目录
一.引言
二.多样性
三.MMR 流程
1.标准 MMR
2.窗口 MMR
四.基于向量内积相似度的 MMR Python 实现
1.模拟用户 rank 结果
2.向量内积计算 MRi
2.1 获取向量计算 max sim
2.2 argmax 获取最优 MRi item
3.MMR 测试
4.MMR 完整代码
五.总结
一.引言
MMR - Maximal Marginal Relevance 最大边界相关算法是一种多样性计算方法,最早起源于 NLP,后被应用于推荐算法的重排用于提高推荐的多样性。
二.多样性
推荐系统常常分为召回、粗排、精排与重排、随着步骤的深入,物料的数量也越来越小,精排给 n 个候选 item 打分后,可以获得每个物品的融合分数,有纯 CTR 场景,此时分数为 CTR、也有多目标场景、例如同时预测 Item 的点赞率、收藏率、点击率等等,此时将多个指标加权作为当前 item 的融合分数,这里我们统称为 reward_i 代表当前 item 的回报值。
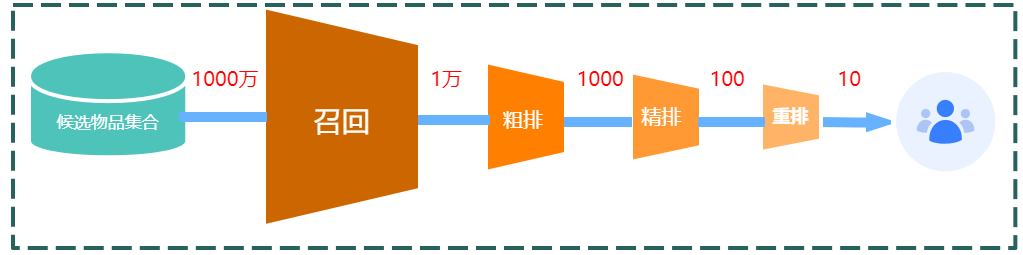
传统推荐阶段在精排后按照 reward_i 降序排列取 TopK 即可实现推荐,为了提高用户推荐的多样性,我们引入了 item 的相似度度量记录为 sim(i,j),其中相似度的计算可以是简单的类目匹配,也可以是 Context 文本向量的相似度度量。
多样性重排要求从 n 个精排 item 中选出 TopK,要求这 K 个商品既有高精排分数,也拥有一定的多样性。
三.MMR 流程
1.标准 MMR
Maximal Marginal Relevance 最大边界相关算法:
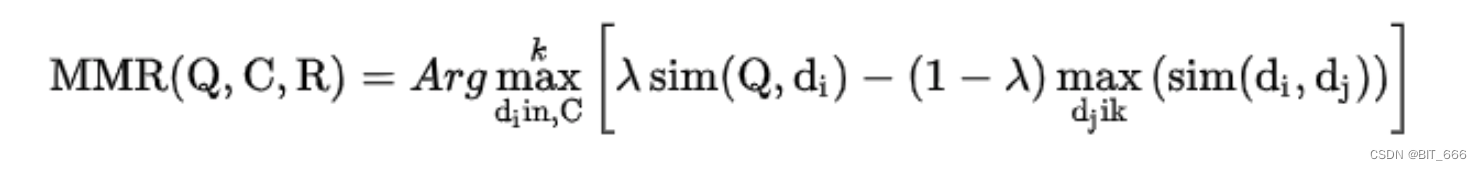
上图为 MMR 在论文中的公式表达,上面多样性中我们提到 MMR 最终的目的是既要又要,所以式子中的 λ 很明显是作为调节因子,控制用户既要想要的区分度,下面解释下推荐系统下的 MMR 计算:
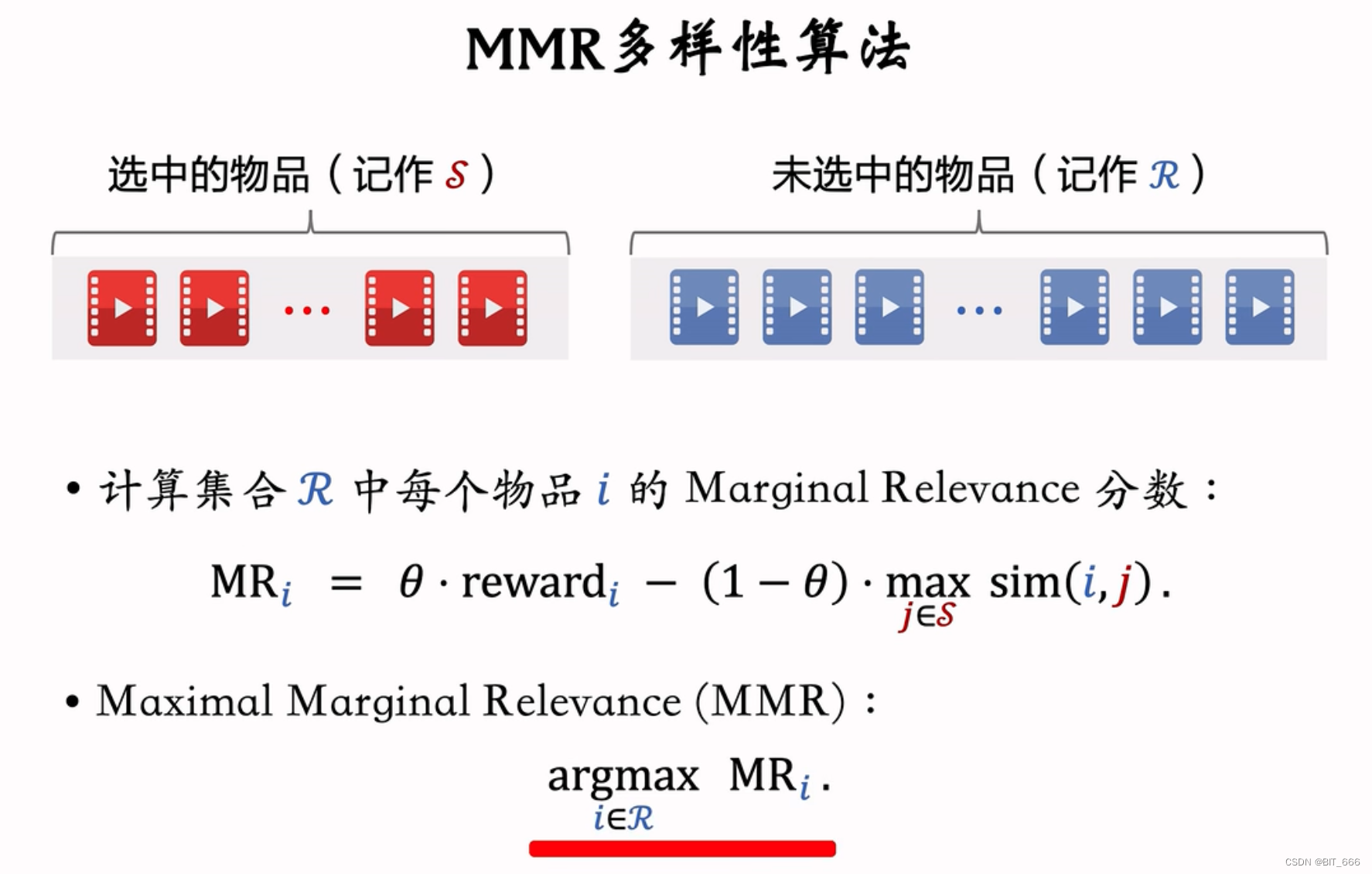
• 构建集合 S 与 R
精排后获得 N 个候选商品,其中 reward 排名第一个 item 构成数组 S = [Top],剩下的 N-1 个商品构成数组 R。S 中的物品代表已选、R 中的物品代表备选,假设要从 N 中选 Top K,则 MMR 的任务是从 R 中挑选 K-1 个商品送进 S。
• 计算 R 中商品的 MRi
初始化 S 和 R 后,需要计算 R 中每个物品的 MRi,MRi 是综合了商品的打分与其与 S 中商品的多样性得到的分数,θ 为调和参数,θ 越大越偏向 reward 高的商品,反之越偏向多样性强的物品,此时曝光少、长尾的物品更容易获得下发机会。
i 代表当前 R 中的某个候选集,j 是所有当前 S 中的商品,需要计算 i、j 的相似度,并取出 max 的值,这一步主要是为了让当前 i 尽量不与 S 中的某个商品很相似,从而导致多样性差或者出现重复内容。
• MMR 添加商品至 S
遍历 R 中的商品并计算 sim(i,j),argmax 找到 MRi 最大的候选 item 从 R 中 pop 并 append 添加至 S 中。重复上述步骤 K-1 次,此时 len(S) = K、len(R) = N - K ,迭代结束,S 作为 MMR 重排后的结果参与后续推荐逻辑。
Tips:
- 关于 S 的初始化
为什么 S 初始化要放入 reward 最高的商品,这是因为当 S 为 0 时,max sim 这一项为 0 ,所以 RMi 的计算只考虑 θ * reward,自然会放入 reward 最高的商品,当 S 有元素时,max sim 这一项非 0 ,从而可能出现 reward 低但多样性好的商品逆袭。
- sim(i,j) 计算
sim(i,j) 可以是简单的物品属性匹配,例如一级类目、二级类目、三级类目的匹配,也可以通过预训练 embedding 的方式,获取不同商品的 embedding,通过计算向量内积、向量 Cos 等方式计算候选集之间的相似度。这里推荐使用基于图片或者 NLP 语义理解的 embedding 方式,而不推荐类似双塔的结构,这是因为双塔训练对于长尾与低曝光物品训练不到位,可能影响效果。
- 关于 max、θ
max 是寻找当前候选与所有 item 中相似度的最大值,这里也可以尝试 mean 代表与整体的相似度差异。 θ 的话就根据自己的场景调试即可,不同的值不同的偏好,可以从 0.5 试起来。
2.窗口 MMR

当 K 设置的很大时,随着添加的物品增多,max sim(i,j) 总是约等于1,这将导致 MMR 算法退化成基于 reward 排序。 解决方案也很简单,把 max 的计算方式修改,把与 J ∈ S 改成 J ∈ SBS 即 S 的一个子集,实际场景下为 S 中最近选中的 M 个物品。这个也很好理解,第 1 个物品和第 30 个物品可以相似,这对多样性并不会造成多大影响,只要保证局部的 W 内的多样性同样可以做好用户的多样性。
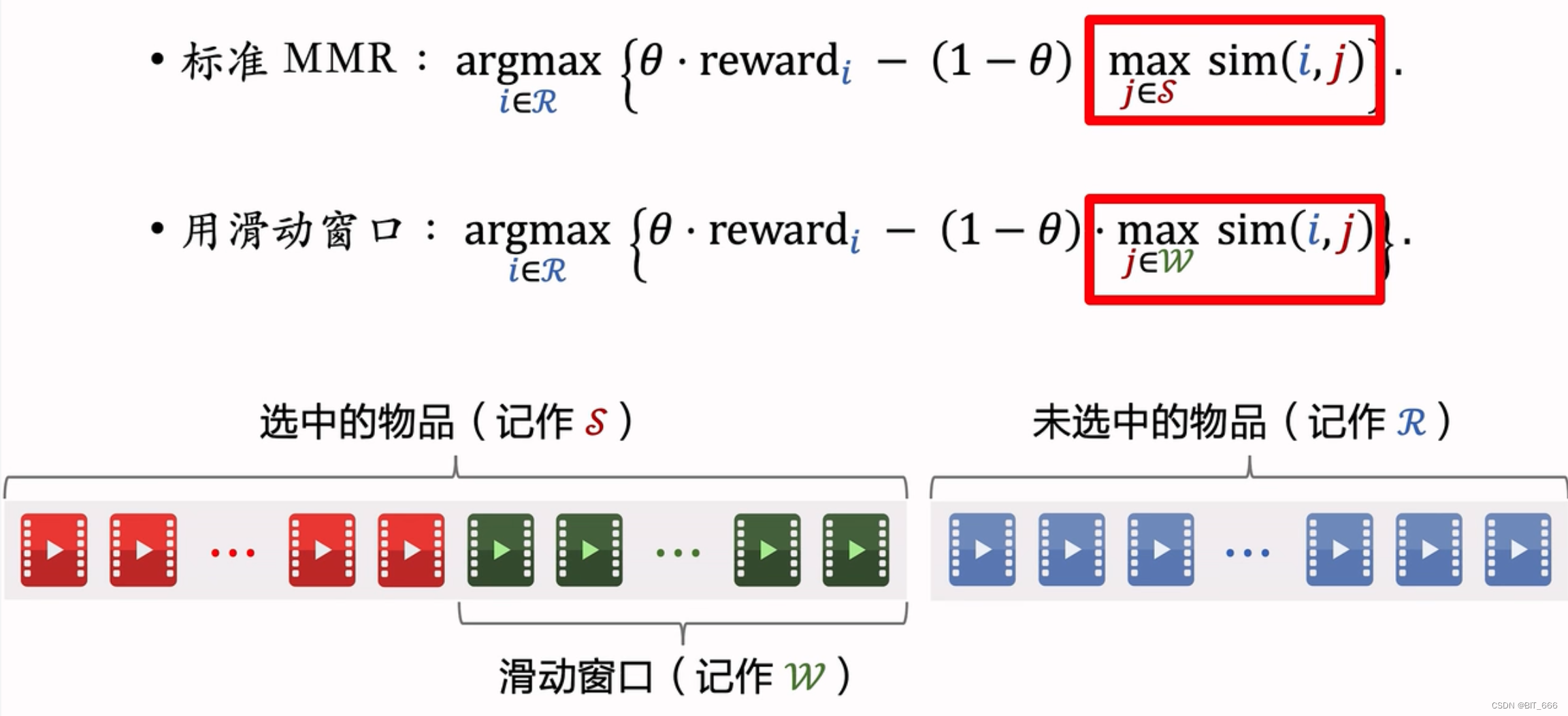
Tips:
- 关于计算复杂度
传统 MMR 计算需要遍历 R 中的物品,同时 R 中每个物品还需要遍历 S 中的物品,计算复杂度较高。引入滑动窗口可以有效缩减 max sim(i,j) 的计算量,可以通过提前缓存 item 之间的 sim 值或者引入动态 Cache 提高 MRi 的计算速度。除此之外,通过 batch 矩阵计算也可以优于 for 循环的 sim 计算。
- 关于 W 窗口大小
这个参数的设置有多个考虑因素,一方面要考虑用户一次刷新要曝光的物品条数,W 应该与该数量成正比,除此之外也可以考虑实际端上曝光可显示范围数,例如手机上一屏只能显示 6 件商品,那么也可以适当缩小 W 范围。
四.基于向量内积相似度的 MMR Python 实现
1.模拟用户 rank 结果
if __name__ == '__main__':
total = 10000
n = 100
k = 10
theta = 0.5
# 1.模拟用户排序分数,假设此时为精排,候选集 n=100
R = list(zip(np.random.randint(0, total, size=n), np.random.random(n)))
# 2.Embedding 相似度依据
id_embedding = dict(zip(list(range(0, total)), np.random.random(size=(total, 8))))这里假设商品库大小为 10000,精排结果为 100,重排后选择 K=10 个商品,R 代表用户排序的商品 id 与 reward 得分:
(2929, 0.8633555492090925)
(1662, 0.18390267494361623)
(8939, 0.9977265350155343)
(2402, 0.3223362034792787)
(9430, 0.19965218206425672)id_embedding 为模拟的 10000 个商品的预训练 embedding,实际场景下可以通过 NLP 例如 bert 生成相关的文案 Embedding,通过 CNN 生成相关的图像信息 Embedding 再将二者结合:
9995: array([0.77517001, 0.6545193 , 0.07678476, 0.82733098, 0.86182284, 0.04631414, 0.00104291, 0.91166001]),
9996: array([0.68162543, 0.3751251 , 0.10805542, 0.63555129, 0.51926022, 0.2010376 , 0.59947074, 0.7950087 ]),
9997: array([0.95780135, 0.00484409, 0.05476651, 0.65649113, 0.71699212, 0.88593591, 0.49342144, 0.29664633]),
9998: array([0.88086731, 0.70929634, 0.58964263, 0.70942298, 0.16545527, 0.6283401 , 0.02261712, 0.46174134]),
9999: array([0.88725936, 0.33872398, 0.10774754, 0.95433321, 0.71457625, 0.92265572, 0.63147676, 0.48301763])}2.向量内积计算 MRi
2.1 获取向量计算 max sim
sort_list = []
for item in _R:
# 候选 Id 与预期收益
item_id = item[0]
item_reward = item[1]
# 获取向量用于相似度计算
item_emd = np.expand_dims(_id_embedding[item_id], axis=0)
# 是否使用滑动窗口
if is_slid:
s_emd = np.transpose([_id_embedding[s[0]] for s in _S[len(_S) - window_size: len(_S)]])
else:
s_emd = np.transpose([_id_embedding[s[0]] for s in _S])
# 计算 Max Sim ij
max_sim = np.max(np.dot(item_emd, s_emd))
# 计算 MRi
MRi = theta * item_reward - (1 - theta) * max_sim
sort_list.append((item_id, item_reward, MRi))获取 Ri 的向量,与 S 中的多个候选商品 Item 进行 Batch Dot 计算,最后套公式计算 MRi。
2.2 argmax 获取最优 MRi item
# 获取大的 RMi 商品
sort_list.sort(key=lambda x: x[2], reverse=False)
max_MRi = sort_list.pop()
cur_max = (max_MRi[0], max_MRi[1])
# Max RMi 从 R 移到 S 中
max_MRi_id = _R.index(cur_max)
_R.pop(max_MRi_id)
_S.append(cur_max)根据 MRi 排序,将 MRi 最大的 item 从 R 中 pop 并 append 至 S 中,完成一次循环。将上述逻辑执行 K-1 次,完成 K 个候选商品的选择。这里通过 is_slid 和 w 参数控制是否使用滑动窗口,工业场景下推荐使用滑动窗口并根据业务场景曝光条数选择合适的 w。
3.MMR 测试
# 3.MMR
S = mmr(R, id_embedding, k)
for candidate in S:
print("Id: %s Reward: %s" % (candidate[0], candidate[1]))S Size: 2 R Size: 98 Id: 2023 Reward: 0.9803380341271558 RMi: 0.18914732654032512
S Size: 3 R Size: 97 Id: 7055 Reward: 0.9234506566901367 RMi: 0.09500372556637421
S Size: 4 R Size: 96 Id: 1307 Reward: 0.7965671493211518 RMi: 0.03062159309825946
S Size: 5 R Size: 95 Id: 4457 Reward: 0.9834577224706769 RMi: 0.09144580217525927
S Size: 6 R Size: 94 Id: 5394 Reward: 0.7642957463819996 RMi: -0.25072450194085166
S Size: 7 R Size: 93 Id: 2844 Reward: 0.7683949135991219 RMi: -0.17790320675225413
S Size: 8 R Size: 92 Id: 1430 Reward: 0.6749584037283536 RMi: -0.25759969410263295
S Size: 9 R Size: 91 Id: 8762 Reward: 0.7054624111048696 RMi: -0.26594825156168417
S Size: 10 R Size: 90 Id: 1109 Reward: 0.8096079183764663 RMi: -0.23384115011894474我们在每一轮迭代中打印了 S、R 的信息,并打印了每轮从 R 中优胜的 item 对应的 Reward 与 RMi,可以看到最终 S 中的候选集已不完全按照 reward 排序,一些 reward 相对较低但多样性好的商品也会排在前面:
Id: 3816 Reward: 0.9994031803099526
Id: 2023 Reward: 0.9803380341271558
Id: 7055 Reward: 0.9234506566901367
Id: 1307 Reward: 0.7965671493211518
Id: 4457 Reward: 0.9834577224706769
Id: 5394 Reward: 0.7642957463819996
Id: 2844 Reward: 0.7683949135991219
Id: 1430 Reward: 0.6749584037283536
Id: 8762 Reward: 0.7054624111048696
Id: 1109 Reward: 0.80960791837646634.MMR 完整代码
import numpy as np
def mmr(_R, _id_embedding, _k=10, is_slid=True, window_size=5):
# 按照 reward 排序 False 增序、True 降序
_R.sort(key=lambda x: x[1], reverse=False)
# 初始化集合 S
top = _R.pop()
_S = [top]
_RMi = []
# 构建后 K 个元素
for i in range(_k - 1):
sort_list = []
for item in _R:
# 候选 Id 与预期收益
item_id = item[0]
item_reward = item[1]
# 获取向量用于相似度计算
item_emd = np.expand_dims(_id_embedding[item_id], axis=0)
# 是否使用滑动窗口
if is_slid:
s_emd = np.transpose([_id_embedding[s[0]] for s in _S[len(_S) - window_size: len(_S)]])
else:
s_emd = np.transpose([_id_embedding[s[0]] for s in _S])
# 计算 Max Sim ij
max_sim = np.max(np.dot(item_emd, s_emd))
# 计算 MRi
MRi = theta * item_reward - (1 - theta) * max_sim
sort_list.append((item_id, item_reward, MRi))
# 获取大的 RMi 商品
sort_list.sort(key=lambda x: x[2], reverse=False)
max_MRi = sort_list.pop()
cur_max = (max_MRi[0], max_MRi[1])
# Max RMi 从 R 移到 S 中
max_MRi_id = _R.index(cur_max)
_R.pop(max_MRi_id)
_S.append(cur_max)
print(
"S Size: %s R Size: %s Id: %s Reward: %s RMi: %s" % (len(_S), len(_R), max_MRi[0], max_MRi[1], max_MRi[2]))
return _S
if __name__ == '__main__':
total = 10000
n = 100
k = 10
theta = 0.5
# 1.模拟用户排序分数,假设此时为精排,候选集 n=100
R = list(zip(np.random.randint(0, total, size=n), np.random.random(n)))
# 2.Embedding 相似度依据
id_embedding = dict(zip(list(range(0, total)), np.random.random(size=(total, 8))))
# 3.MMR
S = mmr(R, id_embedding, k)
for candidate in S:
print("Id: %s Reward: %s" % (candidate[0], candidate[1]))
一些最大元素的构造也可以使用堆代替 List,提高计算效率,元素 Embedding 可以通过预训练得到或者换成简单的规则匹配。
五.总结
MMR 发表于 1998 年,是早期多样性文章的代表作之一,算法简单有效值得大家在推荐场景使用。
参考:
MMR 多样性算法(Maximal Marginal Relevance)
The use of MMR, diversity-based reranking for reordering documents and producing summaries
更多推荐算法相关深度学习:深度学习导读专栏




![C# webapi接口传输byte[]数据,报错:415 Unsupported Media Type](https://img-blog.csdnimg.cn/3ac96157a7404d9fb43a65e18e4390e3.png)