找遍全网无奈只能自己开发某博热点评论数据爬取与用户情感分析平台,这就是技术人的创新!
最近想看一下微博热点评论的用户人群情感趋势,想到的就是去爬取某博的评论数据,然后进行一个可视化的情感分析。想想吧,这个项目肯定网上一大堆,然后呢,自己去搜索,可把我气的。Github和csdn居然没有一个能够参考的好项目,不是拉下来跑不了。就是一些过时的程序,早都被反爬了。这可把我气的,花了两天时间自己研究琢磨了一个平台。现在免费提供给大家,希望大家多多收藏。相信我,你以后一定会用到的!
文章目录
- 找遍全网无奈只能自己开发某博热点评论数据爬取与用户情感分析平台,这就是技术人的创新!
- 前言
- 一、layui介绍
- 二、echart介绍
- 三、开发过程
- 3.1 后端设计
- 3.1.1 使用flask web框架快速搭建
- 3.1.2 某博热点数据爬取
- 3.1.2.1 登录某博网页
- 3.1.2.2 点击进入你要爬取的热点事件
- 3.1.2.3 点击进入你要爬取的评论目标
- 3.1.2.4 抓取评论url并且获取cookie
- 3.1.2.5 通过requests请求获取数据
- 3.1.3 数据分析与清洗
- 3.1.4 情感分析过程
- 3.1.5 数据保存
- 3.2 前端设计
- 3.2.1 用户登录注册
- 3.2.2 某博评论数据爬取
- 3.2.3 某博评论数据分析
- 总结
- 最后当然是源码公开拉!
前言
为了能让小白能够看懂我先来介绍一下我使用到的一些技术
- 前端为layui和echart
- 后端为python flask框架
- MYSQL数据库
- 情感分析NLP
- 爬虫技术
一、layui介绍
Layui是一个基于Web界面的前端UI框架,提供了丰富的组件和接口,并且易于使用和定制。它被广泛应用于Web开发项目中,可以帮助开发者快速搭建出美观、高效的用户界面。Layui采用了模块化的设计方式,使得开发者可以根据需要选择需要的组件,同时也可以方便的自定义扩展组件。它的主要特点包括简洁、易用、减少样式冲突、响应式设计。
二、echart介绍
Echart是一种用于数据可视化的JavaScript图表库,它支持多种图表类型,如折线图、柱状图、饼图、散点图等,并且具有动态交互性和可定制性。Echart可以通过简单的JavaScript代码来实现丰富的数据可视化效果,适用于不同领域的数据分析与展示。
三、开发过程
3.1 后端设计
3.1.1 使用flask web框架快速搭建
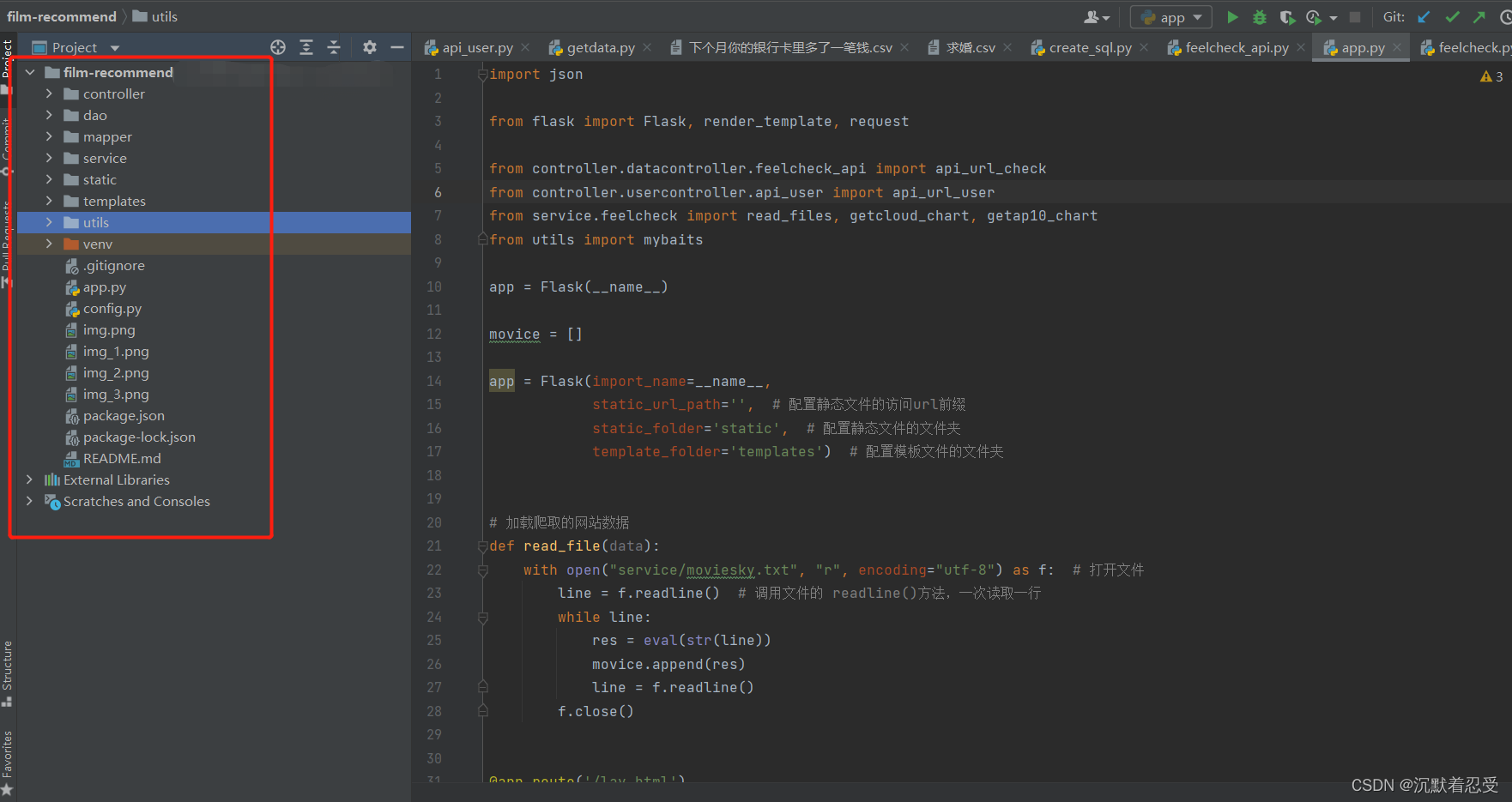
- Controller里面是和前端交互的API。
- Dao里面是与数据库连接的映射接口实体
- Mapper里面是与数据库连接的接口
- Service里面实现爬虫数据逻辑
- Static里面存放静态资源数据
- Templates存放前端HTML文件里面集成了类UI
- Utils是我自己分装的一些工具实体,里面有一些词云生成器和数据库脚本一键生成工具。数据库脚本一键生成工具,下期我再介绍。
先看效果图:
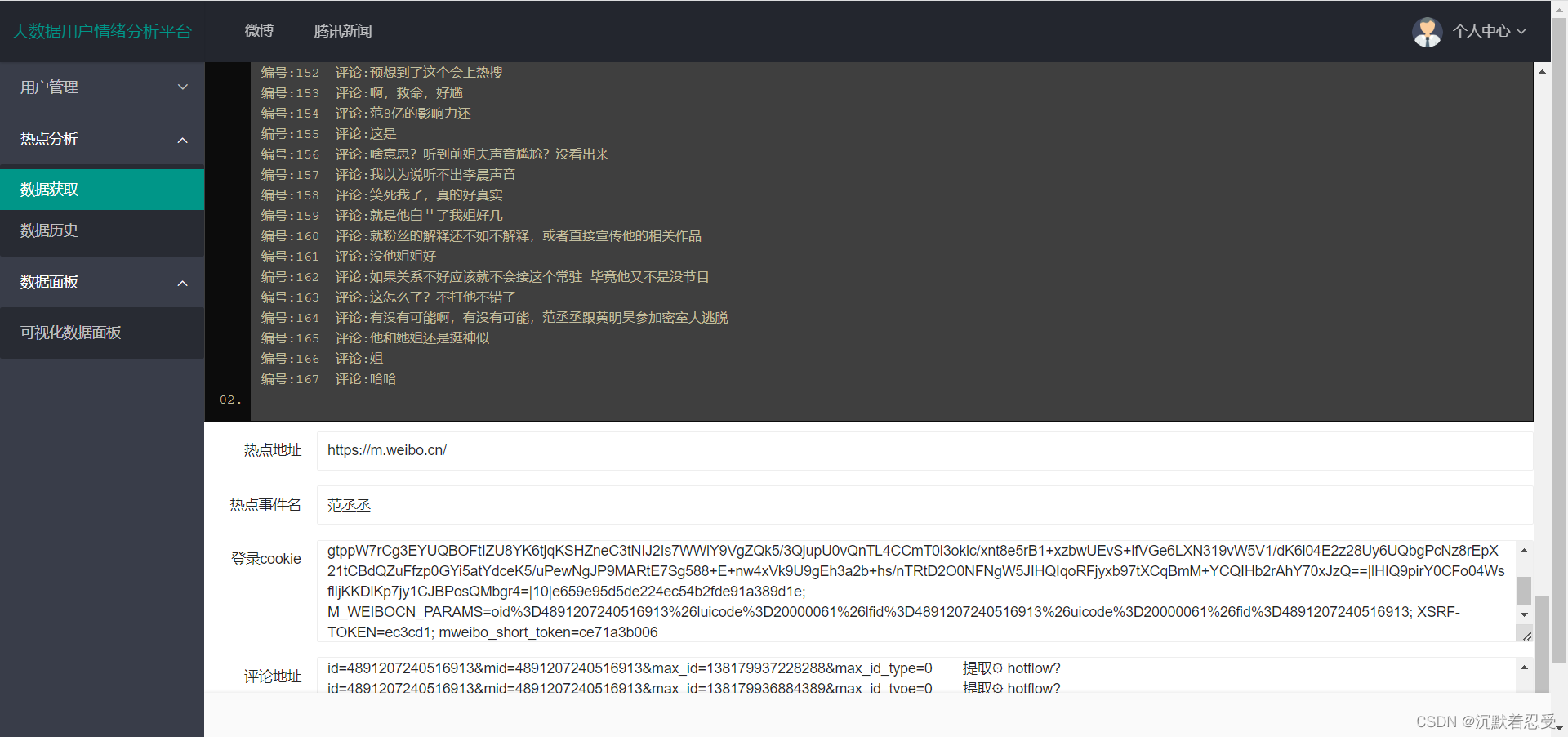
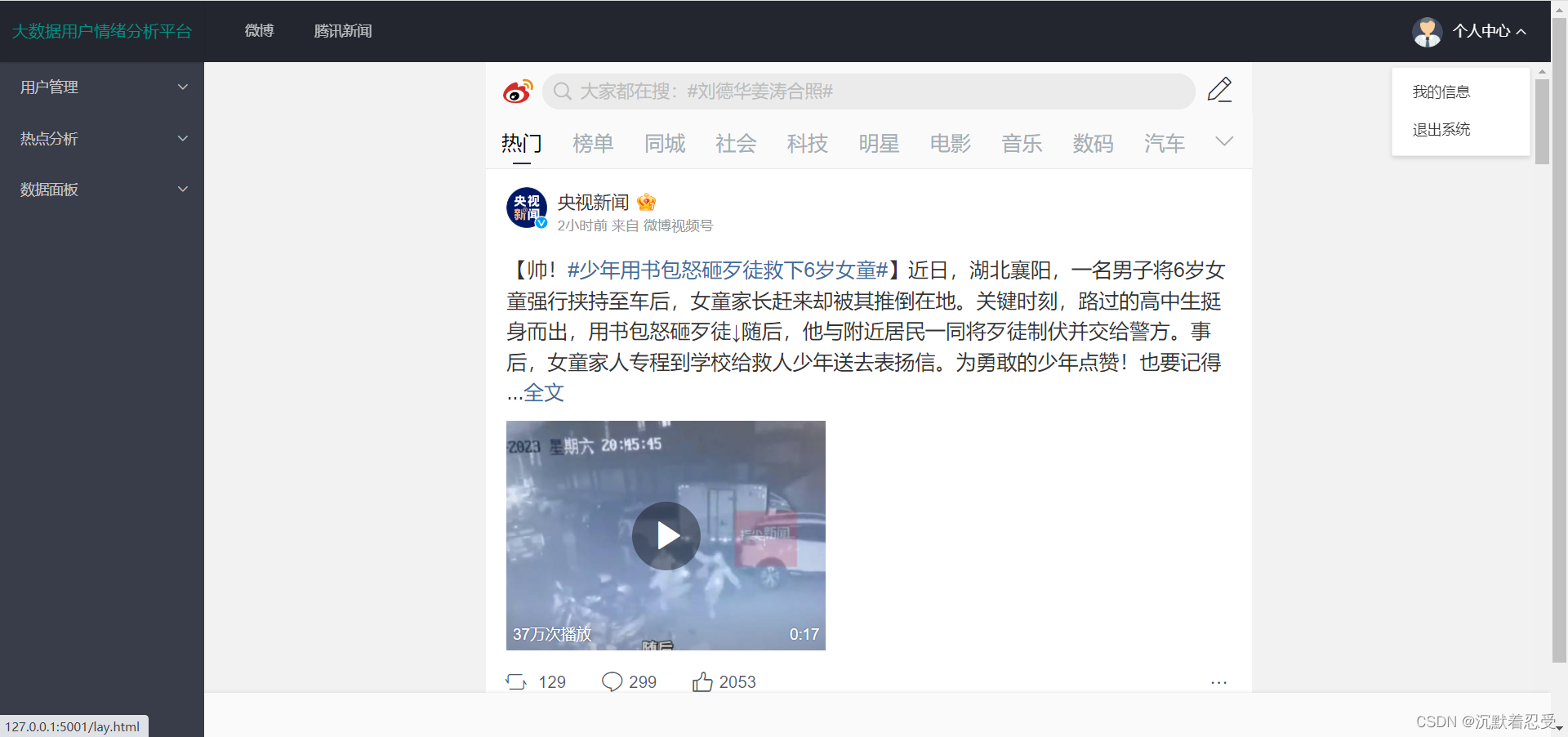
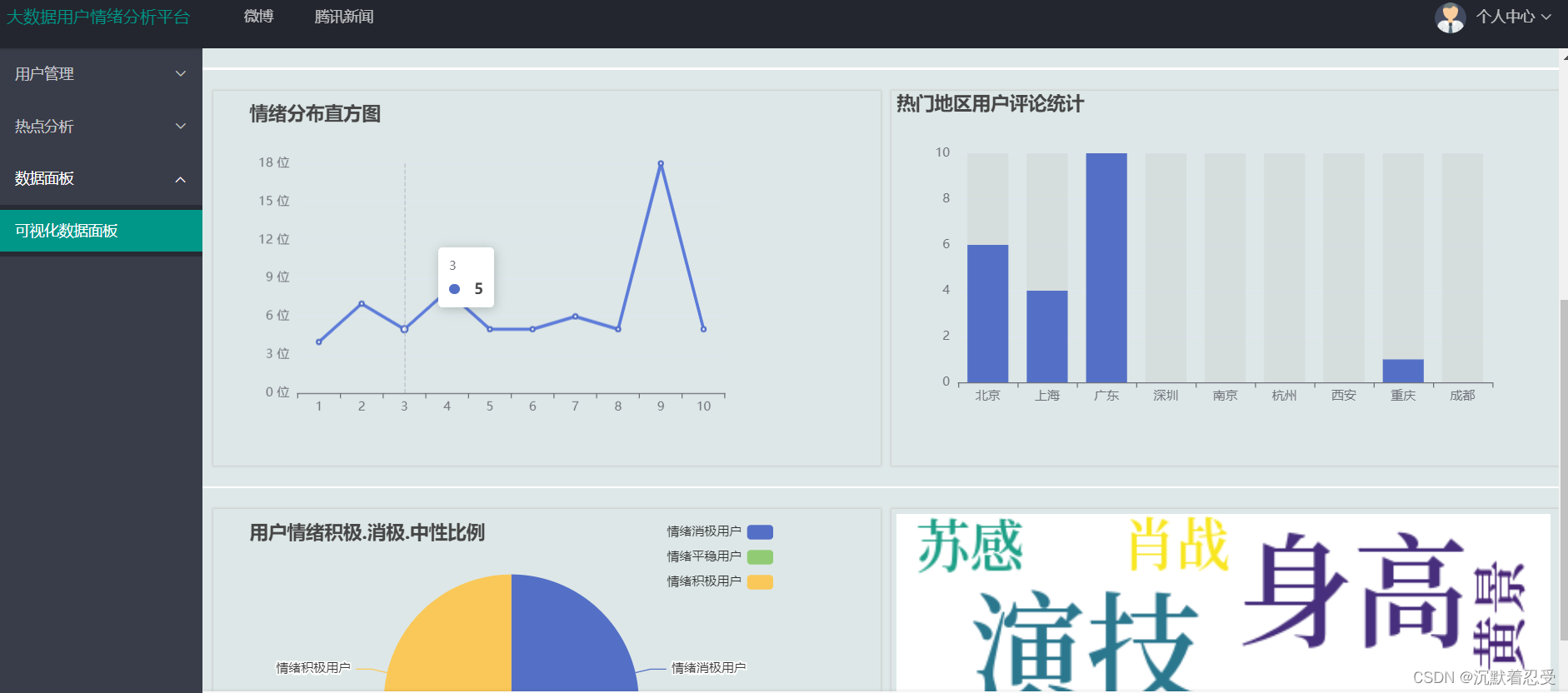
3.1.2 某博热点数据爬取
爬取思路,大神勿喷:
3.1.2.1 登录某博网页
登录地址为:微博地址
如果没有登录记得登录,登录成功后进入微博的H5页面。
3.1.2.2 点击进入你要爬取的热点事件
- 要注意现在需要获取一下网站的cookie
- 获取方式为如下:
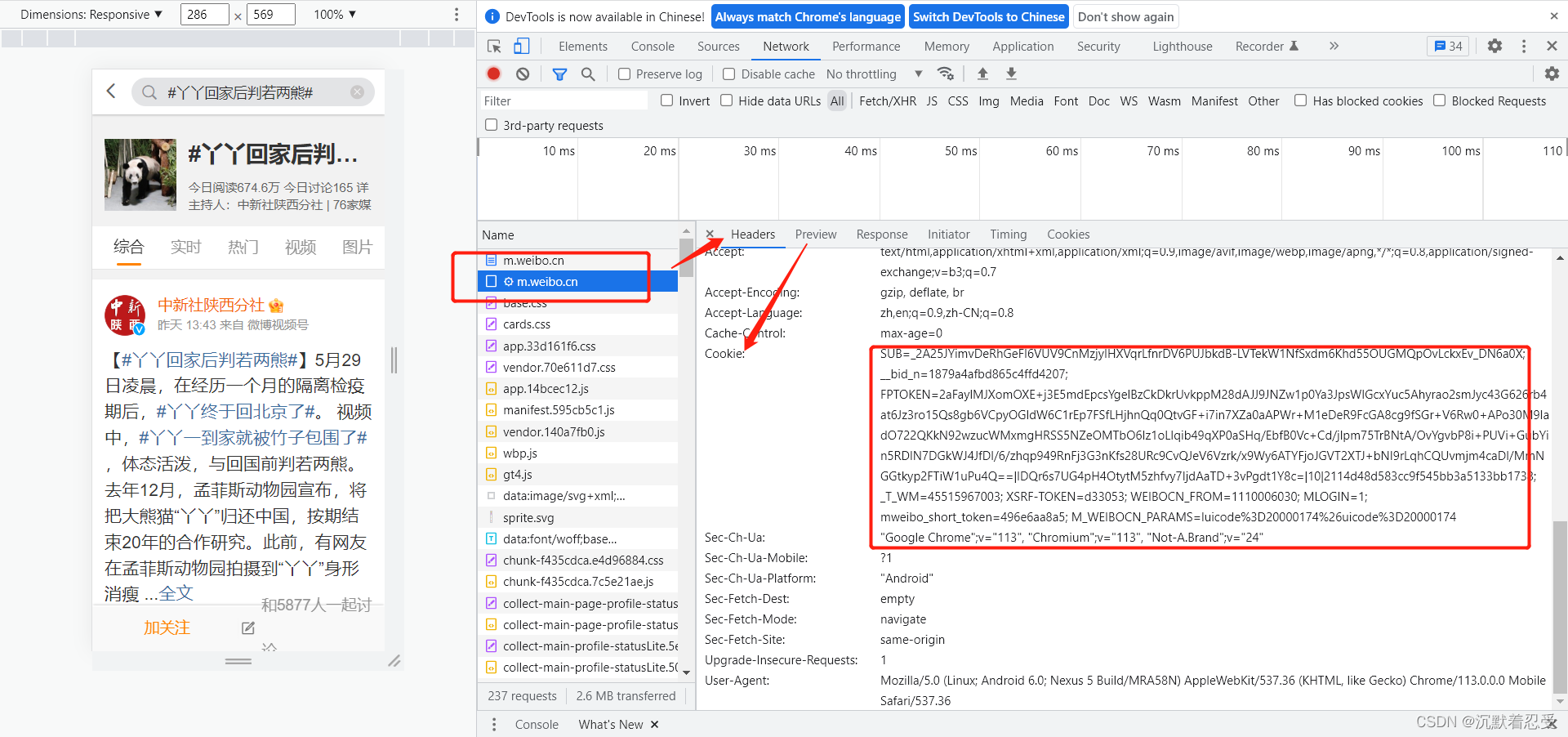
3.1.2.3 点击进入你要爬取的评论目标
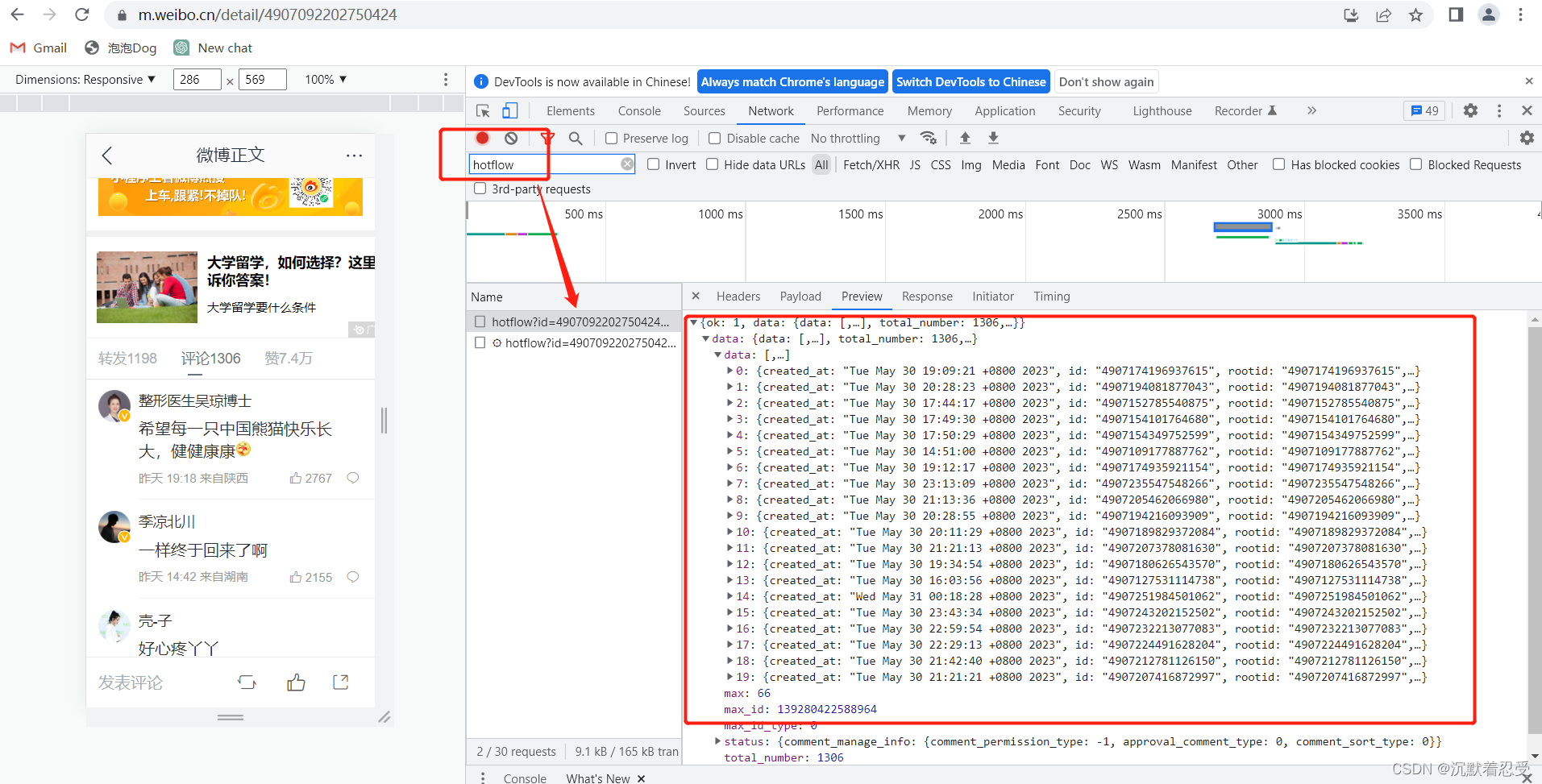
评论链接:评论链接
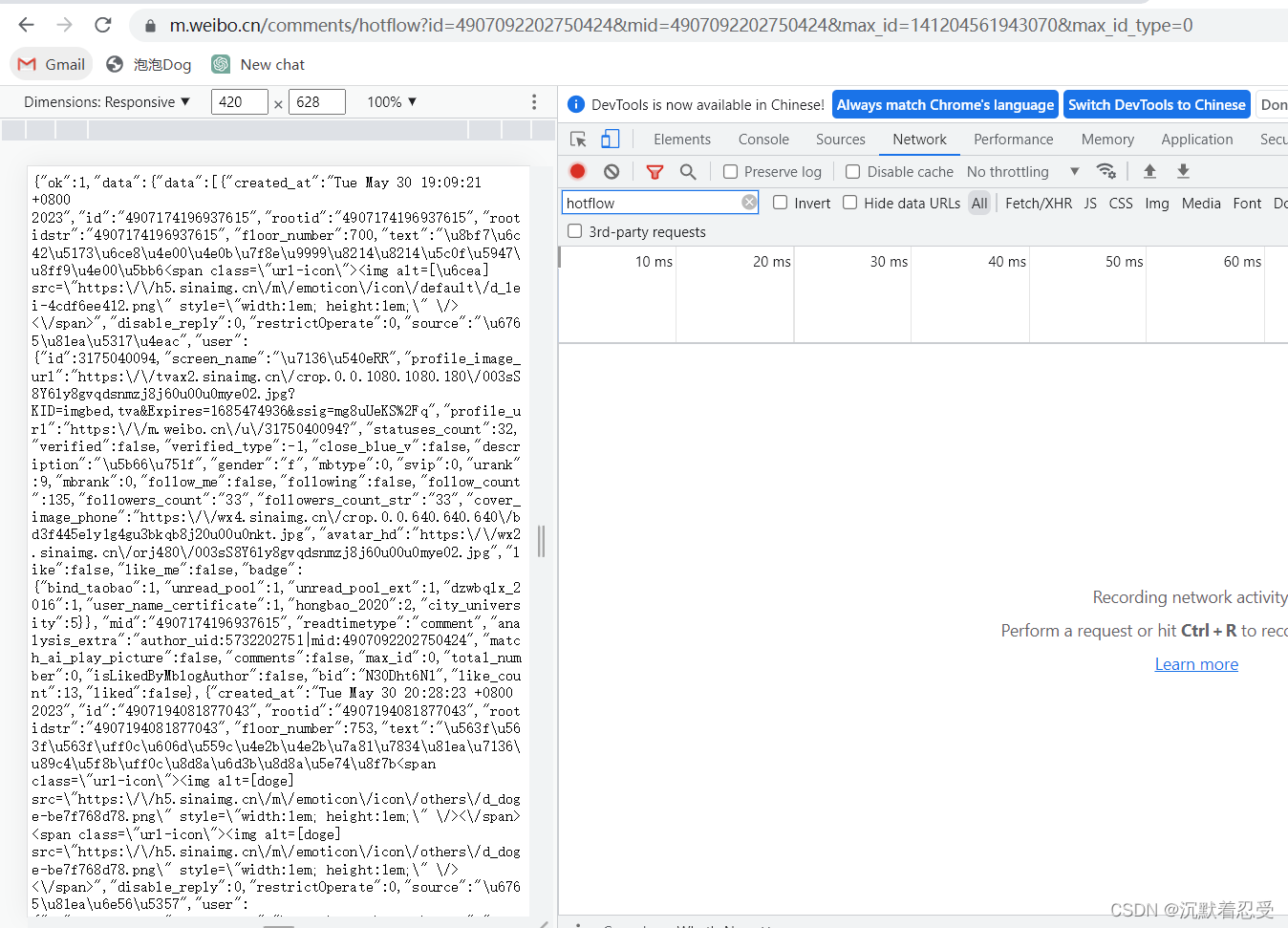
有个恶心的问题是爬取这个链接根本不是固定的,需要我们自己手动翻页收集,这里应该是人家的反扒策略。
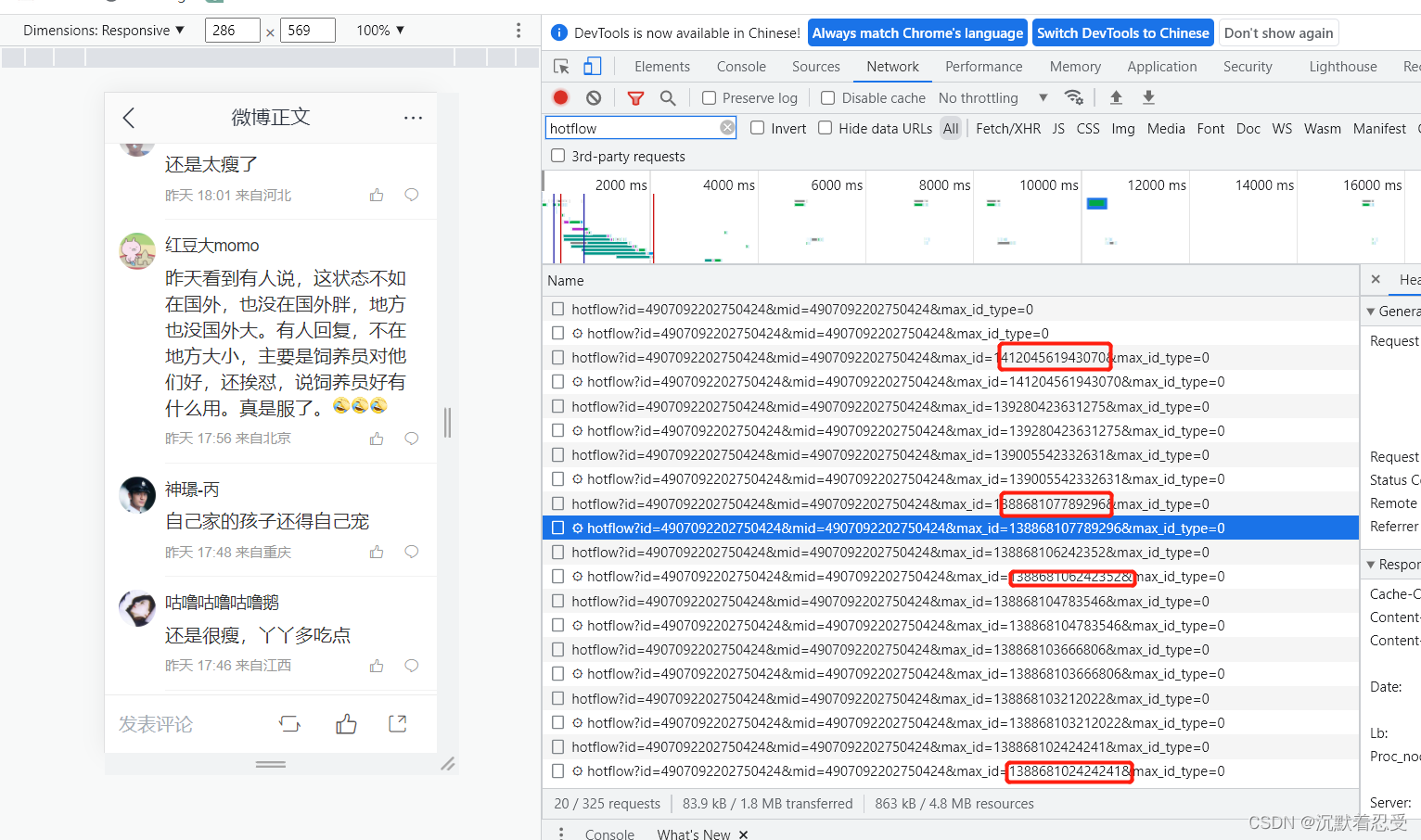
所以我只能将所有链接复制填写到输入框中进行遍历。遍历时要进行字符串处理
# 识别多页评论数据
def get_readUrl(data_url):
data = data_url
data_goods = []
str_data = data.split("hotflow")
for k in str_data:
if len(k) > 10:
data = k[:78]
print(data)
data_goods.append(data)
return data_goods
3.1.2.4 抓取评论url并且获取cookie
代码如下:
# 爬取微博热点评论
# 获取当前热搜信息
import json
import time
import requests
from service.feelcheck import write
# 获取某个信息
def get_data(hot_band_url, data_goods, cookie, name):
mydata_pa = []
headers = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39',
'cookie': cookie,
'Accept': 'application/json, text/plain, */*'
}
id = 0
try:
for k in data_goods:
print(hot_band_url + k)
data = requests.get(hot_band_url + k, headers=headers) # 请求
# time.sleep(1) # 防止被监控
data = data.json()
data = data['data']['data']
for k in data:
res = {}
text = get_split(k['text'])
if text != "":
res['id'] = id
res['source'] = k['source']
res['console'] = get_split(k['text'])
mydata_pa.append(res)
id += 1
print("开始写数据")
write(mydata_pa, name)
return mydata_pa
except:
res = []
return res
# 截取评论
def get_split(comments):
start = str(comments).find("<")
return comments[0:start]
# 识别多页评论数据
def get_readUrl(data_url):
data = data_url
data_goods = []
str_data = data.split("hotflow")
for k in str_data:
if len(k) > 10:
data = k[:78]
print(data)
data_goods.append(data)
return data_goods
#
# if __name__ == '__main__':
# data = get_readUrl()
# get_data(hot_band_url, data)
3.1.2.5 通过requests请求获取数据
# 获取某个信息
def get_data(hot_band_url, data_goods, cookie, name):
mydata_pa = []
headers = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39',
'cookie': cookie,
'Accept': 'application/json, text/plain, */*'
}
id = 0
try:
for k in data_goods:
print(hot_band_url + k)
data = requests.get(hot_band_url + k, headers=headers) # 请求
# time.sleep(1) # 防止被监控
data = data.json()
data = data['data']['data']
for k in data:
res = {}
text = get_split(k['text'])
if text != "":
res['id'] = id
res['source'] = k['source']
res['console'] = get_split(k['text'])
mydata_pa.append(res)
id += 1
print("开始写数据")
write(mydata_pa, name)
return mydata_pa
except:
res = []
return res
3.1.3 数据分析与清洗
try:
for k in data_goods:
print(hot_band_url + k)
data = requests.get(hot_band_url + k, headers=headers) # 请求
# time.sleep(1) # 防止被监控
data = data.json()
data = data['data']['data']
for k in data:
res = {}
text = get_split(k['text'])
if text != "":
res['id'] = id
res['source'] = k['source']
res['console'] = get_split(k['text'])
mydata_pa.append(res)
id += 1
print("开始写数据")
write(mydata_pa, name)
return mydata_pa
except:
res = []
return res
3.1.4 情感分析过程
主要使用NLP进行情感分析,这里我又要和小白科普了:
什么是NLP?
NLP代表自然语言处理(Natural Language Processing)。它是计算机科学和人工智能领域的分支之一,旨在使计算机能够理解、分析、生成和处理人类语言的形式和含义。它涉及许多技术,包括语音识别、文本分析、信息提取、语义理解和机器翻译等。NLP的应用范围很广,包括智能语音助手、机器翻译、数据挖掘、自动化客户服务、垃圾邮件过滤等。
import pandas
import pandas as pd
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import numpy as np
import jieba
from jieba import analyse
import csv
# 生成词云数据
from wordcloud import WordCloud
def write(data, name):
# 打开文件
file_name = 'G:/mydemo/film-recommend/static/{}.csv'.format(name)
with open(file_name, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["id", "console", "local"])
try:
pd.DataFrame(data).to_csv(file_name)
except:
print("the data is over")
def read_files(data_file):
data = pd.read_csv(data_file) # 读取csv文件数据
data.head(2)
data1 = data[['id', 'console', 'source']]
data1.head(10)
data1['emotion'] = data1['console'].apply(lambda x: SnowNLP(x).sentiments)
print(data1.head(10))
data1.describe()
return data1
def getattion_chart(data1):
# 计算积极评论与消极评论各自的数目
pos = 0
neg = 0
for i in data1['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
# 积极评论占比
res = {
'pos': pos,
'neg': neg
}
print(res)
return res
def getap10_chart(data):
# 关键词top10
text = ''
for s in data['console']:
text += s
key_words = jieba.analyse.extract_tags(sentence=text, topK=10, withWeight=True, allowPOS=())
print(key_words)
res = []
for k in range(0, 10):
res.append(key_words[k][0])
return res
# 参数说明 :
# sentence
# 需要提取的字符串,必须是str类型,不能是list
# topK
# 提取前多少个关键字
# withWeight
# 是否返回每个关键词的权重
# allowPOS是允许的提取的词性,默认为allowPOS =‘ns’, ‘n’, ‘vn’, ‘v’,提取地名、名词、动名词、动词
def getcloud_chart(data):
w = WordCloud(background_color="white",
font_path="G:/mydemo/film-recommend/service/SimplifiedChinese/SourceHanSerifSC-SemiBold.otf") # font_path="msyh.ttc",设置字体,否则显示不出来
text = ''
for s in data:
text += s + "\n"
w.generate(text)
w.to_file("G:/mydemo/film-recommend/static/img/doubanTop10cloud.png")
if __name__ == '__main__':
getap10_chart(read_files())
3.1.5 数据保存

def write(data, name):
# 打开文件
file_name = 'G:/mydemo/film-recommend/static/{}.csv'.format(name)
with open(file_name, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["id", "console", "local"])
try:
pd.DataFrame(data).to_csv(file_name)
except:
print("the data is over")
3.2 前端设计
3.2.1 用户登录注册

3.2.2 某博评论数据爬取
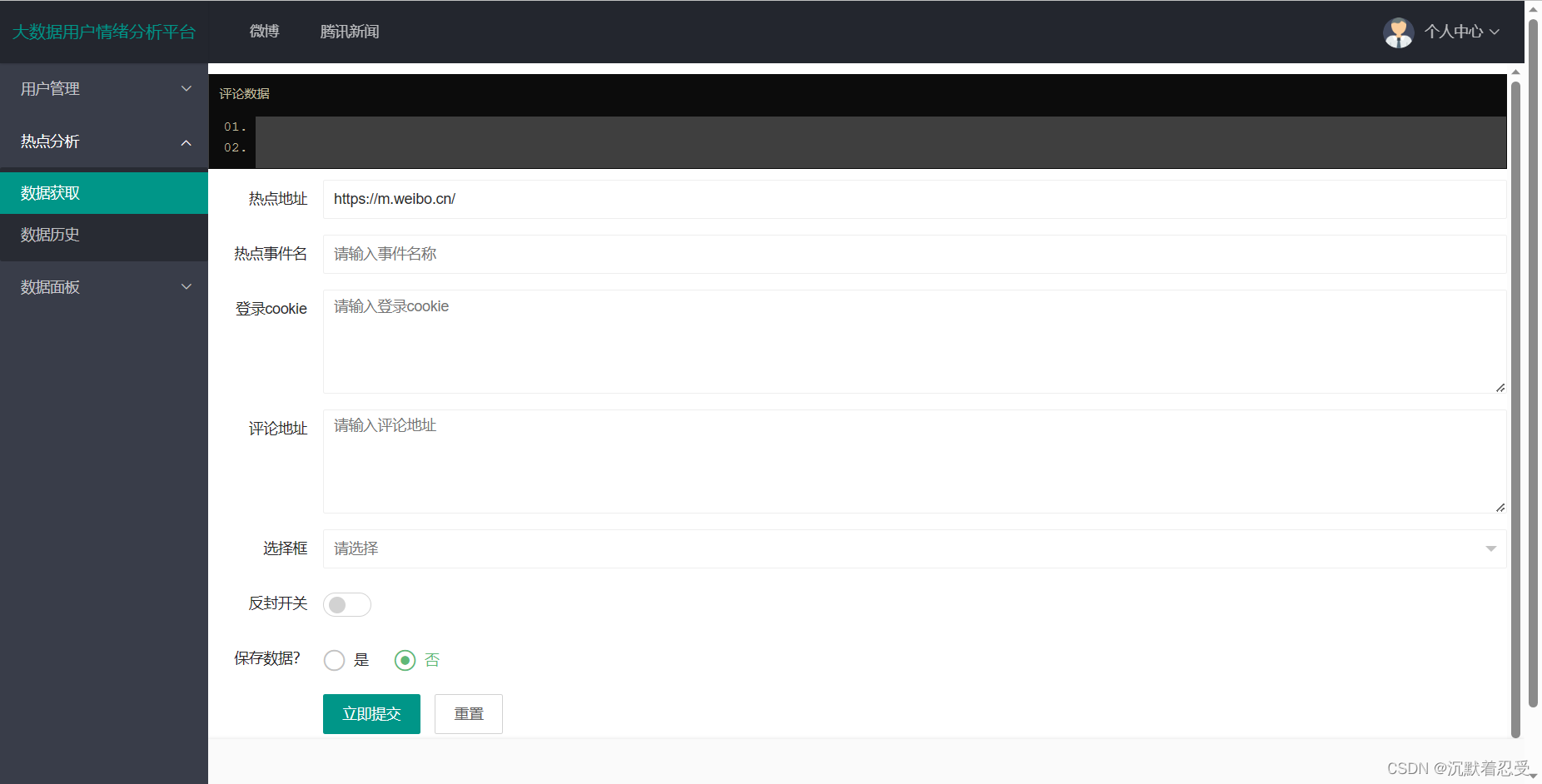
3.2.3 某博评论数据分析
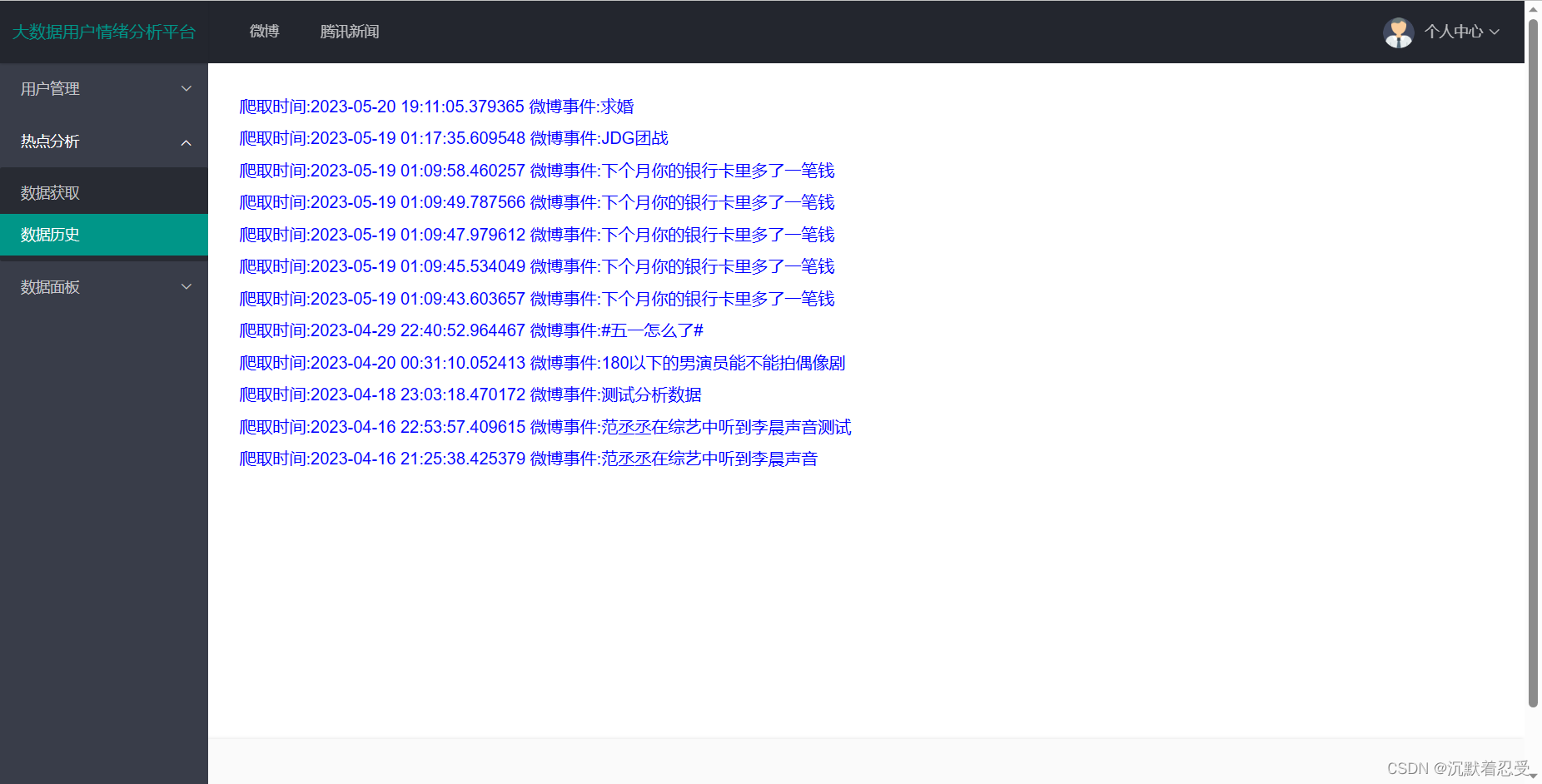
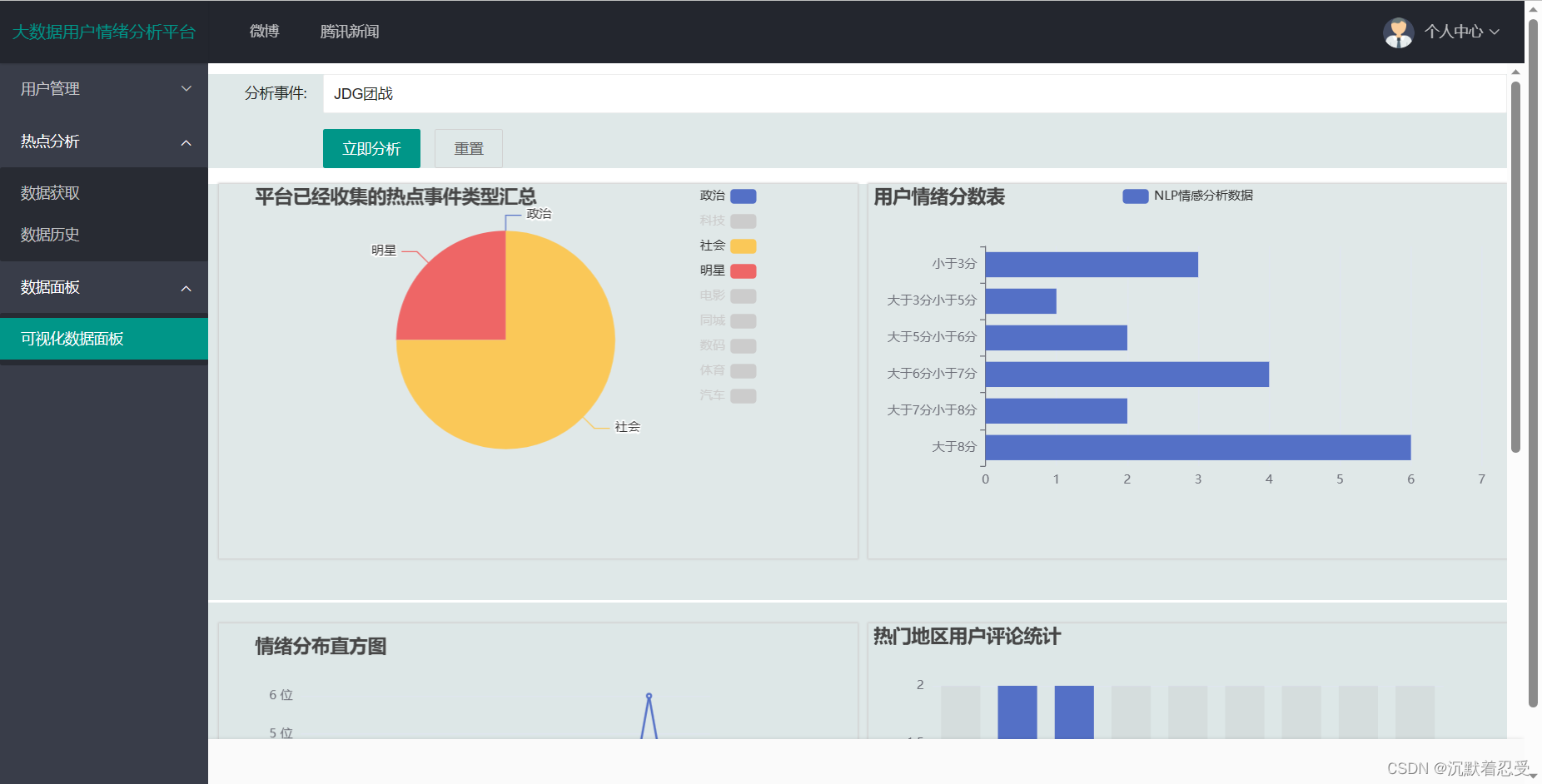
总结
经过两天没日没夜的开发,终于把这个搞完了,想告诉大家的是,我们开发者有现成的东西,当然可以用,但是如果找不到,那么我们就要开动自己的小脑筋,虽然这个事儿简单,但是不难看出,只有自己有创造力,有激情,有动力,最后总能做成一件事。正在求职找工作的同学可以私聊我,跟我一起学习更有趣的技术。
还有就是官方的ai写作nb!
以后什么概念不怕自己写不好啦,同学们还不快用起来。
最后当然是源码公开拉!
github地址:某博热点事件评论数据获取与用户情感分析
还不快快收藏,那天自己要用找不到了,哭去吧!哈哈