本文继续接着我的上一篇博客【Python爬虫】简单案例介绍1-CSDN博客
目录
跨页
3.2 环境准备
跨页
当对单个页面的结构有了清晰的认识并成功提取数据后,接下来就需要考虑页面之间的跨页问题。此时我们便迎来了下一个关键任务:如何实现跨页爬取?
因为互联网上的信息往往是分散在多个页面中的,跨页爬取能够让我们获取更全面、更丰富的数据。这就要求我们研究页面之间的链接关系,找到页面跳转的规律。有些网站通过页码参数来实现页面切换,如page=1、page=2等;而有些则可能采用更复杂的链接结构,比如根据时间、分类等进行页面划分。我们需要识别这些规律,并运用相应的代码逻辑,模拟用户在页面间的跳转操作,从而实现从一个页面跳转到另一个页面,不断扩大数据的采集范围。只有兼顾单个页面的精准剖析和页面间的有效跨页,才能构建出高效、稳定的 Python 爬虫程序,满足各种数据获取的需求。
(1)在需要爬取的页面右击“检查”打开浏览器开发者工具,之后点击“Network”,
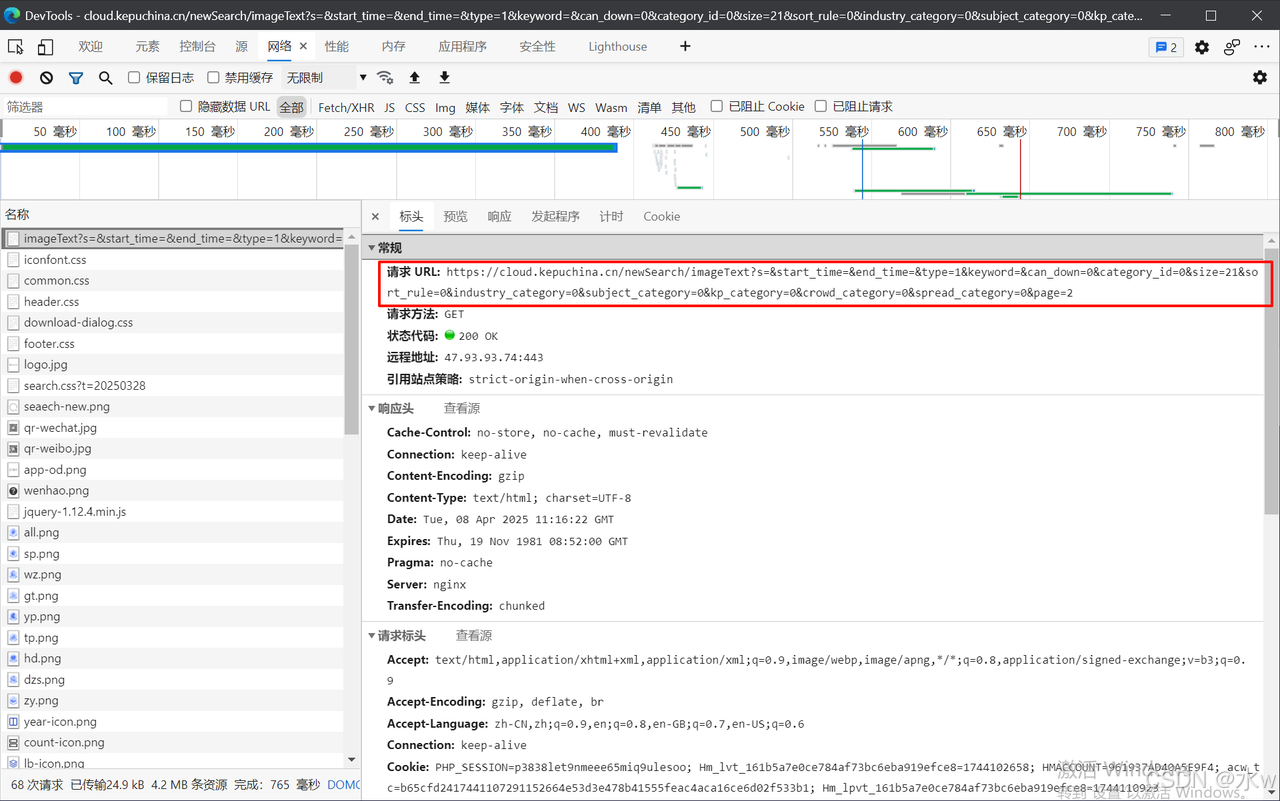
可以发现其中的规律,
https://cloud.kepuchina.cn/newSearch/imageText?category_id=0&can_down=0
https://cloud.kepuchina.cn/newSearch/imageText?s=&start_time=&end_time=&type=1&keyword=&can_down=0&category_id=0&size=21&sort_rule=0&industry_category=0&subject_category=0&kp_category=0&crowd_category=0&spread_category=0&page=2
https://cloud.kepuchina.cn/newSearch/imageText?s=&start_time=&end_time=&type=1&keyword=&can_down=0&category_id=0&size=21&sort_rule=0&industry_category=0&subject_category=0&kp_category=0&crowd_category=0&spread_category=0&page=3到此,这就是整个爬取该目标网站文章的大致思路。
3.2 环境准备
在着手进行 Python 爬虫项目开发代码的编写之前,做好充分的准备工作是至关重要的。首先,要确保 Python 环境已经正确安装并配置妥当。
此外,还需要确保已经安装了一些爬虫项目中大概率会用到的第三方库。如未安装,可以使用下列命令进行安装:
pip3 install lxml # 是一个高性能的 XML 和 HTML 解析库,可以快速地解析网页的 HTML 代码,并且支持通过 XPath 和 CSS 选择器等方式精准定位页面中的元素,方便提取所需的数据,解析速度相较于一些其他的解析方式往往更快。
pip3 install bs4 # BeautifulSoup是一个强大的 HTML/XML 解析库,能将复杂的 HTML 或 XML 文档转换为树形结构,方便用户通过标签名、类名、ID 等属性查找和提取数据。
pip3 install pandas # 是一个功能强大的数据处理和分析库,提供了名为 DataFrame 的数据结构,便于对数据进行整理、清洗、转换以及各种数据分析操作。
pip3 install xlwt # 主要用于创建和写入 Excel 文件(.xls 格式)。
pip3 install openpyxl # 侧重于处理新版本的 Excel 文件(.xlsx 格式),支持对 Excel 文件进行读、写以及各种复杂的单元格格式设置、数据填充等操作。
pip3 install requests # 能够简单且高效地发送各种 HTTP 请求(比如 GET、POST 等请求方法),可以方便地处理请求头、请求参数、Cookie 等相关信息。