点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【Transformer】微信交流群
【CVPR 2023】LinK:用线性核实现3D激光雷达感知任务中的large kernel
本文介绍我们媒体计算研究组(MCG)在3D激光雷达感知领域提出的新型网络设计。针对点云数据的稀疏性,使用线性核(LinK)来扩大模型的有效感受野,提升3D检测、分割等任务的性能。

LinK: Linear Kernel for LiDAR-based 3D Perception
论文链接:https://arxiv.org/abs/2303.16094
代码链接:https://github.com/MCG-NJU/LinK
研究动机
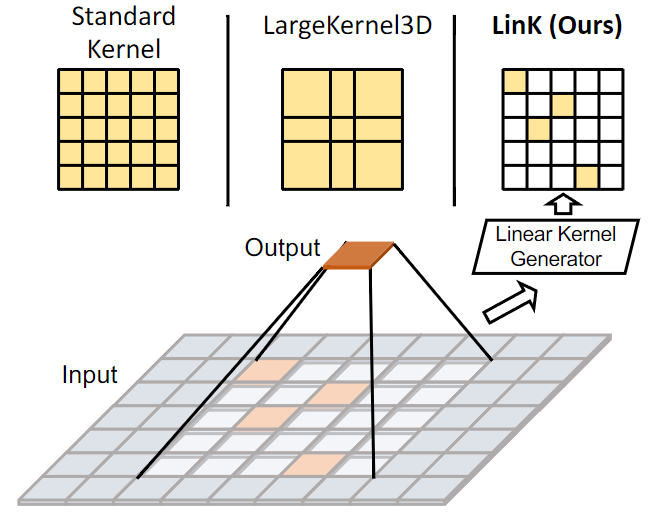
在2D计算机视觉任务中,更大的感受野使得模型在语义分割、目标检测等下游任务上的性能获得显著的提升。此前,一些方法(RepLKNet[1]等)探究了2D图像处理领域中使用更大的卷积核来获得更大范围的感知能力。
由于3D数据模态的稀疏性,将大卷积核的设计引入3D存在两方面的障碍。一是效率问题:3D任务中,开销随尺寸立方增长,若将卷积核大小从3×3×3简单地扩张到7×7×7,模型大小会是原来的10倍,扩展到21×21×21则会变为343倍。另一方面是优化问题:由于点云在空间中分布较为稀疏,如果卷积核的每个位置都被赋予一定的权重,那么3D数据的稀疏性会导致大量空闲位置的权重在网络迭代中并没有参与更新,导致参数更新缓慢。此前有人尝试使用局部块内元素共享参数的方式来缓解这两个问题,提出了大小为7×7×7的空间共享权重卷积核(LargeKernel3D[2])。该设计成功地在3D语义分割和目标检测任务上提升了小卷积核的性能,但感受野的扩张幅度仍然有限。
为了解决这些问题,我们提出线性核LinK,以类卷积的方式实现更大的感知范围。该方法有两处核心设计:一是用线性核生成器替换静态的卷积权重,仅为非空区域的点云提供权重。同时,该模块是逐层共享的,避免了稀疏分布的权重在某次迭代中没有被优化的情况,改善了优化问题。二是在不同滑动窗口的重叠区域复用预先计算的聚合结果,使整体计算复杂度进一步降低,甚至最终计算量为常量,与实际感受范围无关。换句话说,我们可以基于LinK以一致的开销实现任意大小的线性核。
我们的方法
核生成器
前文中讨论了大卷积核下稀疏卷积的两大缺陷:开销大以及优化困难。我们首先采用神经网络模块 来在线生成权重,取代静态卷积核 ,使得网络参数量与不随卷积核尺寸增长而增长,与之前方法对比如下:
线性核生成器解决了参数量增长的问题,然后,并没有解决计算量的问题。于是我们考虑,能否将不同卷积窗口的重叠区域的特征聚合结果进行复用,这样有可能降低计算量。
为此,我们以一个toy case为例。假设两个相邻窗口中的元素集合分别为
其中每个元素表示一个体素。这两个窗口的重叠区域为
我们分别将 中的元素特征聚合到 和 ,聚合过程为
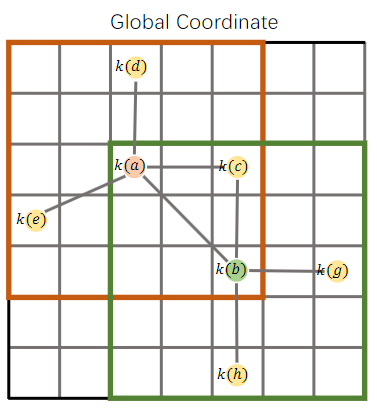
可以发现,每个重叠区域中的元素对 和 采用不同的local offset来获得权重。因此,基于local offset的方式难以复用重叠区域的聚合结果,如下图所示:

基于global coordinate的预聚合
为了解决这个问题,考虑到每个位置的global coordinate是唯一的,我们提出,将local offset拆分为global coordinate的组合。对于区域 ,我们使用如下公式计算这三个元素的预聚合结果:
也是kernel generator。然后,若要得到 在区域 上的聚合特征,我们用如下方式生成基于local offset的结果:
这样,不管有多少个元素要来复用区域 上的聚合特征,都不需要再重新计算 。
那么问题来了,上式成立的前提是
为了使其成立,我们参考APP-Net[3],使用线性映射 来实现 和 。我们将这过程称为线性核生成器,也即LinK方法名字的由来(Linear Kernel Generator)。这两个函数可以用三角函数、指数函数等不同的形式进行激活,正文中主要采用了余弦函数的方式。此时两个窗口A、B的聚合过程如下图所示:
基于LinK的类卷积核设计
基于上述设计,我们将整体点云划分为不重叠的块,每个块的大小为 ,对每个块进行特征预聚合。为每个块查询其周围 个近邻块,生成一个感受范围为 的大块的预聚合特征 。对 使用上述合成local offset的操作,即可为每个聚合中心算得最终的特征。这部分的具体公式可见论文原文。在实验中,设 ,即可得到 21×21×21 的感知范围。整体过程如下图所示:

网络结构
LinK模块结构
LinK模块由两个分支组成:一个分支为使用线性投影+三角核函数实现的大核分支,另一分支为 3×3×3 的稀疏卷积小核旁路,结构图如下所示。

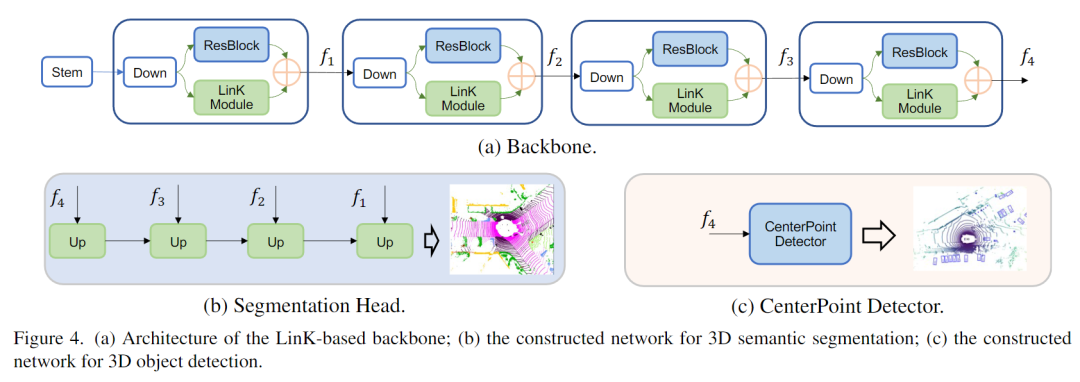
下游任务应用
应用到下游任务(检测和分割)中时,我们分别选取CenterPoint和MinkUnet作为基础架构,并使用基于LinK的backbone替代了原本基于稀疏卷积实现的backbone,保留了原始的检测头和分割头不变,具体结构如下图所示。
实验
我们在nuScenes上评估了目标检测的结果,在SemanticKITTI上评估了语义分割的结果。结果分别如下所示:
nuScenes

截止论文发表,我们的方法在nuScenes数据集上取得了SOTA(73.4 NDS)。得益于超大的感受野,与baseline CenterPoint相比,我们的方法在大尺寸的物体(例如bus、con-veh等)上提升显著。
SemanticKITTI

在SemanticKITTI上,我们的方法相较baseline MinkUNet获得了2.7 mIoU的提升。更多可视化分析见原始论文。
总结
在本文中,我们提出了一个线性核生成器LinK,能够以不变的计算量任意扩大模型感受野,大幅提升现有模型在下游任务(检测、分割)上的性能。我们通过实验证明了LinK对下游任务性能提升的有效性与通用性。LinK在nuScenes(LiDAR only)上达到了SOTA性能,希望可以让大家对大感受野的新方法以及其在3D感知任务上的应用有更多关注。
引用
[1] Ding, Xiaohan, et al. "Scaling up your kernels to 31x31: Revisiting large kernel design in cnns."Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[2] Chen, Yukang, et al. "Scaling up kernels in 3d cnns."arXiv preprint arXiv:2206.10555(2022).
[3] Lu, Tao, et al. "APP-Net: Auxiliary-point-based Push and Pull Operations for Efficient Point Cloud Classification."arXiv preprint arXiv:2205.00847(2022).
点击进入—>【Transformer】微信交流群
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-扩散模型或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()