大家好,我是千与千寻,可以叫我千寻,我自己主要的编程语言是Python和Java。
说到Python编程语言,使用Python语言主要使用的是数据科学领域的从业者。
Python编程语言之所以在数据科学领域十分火热,源于Python语言的三大数据科学工作包,NumPy,Pandas,SciPy。
以下是三个工具包的功能简介。
NumPy:NumPy 是 Python 中最常用的数值计算库之一。它提供了一个高效的多维数组对象和用于操作数组的函数,使得在 Python 中进行数值计算变得更加简单和高效。

Pandas:Pandas 是一个功能强大且灵活的数据分析工具,广泛用于数据清洗、整理和处理。Pandas 提供了丰富的数据操作和转换函数,可以进行数据的选择、过滤、聚合、合并等操作,方便进行数据预处理和分析。

SciPy:SciPy 提供了许多模块和子模块,包括线性代数、数值积分、优化、信号处理、图像处理、统计学等领域的函数和工具。常用于数据分析、数值计算、科学计算以及机器学习等领域。

对于数据科学行业的从业者掌握pandas,numpy,scipy三大数据科学工具包是最基本的技能之一。
Numpy工具包主要用于矩阵的变换,而SciPy工具包则是应用于图像处理领域。但是真正对实际的数据清洗,整理以及处理的操作使用的是pandas工具包,同时业务方的底层数据集通常是以csv的表格文件进行存储的。
我们以下的一个实际的代码例子,来亲自感受一下Pandas工具包的实际用法与教程。
需求:对电影评分表格数据处理,加载电影数据集的数据,计算平均评分,同时对不同评分数量的电影进行数量统计,并绘制饼状图。
备注:电影评分表格数据内容,表格数据中包含三列,电影序号,电影名称,电影评分。
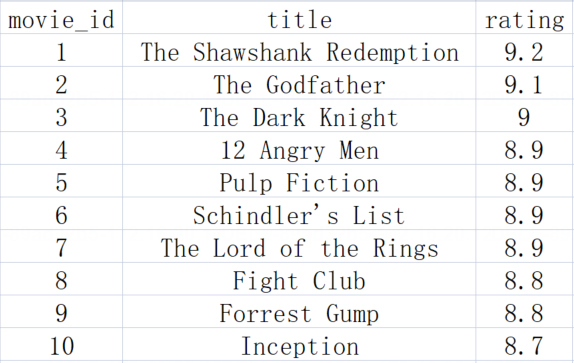
- 加载表格数据集的数据内容并打印
# 加载数据集
data = pd.read_csv('movies.csv')
# 展示前几行数据
print(data.head())
运行结果:
movie_id title rating
0 1 The Shawshank Redemption 9.2
1 2 The Godfather 9.1
2 3 The Dark Knight 9.0
3 4 12 Angry Men 8.9
4 5 Pulp Fiction 8.9
- 计算平均评分
# 计算平均评分
average_rating = data['rating'].mean()
print('平均评分:', average_rating)
运行结果:
平均评分: 8.919999999999998
- 统计不同评分的数量
rating_counts = data['rating'].value_counts()
print('评分统计:')
print(rating_counts)
运行结果:
评分统计:
8.9 4
8.8 2
9.2 1
9.1 1
9.0 1
8.7 1
- 将电影评分的分布绘制为饼状图
# 绘制评分分布饼状图
plt.pie(rating_counts.values, labels=rating_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('电影评分分布')
运行结果:
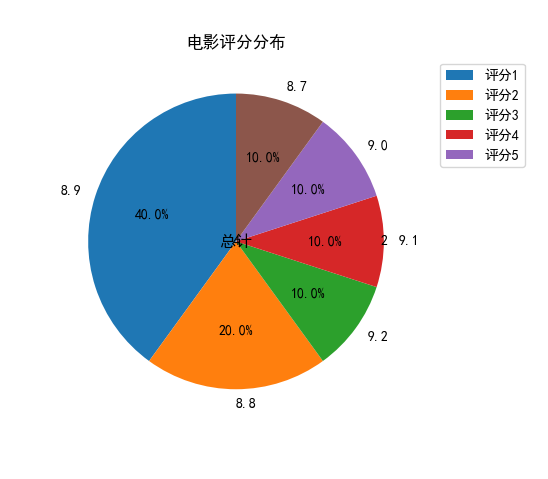
怎么样,Pandas代码工具包进行表格数据的处理能力,效果是不是十分不错呢?而且感觉很酷炫!
不过Pandas代码工具包还是需要一定的编程基础的,由于还需要定义绘制图片的字体以及布局等,所以即使这样几个简单的处理,也写了大约60行的代码。
那么,有没有什么办法,直接让代码自动生成或者处理我们的数据需求?
当然了!在AI的洪流时代,没有什么是不可能!Pandas与ChatGPY两个工具包,进行强强结合。
现在已经诞生了“ChatGPT+Pandas”结合的:Pandas-ai工具包,实现了人工智能辅助我们做数据分析!
到底是什么效果,我们一起来看一看!
- PandasAI安装命令
pip install pandasai
- 准备基础表格的数据,引用了官网的各国GDP数据
import pandas as pd
from pandasai import PandasAI
# 随机初始化各国名称,GDP数据,幸福指数数据
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [19294482071552, 2891615567872, 2411255037952, 3435817336832, 1745433788416, 1181205135360, 1607402389504, 1490967855104, 4380756541440, 14631844184064],
"happiness_index": [6.94, 7.16, 6.66, 7.07, 6.38, 6.4, 7.23, 7.22, 5.87, 6.12]
})
from pandasai.llm.openai import OpenAI
llm = OpenAI(api_token="YOUR_API_TOKEN")
pandas_ai = PandasAI(llm, conversational=False)
pandas_ai(df, prompt='Which are the 5 happiest countries?')
api_token="YOUR_API_TOKEN"中的字符串替换为自己的API KEY,生成方法很简单,如下图:
以上代码的运行结果如下图所示
According to the data, the top 5 happiest countries are the United States, Canada, Australia, United Kingdom, and Germany.
- 不仅可以直接进行对话的文字回答,PandasAI的工具包还可以直接进行图片生成
pandas_ai.run(df, "Plot the histogram of countries showing for each the gpd, using different colors for each bar")
以上代码的运行结果如下图所示
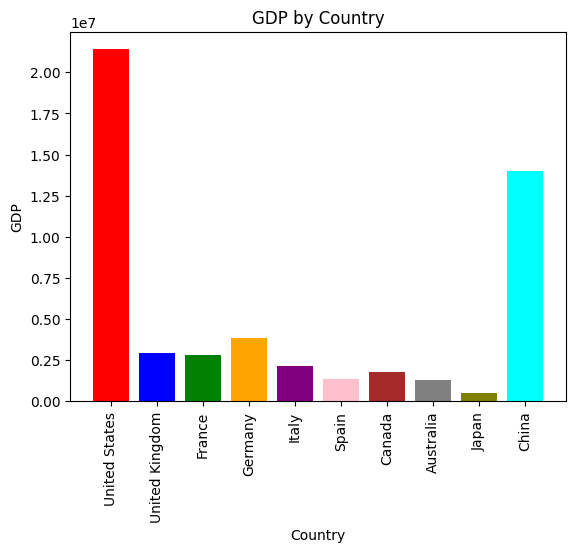
4.并且PandasAI工具包不仅仅支持英文对答,中文也是支持的
pandas_ai.run(df, "哪个国家的GDP最少?使用中文回答")
运行结果输出:
哪个国家的GDP最少?日本。
怎么样?是不是十分的神奇?在ChatGPT的大模型时代,真的没有任何行业不受冲击的。
作为一名程序员要学会拥抱变化,使用Pandas+ChatGPT去提高自己的工作效率,因为时代在发展进步!
我是千与千寻,一名只讲干货的码农,我们下期见~
本文由mdnice多平台发布