学习目标/Target
掌握广告点击流实时统计实现思路
掌握利用Kafka生产用户广告点击流数据
了解数据库设计
掌握如何创建Spark Streaming连接
掌握利用Spark Streaming读取业务数据
掌握利用Spark读取黑名单用户
掌握利用Spark Streaming过滤黑名单用户
掌握利用Spark Streaming统计每个城市不同广告的点击次数
掌握利用Spark Streaming添加黑名单用户
掌握将数据持久化到HBase数据库
熟悉如何利用HBase Shell命令向HBase数据库的表中添加数据
概述
电商网站通常会存在一些广告位,当用户浏览网站时投放的广告内容会在对应广告位显示。此时,有些用户可能会点击广告跳转到对应界面去查看详情,从而提升用户在网站的浏览深度和购买概率,针对这种用户广告点击行为的实时数据进行实时计算和统计,可以帮助公司实时地掌握各种广告的投放效果,以便于后续能够及时地对广告投放相关的策略进行调整和优化,以期望通过广告的投放获取更高的收益。
目录
学习目标/Target
概述
1.数据集分析
2.实现思路分析
3.数据库设计
4. 实现广告点击流实时统计
5.运行程序
1.数据集分析
本需求采用Java程序模拟生成用户广告点击数据,通过Kafka的生产者发布用户广告点击数据形成实时数据流,数据流中的每一条数据代表一个用户点击广告的行为,当Kafka生产者程序运行时会产出源源不断的用户广告点击流数据。
1596006895171,16,6,tianjin
单条用户广告点击数据包含四个字段内容,依次分别是时间戳(time)、用户ID(userid)、广告ID(adid)和城市(city)。
2.实现思路分析
通过Kafka实时生产用户广告点击流数据,SparkStreaming作为消费者实时读取Kafka生产的数据,与HBase数据库中黑名单用户表的数据进行合并,并过滤包含黑名单用户的数据。对过滤后的数据进行两次聚合操作,第一次聚合统计每个广告在不用城市的点击次数。第二次聚合统计用户出现的次数,用于将广告点击次数超过100的用户添加到黑名单用户中。

读取:读取Kafka实时生产用户广告点击流数据。
转换:将数据格式转换为以userid为Key,adid和city作为一个整体为Value的数据形式。
合并/过滤:将转换后的数据与读取的黑名单用户数据进行合并,并过滤包含黑名单用户的数据。
转换/聚合:将数据格式转换为以adid和city作为一个整体为Key,数值1作为Value的数据形式。
转换/聚合:将数据格式转换为以userid作为Key,值1作为Value的数据形式,然后进行聚合操作统计每个用户出现的次数。
读取:读取HBase数据库中黑名单用户
添加:将用户出现次数超过100的用户添加到HBase数据库中的黑名单用户中。
3.数据库设计
读取HBase数据库中黑名单用户 将转换后的数据与读取的黑名单用户数据进行合并。

数据表adstream:存储用户广告点击流实时统计结果。
数据表blacklist:存储黑名单用户。
STEP 01
打开HBase命令行工具:
打开虚拟机启动大数据集群环境(此时可以不启动使用远程连接工具SecureCRT连接虚拟机Spark01,执行“hbase shell”命令进入HBase的命令行工具。
STEP 02
创建表blacklist:
通过HBase的命令行工具创建表blacklist并指定列族为black_user,用于存储黑名单用户数据。
create 'blacklist','black_user'
STEP 03
插入黑名单用户:
通过HBase的命令行工具在表blacklist的列族black_user下插入黑名单用户,指定uerid为33、44和55的用户为黑名单用户。
STEP 04
创建表adstream:
通过HBase的命令行工具创建表adstream并指定列族为area_ads_count,用于存储用户广告点击流实时统计结果。
create 'adstream','area_ads_count'
4. 实现广告点击流实时统计
4.1 修改pom.xml文件
 在项目SparkProject的pom.xml文件中添加Spark Streaming、Hadoop和Spark Streaming整合Kafka依赖。
在项目SparkProject的pom.xml文件中添加Spark Streaming、Hadoop和Spark Streaming整合Kafka依赖。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.2</version>
</dependency>
4.2 生产用户广告点击流数据
STEP 01
实现Kafka生产者:
在项目SparkProject的java目录新建Package包“cn.itcast.streaming”,用于存放广告点击流实时统计的Java文件,并在该包中创建Java类文件MockRealTime,用于实现Kafka生产者,生产用户广告点击流数据。
STEP 02
启动Kafka消费者:
打开虚拟机启动大数据集群环境(包括Kafka),使用远程连接工具SecureCRT连接虚拟机Spark01,进入Kafka安装目录(/export/servers/kafka_2.11-2.0.0)启动Kafka消费者。
bin/kafka-console-consumer.sh \
--bootstrap-server spark01:9092,spark02:9092,spark03:9092 \
--topic ad
STEP 03
启动Kafka生产者:
在项目SparkProject的包“cn.itcast.streaming”中选中文件MockRealTime.java并单击右键,在弹出的菜单栏选择“Run. MockRealTime.main()”运行Kafka生产者程序,生产用户广告点击流数据。
STEP 04
查看Kafka消费者:
在虚拟机Spark01的Kafka消费者窗口查看数据是否被成功接收。
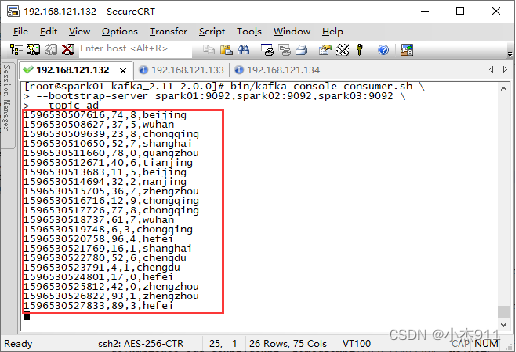
STEP 05
关闭Kafka消费者:
在虚拟机Spark01的Kafka消费者窗口通过组合键“Ctrl+C”关闭当前消费者。
STEP 06
关闭Kafka生产者:
在IntelliJ IDEA控制台中单击红色方框的按钮关闭Kafka生产者程序,关闭Kafka生产者程序。

4.3 创建Spark Streaming连接
在项目SparkProject的包“cn.itcast.streaming”中创建Java类文件AdsRealTime.java,用于实现广告点击流实时统计。
public class AdsRealTime {
public static void main(String[] arg) throws IOException,
InterruptedException {
//实现Spark Streaming程序
}
}
在类AdsRealTime的main()方法中,创建JavaStreamingContext对象和SparkConf对象,JavaStreamingContext对象用于实现Spark Streaming程序,SparkConf对象用于配置Spark Streaming程序各种参数。
System.setProperty("HADOOP_USER_NAME","root");
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("stream_ad"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); jsc.checkpoint("hdfs://192.168.121.133:9000/checkpoint");
4.4 读取用户广告点击流数据
在类AdsRealTime的main()方法中,指定Kafka消费者的相关配置信息。
final Collection<String> topics = Arrays.asList("ad"); Map<String, Object> kafkaParams = new HashMap<>(); kafkaParams.put("bootstrap.servers","spark01:9092,spark02:9092,spark03:9092"); kafkaParams.put("key.deserializer", StringDeserializer.class); kafkaParams.put("value.deserializer", StringDeserializer.class); kafkaParams.put("group.id", "adstream"); kafkaParams.put("auto.offset.reset", "latest"); kafkaParams.put("enable.auto.commit", true);
在类AdsRealTime的main()方法中,使用类KafkaUtils的createDirectStream()方法从Kafka生产者读取用户广告点击流数据,并加载到userAdStream。
JavaInputDStream<ConsumerRecord<String, String>> userAdStream = KafkaUtils.createDirectStream(
jsc,LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
);
4.5 获取业务数据
在类AdsRealTime的main()方法中,使用mapToPair()算子转换userAdStream中每一行数据生,获取用户广告点击流数据中的userid(用户ID)、adid(广告ID)和city(城市),将转化结果加载到userClickAdsStream。
JavaPairDStream<String,Tuple2<String,String>> userClickAdsStream = userAdStream.mapToPair((PairFunction<ConsumerRecord<String, String>, String,Tuple2<String, String>>) record -> {
String[] value = record.value().split(",");
String userid =value[1];
String adid =value[2];
String city =value[3];
return new Tuple2<>(userid,new Tuple2<>(adid,city));
});
4.6 读取黑名单用户数据
在类AdsRealTime的main()方法中,使用mapToPair()算子转换userAdStream中每一行数据生,获取用户广告点击流数据中的userid(用户ID)、adid(广告ID)和city(城市),将转化结果加载到userClickAdsStream。
JavaPairDStream<String,Tuple2<String,String>> userClickAdsStream = userAdStream.mapToPair((PairFunction<ConsumerRecord<String, String>, String,Tuple2<String, String>>) record -> {
String[] value = record.value().split(",");
String userid =value[1];
String adid =value[2];
String city =value[3];
return new Tuple2<>(userid,new Tuple2<>(adid,city));
});
在HBase数据库操作工具类HbaseUtils中添加方法scan(),用于获取HBase数据库中指定表的全部数据。
public static ResultScanner scan(String tableName)
throws IOException {
Table table = HbaseConnect.getConnection().getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
return table.getScanner(scan);
}
在类AdsRealTime中添加方法getBlackUser(),用于获取HBase数据库中黑名单用户表的数据。
public static ArrayList getBlackUser() throws IOException {
ResultScanner blcakResult = HbaseUtils.scan("blacklist");
Iterator<Result> blackIterator = blcakResult.iterator();
ArrayList<Tuple2<String,String>> blackList = new ArrayList<>();
while (blackIterator.hasNext()){
String blackUserId = new String(blackIterator.next().value());
blackList.add(new Tuple2<>(blackUserId,"black"));
}
return blackList;
}
在类AdsRealTime的main()方法中,使用parallelizePairs()算子将存放黑名单用户的集合转换JavaPairRDD,将转换结果加载到blackUserRDD。
JavaPairRDD<String,String> blackUserRDD = jsc.sparkContext().parallelizePairs(getBlackUser());
4.7 过滤黑名单用户
在类AdsRealTime的main()方法中,使用transformToPair()算子转换userClickAdsStream的每一行数据,在转换的过程中过滤黑名单用户,将转换结果加载到checkUserClickAdsStream。
JavaPairDStream<String,Tuple2<String,String>> checkUserClickAdsStream = userClickAdsStream.transformToPair( ……
);
在类AdsRealTime的main()方法中,使用mapToPair()算子转换checkUserClickAdsStream的每一行数据,将用户ID的值替换为1,通过areaAdsStream加载转换结果。
JavaPairDStream<Tuple2<String,String>, Integer> areaAdsStream
= checkUserClickAdsStream.mapToPair(
(PairFunction<
Tuple2<String, Tuple2<String, String>>,
Tuple2<String, String>,
Integer>) checkUserClickAdsTuple2 -> {
String adid = checkUserClickAdsTuple2._2._1;
String city = checkUserClickAdsTuple2._2._2;
return new Tuple2<>(new Tuple2<>(city,adid),new Integer(1));
});
在类AdsRealTime的main()方法中,使用updateStateByKey()算子维护areaAdsStream的状态,用于统计每个城市不同广告的点击次数,将统计结果加载到countAreaAdsStream。
JavaPairDStream<Tuple2<String,String>, Integer> countAreaAdsStream
= areaAdsStream.updateStateByKey( (Function2<List<Integer>,Optional<Integer>, Optional<Integer>>)
(valueList, oldState) -> {
Integer newState = 0;
if (oldState.isPresent()){
newState = oldState.get();
}
for (Integer value : valueList){
newState += value;
}
return Optional.of(newState);
});
在类AdsRealTime的main()方法中,使用mapToPair()算子转换checkUserClickAdsStream的每一行数据,便于后续聚合统计每个用户点击广告的次数,将转换结果加载到userStream。
JavaPairDStream<String,Integer> userStream = checkUserClickAdsStream
.mapToPair(
(PairFunction<Tuple2<String, Tuple2<String, String>>,
String, Integer>) checkUserClickAdsTuple2 ->
new Tuple2<>(
checkUserClickAdsTuple2._1,
new Integer(1)));
在类AdsRealTime的main()方法中,使用updateStateByKey()算子维护userStream的状态,用于统计每个用户点击广告的次数,将统计结果加载到countUserStream。
JavaPairDStream<String, Integer> countUserStream =userStream.updateStateByKey((Function2<List<Integer>,Optional<Integer>,Optional<Integer>>)
(valueList, oldState) -> {
Integer newState = 0;
if (oldState.isPresent()){
newState = oldState.get();
}
for (Integer value : valueList){
newState += value;
}
return Optional.of(newState);
});
4.9 添加黑名单用户
在类AdsRealTime的main()方法中,使用foreachRDD()算子遍历countUserStream中的RDD,将广告点击次数超过100的用户添加到HBase数据库的黑名单表blacklist中。
countUserStream.foreachRDD((VoidFunction<JavaPairRDD<String, Integer>>) countUserRDD -> countUserRDD.foreach((VoidFunction<Tuple2<String, Integer>>) countUserTuple2 -> {
if (countUserTuple2._2>100){
HbaseUtils.putsOneToHBase(
"blacklist",
"user"+countUserTuple2._1,
"black_user",
"userid",
countUserTuple2._1);
}
}));
4.10 持久化数据
在类AdsRealTime的main()方法中,使用foreachRDD()算子遍历countAreaAdsStream,将每个城市中不同广告的点击次数持久化到HBase数据库的adstream表。
countAreaAdsStream.foreachRDD((
VoidFunction<JavaPairRDD<Tuple2<String, String>,Integer>>
) countAreaAdsRDD ->countAreaAdsRDD.foreach((VoidFunction< Tuple2<Tuple2<String, String>, Integer>>)
countAreaAdsTuple2 -> {
String adid = countAreaAdsTuple2._1._2;
String city = countAreaAdsTuple2._1._1;
int count = countAreaAdsTuple2._2; HbaseUtils.putsOneToHBase("adstream",city+"_"+adid,"area_ads_count","area",city); HbaseUtils.putsOneToHBase("adstream",city+"_"+adid,"area_ads_count","ad",adid); HbaseUtils.putsOneToHBase("adstream",city+"_"+adid,"area_ads_count","count",String.valueOf(count)); }));
在类AdsRealTime的main()方法中,添加启动与关闭Spark Streaming连接等方法。
jsc.start();
jsc.awaitTermination();
HbaseConnect.closeConnection();
jsc.close();
5.运行程序





![]()
Kafka生产者程序和用户广告点击流实时统计程序启动成功后,可在IDEA的控制台查看程序运行状态。

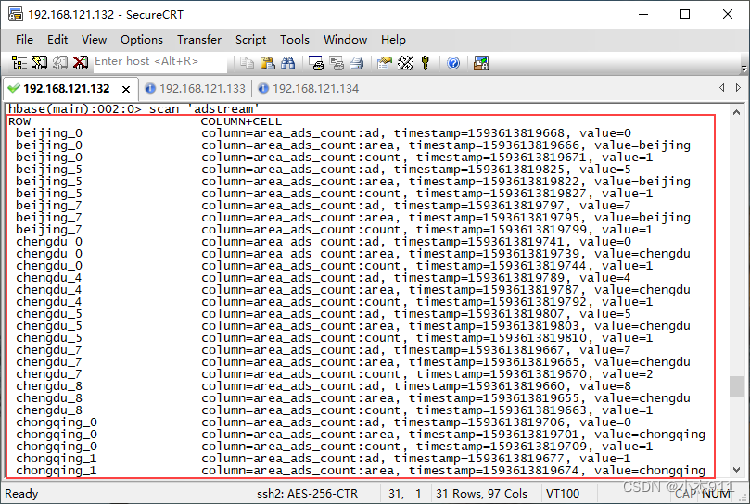
使用远程连接工具SecureCRT连接虚拟机Spark01,执行“hbase shell”命令,进入HBase命令行工具,在HBase命令行工具中执行“scan 'adstream'”命令,查看HBase数据库中表adstream的统计结果。
小结
本文主要讲解了如何通过用户广告点击流数据实现广告点击流实时统计,首先我们对数据集进行分析,使读者了解广告点击流的数据结构。接着通过实现思路分析,使读者了解广告点击流实时统计的实现流程。然后通过IntelliJ IDEA开发工具实现广告点击流实时统计程序并将统计结果实时存储到HBase数据库,使读者掌握运用Java语言编写Spark Streaming、HBase和Kafka生产者程序的能力。最后在IntelliJ IDEA开发工具运行用户广告点击流实时统计程序,使读者了解IntelliJ IDEA开发工具运行程序的方法。
点赞一建三连!