1.相关工作
1)基于结构的知识嵌入
进一步分成基于翻译的模型和基于语义匹配的模型
基于翻译的模型采用基于距离的评分函数,TransE把实体和关系嵌入到一个维度为d的共享向量空间中;TransH,TransR,RotatE.
语义匹配模型采用基于相似性的评分函数,RESCAL,DistMult,CoKE.
2)基于描述的知识嵌入
DKRL [Xie等人,2016]首先引入实体的描述,并通过卷积神经网络对其进行编码。
KEPLER [Wang等人,2019b]使用PLM作为编码器来派生基于描述的嵌入,并以KE和PLM的目标进行训练。
Pretrain-KGE [Zhang et al ., 2020b]提出了一种通用的基于描述的KE框架,该框架使用基于描述的嵌入初始化另一个可学习的KE,并在微调plm后丢弃plm以提高效率。
KGBERT [Yao等人,2019]将h, r, t的描述作为一个输入序列连接到plm,并通过序列嵌入对这三个序列进行评分。
StAR
2.LMKE模型
在本文中,我们提出了一个更好地将语言模型用作知识嵌入的方法LMKE(Language Models as Knowledge Embeddings),同时利用结构信息和文本信息。
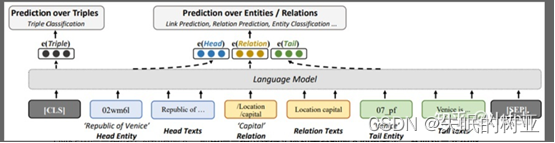

嵌入完,要进行链接预测和三元组分类两个任务。三元组分类基于上面的p(u)可以进行。但链接预测需要预测出不完整实体的缺失实体,需要将候选实体(一般是所有实体)填入不完整三元组,并把相应的三元组打分,再对候选实体按照得分进行排序。但是上面的LMKE模型,这个流程的时间复杂度太高。
所以就有了下面的变体
为了让语言模型高效用于链接预测任务,一个简单的方式是不完整地编码三元组,而仅编码部分三元组。
MEM-KGC模型
MEM-KGC可以看作LMKE的masked变体,将待预测的缺失实体和其文本描述mask,并将相应的向量表示q输入一个线性层来预测缺失实体。
降低了时间复杂度,担忽略了待预测实体的文本信息,降低了文本信息的利用率。
提出了一个对比学习框架来更充分利用文本信息
在框架中,给定的实体-关系对被看作查询q,目标实体(缺失实体)被看作键k,通过匹配q和k进行对比学习。
3.C-LMKE模型(本文提出的模型)
C-LMKE是对比学习框架下的LMKE变体,
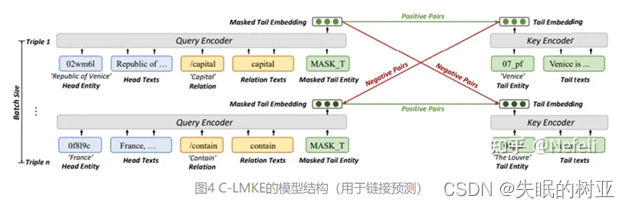
C-LMKE进行批次内的对比匹配,从而避免编码负样本带来的额外开销。
具体来说,对于batch中的第i个三元组,它的给定实体关系对q和目标实体k构成一个正样本,而同batch内其他三元组的目标实体k’与q构成负样本。
C-LMKE在训练和链接预测时的时间复杂度均显著优于现有基于文本的方法。
使用双层MLP(多层感知器)来计算q和k的匹配度,而不是使用对比学习中常用的余弦相似度,因为可能存在多个键匹配q。
如果k1和k2都匹配q,并且我们最大化(q, k1)和(q, k2)之间的相似性,(k1, k2)也会被强制相似,这是不可取的。因此,q与k匹配的概率为:

d_q和d_k是度数信息,对应实体在训练集中三元组个数
基于得分p(q, k),我们使用二元交叉熵作为损失函数进行训练,并参考RotatE中提出的自对抗负采样来提高难负样本的损失权重。
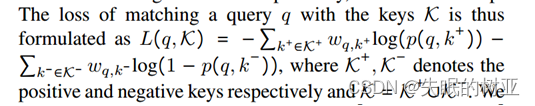






![深度学习 - 52.推荐场景的多样性与 MMR [Maximal Marginal Relevance] 简介与 Python 实现](https://img-blog.csdnimg.cn/5ff39b73dc78496f8559afba2b144fe2.png)