目录
什么是窗口函数
窗口函数与其他函数区别
over()函数
窗口函数类型
窗口函数举例
什么是窗口函数
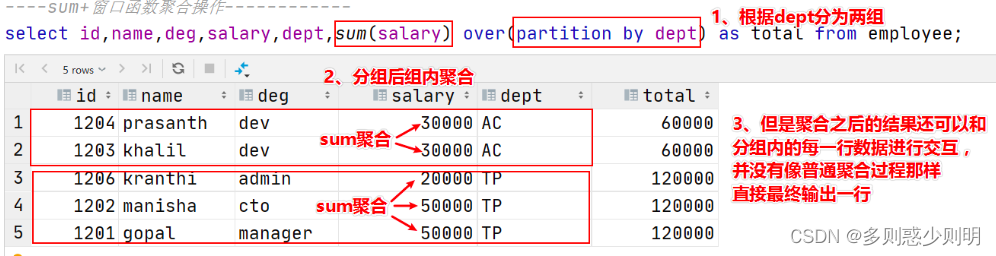
窗口函数是一种SQL函数,非常适合于数据分析,因此也叫做OLAP函数。
最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。
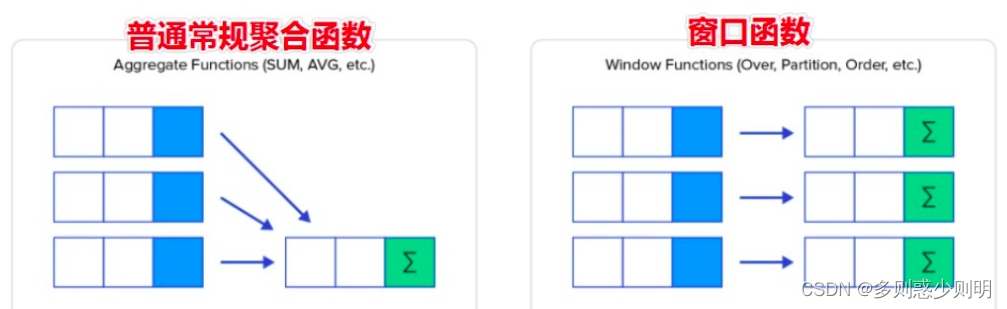
窗口函数简单的说就是在执行聚合函数的时候指定一个操作窗口,这个窗口由over来进行控制
窗口函数与其他函数区别
如果函数具有OVER子句,则它是窗口函数。
如果它缺少OVER子句,则它是一个普通的聚合函数
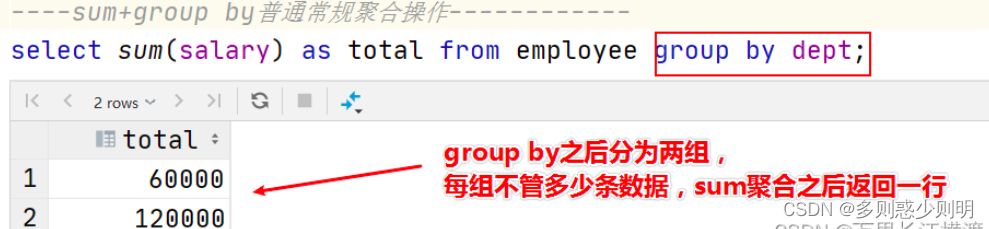
通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
例子:
参考
hive窗口函数(开窗函数)_hive 窗口函数_万里长江横渡的博客-CSDN博客
over()函数
over():指定分析函数工作的数据窗口大小,这个大小可能会随着行的变化而变化。
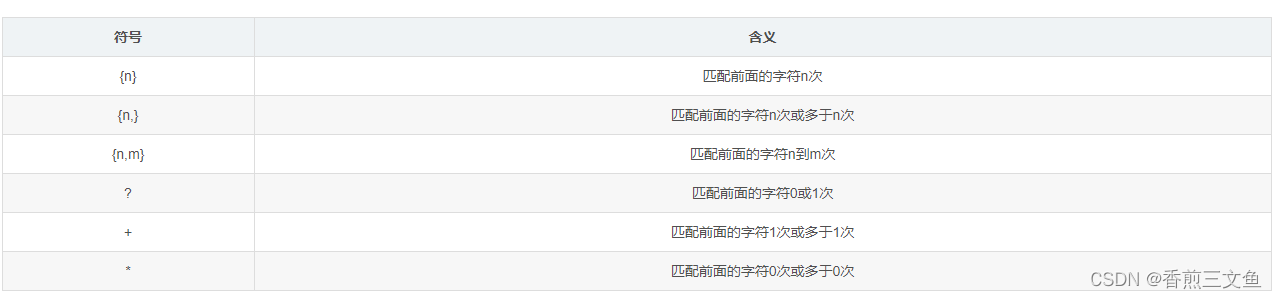
其基本语法如下:<分析函数> over ( partition by <用于分组的列名> order by <用于排序的列名> desc/asc rows between 开始行 and 结束行 )
例子:
select
user_id,
user_type,
sales,
count(user_id) over(partition by user_type order by sales desc
rows between unbounded preceding and current row) as cnt
from order_detailover()里面一共有3部分组成:分区、排序、指定窗口范围,注意这三部分可以组合使用,也可以不使用。
- partition by col:按照字段col分组,在组内进行分析。
- order by col:分组后在组内按照字段col进行排序。
- rows/range:窗口子句,在分析时进一步分组。
- rows: 是物理窗口,即根据order by子句排序后,取的前m行及后n行的数据计算
- range: 是逻辑窗口,是指定当前行对应值的范围取值,取大于等于当前行的值-m的行,以及小于等于当前行的值+n的行进行计算
窗口范围取值可选项
1)范围取值
【a:rows+参数来控制范围】
默认值(不写):这个其实是最常用的,下面会进行不同情况下默认值总结
preceding:往前;
following: 往后
current row:当前行
unbounded :起点(一般结合preceding,following使用)
unbounded preceding: 表示该窗口最前面的行(起点)
unbounded following:该窗口最后面的行(终点)
例子:
rows between unbounded preceding and current row --(表示从窗口起点到当前行)
rows between unbounded preceding and unbounded following--(表示从窗口起点到终点)
rows between 2 preceding and 1 following --(表示往前2行到往后1行)
rows between 2 preceding and 1 current row --(表示往前两行到当前行)
rows between current row and unbounded following --(表示当前行到终点)
窗口函数类型
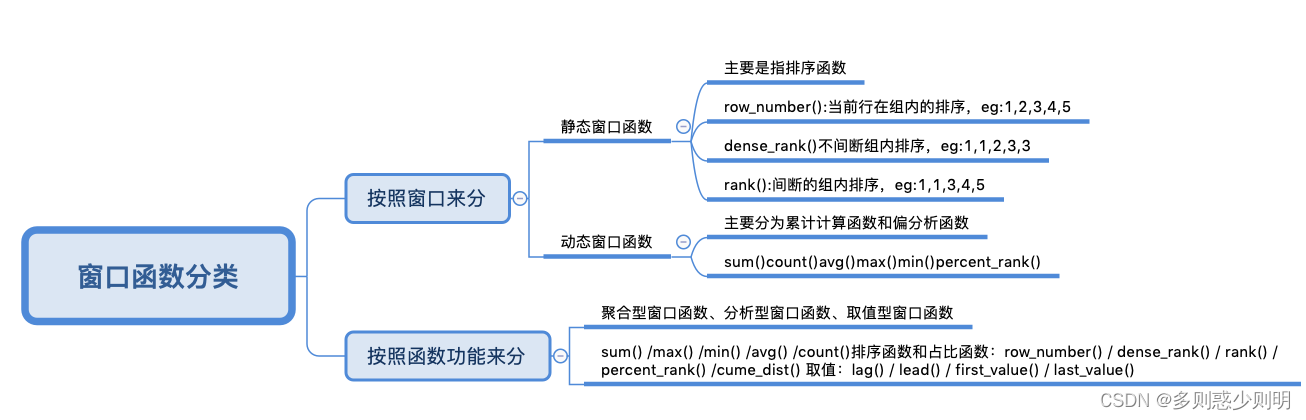
常用窗口可划分为如下几类:聚合函数(max、min、sum、avg、count)、跨行取值函数()、排名函数
例子: 三个排序函数区别(每种用户类型销量排名)
select
user_id,
user_type,
sales,
row_number() over(partition by user_type order by sales) as rn,
dense_rank() over(partition by user_type order by sales) as rd,
rank() over(partition by user_type order by sales) as rr
from order_detail
返回排序序号
ROW_NUMBER() : 一列连续的序号,如1,2,3,4,5
RANK():对于数值相同的这一项会标记为相同的序号,而下一个序号跳过。比如{4,5,6}变成了{4,4,6}.
DENSE_RANK():对于数值相同的这一项,也会标记为相同的序号,但下一个序号并不会跳过。比如{4,5,6}变成了{4,4,5}.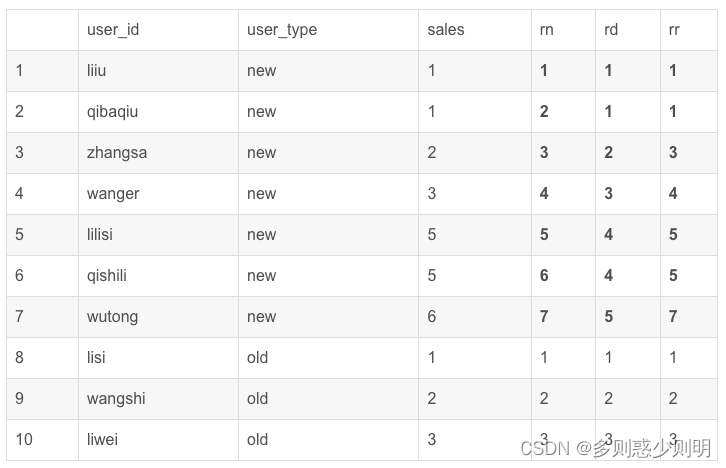
例子:Hive中使用over()实现累积求和
sum(需要求和的列) over(partition by 分组列 )
sum(需要求和的列) over(partition by 分组列 order by 排序列 asc/desc)
sum(需要求和的列) over(partition by 分组列 order by 排序列 range between … and …)
select*,sum(cnt) over(partition by name order by month) as total_cnt
from default.salerinfo
例子:
> --默认为从起点到当前行
> sum(t.gold_medal) over (order by t.gold_medal) as sum2,
> --从起点到当前行,同sum2。
> sum(t.gold_medal) over (order by t.gold_medal rows between unbounded preceding and current row) as sum3,
> --当前行+往前1行
> sum(t.gold_medal) over (order by t.gold_medal rows between 1 preceding and current row) as sum4,
> --当前行+往前1行+往后2行
> sum(t.gold_medal) over (order by t.gold_medal rows between 1 preceding and 2 following) as sum5,窗口函数举例
lead (col,n,def) :返回窗口内col列往下第n行的值。col为列名,n为往下第n行(省略则默认为1),def为默认值。 说明:与lag的取值方向相反。
lag (col,n,def):返回窗口内col列往上第n行的值。col为列名,n为往上第n行(省略则默认为1),def为默认值。 说明:与lead的取值方向相反。
分别包括:
lag和lead(不支持自定义窗口):
lag(): 按照 所在行的偏移量 取 前面的第几行
lead(): 按照 所在行的偏移量 取 后面的第几行
first_value和last_value(支持自定义窗口):
first_value():当前窗口内所有行数据中的最小值
last_value(): 当前窗口内所有行数据中的最大值
⚠️要注意,lag和lead不能使用自定义窗口,因为已经规定好了具体某一行与当前行作为一个窗口,不能再定义是负无穷到正无穷这样自定义的规则。