作者:Priscilla Parodi

会话界面已经存在了一段时间,并且作为协助各种任务(例如客户服务、信息检索和任务自动化)的一种方式而变得越来越流行。 通常通过语音助手或消息应用程序访问,这些界面模拟人类对话,以帮助用户更有效地解决他们的查询。
随着技术的进步,聊天机器人被用来处理更复杂的任务 —— 而且速度更快 —— 同时仍然为用户提供个性化的体验。 自然语言处理 (NLP) 使聊天机器人能够处理用户的语言,识别其消息背后的意图,并从中提取相关信息。 例如,命名实体识别通过将文本分类为一组类别来提取文本中的关键信息。 情绪分析确定情绪基调,而问题回答则确定查询的 “答案”。 NLP 的目标是使算法能够处理人类语言并执行历史上只有人类才能完成的任务,例如在大量文本中查找相关段落、总结文本以及生成新的原创内容。
这些高级 NLP 功能建立在称为矢量搜索的技术之上。 Elastic 原生支持矢量搜索,执行精确和近似 k 最近邻 (kNN) 搜索,以及 NLP,支持直接在 Elasticsearch 中使用自定义或第三方模型。
在这篇博文中,我们将探讨矢量搜索和 NLP 如何增强聊天机器人的功能,并展示 Elasticsearch 如何促进这一过程。 让我们从矢量搜索的简要概述开始。
矢量搜索
尽管人类可以理解书面语言的含义和语境,但机器却做不到。 这就是矢量的用武之地。通过将文本转换为矢量表示(文本含义的数字表示),机器可以克服这一限制。 与传统搜索相比,矢量不是依赖关键字和基于频率的词汇搜索,而是使用为数值定义的操作来处理文本数据。
这允许矢量搜索通过使用 “嵌入空间” 中的距离来表示给定查询矢量的相似性来定位共享相似概念或上下文的数据。 当数据相似时,对应的矢量也会相似。

矢量搜索不仅用于 NLP 应用程序,还用于涉及非结构化数据的各种其他领域,包括图像和视频处理。
在聊天机器人流程中,可以有多种用户查询方法,因此,有不同的方法来改进信息检索以获得更好的用户体验。 由于每个备选方案都有其自身的一系列优点和可能的缺点,因此必须考虑可用的数据和资源,以及培训时间(适用时)和预期的准确性。 在下一节中,我们将介绍问答 NLP 模型的这些方面。
问答式
问答 (QA) 模型是一种 NLP 模型,旨在回答以自然语言提出的问题。 当用户的问题需要从多个资源中推断出答案,而文档中没有预先存在的目标答案时,生成 QA 模型会很有用。 然而,这些模型的计算成本可能很高,并且需要大量数据来进行领域相关训练,这可能会降低它们在某些情况下的实用性,尽管这种方法对于处理域外问题特别有价值。
另一方面,当用户对特定主题有疑问并且文档中有实际答案时,可以使用提取式 QA 模型。 这些模型直接从源文档中提取答案,提供透明和可验证的结果,使它们成为希望提供简单有效的问题回答方式的企业或组织的更实用的选择。
下面的示例演示了如何使用预训练的提取式 QA 模型(可在 Hugging Face 上获得并部署到 Elasticsearch 中)从给定上下文中提取答案:
POST _ml/trained_models/deepset__minilm-uncased-squad2/deployment/_infer
{
"docs": [{"text_field": "Canvas is a data visualization and presentation application within Kibana. With Canvas, live data can be pulled directly from Elasticsearch and combined with colors, images, text, and other customized options to create dynamic, multi-page displays."}],
"inference_config": {"question_answering": {"question": "What is Kibana Canvas?"}}
}
{
"predicted_value": "a data visualization and presentation application",
"start_offset": 10,
"end_offset": 59,
"prediction_probability": 0.28304219431376443
}
部署经过训练的模型。
将模型添加到推理摄取管道。
处理用户查询和检索信息的方法多种多样,在处理非结构化数据时,使用多种语言模型和数据源可能是一种有效的替代方法。 为了说明这一点,我们有一个聊天机器人的数据处理示例,该聊天机器人用于响应查询并考虑从选定文档中提取的数据。
聊天机器人数据处理:NLP 和矢量搜索
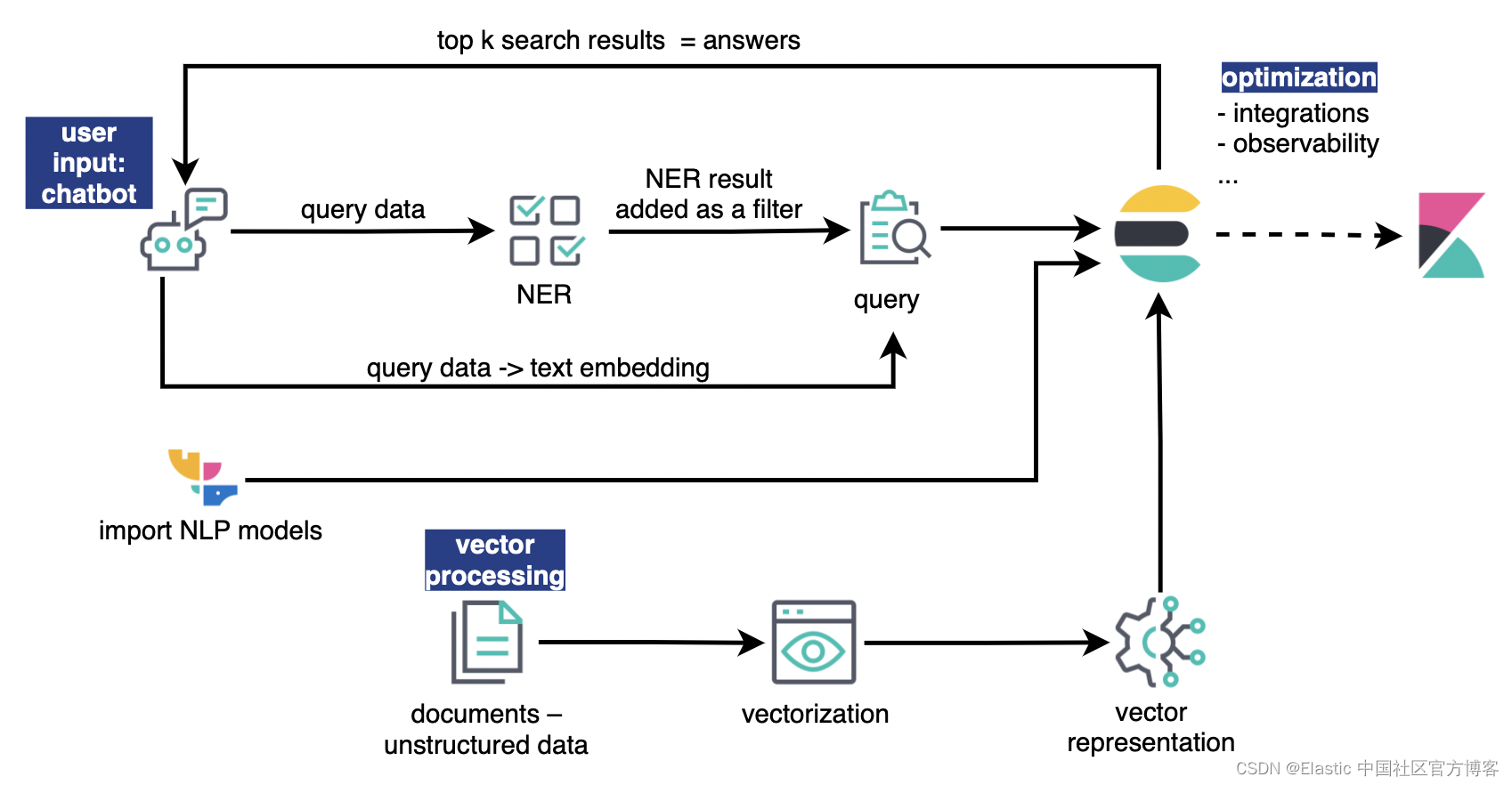
如上所示,我们的聊天机器人的数据处理可以分为三个部分:
- 矢量处理:这部分将文档转换为矢量表示。
- 用户输入处理:这部分从用户查询中提取相关信息,进行语义搜索和混合检索。
- 优化:这部分包括监控,对于确保聊天机器人的可靠性、最佳性能和良好的用户体验至关重要。
矢量处理
对于处理部分,第一步是确定每个文档的组成部分,然后将每个元素转换为矢量表示; 可以为范围广泛的数据格式创建这些表示。
有多种方法可用于计算嵌入,包括预训练模型和库。
请务必注意,对这些表示进行搜索和检索的有效性取决于现有数据以及所用方法的质量和相关性。
在计算矢量时,它们以 dense_vector 字段类型存储在 Elasticsearch 中。
PUT <target>
{
"mappings": {
"properties": {
"doc_part_vector": {
"type": "dense_vector",
"dims": 3
},
"doc_part" : {
"type" : "keyword"
}
}
}
}聊天机器人用户输入处理
对于用户部分,在收到问题后,在继续之前从中提取所有可能的信息是很有用的。 这有助于理解用户的意图,在这种情况下,我们使用命名实体识别模型 (NER) 来帮助实现这一点。 NER 是识别命名实体并将其分类为预定义实体类别的过程。
POST _ml/trained_models/dslim__bert-base-ner/deployment/_infer
{
"docs": { "text_field": "How many people work for Elastic?"}
}
{
"predicted_value": "How many people work for [Elastic](ORG&Elastic)?",
"entities": [
{
"entity": "Elastic",
"class_name": "ORG",
"class_probability": 0.4993975435876747,
"start_pos": 25,
"end_pos": 32
}
]
}虽然不是必要的步骤,但通过使用结构化数据或上述或其他 NLP 模型结果对用户的查询进行分类,我们可以使用过滤器限制 kNN 搜索。 这有助于通过减少需要处理的数据量来提高性能和准确性。
"filter": {
"term": {
"org": "Elastic"
}
}语义搜索和混合检索
由于提示源自用户查询,而聊天机器人需要处理具有可变性和歧义性的人类语言,因此语义搜索非常适合。 在 Elasticsearch 中,你可以通过将查询字符串和嵌入模型的 ID 传递到 query_vector_builder 对象来一步执行语义搜索。 这将矢量化查询并执行 kNN 搜索以检索与查询含义最接近的前 k 个匹配项:
POST /<target>/_search
{
"knn": {
"field": "doc_part_vector",
"k": 5,
"num_candidates": 20,
"query_vector_builder": {
"text_embedding": {
"model_id": "<text-embedding-model-id>",
"model_text": "<query_string>"
}
}
}
}端到端示例:如何部署文本嵌入模型并将其用于语义搜索。
Elasticsearch 使用 Okapi BM25 的 Lucene 实现(一种稀疏模型)对文本查询的相关性进行排名,而密集模型(dense models)则用于语义搜索。 为了结合矢量匹配和从文本查询中获得的匹配两者的优势,你可以执行混合检索:
POST <target>/_search
{
"query": {
"match": {
"content": {
"query": "<query_string>"
}
}
},
"knn": {
"field": "doc_part_vector",
"query_vector_builder": {
"text_embedding": {
"model_id": "<text-embedding-model-id>",
"model_text": "<query_string>"
}
},
"filter": {
"term": {
"org": "Elastic"
}
}
}
}结合稀疏和密集模型通常会产生最好的结果
稀疏模型通常在短查询和特定术语上表现更好,而密集模型则利用上下文和关联。 如果你想了解更多关于这些方法如何比较和相互补充的信息,我们在这里将 BM25 与两个专门针对检索进行训练的密集模型进行基准测试。
最相关的结果通常可以是给用户的第一个答案,_score 是一个用来确定返回文档相关性的数字。
聊天机器人优化
为了帮助改善聊天机器人的用户体验、性能和可靠性,除了应用混合评分之外,你还可以采用以下方法:
情绪分析:为了在对话展开时了解用户评论和反应,你可以合并情绪分析模型:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": { "text_field": "That was not my question!"}
}
{
"predicted_value": "NEGATIVE",
"prediction_probability": 0.980080439016437
}GPT 的功能:作为增强整体体验的替代方案,你可以将 Elasticsearch 的搜索相关性与 OpenAI 的 GPT 问答功能结合起来,利用 Chat Completion API 将这些前 k 个文档作为上下文返回给用户模型生成的响应。 提示:“answer this question <user_question> using only this document <top_search_result>”。详细阅读 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(一)”。
可观察性:确保任何聊天机器人的性能都至关重要,而监控是实现这一目标的重要组成部分。 除了捕获聊天机器人交互的日志之外,跟踪响应时间、延迟和其他相关聊天机器人指标也很重要。 通过这样做,你可以识别模式、趋势,甚至检测异常。 Elastic 可观察性工具使你能够收集和分析这些信息。
总结
这篇博文涵盖了 NLP 和矢量搜索是什么,并深入研究了一个聊天机器人的示例,该聊天机器人通过考虑从文档的矢量表示中提取的数据来响应用户查询。
正如所展示的那样,使用 NLP 和矢量搜索,聊天机器人能够执行超出结构化目标数据的复杂任务。 这包括使用多个数据源和格式作为上下文来提出建议和回答特定产品或业务相关的查询,同时还提供个性化的用户体验。
用例范围从通过协助客户查询来提供客户服务到通过提供分步指导、提出建议甚至自动化任务来帮助开发人员查询。 根据目标和现有数据,还可以利用其他模型和方法来获得更好的结果并改善整体用户体验。
以下是有关该主题的一些可能有用的链接:
- 如何部署自然语言处理 (NLP):入门
- Elasticsearch 中图片相似度搜索概述
- ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据
- 使用 OpenTelemetry 和 Elastic 监控 OpenAI API 和 GPT 模型
- IT 领导者需要矢量搜索来改善搜索体验的 5 个原因
通过在 Elasticsearch 中整合 NLP 和本机矢量搜索,你可以利用其速度、可扩展性和搜索功能来创建能够处理大量结构化或非结构化数据的高效聊天机器人。
准备好开始了吗? 开始免费试用 Elastic Cloud。
在这篇博文中,我们可能已经使用或参考了由其各自所有者拥有和运营的第三方生成人工智能工具。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害承担任何责任。 使用带有个人、敏感或机密信息的 AI 工具时请谨慎行事。 你提交的任何数据都可能用于人工智能训练或其他目的。 无法保证你提供的信息将得到安全保护或保密。 在使用之前,你应该熟悉任何生成人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。