目录
索引的优缺点
MySQL索引类型
索引原理
常见索引类型
MySQL数据库要⽤B+树存储索引⽽不⽤红⿊树、B树、 Hash的原因
怎么验证 MySQL 的索引是否满足需求
聚簇索引和非聚簇索引
索引的优缺点
索引的优点
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 空间方面:索引需要占物理空间。
MySQL索引类型
-
从索引存储结构划分:B Tree索引、Hash索引、FULLTEXT全文索引、R Tree索引
-
从应用层次划分:普通索引、唯一索引、主键索引、复合索引
-
从索引键值类型划分:主键索引、辅助索引(二级索引)
-
从数据存储和索引键值逻辑关系划分:聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
索引原理
常见索引类型
- hash B树 B+树
- 具体来说 MySQL 中的索引,不同的数据引擎实现有所不同,但目前主流的数据库引擎的索引都是 B+ 树
hash:底层就是 Hash 表。进⾏查找时,根据 key 调⽤Hash 函数获得对应的 hashcode,根据 hashcode 找到对应的数据⾏地址,根据地址拿到对应的数据。
B树:B树是⼀种多路搜索树,n 路搜索树代表每个节点最多有 n 个⼦节点。每个节点存储 key + 指向 下⼀层节点的指针+ 指向 key 数据记录的地址。查找时,从根结点向下进⾏查找,直到找到对应的 key。
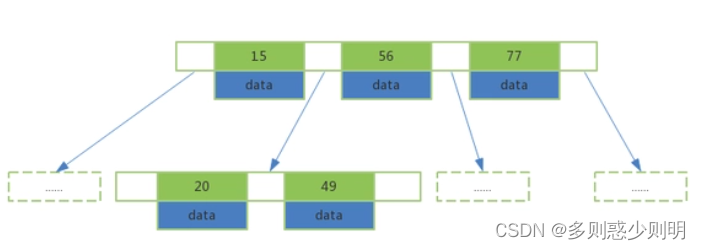
B+树:B+树是b树的变种,主要区别在于:B+树的⾮叶⼦节点只存储 key + 指向下⼀层节点的指针。 另外,B+树的叶⼦节点之间通过指针来连接,构成⼀个有序链表,因此对整棵树的遍历只需要⼀次线性遍历叶⼦结点即可。

相比B树,B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子节点的指针进行遍历即可。而B树需要遍历范围内所有的节点和数据,显然B+Tree效率高。
MySQL数据库要⽤B+树存储索引⽽不⽤红⿊树、B树、 Hash的原因
- 红⿊树:如果在内存中,红⿊树的查找效率⽐B树更⾼,但是涉及到磁盘操作,B树就更优了。因为红⿊树是⼆叉树,数据量⼤时树的层数很⾼,从树的根结点向下寻找的过程,每读1个节点,都相当于⼀次IO操作,因此红⿊树的I/O操作会⽐B树多的多。
-
hash 索引:如果只查询单个值的话,hash 索引的效率⾮常⾼。但是 hash 索引有⼏个问题:
1)不⽀持范围查询;2)不⽀持索引值的排序操作;3)不⽀持联合索引的最左匹配规则。
-
B树索引:B树索相⽐于B+树,在进⾏范围查询时,需要做局部的中序遍历,可能要跨层访问,跨层访问代表着要进⾏额外的磁盘I/O操作;另外,B树的⾮叶⼦节点存放了数据记录的地址,会导致存放的节点更少,树的层数变⾼。
怎么验证 MySQL 的索引是否满足需求
使用 explain 查看 SQL 是如何执行查询语句的,从而分析你的索引是否满足需求。
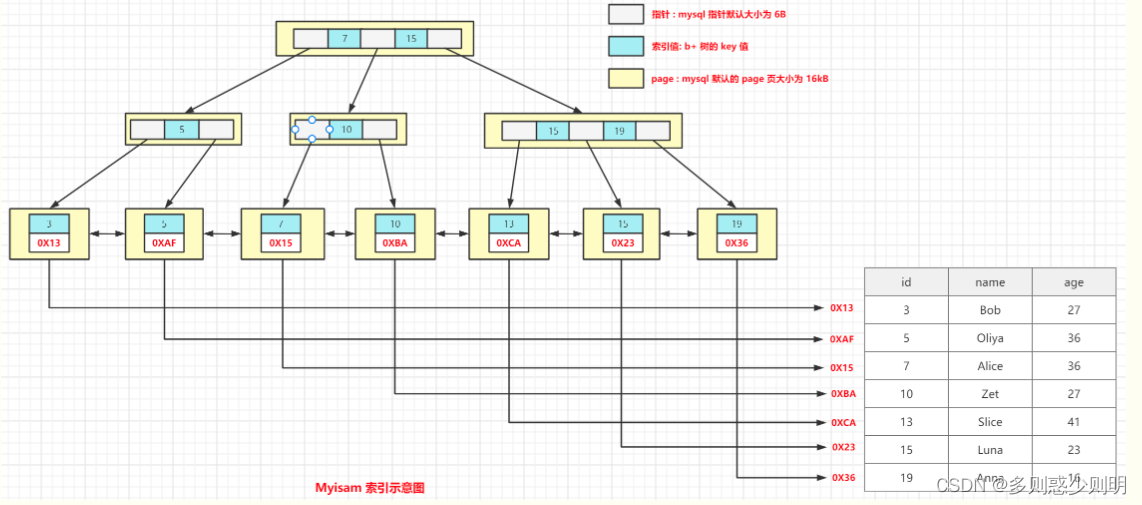
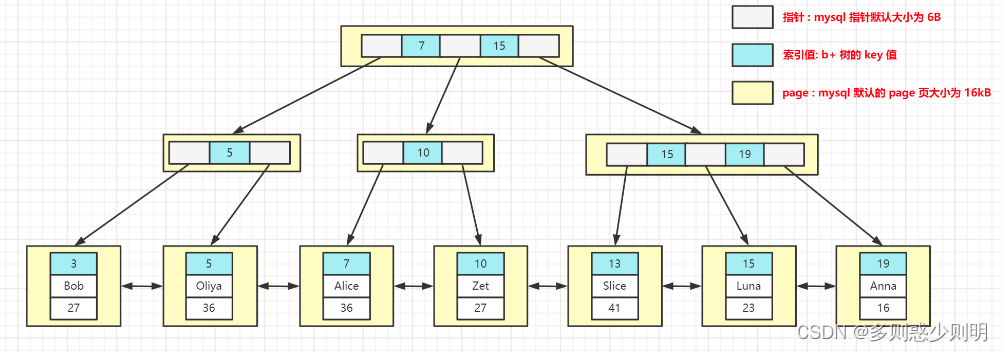
聚簇索引和非聚簇索引
数据库中B+树索引分为聚集索引(clustered index)和非聚集索引(secondary index).
- 这两种索引的共同点是内部都是B+树,高度都是平衡的,叶节点存放着所有数据。不
- 同点是叶节点是否存放着一整行数据。
参考:聚集索引与非聚集索引_聚集索引和非聚集索引_车友车行·的博客-CSDN博客
- B+Tree的叶子节点存放主键索引值和行记录(完整的表数据)就属于聚簇索引;
叶子节点存储的是 索引列字段 + 完整的行记录数据,通过聚集索引能直接获取到整行数据
Innodb 的主键索引就是基于聚集索引实现的,叶节点的数据就是我们要找的数据。
- 如果索引值和行记录分开存放就属于非聚簇索引。
- 通俗点讲
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
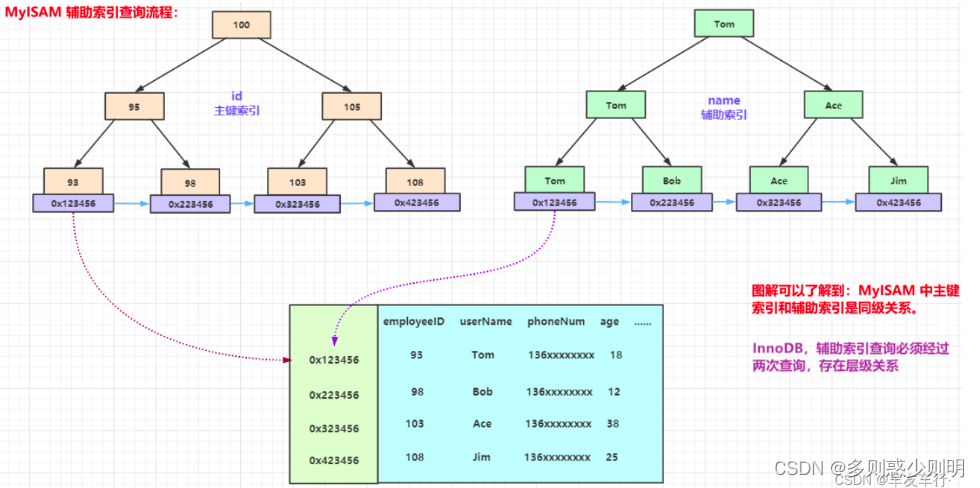
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据
InnoDB的聚簇索引就是按照主键顺序构建 B+Tree结构。B+Tree的叶子节点就是行记录,行记录和主键值紧凑地存储在一起。 这也意味着 InnoDB 的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。通常说的主键索引就是聚集索引。 InnoDB的表要求必须要有聚簇索引(每个表只能有一个聚集索引/一个主键,因为目录只能按照一种方法进行排序 ):
-
如果表定义了主键,则主键索引就是聚簇索引
-
如果表没有定义主键,则第一个非空unique列作为聚簇索引
-
否则InnoDB会从建一个隐藏的row-id作为聚簇索引
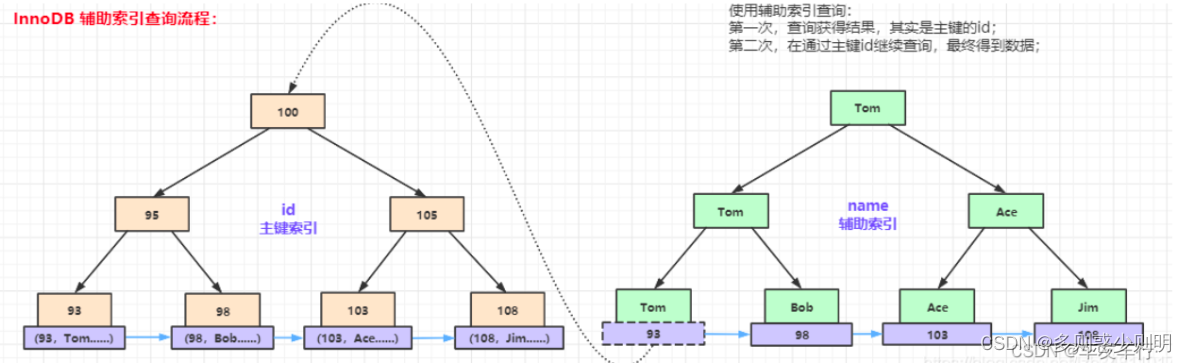
与InnoDB表存储不同,MyISAM数据表的索引文件和数据文件是分开的,被称为非聚簇索引结构。
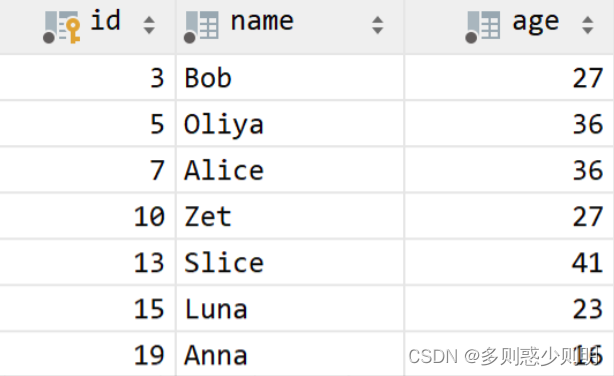
例子:表结构
基于这张表的主键 id 建立的聚集索引:
Myisam 以 id 为主键建立的非聚集索引: