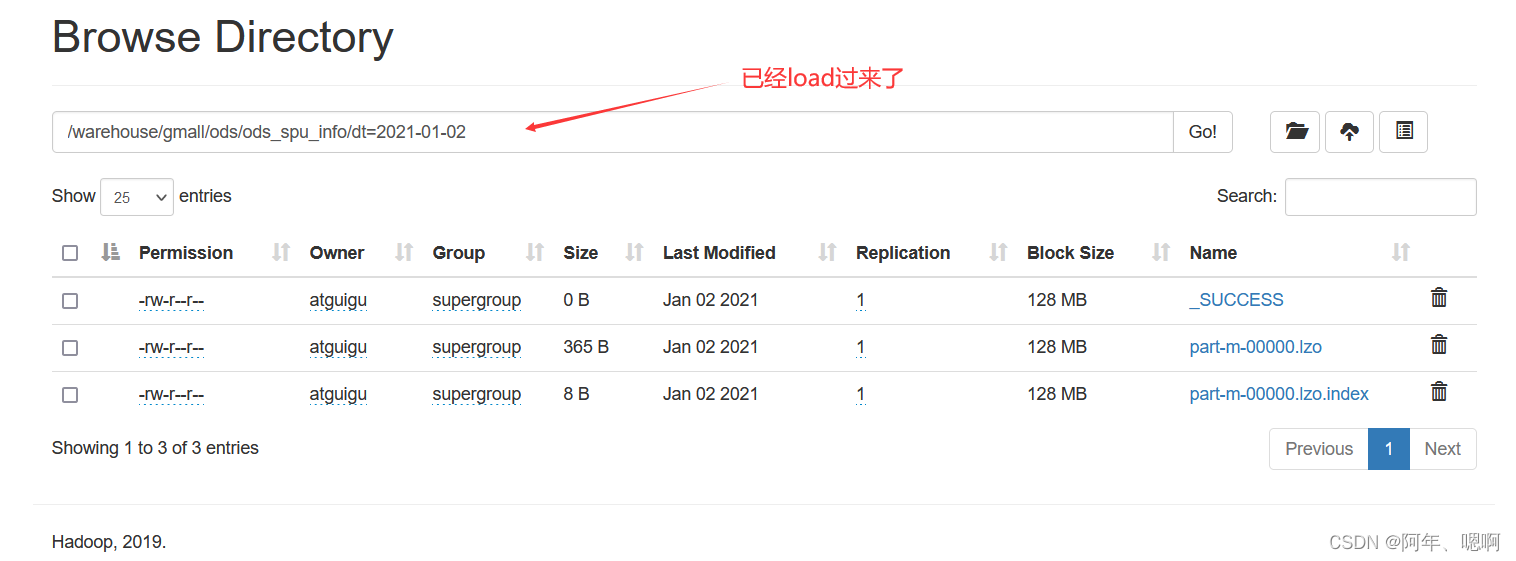
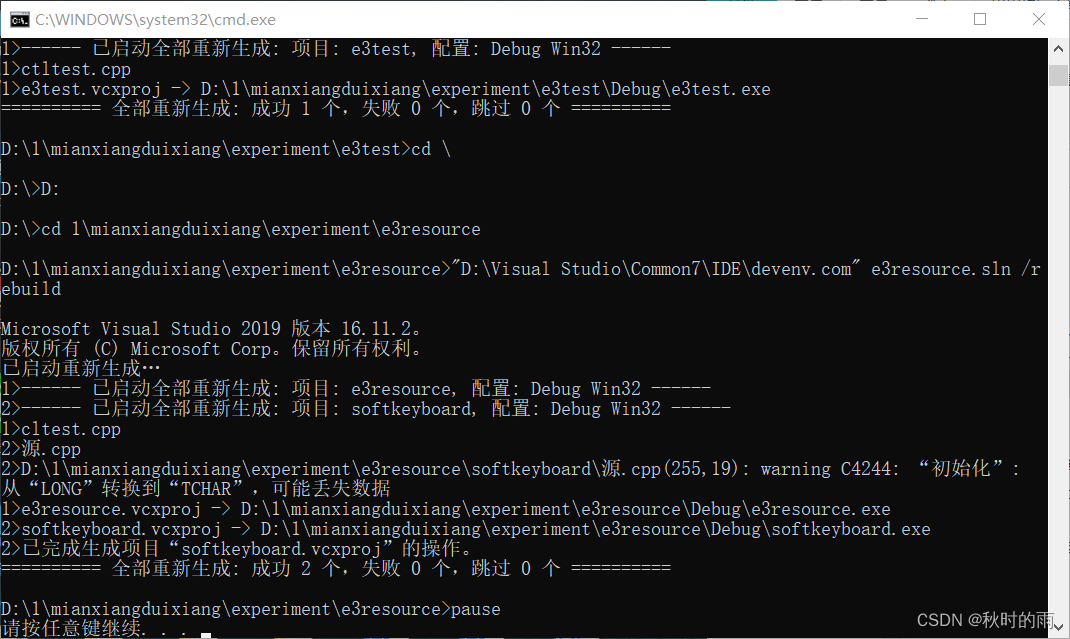
到Hive中查看表数据:
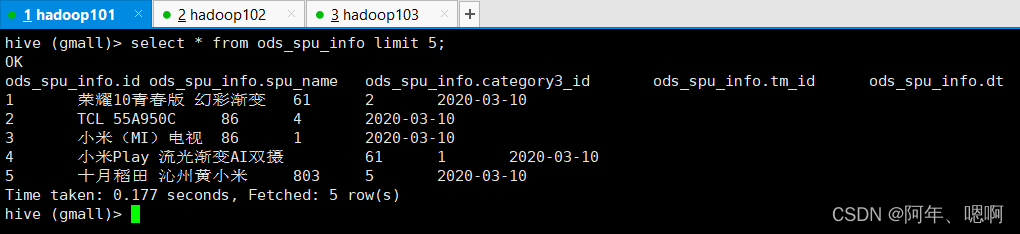
至此,业务数据库中的数据已经从MySQL导入到了Hive中