1867-154075-0014
重中之重
run.sh脚本分析
wenet aishell脚本解析_weixin_43870390的博客-CSDN博客
一、准备工作
第一步:准备训练数据,拷贝到远程服务器
将准备好的数据文件0529_0531_dataset,上传到恒源云上的/hy-tmp/wenet/examples/aishell/s0下
0529_0531_merge_label .txt标签文件的内容中,每行为音频ID 空格 音频标签,无表头
本地文件:
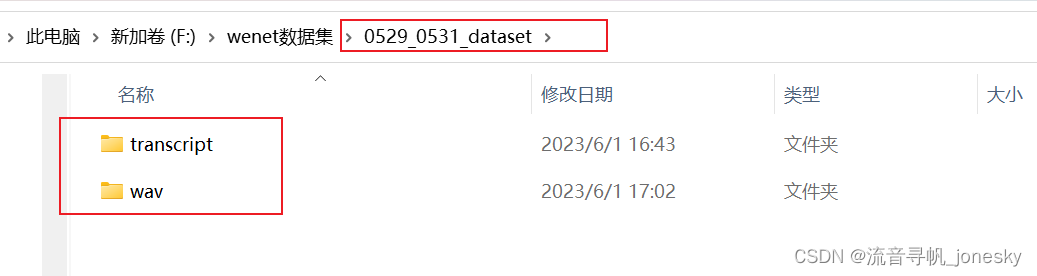



远程文件:

第二步,准备多个text和wav.scp文件,拷贝到远程服务器
1.远程上手动创建几个文件
cd /hy-tmp/wenet/examples/aishell/s0
mkdir -p data/train
mkdir -p data/test
mkdir -p data/dev2.拷贝text、wav.scp文件到远程服务器
将本地准备好的F:/wenet数据集/0529_0531_merge/chuli下的train、dev、test中的text、wav.scp两个文件分别拷贝到远程/hy-tmp/wenet/examples/aishell/s0/data下对应的train、dev、test文件夹下

text的内容如下:
音频ID 空格 音频标签
1867-154075-0014 你好请问有什么需要帮助的吗 1970-26100-0022 家里停电了
wav.scp的内容如下:
音频ID 空格 音频路径
1867-154075-0014 /hy-tmp/XXX/XXX.wav 1970-26100-0022 /hy-tmp/XXX/XXX.wav
二、修改run.sh脚本和yaml参数
先下载预训练模型
打开Pretrained Models in WeNet — wenet documentation

点击红框中的模型,先填表格,就可以下载
cd /hy-tmp/wenet/examples/aishell/s0
mkdir pretrained_model
cd pretrained_model
wget https://wenet-1256283475.cos.ap-shanghai.myqcloud.com/models/wenetspeech/wenetspeech_u2pp_conformer_exp.tar.gz
tar -xzf wenetspeech_u2pp_conformer_exp.tar.gz
解压后模型文件中包含四个文件:final.pt,train.yaml,units.txt,global_cmvn

然后开展以下步骤,修改/hy-tmp/wenet/examples/aishell/s0下的run.sh文件中的参数:
(1)根据GPU数量,修改序号
export CUDA_VISIBLE_DEVICES="0"
(2)修改结束步骤(可选,如果不一步一步敲命令,想直接执行多步必须改)
stop_stage=4
(3)修改训练数据的路径
data=/hy-tmp/wenet/examples/aishell/s0/0529_0531_dataset
其中0529_0531_dataset是前面上传的训练数据文件夹
(4)修改词典路径,为预训练模型的词典
虽然执行stage2会根据训练数据生成词典(几千个而已),但是要改成预训练模型的词典路径,因为预训练模型的语料比较大,生成的词典自然比较大(几万个)
dict=pretrained_model/20220506_u2pp_conformer_exp/units.txt
(5)修改模型配置(用预训练模型的yaml)
先改成预训练模型的yaml文件路径
train_config=pretrained_model/20220506_u2pp_conformer_exp/train.yaml
再打开预训练模型的train.yaml,修改里面的cmvn_file参数为(这边用绝对路径靠谱些,因为没有跟run.sh同级目录)
先用预训练模型的cmvn
cmvn_file: /hy-tmp/wenet/examples/aishell/s0/pretrained_model/20220506_u2pp_conformer_exp/global_cmvn
疑问:CMVN是对特征进行倒谱均值归一化,不是应该基于新的训练数据集计算得到的吗?理论上不应该用预训练数据的,都试试吧,看实验效果(测试不用预训练模型的还是报短音频帧数过滤方面的错误)
同时修改train.yaml中的其他参数
#改成16,防止显存不够
batch_size: 16
min_length: 30 # 1帧=10ms,过来掉少于0.3秒的
token_max_length: 200 #最大文字长度
max_epoch: 100 # 先训练100次试试
(6)修改成有计算cmvn
cmvn=true
修改修改$cmvn && cp data/${train_set}/global_cmvn $dir 为
$cmvn && cp /hy-tmp/wenet/examples/aishell/s0/pretrained_model/20220506_u2pp_conformer_exp/global_cmvn $dir
(7) 修改模型生成后的存放地址(每次新训练一个模型前,切记修改)
dir=model_0529_0531/conformer
(8)指定预训练模型,进行增量训练
checkpoint= pretrained_model/20220506_u2pp_conformer_exp/final.pt
即checkpoint=pretrained_model/20220506_u2pp_conformer_exp
(9)修改为多模型平均计算
average_checkpoint=true
(10)同时修改如下:
local/aishell_data_prep.sh ${data}/wav \
${data}/transcript
三、修改 s0/local/aishell_data_prep.sh的参数

根据实际情况修改文件名
aishell_text=$2/0529_0531_merge_label .txt
六、执行stage1
./run.sh --stage 1 --stop-stage 1
- 把transcript取掉空格,重新生成text,原来的变成text.org
- 使用wav.scp计算cmvn,存放到train目录下面
七、不执行stage 2(这步是生成词典,但是我们用的是预训练模型的词典,所以不用生成)
八、执行stage3
./run.sh --stage 3 --stop-stage 3
data/train data/test data/dev都生成了data.list
把wav.scp 和 text准备成data.list
九、开始训练
./run.sh --stage 4 --stop-stage 4