简介
最近参加一个统计建模的比赛。模型建模后,需要展示不同模型的性能指标,数据如下所示:

其中,第 1 列是不同样本,共376条。第 2-4 列是随机森林得到的结果,第 5-7 列是XGBoost的结果。一共使用了三种评价指标(分类数据:准确率,召回率和 F1 得分)。
对于这样的数据,读者会使用这么的方式进行可视化?欢迎文末留言交流~
小编当时想到的是,使用面积图展示,最终图形如下:
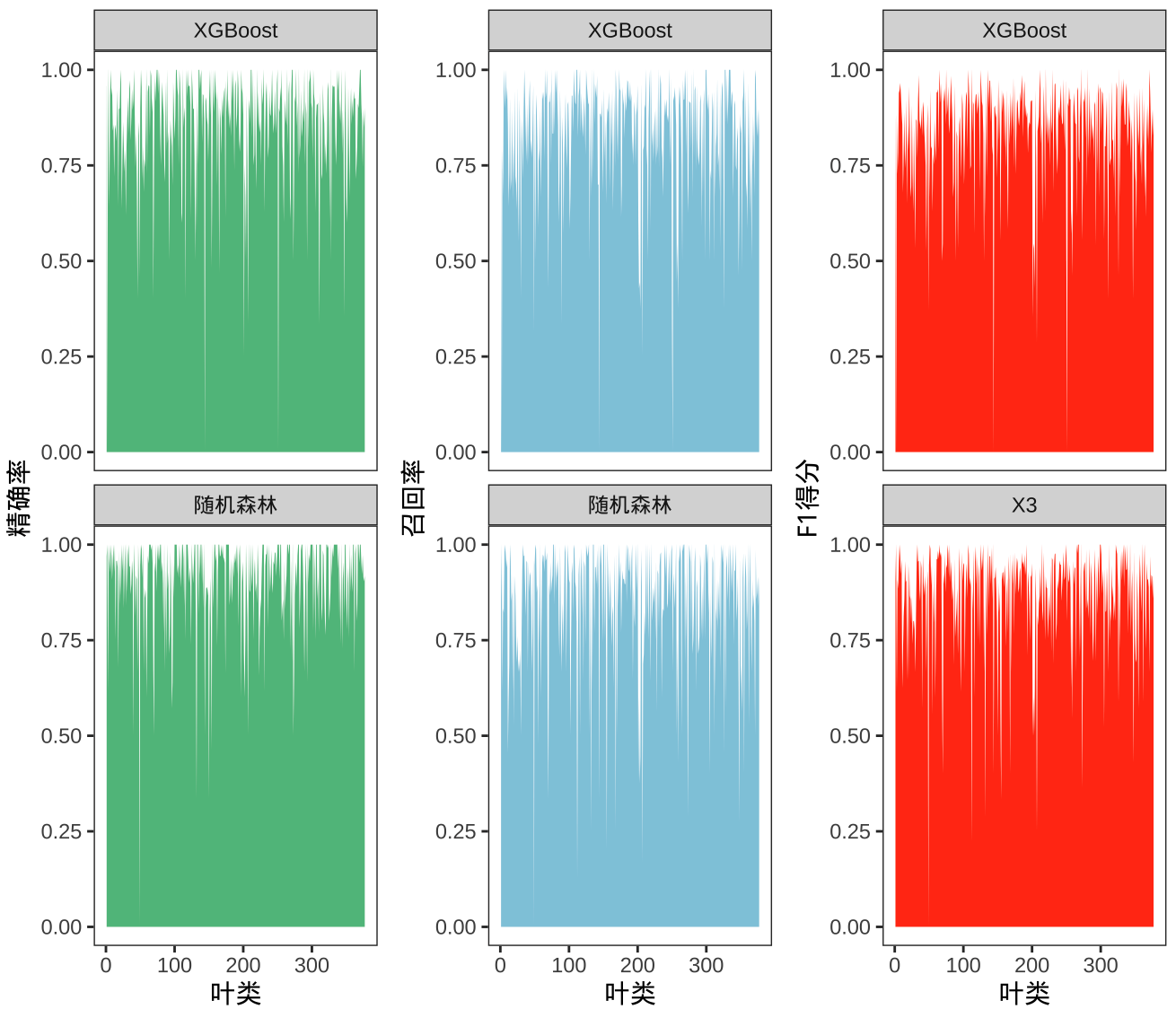
结论:从图中可以看出,两种集成算法对于 376 个叶类分类结果的评估指标都比较接近于 1,说明这两种方法整体效果比较满意。 但是对于 XGBoost 来说,小于 1 的部分更多,说明某些叶类分类效果差的情况更多。
注意:如果不是这个方向,可能看的不大懂。但是没关系,学会绘制,并将其用到自己的领域即可。在公众号后台回复[
建模比赛案例图形]即可免费获取。
接下来,将展示整个绘制过程。
加载数据
library(readxl) # 加载 Excel 数据集
library(ggplot2) # 绘制图形
library(tidyverse)
library(cowplot) # 合并图形
library(viridis) # 图形配色
library(showtext) # 解决中文字体显示问题
showtext_auto()
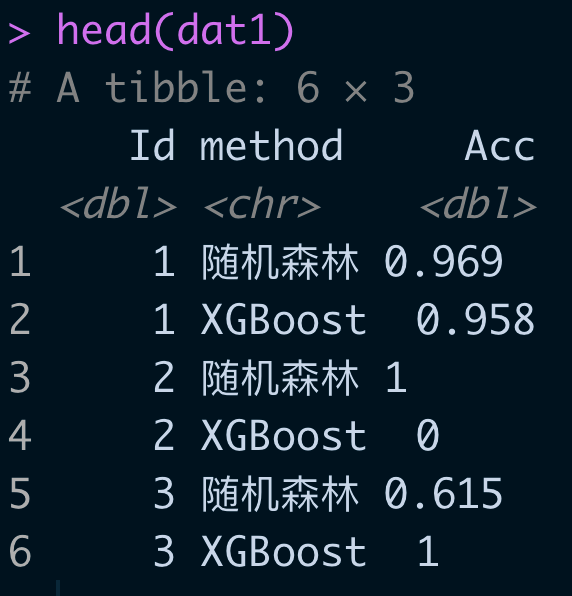
使用 readxl 包中的 read_excel() 加载 sheet=1 的数据集。并修改数据列名预览如下:
dat = read_excel("test.xlsx",sheet=1,na="NA")
colnames(dat) = c("Id",paste("X",1:6,sep=''))
head(dat)

使用 Tidyverse 包中的 pivot_longer() 将宽表转化为长表,具体教程可见:《R语言教程》。此时得到 ggplot2 所需的数据类型。
注意:小编这里将不同评价指标单独绘制,最后进行合并。
dat %>% select(c(Id,X1,X4)) %>% rename("随机森林"=X1, "XGBoost"=X4) %>%
pivot_longer(
cols = c("随机森林","XGBoost"),
names_to = "method",
names_transform = list(method = as.character),
values_to = "Acc") -> dat1
绘制单个评价指标结果
先绘制准确率的图形,使用的几何对象为:geom_area(),并利用 facet_wrap() 对方法(method)进行分面。之后,对主题以进行修改。使用自定义的颜色修改配色。
cols <- c("#85BA8F", "#A3C8DC","#349839","#EA5D2D","#EABB77","#F09594")
p1 = ggplot(dat1) +
geom_area(aes(Id,Acc),fill = cols[1]) +
facet_wrap(vars(method),nrow = 2,strip.position = "top") +
theme_bw() +
ylab("精确率") +
xlab("叶类") + #主题设置
theme(panel.grid = element_blank())
p1

同理,绘制其他两种指标体系的结果。这里就不放出来了,完整代码见公众号,回复【建模比赛案例图形】即可免费获取,或者文末。
合并图形
最后使用 cowplot 包中的 plot_grid() 将三个指标图形进行合并
plot_grid(p1,p2,p3,ncol = 3)
完整代码
# install.packages("readxl")
library(readxl)
library(ggplot2)
library(tidyverse)
library(cowplot)
library(viridis)
library(showtext)
showtext_auto()
### 绘制不同方法的区域图===========
dat = read_excel("test.xlsx",sheet=1,na="NA")
colnames(dat) = c("Id",paste("X",1:6,sep=''))
head(dat)
dat %>% select(c(Id,X1,X4)) %>% rename("随机森林"=X1, "XGBoost"=X4) %>%
pivot_longer(
cols = c("随机森林","XGBoost"),
names_to = "method",
names_transform = list(method = as.character),
values_to = "Acc") -> dat1
head(dat1)
cols <- c("#85BA8F", "#A3C8DC","#349839","#EA5D2D","#EABB77","#F09594")
#==
p1 = ggplot(dat1) +
geom_area(aes(Id,Acc),fill = cols[1]) +
facet_wrap(vars(method),nrow = 2,strip.position = "top") +
theme_bw() +
ylab("精确率") +
xlab("叶类") + #主题设置
theme(panel.grid = element_blank())
p1
#==
dat %>% select(c(Id,X2,X5)) %>% rename("随机森林"=X2, "XGBoost"=X5) %>%
pivot_longer(
cols = c("随机森林","XGBoost"),
names_to = "method",
names_transform = list(method = as.character),
values_to = "Acc") -> dat2
p2 = ggplot(dat2) + geom_area(aes(Id,Acc),fill = cols[2]) + facet_wrap(vars(method),nrow = 2,strip.position = "top") +
theme_bw() + ylab("召回率") + xlab("叶类") + #主题设置
theme(panel.grid = element_blank())
p2
#==
dat %>% select(c(Id,X3,X6)) %>% rename("随机森林"=X3, "XGBoost"=X6) %>%
pivot_longer(
cols = c("随机森林","XGBoost"),
names_to = "method",
# names_transform = list(method = as.factor),
values_to = "Acc") -> dat3
p3 = ggplot(dat3) +
geom_area(aes(Id,Acc),fill = cols[4]) +
facet_wrap(vars(method),nrow = 2,strip.position = "top") +
theme_bw() +
ylab("F1得分") +
xlab("叶类") + #主题设置
theme(panel.grid = element_blank())
p3
#== 合并图形
plot_grid(p1,p2,p3,ncol = 3)




![[附源码]计算机毕业设计ssm校园一卡通服务平台](https://img-blog.csdnimg.cn/1d06ef2aaec34ead9a32094a73251654.png)
![[附源码]计算机毕业设计基于springboot的家政服务平台](https://img-blog.csdnimg.cn/c1fa8b8299ca48b5a20f70d97283853e.png)

![[附源码]Python计算机毕业设计Django框架的食品安全监督平台的设计与实现](https://img-blog.csdnimg.cn/d6d8f5deaf264b9b9145e19c411e9877.png)




![[附源码]计算机毕业设计毕业生就业管理系统](https://img-blog.csdnimg.cn/03d58f0760ff4b0197b13439a3e6cfdf.png)