前几篇我们介绍了一个重点概念model-base和model-free,其中model-base是建立在存在某个环境模型,从模型中可以获得状态、动作、奖励的转移信息,比如动态规划方法,当我们确定了状态动作的转换概率,此时我们可以通过递归的方式,迅速获得价值函数的估计。
在价值函数的更新过程中,一种方式是遍历所有状态-动作来完成更新,但如果状态-动作太多,而某些状态对于我们目标达成完全没有用,遍历所有状态进行更新的效率非常低,另一方面各状态的价值函数更新存在相互依赖,因此其更新顺序也会影响训练的效率,因为所谓的planning是合理地规划状态更新步骤。
而当我们对于环境模型是完全未知时,就必须要通过同环境进行交互采样来获得真实累积收益,然后通过其来更新价值函数,这种方法称为model-free,MC和TD算法就属于此类,其通过采样来学习。这类方法的好处是其获得的收益是真实无偏的,但其训练速度要远慢于model-base的方法,特别是当同真实环境交互采样的代价很高时。
因此本节介绍一种通用的方式将两种策略进行结合,在对于环境完全未知的情况下,通过构建一个可学习的环境模型,一方面环境模型也可通过真实采样来学习,另一方面通过环境模型进行仿真采样,并也可以通过仿真采样来更新价值函数。

上图描述整体结构,一方面通过真实环境采样去直接学习价值函数,另一方面通过真实环境采样去学习环境模型,然后通过环境模型来间接学习价值函数。
1. Dyna算法
Dyna算法是上述模型最为基本的实现,其假设了环境状态转移是确定的,还不是概率的,即:
因此在Dyna算法,其用一个表格来表示环境模型其指向了另一个确定状态。
Dyna算法将训练过程分为多个迭代轮数,在每个迭代轮数,会进行一轮真实环境采样,并更新价值函数,同时根据采样结果来更新环境模型,之后再根据环境模型来迭代更新价值函数n次。

2. Dyna-Q+
在Dyna算法中假设了模型在学习某个状态及动作之后就不会变化,换而言之模型不会更新或出错,但当这种情况发生时,那么Dyna算法中(f)过程的间接学习就会有问题,因此Dyna-Q+在该过程中引入了启发式算法,其将环境模型表示为,其中T表示更新时间。价值函数更新所用于R值会随着未更新时间越长而增加。从而鼓励去探索长时间未探索的状态。
3. Prioritized Sweeping
在Dyna算法中,当完成真实采样后,价值函数几乎没有变化,此时再通过模型来进行仿真训练是没有意义的,因为此时价值函数也不会有更新。因此Prioritized Sweeping思想通过真实采样后价值函数是否变化来判断是否需要通过模型来进行仿真训练。另一方面只会考虑该状态所影响的其他状态来进行更新。

4. Expected vs. Sample Updates
在通过模型来进行仿真训练中,价值函数更新方式有两种,通过动态规划中的期望更新:
或类似于Q-learning中采样更新的方式:
后者相比于前者来说,单次迭代其计算量要小很多,但是前者的收敛速度更快,而后者要经过多次更新。然而当状态-动态很多时,采样更新由于计算量较少,其整体的收敛速度会更快。
5. Trajectory Sampling
采样方式存在两种一种是通过on-policy进行采样,一种直接均匀采样,我们可以直观的感觉通过on-policy方式加快模型训练,但另一方面可能会漏探索某些状态,导致无法达到最优点。

上图比较了on-policy采样和直接均匀采样的效果不同,首先on-policy收敛速度更快,特别是当状态数增加时效果更明显,另外左图可以看出当分支较多时(当前状态的下一可能状态的数量),on-policy可能无法达到最优点。
6. Real-time Dynamic Programming
RTDP通过上述提到on-policy Trajectory Sampling方式来加快原始DP算法的收敛速度,原始的价值函数更新公式为:
而RTDP的价值函数更新公式为:
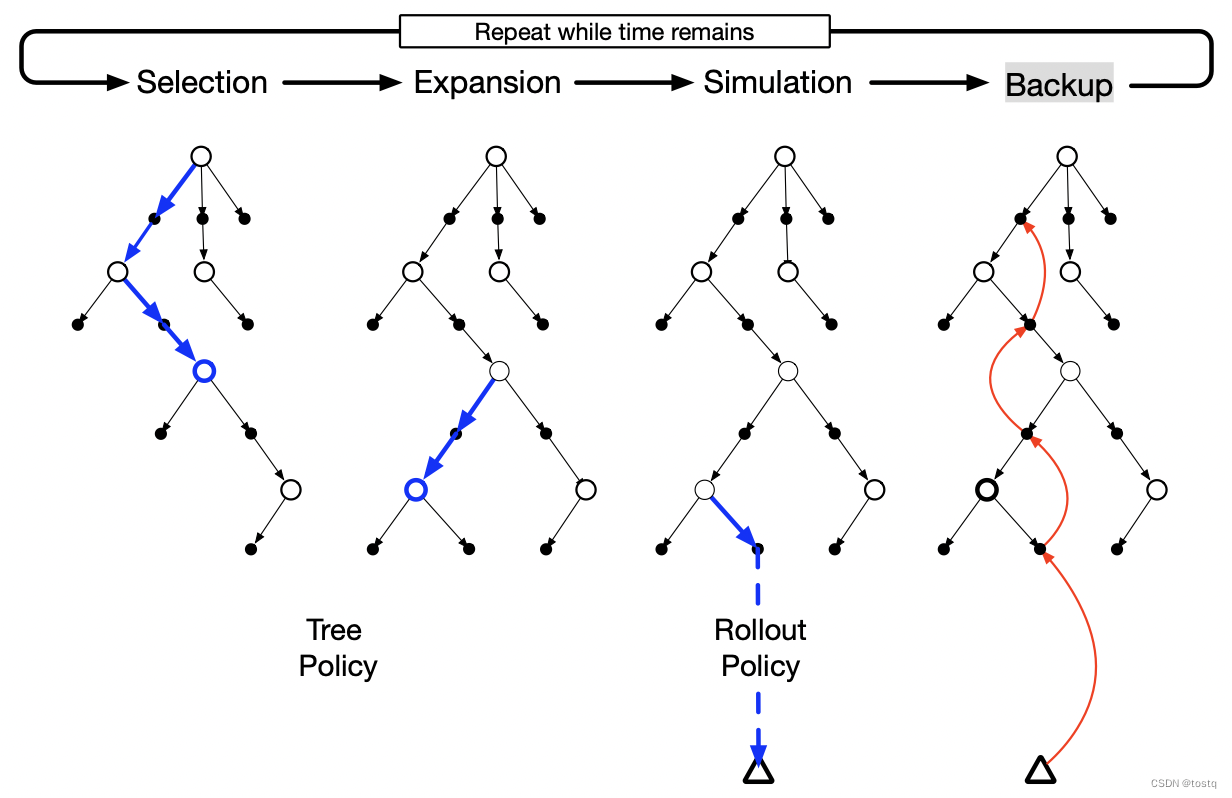
7. Monte Carlo Tree Search
传统的Monte Carlo方法,需要遍历全部的状态-动作空间,这么做的效率非常低,特别是当状态空间特别大时,更是很难实现。因此Tree Search的方式是通过树结构来存储历史状态访问路径,每个状态都是树上的一结点,从某个根结点出来来访问后续状态,这种方式避免大量无效状态的访问。
我们假设对于Monte Carlo Tree中的某个状态结点,其存在三种情况:
- 终结点:该结点是终结点
- 中间结点:该结点存在后续结点且已经被完全探索
- 探索点:该结点存在后续结点且已经未被完全探索
Monte Carlo Tree Search从某根结点开始,迭代按下面四个步骤运行:
- select:从根结点出发,依次向下探索,当遇到中间结点时,根据Tree Policy来选择某个子结点,直到遇到终结点(更新整个路径状态的价值函数)或者遇到探索点
-
Expansion:当遇到探索点时,从中选择一个未完全探索的子结点
-
Simulation:未完全探索的子结点通过Rollout Policy来选择后续的状态动作,直到遇到终结点
-
Backup:遇到终结点,更新整个路径上状态-动作的价值函数。