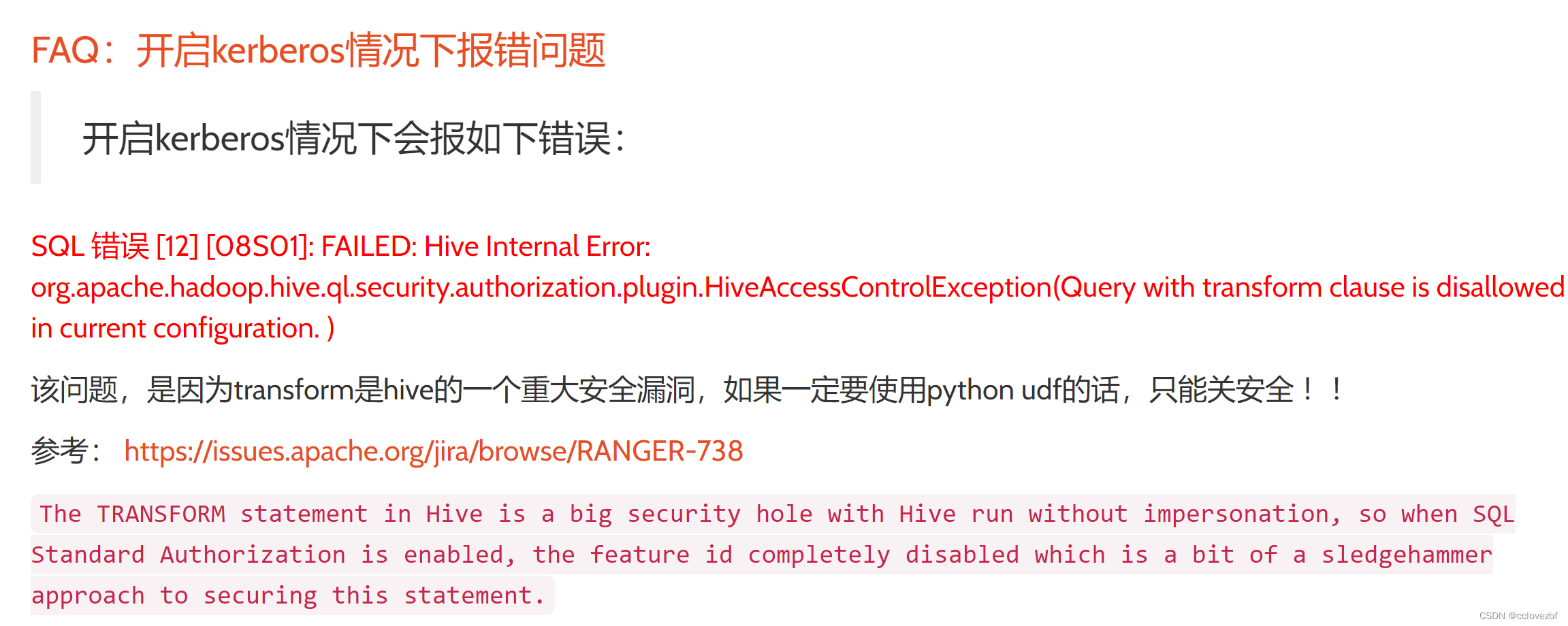
简单的总结了flink的几种source来源,可以参考下
package com.atguigu.apitest
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import scala.util.Random
/**
* 功能:演示 flink的source来源
*
*/
// 定义样例类,温度传感器
case class SensorReading(id:String, timestamp: Long,temmperature:Double )
object SourceTest {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 1 从集合中读取数据
val dataList=List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1)
)
val stream1=env.fromCollection(dataList)
//val stream1=env.fromElements(1.0,35,"hello") // 直接创建集合的方法
// 2 从文件中读取数据
val inputPath="F:\\FlinkTutorial\\src\\main\\scala\\com\\atguigu\\apitest\\Sensor.txt"
val stream2=env.readTextFile(inputPath)
// 3 从kafka中读取数据
val properties = new Properties()
properties.setProperty("bootstrap.servers", "hadoop:9092")
properties.setProperty("group.id", "consumer-group")
// 没有调试出来,可能是因为版本的问题, 以前的kafka参数是 zookeeper 现在的kafka参数是 bootstrap.servers
// Caused by: org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching topic metadata
val stream3=env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties) )
// 4. 自定义Source
val stream4 = env.addSource( new MySensorSource() )
stream3.print() // setParallelism(1)
// 执行
env.execute("source test")
}
}
class MySensorSource() extends SourceFunction[SensorReading]{
// 定义一个标识位flag, 用来表示数据源是否正常运行发出数据
var running:Boolean =true
override def cancel(): Unit = {
running=false
}
override def run(ctx: SourceFunction.SourceContext[SensorReading]): Unit = {
// 定义一个随机数发生器
val rand=new Random()
// 随机生成一组(10个)传感器的初始温度: (id,temp)
var curTemp = 1.to(10).map( i => ("sensor_" + i, rand.nextDouble() * 100) )
// 定义无限循环,不停地产生数据,除非被cancel
while (running) {
// 在上次数据基础上微调,更新温度值
curTemp=curTemp.map(
data=>(data._1,data._2+rand.nextGaussian())
)
// 获取当前时间戳,加入到数据中,调用ctx.collect发出数据
val curTime=System.currentTimeMillis()
curTemp.foreach(
data=>ctx.collect(SensorReading(data._1,curTime,data._2))
)
// 间隔 500 ms
Thread.sleep(500)
}
}
}
集合,文件以及自定义source 相对简单,重点演示kafka的对接
kafka作为生产者进行数据的输入

flink的数据产出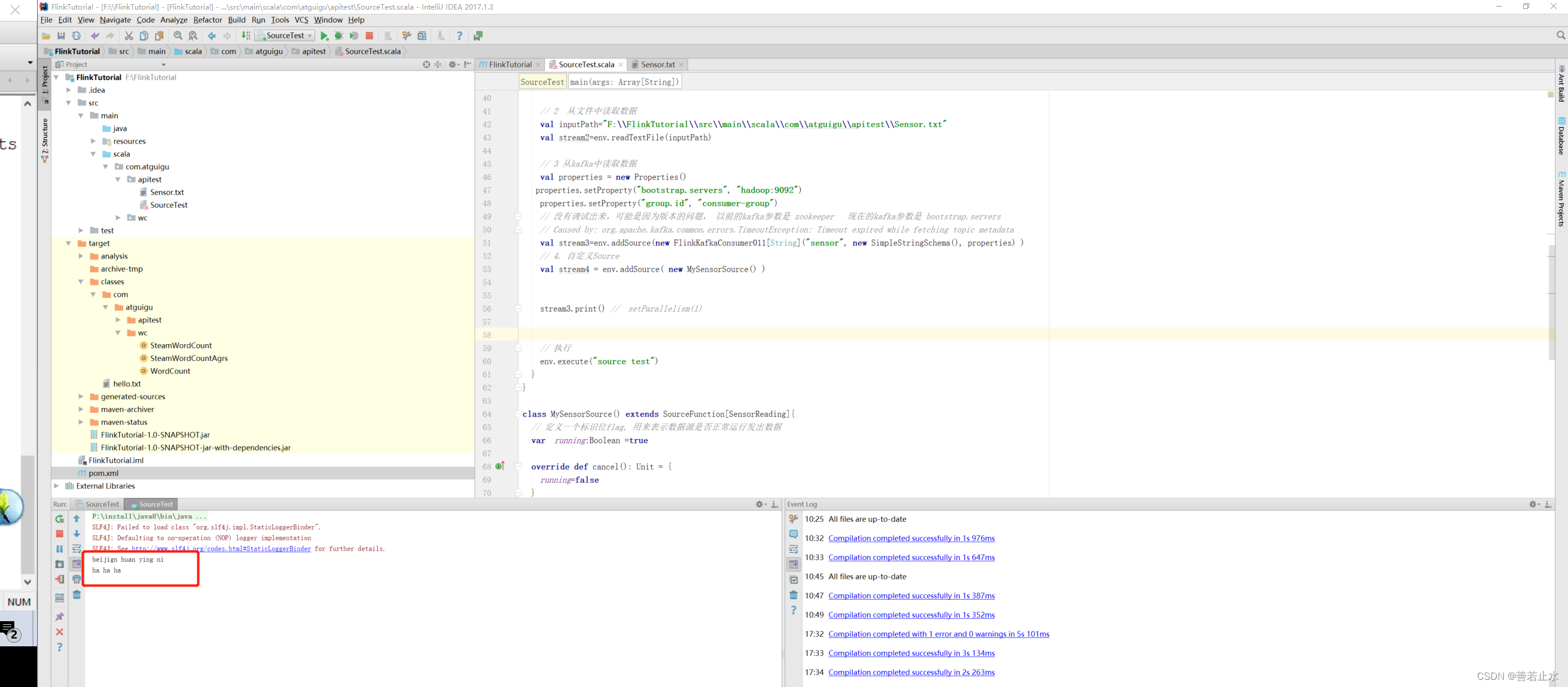
总结点:
bootstrap.servers 属于kafka版本>= v2.2时的参数
旧版的kafka版本(< v2.2) 用的参数依然是 zookeeper node1:2181
如果kafka的版本过低,比如 v0.8.2.1 时,flink会一致等待中,最后报错
Caused by: org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching topic metadata
建议kafka版本: v2.8.1
直接从官网下载即可 https://kafka.apache.org/downloads