背景
在做研究的时候,通常我们希望同样的样本,同样的代码能够得到同样的实验效果,但由于代码中存在一些随机性,导致虽然是同样的样本和程序,但是得到的结果不一致。在pytorch的官方文档中为此提供了一些建议,原文档:REPRODUCIBILITY。下面我们来看看看具体的内容。
程序包的随机性
pytorch中的随机性
pytorch在一些操作具有随机性,如:torch.svd_lowrank(),我们可以使用torch.manual_seed()设置随机数种子来使得所有的设备(CPU和GPU)的随机性一致(本质来说现有的随机函数都是伪随机,都是通过随机数种子确定)。如:
import torch
torch.manual_seed(0)
python中的随机性
当然有时候我们的程序中可能还会使用python内建函数random,在程序中设置对应的随机数种子也是需要做的。即:
import random
random.seed(0)
python常用的第三方包-numpy
在数据处理中我们可能也会使用numpy,numpy中也存在响应的随机函数,使用方法如下:
import numpy as np
np.random.seed(0)
需要补充的是,可能在实际的编程中还会使用其他的具有随机操作的包,我们需要根据对应的包设置响应的随机数种子,以确保随机数种子的固定。源头就是设置随机数生成器(random number generator,rng)的随机数种子.
cuda的卷积操作
CUDA卷积操作所使用的cuDNN库,可能是一个应用程序多次执行的非确定性的来源。当用一组新的尺寸参数调用cuDNN卷积时,一个可选的功能可以运行多种卷积算法,对它们进行基准测试以找到最快的算法。然后,在剩下的过程中,最快的算法将被持续用于相应的尺寸参数集。由于基准测试的噪音和不同的硬件,该基准在随后的运行中可能会选择不同的算法,即使是在同一台机器上。
用 torch.backends.cudnn.benchmark = False 禁用基准测试功能会导致 cuDNN 确定性地选择一种算法,可能以降低性能为代价。
避免非决定性的算法
cuda卷积基准
torch.use_deterministic_algorithms()可以让您将PyTorch配置为使用确定性的算法,而不是使用非确定性的算法,如果已知某个操作是非确定性的(并且没有确定性的替代方法),则会抛出一个错误。这一点我们需要查看 torch.use_deterministic_algorithms()文档了解受影响操作的完整列表。
此外,如果你使用CUDA张量,并且你的CUDA版本是10.2或更高,你应该根据CUDA文档设置环境变量CUBLAS_WORKSPACE_CONFIG:https://docs.nvidia.com/cuda/cublas/index.html#cublasApi_reproducibility
.我们可以使用如下代码进行设置:
torch.backends.cudnn.deterministic = True
# 或
torch.use_deterministic_algorithms(True)
两者的区别是:后者可以使pytorch操作变为确定性,而前者只是控制函数的行为,例如CUDA convolution benchmarking,后者将其处理成确定性的算法,而前者只是让其每次选择同样的基准算法,而选择基准算法的算法依然是一个非确定行的算法。
cuda中的rnn和lstm
在CUDA的某些版本中,RNN和LSTM网络可能有非确定性的行为。例如在torch.nn.RNN的文档中介绍:
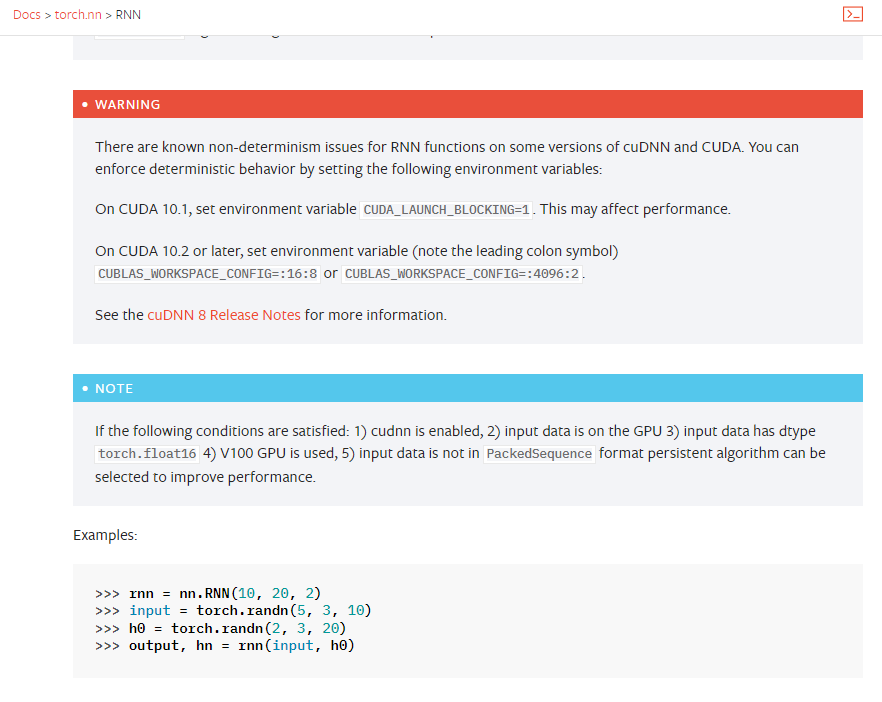
具体的处理方法上面也进行了介绍。
数据加载的随机性
DataLoader中有设置多线程处理数据的参数,由于多进程处理数据也会有先后完成的随机性可能会导致模型训练使用的batch语料不同影响着最终的模型结果,我们可以使用worker_init_fn()和生成器来保持可重复性。例如:
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
numpy.random.seed(worker_seed)
random.seed(worker_seed)
g = torch.Generator()
g.manual_seed(0)
DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
worker_init_fn=seed_worker,
generator=g,
)
如果不想麻烦,在训练语料较少的时候可以考虑使用一个线程去处理数据也是可行的。
其他
当然网上也有博主设置hash操作的环境变量,固定hash的随机性。
os.environ['PYTHONHASHSEED'] = str(seed)
总结
总得来说,在pytorch中存在着一些随机性的操作这个隐藏的比较深,当然官方文档也进行了介绍,根据实际情况进行调整应该可以确保pytorch中的代码能够确定下来,其他的就可能是cuda的情况、数据加载以及使用的第三方包导致的随机性,需要根据情况意义排查了。