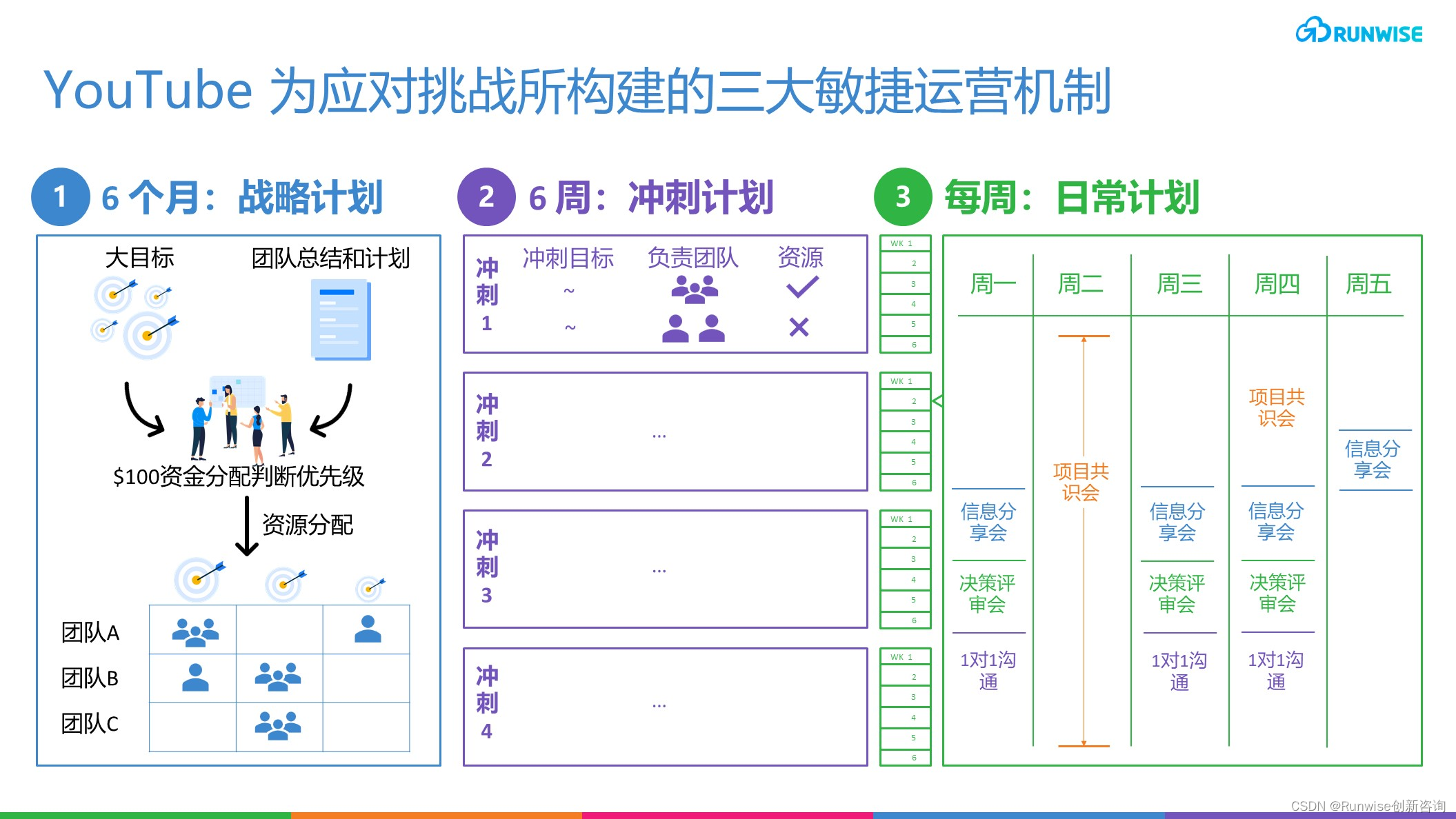
哨兵模式
哨兵模式即在主从复制的基础上增加哨兵监控以控制主从切换实现高可用的一种模式。
本篇主要介绍sentinel系统初始化,心跳检测,故障转移的过程
初始化
从最开始的 redis-server xxx.conf --sentinel 、 redis-sentinel xxx.conf 命令看起。当一个服务以 --sentinel 模式启动时,main函数,会有一些特殊的if代码与之匹配。
int main(int argc, char **argv) {
//...
server.sentinel_mode = checkForSentinelMode(argc,argv); //检查是否哨兵模式
//...
if (server.sentinel_mode) {
initSentinelConfig(); //修改端口号为26379
initSentinel(); //创建并初始化sentinel内存
}
//...
if (!server.sentinel_mode) {
//...
} else {
InitServerLast(); //初始化io线程(这个与哨兵没多大关系,就算不是哨兵模式也会运行InitServerLast方法)
sentinelIsRunning(); //启动哨兵实例
}
}
checkForSentinelMode 比较简单,只是检查是否以sentinel命令启动。如果是则标记 server.sentinel_mode 为true
int checkForSentinelMode(int argc, char **argv) {
int j;
if (strstr(argv[0],"redis-sentinel") != NULL) return 1;
for (j = 1; j < argc; j++)
if (!strcmp(argv[j],"--sentinel")) return 1;
return 0;
}
initSentinelConfig 也只是修改了端口号和把protected_mode置为0而已
void initSentinelConfig(void) {
server.port = REDIS_SENTINEL_PORT; //26379
server.protected_mode = 0; //允许外部链接哨兵实例
}
initSentinel 创建并初始化一块sentinel内存,用于存放哨兵模式运行时数据(比如:集群中的master节点)
void initSentinel(void) {
unsigned int j;
//用哨兵实例专用的命令替换常规的命令
dictEmpty(server.commands,NULL);
for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) {
int retval;
struct redisCommand *cmd = sentinelcmds+j;
retval = dictAdd(server.commands, sdsnew(cmd->name), cmd);
serverAssert(retval == DICT_OK);
}
//初始化数据项
sentinel.current_epoch = 0;
sentinel.masters = dictCreate(&instancesDictType,NULL);
sentinel.tilt = 0;
sentinel.tilt_start_time = 0;
sentinel.previous_time = mstime();
sentinel.running_scripts = 0;
sentinel.scripts_queue = listCreate();
sentinel.announce_ip = NULL;
sentinel.announce_port = 0;
sentinel.simfailure_flags = SENTINEL_SIMFAILURE_NONE;
sentinel.deny_scripts_reconfig = SENTINEL_DEFAULT_DENY_SCRIPTS_RECONFIG;
memset(sentinel.myid,0,sizeof(sentinel.myid));
}
sentinelIsRunning 启动哨兵实例
void sentinelIsRunning(void) {
int j;
//...一些判断
//检查myid是否为0
for (j = 0; j < CONFIG_RUN_ID_SIZE; j++)
if (sentinel.myid[j] != 0) break;
if (j == CONFIG_RUN_ID_SIZE) {
//随机生成ID
getRandomHexChars(sentinel.myid,CONFIG_RUN_ID_SIZE);
sentinelFlushConfig();
}
serverLog(LL_WARNING,"Sentinel ID is %s", sentinel.myid);
//向监控的主节点发送+monitor事件
sentinelGenerateInitialMonitorEvents();
}
至此一个哨兵模式的redis服务就启动了。但是并没有看到自动检测发现并连接集群中其他节点的代码。那么哨兵是如何发现集群上其他节点的存在呢?
sentinelTimer
接下来我们看到serverCron里面有个sentinelTimer方法
void sentinelTimer(void) {
//检测是否需要开启sentinel TILT模式
sentinelCheckTiltCondition();
//对哈希表中的每个服务器实例执行调度任务
sentinelHandleDictOfRedisInstances(sentinel.masters);
//执行脚本命令,
sentinelRunPendingScripts();
//清理已经执行完脚本的进程,
sentinelCollectTerminatedScripts();
//kill执行时间超时的脚本
sentinelKillTimedoutScripts();
//为了防止多个哨兵同时选举,错开定时程序执行的时间。
server.hz = CONFIG_DEFAULT_HZ + rand() % CONFIG_DEFAULT_HZ;
}
继续来到sentinelHandleDictOfRedisInstances
void sentinelHandleDictOfRedisInstances(dict *instances) {
dictIterator *di;
dictEntry *de;
sentinelRedisInstance *switch_to_promoted = NULL;
/* There are a number of things we need to perform against every master. */
di = dictGetIterator(instances);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
//实际处理逻辑
sentinelHandleRedisInstance(ri);
if (ri->flags & SRI_MASTER) {
//如果是master节点,则递归其子节点
sentinelHandleDictOfRedisInstances(ri->slaves);
sentinelHandleDictOfRedisInstances(ri->sentinels);
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
}
}
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
dictReleaseIterator(di);
}
至此我们知道了原来哨兵会从master节点开始,对所有节点递归执行sentinelHandleRedisInstance
sentinelHandleRedisInstance
这个递归递归啥呢?继续sentinelHandleRedisInstance
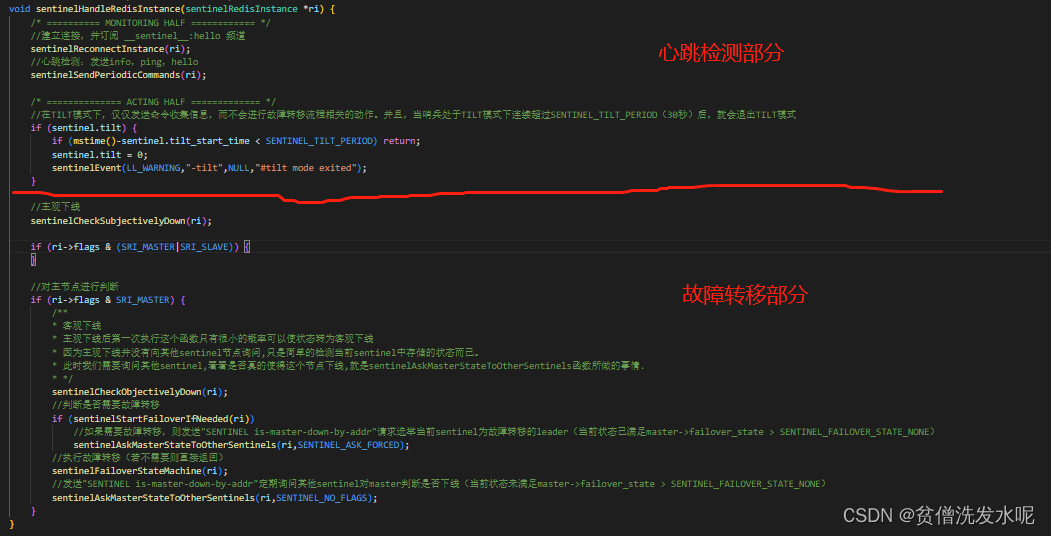
原来心跳检测和故障转移都在这个方法里。
心跳检测
在心跳检测之前会先确认与其他节点的连接是否建立。如果发现节点并未建立连接(包括连接已断开),则会创建命令连接和订阅连接(主/从节点)
sentinelReconnectInstance
void sentinelReconnectInstance(sentinelRedisInstance *ri) {
if (ri->link->disconnected == 0) return;
if (ri->addr->port == 0) return; /* port == 0 means invalid address. */
instanceLink *link = ri->link;
mstime_t now = mstime();
if (now - ri->link->last_reconn_time < SENTINEL_PING_PERIOD) return;
ri->link->last_reconn_time = now;
//创建命令连接
if (link->cc == NULL) {
link->cc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,NET_FIRST_BIND_ADDR);
if (link->cc->err) {
sentinelEvent(LL_DEBUG,"-cmd-link-reconnection",ri,"%@ #%s",
link->cc->errstr);
instanceLinkCloseConnection(link,link->cc);
} else {
link->pending_commands = 0;
link->cc_conn_time = mstime();
link->cc->data = link;
redisAeAttach(server.el,link->cc);
redisAsyncSetConnectCallback(link->cc,
sentinelLinkEstablishedCallback);
redisAsyncSetDisconnectCallback(link->cc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,link->cc);
sentinelSetClientName(ri,link->cc,"cmd");
/* Send a PING ASAP when reconnecting. */
sentinelSendPing(ri);
}
}
//对主/从节点创建订阅连接,并订阅 __sentinel__:hello 频道
if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && link->pc == NULL) {
link->pc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,NET_FIRST_BIND_ADDR);
if (link->pc->err) {
sentinelEvent(LL_DEBUG,"-pubsub-link-reconnection",ri,"%@ #%s",
link->pc->errstr);
instanceLinkCloseConnection(link,link->pc);
} else {
int retval;
link->pc_conn_time = mstime();
link->pc->data = link;
redisAeAttach(server.el,link->pc);
redisAsyncSetConnectCallback(link->pc,
sentinelLinkEstablishedCallback);
redisAsyncSetDisconnectCallback(link->pc,
sentinelDisconnectCallback);
sentinelSendAuthIfNeeded(ri,link->pc);
sentinelSetClientName(ri,link->pc,"pubsub");
/* Now we subscribe to the Sentinels "Hello" channel. */
retval = redisAsyncCommand(link->pc,
sentinelReceiveHelloMessages, ri, "%s %s",
sentinelInstanceMapCommand(ri,"SUBSCRIBE"),
SENTINEL_HELLO_CHANNEL);
if (retval != C_OK) {
/* If we can't subscribe, the Pub/Sub connection is useless
* and we can simply disconnect it and try again. */
instanceLinkCloseConnection(link,link->pc);
return;
}
}
}
/* Clear the disconnected status only if we have both the connections
* (or just the commands connection if this is a sentinel instance). */
if (link->cc && (ri->flags & SRI_SENTINEL || link->pc))
link->disconnected = 0;
}
sentinelSendPeriodicCommands
然后才是真正的心跳检测部分
void sentinelSendPeriodicCommands(sentinelRedisInstance *ri) {
mstime_t now = mstime();
mstime_t info_period, ping_period;
int retval;
if (ri->link->disconnected) return;
//对于INFO、PING和PUBLISH这些非关键命令,有SENTINEL_MAX_PENDING_commands的限制。
if (ri->link->pending_commands >=
SENTINEL_MAX_PENDING_COMMANDS * ri->link->refcount) return;
//info频率的控制。对于下线的节点,将发送info命令的频率由默认的10s一次增加到1s一次
if ((ri->flags & SRI_SLAVE) &&
((ri->master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS)) ||
(ri->master_link_down_time != 0)))
{
info_period = 1000;
} else {
info_period = SENTINEL_INFO_PERIOD;
}
//ping频率的控制。ping间隔最多1s (down_after_period:上次发送 PING 的时长距离现在的阈值。由down-after-milliseconds 配置项决定的)
ping_period = ri->down_after_period;
if (ping_period > SENTINEL_PING_PERIOD) ping_period = SENTINEL_PING_PERIOD;
//对主/从节点发送info命令
if ((ri->flags & SRI_SENTINEL) == 0 &&
(ri->info_refresh == 0 ||
(now - ri->info_refresh) > info_period))
{
retval = redisAsyncCommand(ri->link->cc,
sentinelInfoReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri,"INFO"));
if (retval == C_OK) ri->link->pending_commands++;
}
//对所有节点发送ping命令
if ((now - ri->link->last_pong_time) > ping_period &&
(now - ri->link->last_ping_time) > ping_period/2) {
sentinelSendPing(ri);
}
//发送自身ip,端口,纪元等信息到 __sentinel__:hello 频道
if ((now - ri->last_pub_time) > SENTINEL_PUBLISH_PERIOD) {
sentinelSendHello(ri);
}
}
总结
在心跳检测部分, sentinel会与每个节点建立命令连接,同时订阅主/从节点的 _ sentinel _:hello 频道。并且在后续的定时任务中会执行一下操作:
1、默认10秒1次(下线时1秒1次)发送INFO命令更新主/从节点信息。
2、最多每秒1次发送PING命令检查网络状态
3、默认2秒1次发送sentinel自身ip,端口,纪元等信息到 _ sentinel _:hello 频道,让其他sentinel感知自己
现在再回到文章开头的那个问题:哨兵是如何发现集群上其他节点的存在呢?
对于从节点:当一个从节点加入master节点后,info命令获取master节点最新信息的时候就会将master新加入的从节点同步更新至哨兵,在后续方法处理master的时候就会递归到新加入的从节点,从而建立连接。
对于哨兵节点:由于哨兵节点不像从节点一样,可以"归属于"某个节点,所以对当前已有节点的info命令是无法自动感知到新加入的哨兵节点的。对此redis的做法是让新加入的哨兵节点自己告诉其他节点说“我来啦”。没错,这个就是订阅连接 _ sentinel _:hello 的事。哨兵节点不仅会向 _ sentinel _:hello 频道发送自身信息,而且还会订阅该频道。(通过订阅连接订阅其他sentinel的信息,通过命令连接发送自身信息到频道)
故障转移
为方便阅读,这里再贴一遍sentinelHandleRedisInstance的代码
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
//心跳检测...
//主观下线
sentinelCheckSubjectivelyDown(ri);
if (ri->flags & (SRI_MASTER|SRI_SLAVE)) {
}
//对主节点进行判断
if (ri->flags & SRI_MASTER) {
/**
* 客观下线
* 主观下线后第一次执行这个函数只有很小的概率可以使状态转为客观下线
* 因为主观下线并没有向其他sentinel节点询问,只是简单的检测当前sentinel中存储的状态而已。
* 此时我们需要询问其他sentinel,看看是否真的使得这个节点下线,就是sentinelAskMasterStateToOtherSentinels函数所做的事情.
* */
sentinelCheckObjectivelyDown(ri);
//判断是否需要故障转移
if (sentinelStartFailoverIfNeeded(ri))
//如果需要故障转移,则发送"SENTINEL is-master-down-by-addr"请求选举当前sentinel为故障转移的leader(当前状态已满足master->failover_state > SENTINEL_FAILOVER_STATE_NONE)
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
//执行故障转移(若不需要则直接返回)
sentinelFailoverStateMachine(ri);
//发送"SENTINEL is-master-down-by-addr"定期询问其他sentinel对master判断是否下线(当前状态未满足master->failover_state > SENTINEL_FAILOVER_STATE_NONE)
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}
故障转移的前提是主观下线
主观下线
sentinelCheckSubjectivelyDown
void sentinelCheckSubjectivelyDown(sentinelRedisInstance *ri) {
mstime_t elapsed = 0;
//实例上次活跃到现在的时间
if (ri->link->act_ping_time)
elapsed = mstime() - ri->link->act_ping_time; // 返回距离上次发送PING命令的间隔时间
else if (ri->link->disconnected)
elapsed = mstime() - ri->link->last_avail_time; // 返回距离上次收到PING命令回复的间隔时间
//如果检测到连接的活跃度(activity)很低,那么考虑重断开连接,并进行重连
if (ri->link->cc &&
(mstime() - ri->link->cc_conn_time) >
SENTINEL_MIN_LINK_RECONNECT_PERIOD &&
ri->link->act_ping_time != 0 &&
(mstime() - ri->link->act_ping_time) > (ri->down_after_period/2) &&
(mstime() - ri->link->last_pong_time) > (ri->down_after_period/2))
{
instanceLinkCloseConnection(ri->link,ri->link->cc);
}
if (ri->link->pc &&
(mstime() - ri->link->pc_conn_time) >
SENTINEL_MIN_LINK_RECONNECT_PERIOD &&
(mstime() - ri->link->pc_last_activity) > (SENTINEL_PUBLISH_PERIOD*3))
{
instanceLinkCloseConnection(ri->link,ri->link->pc);
}
/**
* 主观下线条件(或):
* 1:上次活跃时间间隔已经超过了配置文件中指定的down_after_period
* 2:Sentinel 认为实例是主服务器,这个服务器向Sentinel报告它将成为从服务器,且在两个INFO命令间隔还是没有转换成功,认为其下线。
*/
if (elapsed > ri->down_after_period ||
(ri->flags & SRI_MASTER &&
ri->role_reported == SRI_SLAVE &&
mstime() - ri->role_reported_time >
(ri->down_after_period+SENTINEL_INFO_PERIOD*2)))
{
if ((ri->flags & SRI_S_DOWN) == 0) {
sentinelEvent(LL_WARNING,"+sdown",ri,"%@");
ri->s_down_since_time = mstime();
ri->flags |= SRI_S_DOWN;
}
} else {
if (ri->flags & SRI_S_DOWN) {
sentinelEvent(LL_WARNING,"-sdown",ri,"%@");
ri->flags &= ~(SRI_S_DOWN|SRI_SCRIPT_KILL_SENT);
}
}
}
由上可知当上次活跃时间间隔已经超过了配置文件中指定的down_after_period或Sentinel 认为实例是主服务器,但是这个服务器向Sentinel报告它将成为从服务器,且在两个INFO命令间隔还是没有转换成功,认为其主观下线。
客观下线
sentinelCheckObjectivelyDown
void sentinelCheckObjectivelyDown(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
unsigned int quorum = 0, odown = 0;
//客观下线的前提是主观下线
if (master->flags & SRI_S_DOWN) {
quorum = 1;
di = dictGetIterator(master->sentinels);
//遍历查询其他sentinel是否也认为其下线
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->flags & SRI_MASTER_DOWN) quorum++;
}
dictReleaseIterator(di);
//当数量大于master->quorum时则认为其客观下线 (一般为 哨兵数/2+1 )
if (quorum >= master->quorum) odown = 1;
}
if (odown) {
//客观下线
if ((master->flags & SRI_O_DOWN) == 0) {
sentinelEvent(LL_WARNING,"+odown",master,"%@ #quorum %d/%d",
quorum, master->quorum);
master->flags |= SRI_O_DOWN;
master->o_down_since_time = mstime();
}
} else {
//取消客观下线
if (master->flags & SRI_O_DOWN) {
sentinelEvent(LL_WARNING,"-odown",master,"%@");
master->flags &= ~SRI_O_DOWN;
}
}
}
由上可知,客观下线的条件是当前判断为主观下线且有足够多(大于master->quorum)的sentinel也认为下线。
一般情况下主观下线后第一次执行这个函数只有很小的概率可以使状态转为客观下线。因为主观下线并没有向其他sentinel节点询问,只是简单的检测当前sentinel中存储的状态而已。此时我们需要询问其他sentinel,更新其他sentinel是否也认为该节点下线。就是sentinelAskMasterStateToOtherSentinels函数所做的事情。(实际上这个方法是定时器触发的,即不管有没有主观下线都会触发。只是方法里面有对主观下线做判断而已)
is-master-down-by-addr - *
void sentinelAskMasterStateToOtherSentinels(sentinelRedisInstance *master, int flags) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
mstime_t elapsed = mstime() - ri->last_master_down_reply_time;
char port[32];
int retval;
//如果目标 Sentinel 关于主服务器的信息已经太久没更新,则清空
if (elapsed > SENTINEL_ASK_PERIOD*5) {
ri->flags &= ~SRI_MASTER_DOWN;
sdsfree(ri->leader);
ri->leader = NULL;
}
//需要包括主观下线标识才往下走
if ((master->flags & SRI_S_DOWN) == 0) continue;
//若未建立连接则跳过
if (ri->link->disconnected) continue;
//若询问太频繁则跳过
if (!(flags & SENTINEL_ASK_FORCED) &&
mstime() - ri->last_master_down_reply_time < SENTINEL_ASK_PERIOD)
continue;
//向其他sentinel发送"SENTINEL is-master-down-by-addr"
//根据failover_state来决定发 "*" 还是 server.runid,前者代表这只是一次判断是否进行客观下线,后者代表请求投票自己为故障转移leader
ll2string(port,sizeof(port),master->addr->port);
retval = redisAsyncCommand(ri->link->cc,
sentinelReceiveIsMasterDownReply, ri,
"%s is-master-down-by-addr %s %s %llu %s",
sentinelInstanceMapCommand(ri,"SENTINEL"),
master->addr->ip, port,
sentinel.current_epoch,
(master->failover_state > SENTINEL_FAILOVER_STATE_NONE) ?
sentinel.myid : "*");
if (retval == C_OK) ri->link->pending_commands++;
}
dictReleaseIterator(di);
}
sentinelAskMasterStateToOtherSentinels这个方法比较难理解的一点就是,这个方法根据failover_state来决定SENTINEL is-master-down-by-addr参数是 * 还是 server.runid。前者代表这只是一次是否客观下线的判断,后者代表请求投票自己为故障转移leader。很明显,这里的参数是 *。
(当master下线时,会先认为其主观下线,但是未改变failover_state的值,failover_state 仍为 SENTINEL_FAILOVER_STATE_NONE。因此SENTINEL is-master-down-by-addr参数是 *,说明这仅是一次是否客观下线的判断。)
对于SENTINEL is-master-down-by-addr * 的返回则由绑定的回调函数
sentinelReceiveIsMasterDownReply处理。其实这个回调函数就只是更新了其他sentinel的对主节点是否下线以及对后面leader的投票结果而已,没什么特殊的。
void sentinelReceiveIsMasterDownReply(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *ri = privdata;
instanceLink *link = c->data;
redisReply *r;
if (!reply || !link) return;
link->pending_commands--;
r = reply;
if (r->type == REDIS_REPLY_ARRAY && r->elements == 3 &&
r->element[0]->type == REDIS_REPLY_INTEGER &&
r->element[1]->type == REDIS_REPLY_STRING &&
r->element[2]->type == REDIS_REPLY_INTEGER)
{
ri->last_master_down_reply_time = mstime();
//接收其他节点是否认为主节点下线的回复
if (r->element[0]->integer == 1) {
ri->flags |= SRI_MASTER_DOWN;
} else {
ri->flags &= ~SRI_MASTER_DOWN;
}
//如果回复包含选举结果则接收其他节点对sentient领导节点的投票回复
if (strcmp(r->element[1]->str,"*")) {
sdsfree(ri->leader);
if ((long long)ri->leader_epoch != r->element[2]->integer)
serverLog(LL_WARNING,
"%s voted for %s %llu", ri->name,
r->element[1]->str,
(unsigned long long) r->element[2]->integer);
ri->leader = sdsnew(r->element[1]->str);
ri->leader_epoch = r->element[2]->integer;
}
}
}
至此,已经更新了所有sentinel的对主节点是否下线的看法。若主节点真的下线了。下次时间循环再执行客观下线判断的时候就会将其客观下线。
客观下线后才会真正进入sentinelStartFailoverIfNeeded方法判断是否需要故障转移。
int sentinelStartFailoverIfNeeded(sentinelRedisInstance *master) {
//不是客观下线直接返回
if (!(master->flags & SRI_O_DOWN)) return 0;
//当前正在进行故障转移
if (master->flags & SRI_FAILOVER_IN_PROGRESS) return 0;
//上次故障转移间隔太短
if (mstime() - master->failover_start_time <
master->failover_timeout*2)
{
if (master->failover_delay_logged != master->failover_start_time) {
time_t clock = (master->failover_start_time +
master->failover_timeout*2) / 1000;
char ctimebuf[26];
ctime_r(&clock,ctimebuf);
ctimebuf[24] = '\0'; /* Remove newline. */
master->failover_delay_logged = master->failover_start_time;
serverLog(LL_WARNING,
"Next failover delay: I will not start a failover before %s",
ctimebuf);
}
return 0;
}
//故障转移前的准备
//master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
//master->flags |= SRI_FAILOVER_IN_PROGRESS;
sentinelStartFailover(master);
return 1;
}
其实这个方法最重要的几步就是对一些状态做了更新:
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->flags |= SRI_FAILOVER_IN_PROGRESS;
当sentinelStartFailoverIfNeeded返回true时会再次进入sentinelAskMasterStateToOtherSentinels方法,只不过由于这时failover_state的状态是 SENTINEL_FAILOVER_STATE_WAIT_START,大于 SENTINEL_FAILOVER_STATE_NONE。所以 SENTINEL is-master-down-by-addr 的参数是runId,代表这是一次leader的投票。
is-master-down-by-addr - runId
对于这一步的发送与回复的处理在上面讲解sentinelAskMasterStateToOtherSentinels和sentinelReceiveIsMasterDownReply已经一起注释了,为了节省篇幅这里就不再贴一次代码了。
至此,我们知道主节点已经下线了,确定需要故障转移,并且已经发起了故障转移主导leader是哪个sentinel的投票。最后进入sentinelFailoverStateMachine开始故障转移。
sentinelFailoverStateMachine
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_MASTER);
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START: //判断当前哨兵结点是否为leader 是的话 状态改变为SENTINEL_FAILOVER_STATE_SELECT_SLAVE 继续往下走。否的话 看是否选举超时,超时则取消故障转移.
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE: //从所有从节点中选举新的主节点
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE: //新的主节点salve no one。即升级选中从节点为主节点
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION: //如果升级超时,则结束转移过程重新开始
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES: //从节点salve of 新的主节点
sentinelFailoverReconfNextSlave(ri);
break;
}
}
这个方法就比较友好了,状态机的设计使得代码一目了然。每个阶段一个状态,从上往下依次执行。
sentinelFailoverWaitStart
void sentinelFailoverWaitStart(sentinelRedisInstance *ri) {
char *leader;
int isleader;
//获取领导节点选举结果
leader = sentinelGetLeader(ri, ri->failover_epoch);
isleader = leader && strcasecmp(leader,sentinel.myid) == 0;
sdsfree(leader);
//如果不是leader且没有强制故障转移的标识,则判断是否选举超时,超时的话结束转移过程。全部重新开始(ri->failover_state = SENTINEL_FAILOVER_STATE_NONE)
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
int election_timeout = SENTINEL_ELECTION_TIMEOUT;
if (election_timeout > ri->failover_timeout)
election_timeout = ri->failover_timeout;
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
//如果是leader则往下走
sentinelEvent(LL_WARNING,"+elected-leader",ri,"%@");
if (sentinel.simfailure_flags & SENTINEL_SIMFAILURE_CRASH_AFTER_ELECTION)
sentinelSimFailureCrash();
//状态置为 SENTINEL_FAILOVER_STATE_SELECT_SLAVE
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_WARNING,"+failover-state-select-slave",ri,"%@");
}
leader节点选举结果是怎么计算的呢,来看sentinelGetLeader
sentinelGetLeader
char *sentinelGetLeader(sentinelRedisInstance *master, uint64_t epoch) {
dict *counters;
dictIterator *di;
dictEntry *de;
unsigned int voters = 0, voters_quorum;
char *myvote;
char *winner = NULL;
uint64_t leader_epoch;
uint64_t max_votes = 0;
serverAssert(master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS));
counters = dictCreate(&leaderVotesDictType,NULL);
voters = dictSize(master->sentinels)+1; /* All the other sentinels and me.*/
//统计投票结果
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->leader != NULL && ri->leader_epoch == sentinel.current_epoch)
sentinelLeaderIncr(counters,ri->leader);
}
dictReleaseIterator(di);
//找到票数最多的winner
di = dictGetIterator(counters);
while((de = dictNext(di)) != NULL) {
uint64_t votes = dictGetUnsignedIntegerVal(de);
if (votes > max_votes) {
max_votes = votes;
winner = dictGetKey(de);
}
}
dictReleaseIterator(di);
//统计自己的投票结果:优先顺序 leader_epoch -> winner -> 自己
if (winner)
myvote = sentinelVoteLeader(master,epoch,winner,&leader_epoch);
else
myvote = sentinelVoteLeader(master,epoch,sentinel.myid,&leader_epoch);
if (myvote && leader_epoch == epoch) {
uint64_t votes = sentinelLeaderIncr(counters,myvote);
if (votes > max_votes) {
max_votes = votes;
winner = myvote;
}
}
//选举结果的票数需满足:大于voters/2+1 且 大于master->quorum
voters_quorum = voters/2+1;
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
winner = winner ? sdsnew(winner) : NULL;
sdsfree(myvote);
dictRelease(counters);
return winner;
}
先统计票数,统计方法如下:
先统计其他sentinel的票数,再统计自己的票数,当自己有leader_epoch时则投给leader_epoch,没有则投给当前票数最多的winner节点,当都没有时则投给自己,最后再看一下自己是不是winner。当winner的票数满足:大于voters/2+1 且 大于master->quorum。则winner就是leader
不是leader的节点会停留在这一步,只有leader节点才会继续往下走,来到sentinelFailoverSelectSlave方法从slave中选举新的master。
sentinelFailoverSelectSlave
void sentinelFailoverSelectSlave(sentinelRedisInstance *ri) {
sentinelRedisInstance *slave = sentinelSelectSlave(ri);
if (slave == NULL) {
sentinelEvent(LL_WARNING,"-failover-abort-no-good-slave",ri,"%@");
sentinelAbortFailover(ri);
} else {
sentinelEvent(LL_WARNING,"+selected-slave",slave,"%@");
//标记升级节点
slave->flags |= SRI_PROMOTED;
ri->promoted_slave = slave;
//状态置为 SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE
ri->failover_state = SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_NOTICE,"+failover-state-send-slaveof-noone",
slave, "%@");
}
}
新的master节点如何选择呢,来到sentinelSelectSlave方法
sentinelSelectSlave
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
sentinelRedisInstance **instance =
zmalloc(sizeof(instance[0])*dictSize(master->slaves));
sentinelRedisInstance *selected = NULL;
int instances = 0;
dictIterator *di;
dictEntry *de;
mstime_t max_master_down_time = 0;
if (master->flags & SRI_S_DOWN)
max_master_down_time += mstime() - master->s_down_since_time;
max_master_down_time += master->down_after_period * 10;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
/**
* 一些条件的判断筛选出可用的salver
* 1、排除所有处于主观,客观下线的从实例
* 2、排除所有处于无法连接状态的从实例。
* 3、排除所有没有在在默认5s 内回复 Sentinel 的从实例。
* 4、排除所有优先级为 0 的从实例。
* 5、排除所有 info_validity_time为 3 秒以前的,或 5 秒以前的(在主实例为主观下线状态下)的从实例。
*/
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
if (slave->link->disconnected) continue;
if (mstime() - slave->link->last_avail_time > SENTINEL_PING_PERIOD*5) continue;
if (slave->slave_priority == 0) continue;
if (master->flags & SRI_S_DOWN)
info_validity_time = SENTINEL_PING_PERIOD*5;
else
info_validity_time = SENTINEL_INFO_PERIOD*3;
if (mstime() - slave->info_refresh > info_validity_time) continue;
if (slave->master_link_down_time > max_master_down_time) continue;
instance[instances++] = slave;
}
dictReleaseIterator(di);
/**
* 排序可用slaver,取第一个。排序方式
* 1、从实例优先级
* 2、从实例复制偏移量
* 3、从实例 Id 值
*/
if (instances) {
qsort(instance,instances,sizeof(sentinelRedisInstance*),
compareSlavesForPromotion);
selected = instance[0];
}
zfree(instance);
return selected;
}
从所有可选择的从节点中按以下排序方式选排第一的从节点:
1、从实例优先级
2、从实例复制偏移量
3、从实例 Id 值
接着将从节点升级成主节点,来到sentinelFailoverSendSlaveOfNoOne方法
sentinelFailoverSendSlaveOfNoOne
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
//与从服务器连接断开直接结束
if (ri->promoted_slave->link->disconnected) {
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
//向从服务器发送 salve of no one 等升级命令(并不真正关心应答。观察返回的INFO是否返回主角色)
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL,0);
if (retval != C_OK) return;
sentinelEvent(LL_NOTICE, "+failover-state-wait-promotion",
ri->promoted_slave,"%@");
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
ri->failover_state_change_time = mstime();
}
为了防止超时导致一直卡在这里,在SENTINEL_FAILOVER_STATE_WAIT_PROMOTION状态时会有超时检测,如果转移时间大于 failover_timeout 就直接结束故障转移,从头开始。
sentinelFailoverWaitPromotion
void sentinelFailoverWaitPromotion(sentinelRedisInstance *ri) {
/* Just handle the timeout. Switching to the next state is handled
* by the function parsing the INFO command of the promoted slave. */
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
}
升级失败则直接结束故障转移流程。
升级成功,则会进入 SENTINEL_FAILOVER_STATE_RECONF_SLAVES 阶段。但是sentinelFailoverWaitPromotion明显没有相关状态变更的代码。
那升级成功了是怎么进入 SENTINEL_FAILOVER_STATE_RECONF_SLAVES 阶段的?
答案在 sentinelInfoReplyCallback 。上面讲到,哨兵会定时发送INFO命令更新集群内的主/从节点的信息。而这个命令的回调函数就是sentinelInfoReplyCallback。
sentinelInfoReplyCallback
void sentinelInfoReplyCallback(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *ri = privdata;
instanceLink *link = c->data;
redisReply *r;
if (!reply || !link) return;
link->pending_commands--;
r = reply;
if (r->type == REDIS_REPLY_STRING)
sentinelRefreshInstanceInfo(ri,r->str);
}
在sentinelRefreshInstanceInfo方法里面会同步更新节点的最新信息,当发现这个节点是回复的角色是master,但是哨兵认为其实slave时,则会进入判断当前节点是否被标记问升级节点,而且master是否正在故障转移,且转移的阶段是SENTINEL_FAILOVER_STATE_WAIT_PROMOTION。如果都满足,就会把failover_state设为SENTINEL_FAILOVER_STATE_RECONF_SLAVES进入下一阶段。同时哨兵会一直尝试重连旧master,当旧master恢复后,info返回是master,但是前面哨兵会将其标记为slave。这时哨兵就会向旧master发送slaveof “new master”,这样旧master就会作为新master的从机。
sentinelRefreshInstanceInfo
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
//....
if ((ri->flags & SRI_SLAVE) && role == SRI_MASTER) {
if ((ri->flags & SRI_PROMOTED) &&
(ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state ==
SENTINEL_FAILOVER_STATE_WAIT_PROMOTION))
{
//升级slave为master
ri->master->config_epoch = ri->master->failover_epoch;
ri->master->failover_state = SENTINEL_FAILOVER_STATE_RECONF_SLAVES;
ri->master->failover_state_change_time = mstime();
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+promoted-slave",ri,"%@");
if (sentinel.simfailure_flags &
SENTINEL_SIMFAILURE_CRASH_AFTER_PROMOTION)
sentinelSimFailureCrash();
sentinelEvent(LL_WARNING,"+failover-state-reconf-slaves",
ri->master,"%@");
sentinelCallClientReconfScript(ri->master,SENTINEL_LEADER,
"start",ri->master->addr,ri->addr);
sentinelForceHelloUpdateForMaster(ri->master);
} else {
//如果新master状态正常,向旧master发送slaveof命令
mstime_t wait_time = SENTINEL_PUBLISH_PERIOD*4;
if (!(ri->flags & SRI_PROMOTED) &&
sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri,wait_time) &&
mstime() - ri->role_reported_time > wait_time)
{
int retval = sentinelSendSlaveOf(ri,
ri->master->addr->ip,
ri->master->addr->port);
if (retval == C_OK)
sentinelEvent(LL_NOTICE,"+convert-to-slave",ri,"%@");
}
}
}
//...
}
sentinelFailoverReconfNextSlave
void sentinelFailoverReconfNextSlave(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
int in_progress = 0;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG))
in_progress++;
}
dictReleaseIterator(di);
di = dictGetIterator(master->slaves);
while(in_progress < master->parallel_syncs &&
(de = dictNext(di)) != NULL)
{
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
//一些条件的判断
if (slave->flags & (SRI_PROMOTED|SRI_RECONF_DONE)) continue;
if ((slave->flags & SRI_RECONF_SENT) &&
(mstime() - slave->slave_reconf_sent_time) >
SENTINEL_SLAVE_RECONF_TIMEOUT)
{
sentinelEvent(LL_NOTICE,"-slave-reconf-sent-timeout",slave,"%@");
slave->flags &= ~SRI_RECONF_SENT;
slave->flags |= SRI_RECONF_DONE;
}
if (slave->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)) continue;
if (slave->link->disconnected) continue;
//发送 salve of 命令
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == C_OK) {
slave->flags |= SRI_RECONF_SENT;
slave->slave_reconf_sent_time = mstime();
sentinelEvent(LL_NOTICE,"+slave-reconf-sent",slave,"%@");
in_progress++;
}
}
dictReleaseIterator(di);
sentinelFailoverDetectEnd(master);
}
这一步就更简单了,遍历所有从节点,发送salve of ‘newmaster’命令
参考文献:《Redis设计与实现》黄健宏著、redis-5.0.14源码