文章目录
- 一. 左值?右值?
- 二. 右值引用的使用
- 三. 万能引用&完美转发
- 四. 移动构造&移动赋值
- 结束语
一. 左值?右值?
C++中,对于左值,右值,我们可能会理解为 = 赋值符号左边是左值,右边是右值。但是其实不是的。
首先,左值是什么?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址,并且可以对其赋值。
左值可以出现在赋值符号的左边,也可以出现在赋值符号的右边。定义在const修饰符后的变量也是左值,虽然不能赋值,但是可以取地址。
int a = 10;
int *p = new int(7);
const char*str = "hello world";
这当中,除了10和"hello world",其他都是左值。因为他们都可以取地址。
而什么是右值呢?
10和"hello world"其实都是右值。
右值也是一个表示数据的表达式,如:字面常量,表达式返回值,函数返回值等等。右值都具有常性
右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边,右值不能取地址。
int x=10;
int y=20;
x+y
x+y就是一个右值。
区分右值和左值的方式就是看是否能取地址
左值引用就是对左值的引用
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
需要注意的是,const 左值引用可以引用右值。
因为2是右值,具有常性,直接左值引用其实是权限的放大,const左值引用时正确的
右值引用就是对右值的引用,给右值取别名
右值引用的语法:&&
//常见的右值
10;
x + y;
// 对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
//右值引用可以引用move的左值
int a=10;
int &&r1=move(a);
需要注意的是,右值不能取地址,但是右值引用,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是说,右值引用后的变量时左值。我们了解了右值的原理后可以有更好的理解。
稍微总结一下
- 左值可以取地址,右值不能取地址
- 左值引用只能引用左值,不能引用右值。但是const左值引用既可以引用左值,也可以引用右值
- 右值引用只能引用右值,不能引用左值。但是右值引用可以引用move后的左值
二. 右值引用的使用
首先,C++11还对右值进行分类:1.纯右值 2. 将亡值
int a=3;
int b=func(6);
int c=(x+y);
以上,3是纯右值
func(6)是函数的返回值,(x+y)是表达式的返回值。二者都是将亡值
将亡值其实就是中间过渡的临时变量,完成中间传递任务就要被销毁。
我们再回忆一下引用的目的:1. 给变量起别名 2. 减少拷贝
左值引用一般用于函数参数,函数返回值。因为传参和传值返回都是从一个域(函数)跳转到另一个域(函数),但在域中我们有申请堆区的数据,这份数据是每个域都可以访问的,而我们传递变量如果使用传参返回的话,会发生深拷贝,数据也不是原先的数据,还会多出拷贝的消耗。
但如果参数是引用或者传引用返回,就不会有深拷贝的出现
但是左值引用并没有解决全部的问题。我们还是会有传局部变量的情况,局部变量不能使用左值引用,因为局部变量出了作用域就销毁了,使用左值引用时非法访问空间。而当我们传参返回的是一个类时,拷贝的消耗会很大。所以右值引用就诞生了。
右值引用其实就是对局部变量,临时对象数据的转移。
首先,我们使用传值返回,可以看到a和b的地址其实并不一样,所以b是a的拷贝
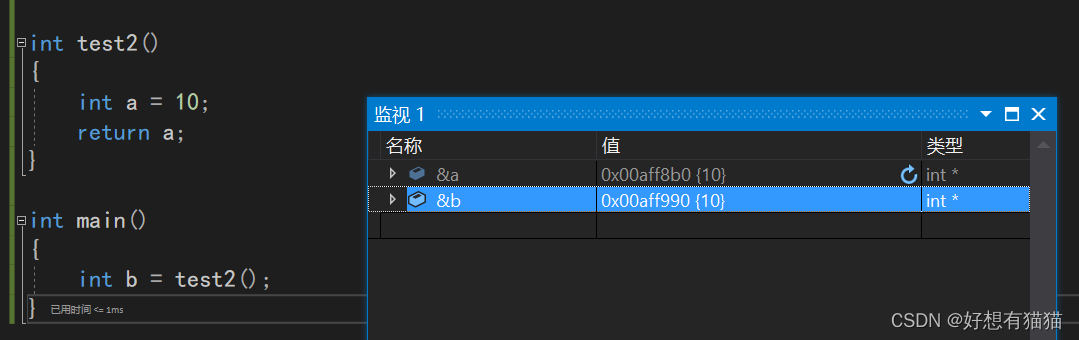
因为a是局部变量,无法传引用返回。此处还只是因为a是int类型,拷贝代价低。但是如果是我们自定的类,那么拷贝的代价就高了。右值引用可以解决这样的问题。
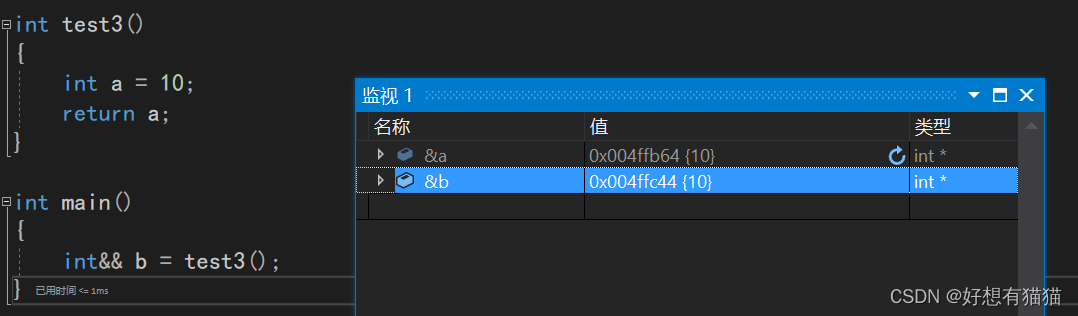
这里我们看到,a和b的地址是一样的,其实右值引用就是将a这个局部变量的数据,转移到b中。
我们再以string作为例子了解右值引用的使用场景
首先,我们使用自己实现的简单的string,因为我们需要在构造处打印输出。方便我们观察。
string 如下:
namespace ljh
{
class string
{
public:
//单参数的构造
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
//cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
移动构造
//string(string&& s)
// :_str(nullptr)
// , _size(0)
// , _capacity(0)
//{
// cout << "string(string&& s) -- 移动语义" << endl;
// swap(s);
//}
移动赋值
//string& operator=(string&& s)
//{
// cout << "string& operator=(string&& s) -- 移动语义" << endl;
// swap(s);
// return *this;
//}
~string()
{
delete[] _str;
_str = nullptr;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string operator+(char ch)
{
string tmp(*this);
tmp += ch;
return tmp;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity; // 不包含最后做标识的\0
};
}
我们在拷贝构造和赋值重载处加上输出语句,如果是深拷贝,那么就会调用二者之一。

我们看到,str2的构建是由两次深拷贝完成的。
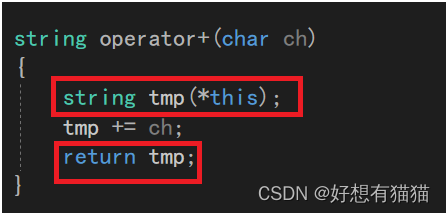
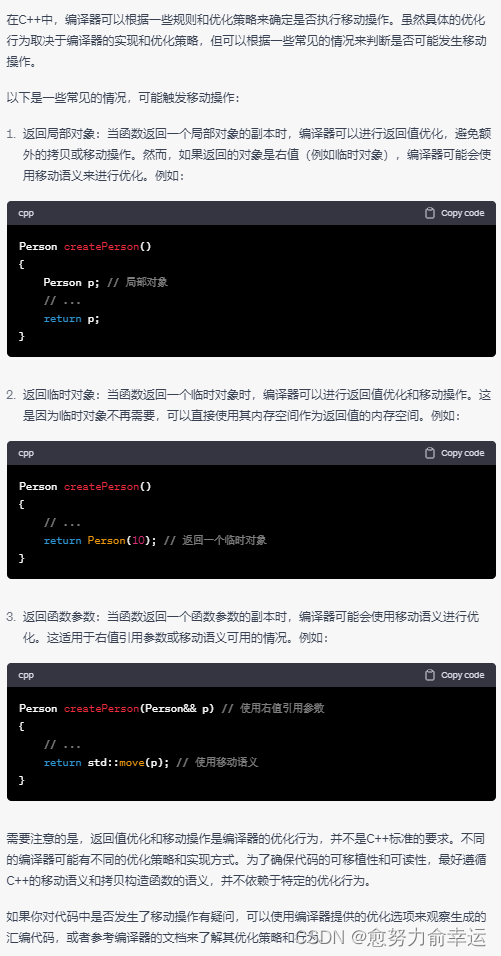
两次深拷贝分别是第一个红框中的拷贝构造,和第二个传值返回,拷贝构造的临时对象。其实这里编译器还做了优化。原本还会有一个临时对象,传值返回的构造其实需要两次拷贝构造,但是编译器对于连续的构造会优化成一次拷贝构造。
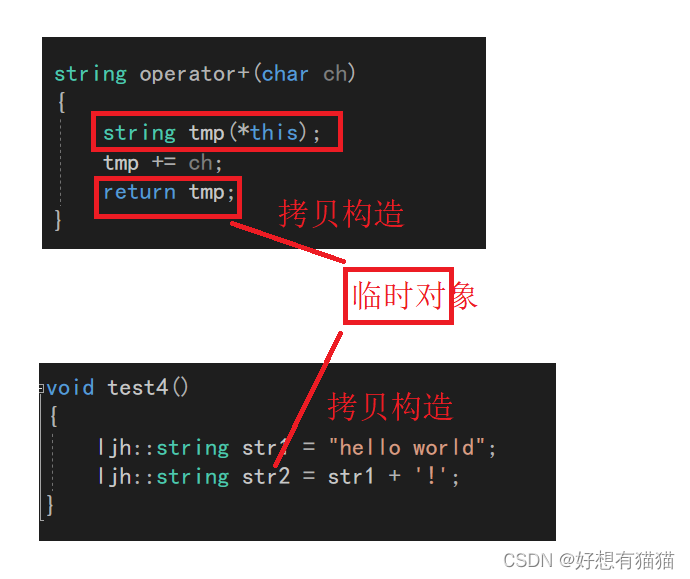
这样拷贝的消耗其实是非常之大的。
其实在operator+中,创建的局部对象中的数据本来就可以使用,但是因为局部对象,无法直接将数据传递给别的域,所以需要拷贝。我们完全可以把局部对象的数据,转移到目标对象中,只需要一次交换,即减少拷贝,又不浪费资源。
那右值引用如何使用呢?
首先,我们要在函数传参上区分二者
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 移动构造
string(string&& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
cout << "string(string&& s) -- 移动构造" << endl;
swap(s);
}
当参数是一个右值时,会优先匹配下面的构造。使用右值引用,减少局部对象拷贝的构造,我们叫做移动构造。

这次,传值返回时因为是临时对象,所以会优先匹配移动构造。
我们按步骤分析一下

首先,tmp是拷贝构造,也就是深拷贝,所以tmp和str1虽然内容一样,但是地址不同。

接着,tmp+=ch,扩容,地址改变。

移动构造,直接将扩容后的tmp的内容全部转移到str2中,二者内容相同,地址相同,说明是数据的直接转移。这就减少了拷贝的消耗了。
但是编译器此处还是存在优化
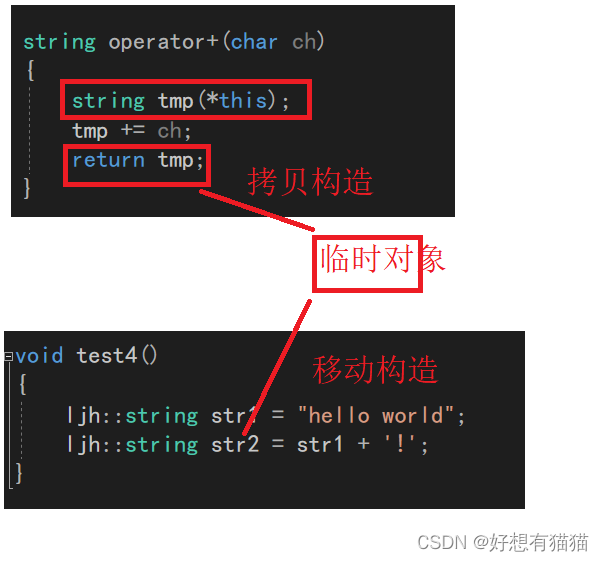
原本应该是先有一次拷贝构造,然后再移动构造。编译器优化成了只有一次移动构造。
右值引用参数的使用,在C++11的STL中都有实现

不仅如此,在相应的插入函数中,也有右值引用的重载版本
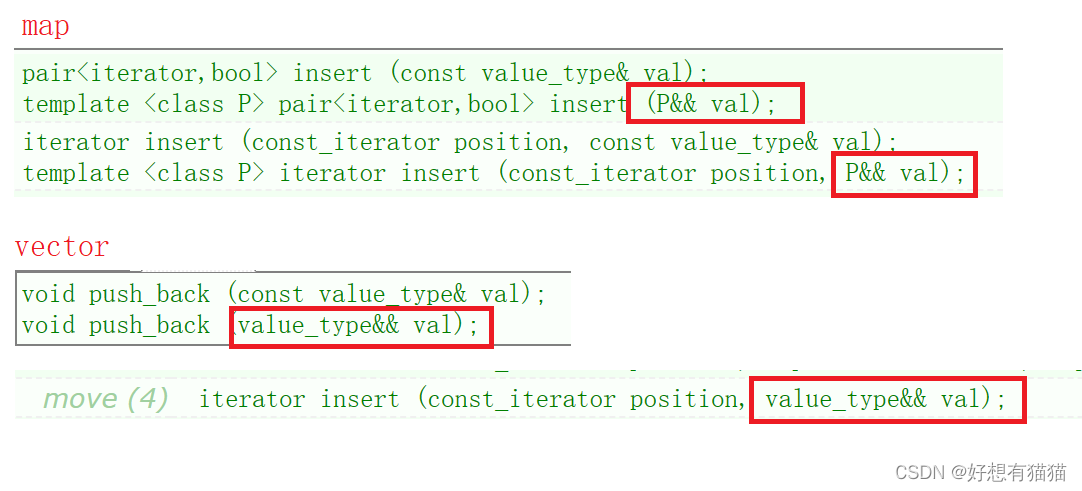
在C++98中,没有右值引用,没有移动构造,那么在使用STL时,比如list,拷贝的成本也很大。

像这样使用匿名对象,就会发生深拷贝。
但是如果是C++11,有右值引用和移动构造,就会是如下结果:

因为匿名对象时右值,生命周期也就一行,我们完全不需要重新拷贝一份匿名对象的数据,我们直接将匿名对象的数据转移就好了。
三. 万能引用&完美转发
我们先看下面这段代码
void Fun(int &x)
{
cout << "左值引用" << endl;
}
void Fun(const int &x)
{
cout << "const 左值引用" << endl;
}
void Fun(int &&x)
{
cout << "右值引用" << endl;
}
void Fun(const int &&x)
{
cout << "const 右值引用" << endl;
}
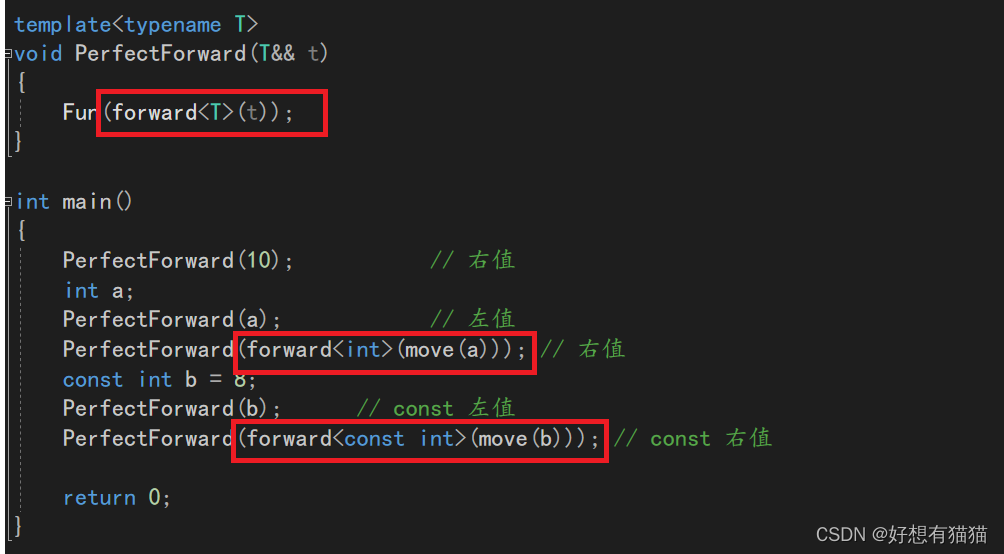
template<typename T>
void PerfectForward(T&& t)
{
Fun(t);
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
运行结果如下:
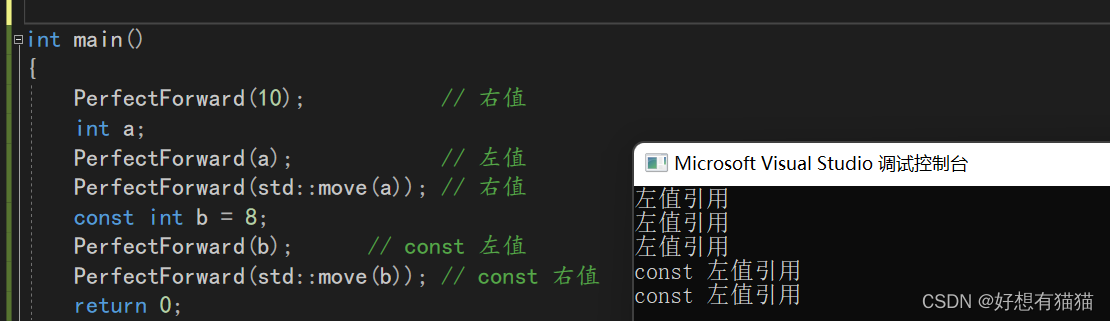
可以看到,不管传入的参数是否是左值,函数模板的推导都是左值。
这就是万能引用。
我们在第一部分也说了,右值引用的属性是左值,如下
int&&rr1=10;
rr1=20;
cout<<&rr1<<endl;
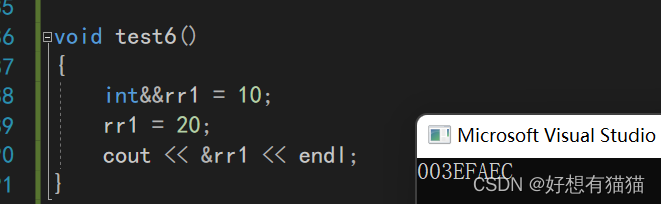
rr1既可以修改值,也可以取地址,所以是左值。
但是这就引出了一个问题。
在类似的函数模板或者类模板场景下,函数传参不就没有右值引用了吗?
而且在STL库中,右值引用不一定是在当前函数中使用,可能还会继续向下传递,但是如果是类模板的话,那就会出现万能引用的场景,右值引用就丢失了,变成左值引用了。
所以为了保持右值引用的属性,C++11提供了完美转发
完美转发:forward<函数模板>()
保持原本的左值属性(右值属性)

四. 移动构造&移动赋值
在C++中,类的默认成员函数有6个
构造函数2.析构函数3.拷贝构造函数4.拷贝赋值重载5. 取地址重载 6. const 取地址重载
前四个较为的重要,后两个使用不多。默认成员函数就是我们不写,编译器会生成一个默认的。
而在C++11中,又新增加了两个默认成员函数:移动构造和移动赋值重载。
移动构造我们上述已经讲解过了,其实就是接收右值,然后将右值的数据交换。
而移动赋值重载,也是同理:接收右值,然后将数据交换。我们还以自己编写的string为例。移动赋值重载代码如下:
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动构造" << endl;
swap(s);
return *this;
}
针对移动构造和移动赋值重载,二者默认生成的条件较为特殊,不同于前6个默认成员函数。
-
如果没有实现移动构造函数,且
析构函数,拷贝函数,拷贝赋值重载也都没有实现,那么编译器会自动生成默认移动构造。默认生成的移动构造,对于内置类型成员变会按字节拷贝,对于自定义类型成员,则需要看这个成员是否实现移动构造,有,则调用其移动构造,否则调用其拷贝构造 -
如果没有实现移动赋值重载,且
析构函数,拷贝函数,拷贝赋值重载也都没有实现,那么编译器会自动生成一个默认移动赋值。默认生成的移动赋值重载,对于内置类型成员会按字节拷贝,对于自定义类型,需要看该成员是否实现移动赋值重载,有则调用移动赋值重载,否则调用拷贝赋值重载 -
如果提供了移动构造或者移动赋值重载,编译器则不会自动提供默认函数
小小总结一下:如果是深拷贝的类,那么析构,拷贝构造,拷贝赋值重载都需要编写,那么此时,也不会有默认的移动构造和移动赋值重载,需要我们自己编写。反之,浅拷贝的类,如果我们没有实现任意一种,则会生成默认的移动构造和移动赋值重载
结束语
感谢你的阅读
如果觉得本篇文章对你有所帮助的话,不妨点个赞支持一下博主,拜托啦,这对我真的很重要。