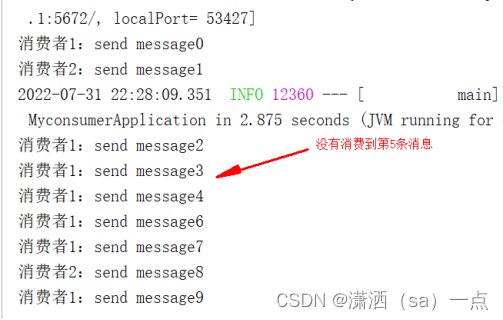
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共820人左右 1 + 2 + 3)新人会进入3群,进瑞典马工群的单独说。
企业是7天24小时运营的。这包括从网站、后勤办公、供应链到其他所有方面。曾经,一切都是分批次进行的。就在几年前,操作系统会暂停,以便将数据加载到数据仓库并运行报告。现在的报告关注的是事情当前的状况。已没有时间进行ETL。
许多IT架构仍然基于中心轮辐式系统。操作系统向数据仓库提供数据,然后数据仓库再向其他系统提供数据。专用的可视化软件根据“仓库”生成报告和仪表板。然而,这种情况正在发生变化,商业上的这些变化要求数据库和系统架构进行适应。
过去十年中,大量的云迁移和可扩展性努力的一部分导致了许多专用数据库的使用。在许多公司,网站由NoSQL数据库支持,而涉及资金的关键系统则位于大型机或关系数据库上。这仅仅是问题的表面。对于许多问题,还会使用更专业化的数据库。通常情况下,这种架构需要使用传统的批处理过程来转移大量数据。操作复杂性不仅导致延迟,还可能出现故障。这种架构并非为了实现可扩展性而设计的,而是为了阻止问题的恶化而拼凑在一起的。
数据库正在发生变化。关系数据库现在能够处理非结构化、文档和JSON数据。NoSQL数据库现在至少具备一些事务支持。同时,分布式SQL数据库在保持与现有SQL数据库和工具的兼容性的同时,实现了数据完整性、关系数据和极端可扩展性。
然而,仅凭这些还不够。事务性或操作性系统与分析系统之间的界限不能成为边界。数据库需要同时处理大量用户和长时间运行的查询,至少在大部分时间里如此。为此,事务性/操作性数据库正在以列式索引或MPP(大规模并行处理)能力的形式增加分析功能。现在可以在一些分布式操作数据库上运行分析查询,例如MariaDB Xpand(分布式SQL)或Couchbase(分布式NoSQL)。
这并不是说现在的技术已经发展到不再需要专用数据库的地步。目前还没有操作数据库能够进行PB级别的分析。在某些边缘案例中,除了时间序列或其他特殊的数据库外,没有其他解决方案。保持事物简单化或实现实时分析的诀窍是避免提取。
在许多情况下,问题的答案在于首次捕获数据的方式。与其将数据发送到一个数据库然后从另一个数据库中提取数据,不如将事务同时应用于两者。像Apache Kafka或Amazon Kinesis这样的现代工具可以实现这种数据流式传输。虽然这种方法确保数据无延迟地到达两个地方,但它需要更复杂的开发来确保数据完整性。通过避免数据的推拉,事务型和分析型数据库可以同时更新,当需要专用数据库时,可以实现实时分析。
有些分析型数据库无法承受这种方式。在这种情况下,可以作为权宜之计使用更为定期的批量加载。然而,要高效地实现这一点,源操作数据库需要处理更多长时间运行的查询,可能会在高峰时段进行。这就需要内置列式索引或MPP。
在它们所处的时代,客户端-服务器数据库表现得非常出色。它们不断发展以充分利用众多CPU和控制器,为各种应用程序提供性能。然而,客户端-服务器数据库是为员工、工作组和内部系统设计的,而不是互联网。在当今网络规模系统和数据无处不在的现代时代,它们已变得完全难以维持。
许多应用程序使用许多不同的隔离数据库。优点是如果其中一个出现故障,受影响范围较小。缺点是总有一些东西始终处于损坏状态。将较少的数据库整合到一个分布式数据结构中,使IT部门能够建立一个更可靠的数据基础设施,在不同数量的数据和流量下,减少停机时间。这也意味着在分析数据时,减少了数据传输的次数。
主要依赖于通用的分布式数据库,既能处理事务,也能进行分析,并在大型分析案例中使用流式传输,您可以支持现代企业所需的实时运营分析。这些数据库和工具在云端和本地都容易获得,并已广泛应用于生产环境。
改变是困难的,需要时间。这不仅仅是一个技术问题,还涉及人员和后勤问题。许多应用程序采用了隔离式架构进行部署,并独立于其他数据基础设施的开发周期。然而,经济压力、日益激烈的竞争和新的商业模式正在推动即使是最保守、最坚定的公司进行变革。