文章目录
- 0. 前置
- 1. 聚合函数介绍
- 1.1 AVG 和 SUM 函数
- 1.2 MIN 和 MAX 函数
- 1.3 COUNT函数
- 2. GROUP BY
- 2.1 基本使用
- 3. HAVING
- 3.1 基本使用
- 3.2 WHERE和HAVING的对比

0. 前置
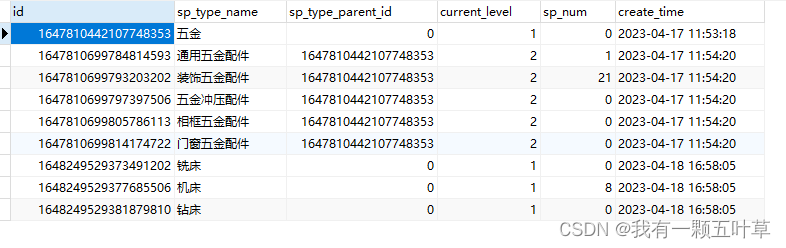
为了方便测试,我们导入一些数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for procatch_work_om_sp_type
-- ----------------------------
DROP TABLE IF EXISTS `procatch_work_om_sp_type`;
CREATE TABLE `procatch_work_om_sp_type` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`sp_type_name` varchar(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '备件类型名称',
`sp_type_parent_id` bigint(20) NOT NULL DEFAULT 0 COMMENT '父类类型id 没有就是0',
`current_level` tinyint(3) UNSIGNED NOT NULL COMMENT '当前层级(1/2/3)',
`sp_num` int(10) UNSIGNED NOT NULL DEFAULT 0 COMMENT '该备件类型下的备件数量(只是该备件类型下,不算类型父级)',
`create_time` datetime(0) DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1661945101694476291 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '运维-备件-备件类型' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of procatch_work_om_sp_type
-- ----------------------------
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810442107748353, '五金', 0, 1, 0, '2023-04-17 11:53:18');
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810699784814593, '通用五金配件', 1647810442107748353, 2, 1, '2023-04-17 11:54:20');
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810699793203202, '装饰五金配件', 1647810442107748353, 2, 21, '2023-04-17 11:54:20');
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810699797397506, '五金冲压配件', 1647810442107748353, 2, 0, '2023-04-17 11:54:20');
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810699805786113, '相框五金配件', 1647810442107748353, 2, 0, '2023-04-17 11:54:20');
INSERT INTO `procatch_work_om_sp_type` VALUES (1647810699814174722, '门窗五金配件', 1647810442107748353, 2, 0, '2023-04-17 11:54:20');
INSERT INTO `procatch_work_om_sp_type` VALUES (1648249529373491202, '铣床', 0, 1, 0, '2023-04-18 16:58:05');
INSERT INTO `procatch_work_om_sp_type` VALUES (1648249529377685506, '机床', 0, 1, 8, '2023-04-18 16:58:05');
INSERT INTO `procatch_work_om_sp_type` VALUES (1648249529381879810, '钻床', 0, 1, 0, '2023-04-18 16:58:05');
数据如下
1. 聚合函数介绍
什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
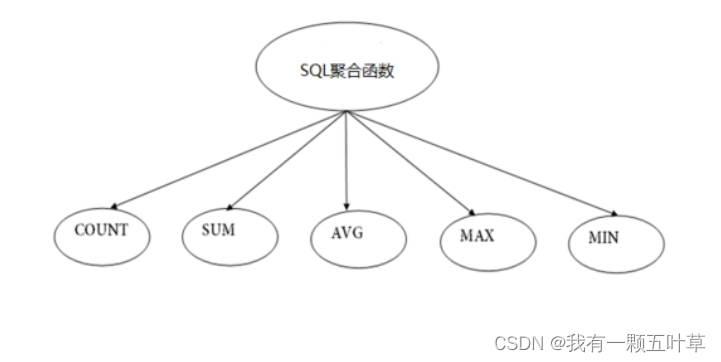
聚合函数类型
- AVG() 求平均值
- SUM() 求和
- MAX() 求最大值
- MIN() 求最小值
- COUNT() 求总行数
聚合函数语法
SELECT SUM(某字段) FROM TABLE_NAME WHERE ...
聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
1.1 AVG 和 SUM 函数
可以对数值型数据使用 AVG 和 SUM 函数。
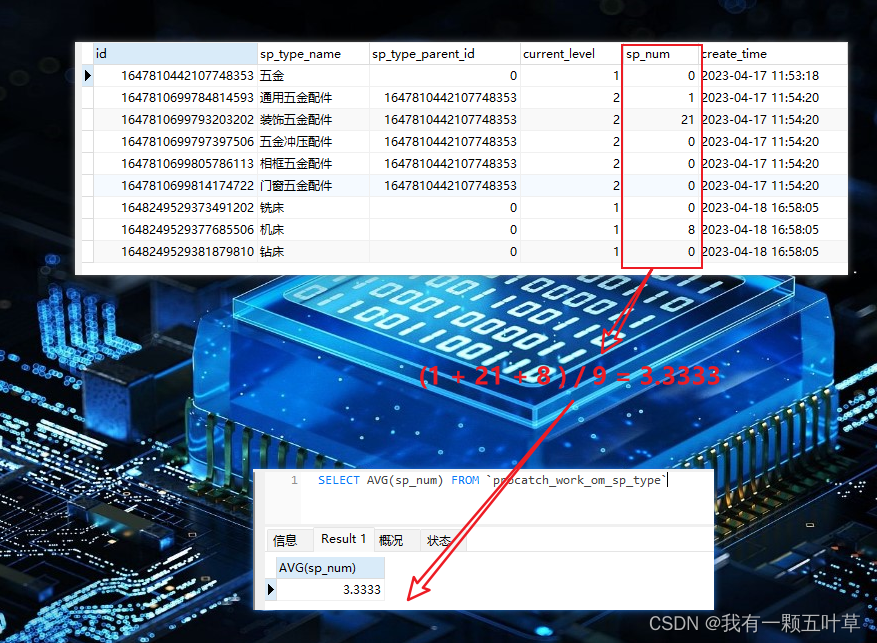
AVG 比如我们求案例表的全部备件类型下的备件数量的平均值
SELECT AVG(sp_num) FROM `procatch_work_om_sp_type`
结果如下:
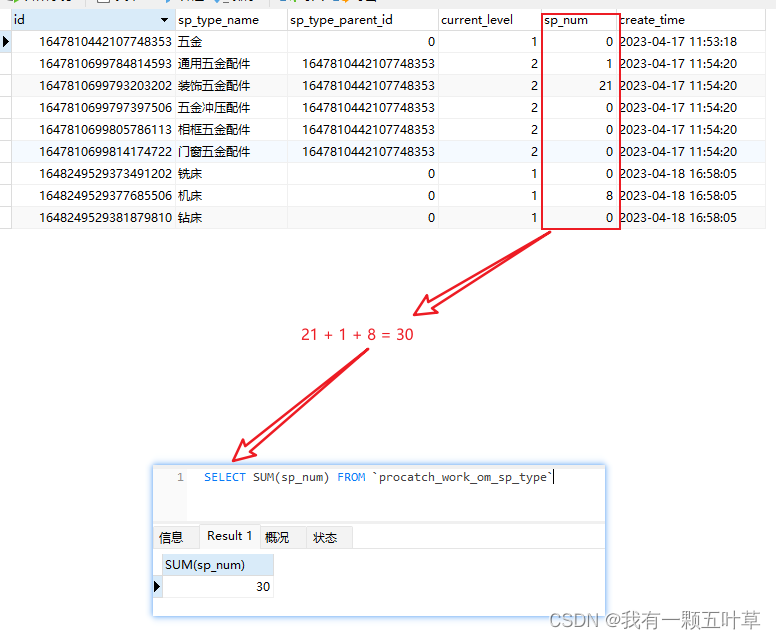
SUM 比如我们求案例表的全部备件类型下的备件数量的和
SELECT SUM(sp_num) FROM `procatch_work_om_sp_type`
结果如下:
1.2 MIN 和 MAX 函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
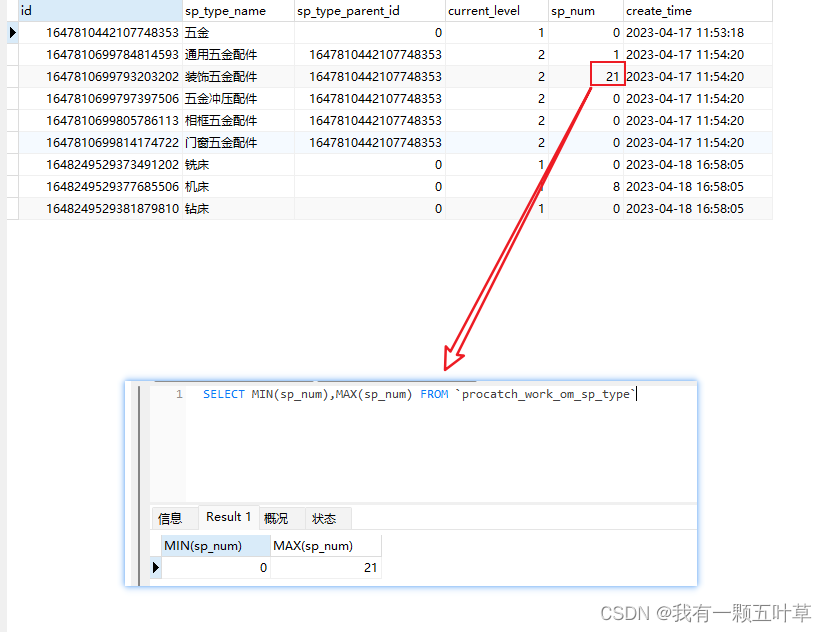
比如我们求案例表的全部备件类型下的备件数量的最小值、最大值
SELECT MIN(sp_num),MAX(sp_num) FROM `procatch_work_om_sp_type`
结果如下:
1.3 COUNT函数
COUNT(*) 返回表中记录总数,适用于任意数据类型。
COUNT(expr) 返回expr不为空的记录总数。
比如我们有如下这张表:
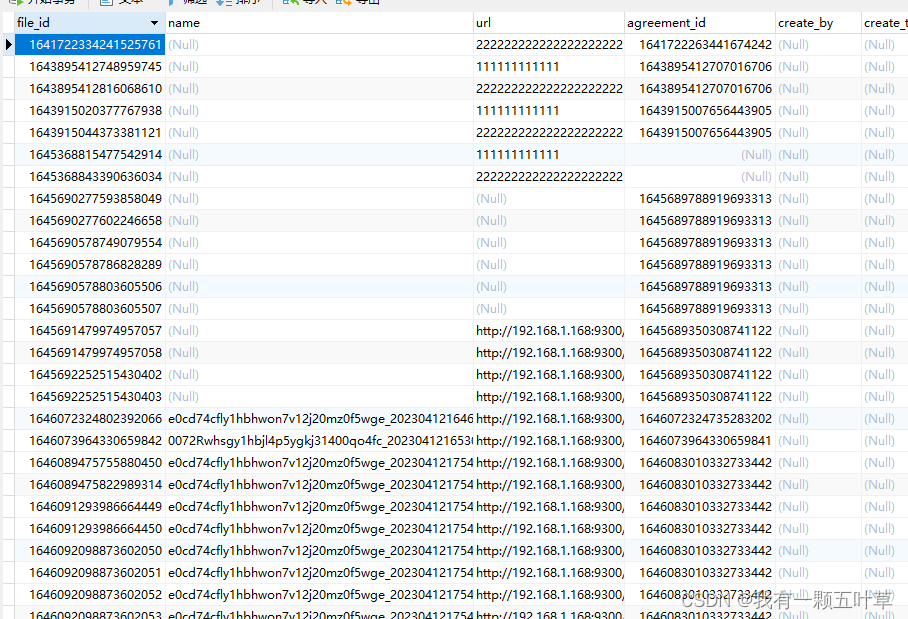
执行如下语句
SELECT COUNT(*), COUNT(name) FROM `agreement_file`
得到结果:分别为 46 个 29
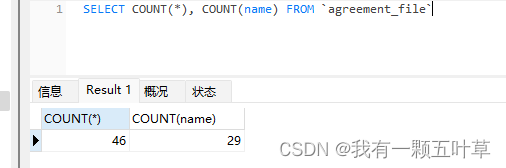
COUNT(*) 返回表中记录总数 :46 。
COUNT(name) 返回 name 不为空的记录总数 :29。
问题:用count(*),count(1),count(列名)谁好呢?
- 其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
- Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。
但好于具体的count(列名)。
问题:能不能使用count(列名)替换count(*)?
- 不要使用 count(列名)来替代 count(*) , count(*) 是 SQL92 定义的标准统计行数的语法,跟数
据库无关,跟 NULL 和非 NULL 无关。
- 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2. GROUP BY
2.1 基本使用
有如下一张表:
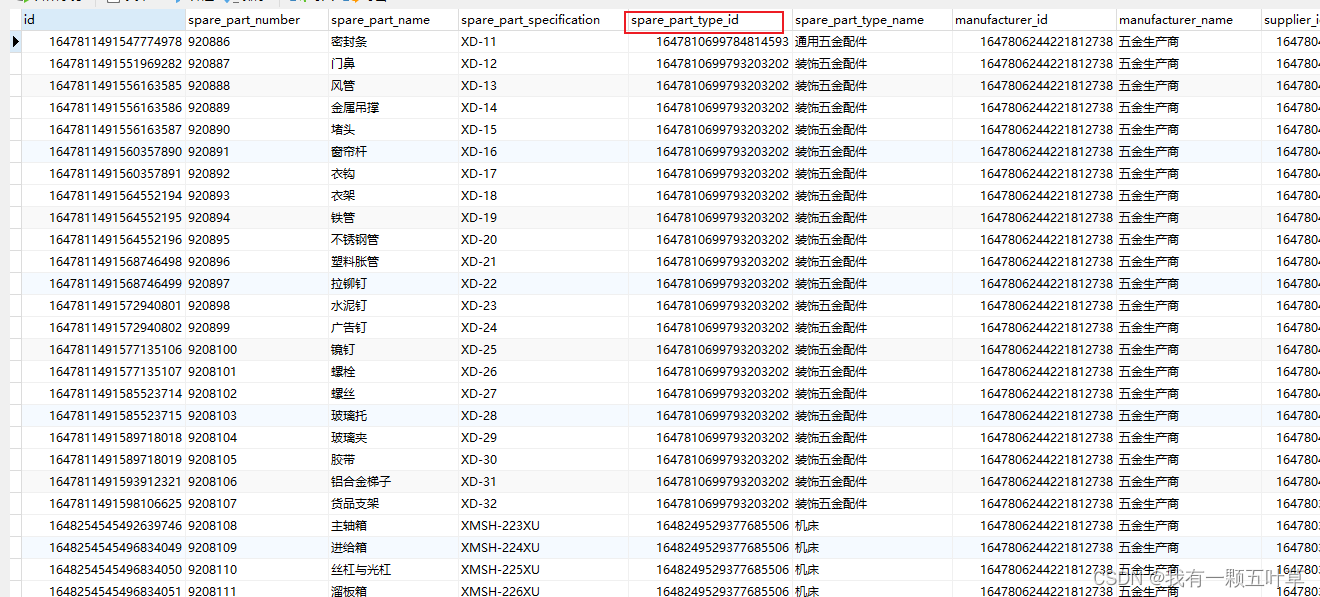
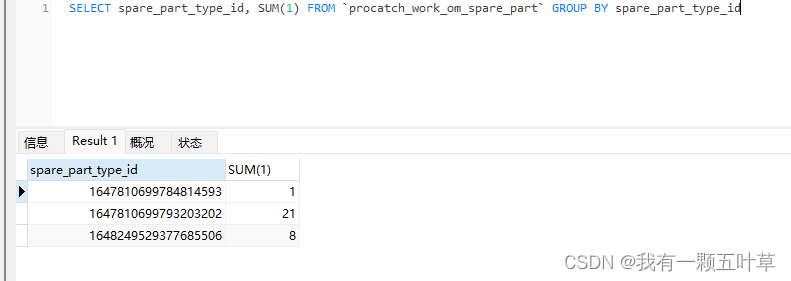
可以使用GROUP BY 语句将表中的数据分成若干组 展示每个备件类型的个数
SELECT spare_part_type_id, SUM(1)
FROM `procatch_work_om_spare_part`
GROUP BY spare_part_type_id
3. HAVING
3.1 基本使用
过滤分组:HAVING子句
1. 行已经被分组。
2. 使用了聚合函数。
3. 满足HAVING 子句中条件的分组将被显示。
4. HAVING 不建议单独使用,建议只和 GROUP BY 一起使用。

注意:不能在 WHERE 子句中使用聚合函数
3.2 WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
小结如下:
| 优点 | 缺点 | |
|---|---|---|
| WHERE | 先筛选数据再关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率较低 |
开发中的选择:
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。