前言
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
CUDA编程:基础与实践 樊哲勇
参考B站:蒙特卡洛加的树

文章所有代码可在我的GitHub获得,后续会慢慢更新
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
0:CUDA Pytorch关系
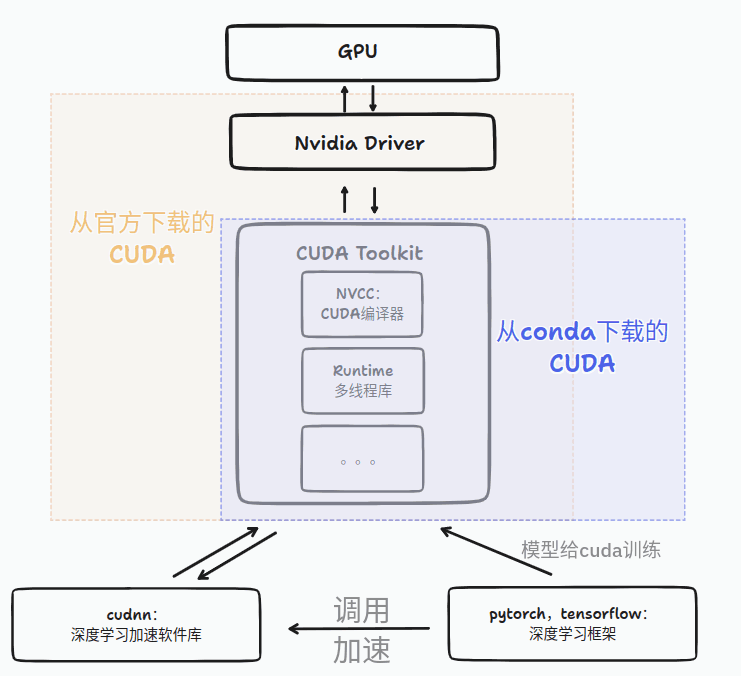
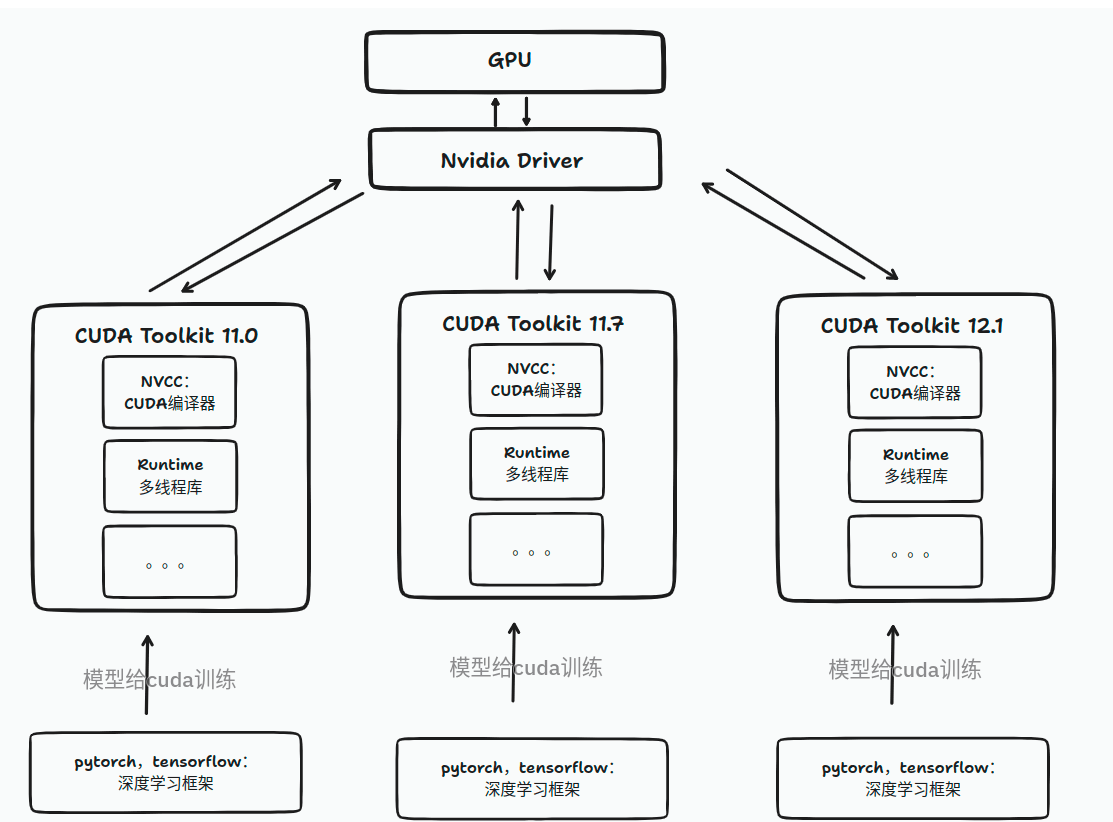
图片来源、详细文章参考点这里
卷积计算
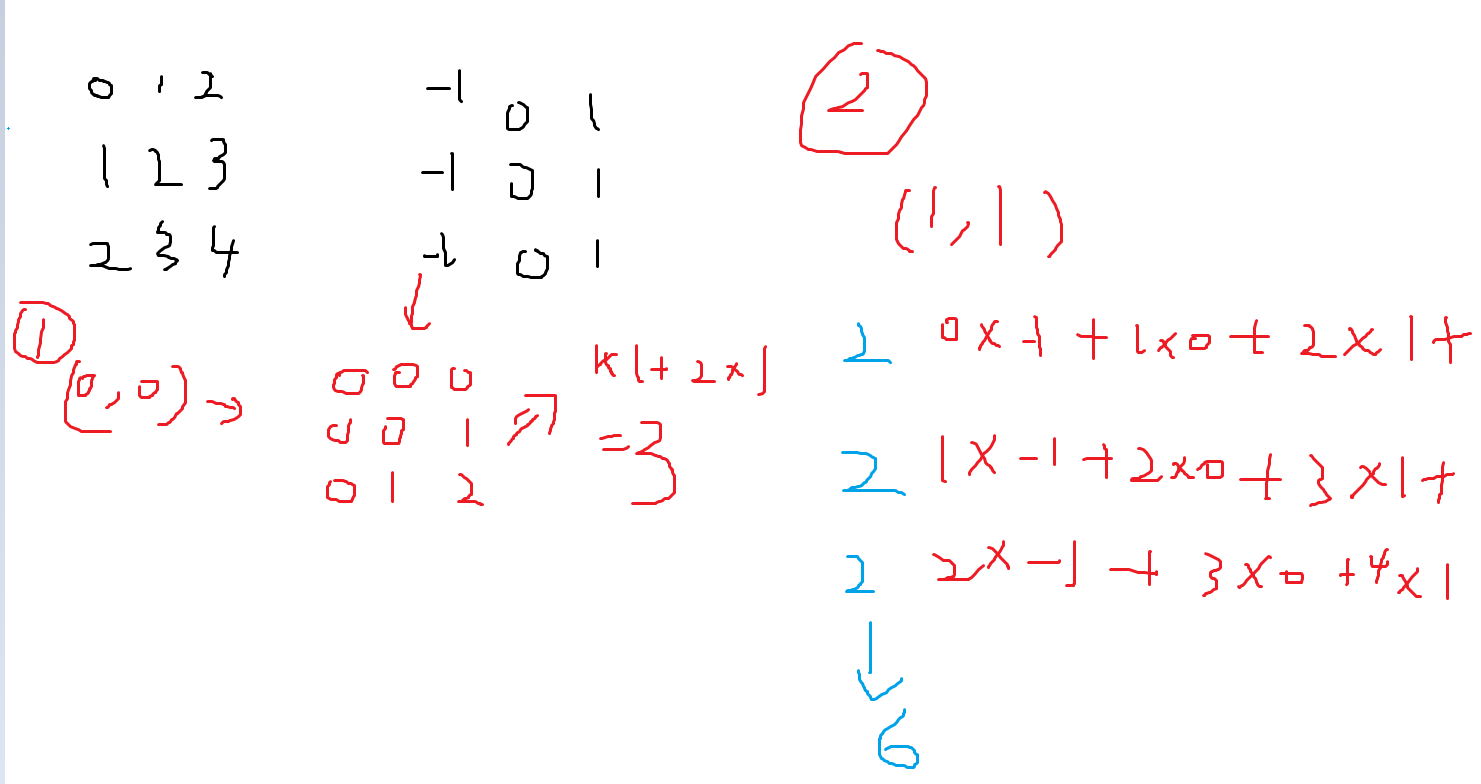
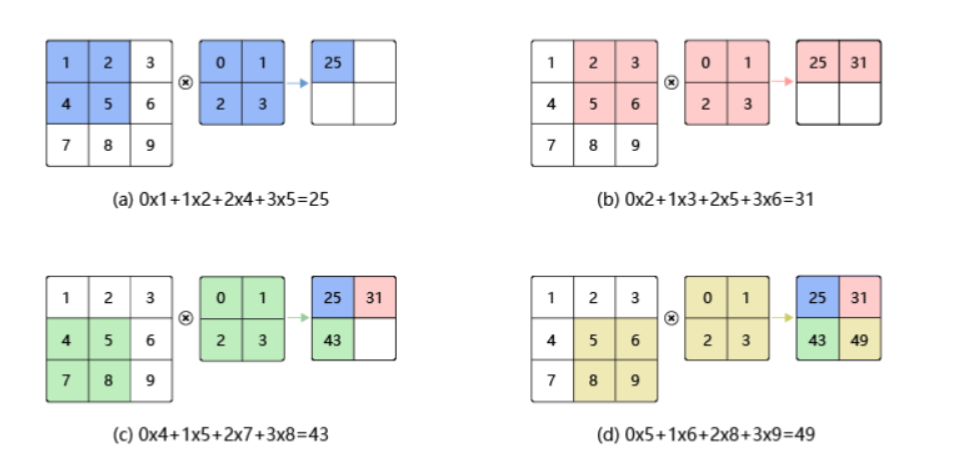
1:CUDA卷积计算编程
代码概述:
(1) CHECK 用来debug错误检测(建议做好习惯)
(2)getThreadNum() 获取线程相关信息
(3)conv 卷积计算
(4)main函数里面
在CPU上开空间,定义数据,img和kernel(卷积核)
CPU数据拷贝到GPU计算
GPU计算 (运行核函数 conv)
计算结果GPU拷贝到CPU
输出
释放空间
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
const int NUM_REPEATS = 10;
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
static void HandleError(cudaError_t err,
const char* file,
int line)
{
if (err != cudaSuccess)
{
printf("%s in %s at line %d\n",
cudaGetErrorString(err),
file, line);
exit(EXIT_FAILURE);
}
}
#define HANDLE_ERROR(err) (HandleError(err, __FILE__, __LINE__))
int getThreadNum()
{
cudaDeviceProp prop;
int count;
CHECK(cudaGetDeviceCount(&count));
printf("gpu num %d\n", count);
CHECK(cudaGetDeviceProperties(&prop, 0));
printf("max thread num: %d\n", prop.maxThreadsPerBlock);
printf("max grid dimensions: %d, %d, %d)\n",
prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
return prop.maxThreadsPerBlock;
}
__global__ void conv(float* img, float* kernel, float* result,
int width, int height, int kernelSize)
{
int ti = threadIdx.x;
int bi = blockIdx.x;
int id = (bi * blockDim.x + ti);
if (id >= width * height)
{
return;
}
int row = id / width;
int col = id % width;
for (int i = 0; i < kernelSize; ++i)
{
for (int j = 0; j < kernelSize; ++j)
{
float imgValue = 0;
int curRow = row - kernelSize / 2 + i;
int curCol = col - kernelSize / 2 + j;
if (curRow < 0 || curCol < 0 || curRow >= height || curCol >= width)
{
}
else
{
imgValue = img[curRow * width + curCol];
}
result[id] += kernel[i * kernelSize + j] * imgValue;
}
}
}
int main()
{
int width = 1000;
int height = 1000;
float* img = new float[width * height];
for (int row = 0; row < height; ++row)
{
for (int col = 0; col < width; ++col)
{
img[col + row * width] = (col + row) % 256;
}
}
int kernelSize = 3;
float* kernel = new float[kernelSize * kernelSize];
for (int i = 0; i < kernelSize * kernelSize; ++i)
{
kernel[i] = i % kernelSize - 1;
}
float* imgGpu;
float* kernelGpu;
float* resultGpu;
CHECK(cudaMalloc((void**)&imgGpu, width * height * sizeof(float)));
CHECK(cudaMalloc((void**)&kernelGpu, kernelSize * kernelSize * sizeof(float)));
CHECK(cudaMalloc((void**)&resultGpu, width * height * sizeof(float)));
CHECK(cudaMemcpy(imgGpu, img,
width * height * sizeof(float), cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(kernelGpu, kernel,
kernelSize * kernelSize * sizeof(float), cudaMemcpyHostToDevice));
int threadNum = getThreadNum();
int blockNum = (width * height - 0.5) / threadNum + 1;
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
conv << <blockNum, threadNum >> >
(imgGpu, kernelGpu, resultGpu, width, height, kernelSize);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("Time = %g +- %g ms.\n", t_ave, t_err);
float* result = new float[width * height];
CHECK(cudaMemcpy(result, resultGpu,
width * height * sizeof(float), cudaMemcpyDeviceToHost));
// visualization
printf("img\n");
for (int row = 0; row < 10; ++row)
{
for (int col = 0; col < 10; ++col)
{
printf("%2.0f ", img[col + row * width]);
}
printf("\n");
}
printf("kernel\n");
for (int row = 0; row < kernelSize; ++row)
{
for (int col = 0; col < kernelSize; ++col)
{
printf("%2.0f ", kernel[col + row * kernelSize]);
}
printf("\n");
}
printf("result\n");
for (int row = 0; row < 10; ++row)
{
for (int col = 0; col < 10; ++col)
{
printf("%2.0f ", result[col + row * width]);
}
printf("\n");
}
return 0;
}
运行时间:
计算1次
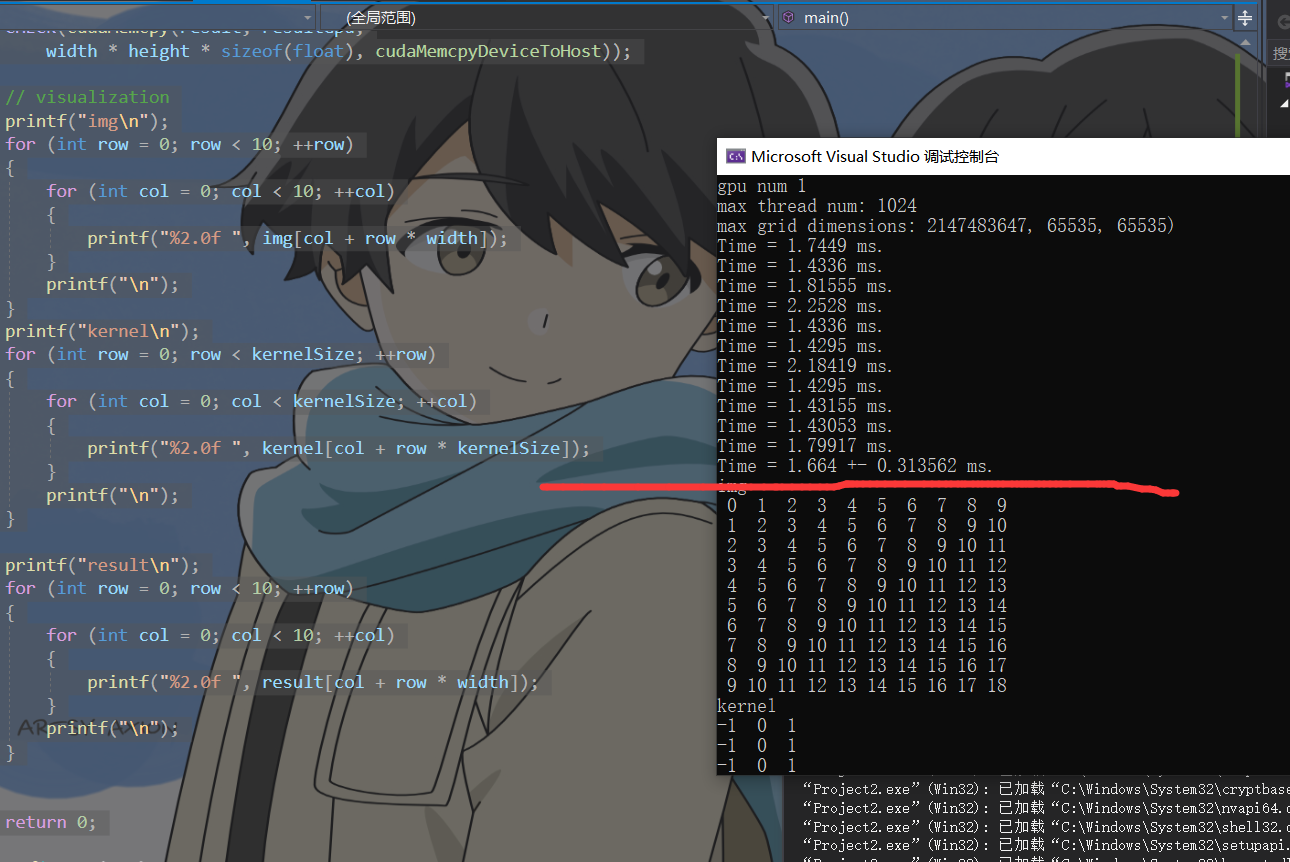
计算50次
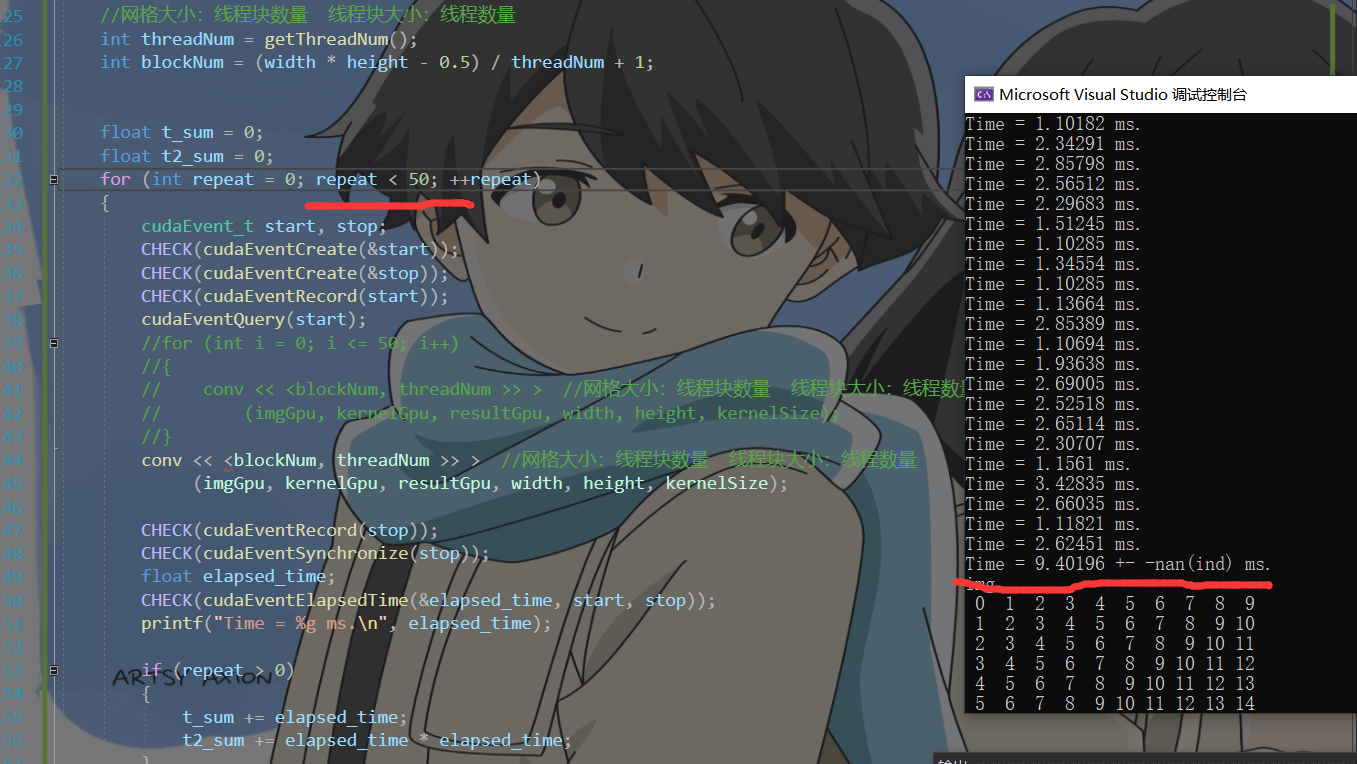
2:Pytorch卷积计算
GPU
import time
import torch
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
width = 1000;
height = 1000;
#img =torch.ones([width,height])
img =torch.randn([width,height])
img = img.to(device)
kernel = torch.tensor([[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0]])
#input = torch.reshape(input, (1, 1, 5, 5))
img = torch.reshape(img, (1, 1, width, height))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
kernel = kernel.to(device)
output = F.conv2d(img, kernel, stride=1).to(device)
# torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
# 返回的是 s , 乘1000 为ms
start = time.perf_counter()
# output = F.conv2d(img, kernel, stride=1).to(device)
output = F.conv2d(img, kernel, stride=1).to(device)
end = time.perf_counter()
print("startime:",start)
print("endtime:",end)
print("total:",end-start)
print("output:size===>",output.shape)
print("output tensor:",output)
计算1次
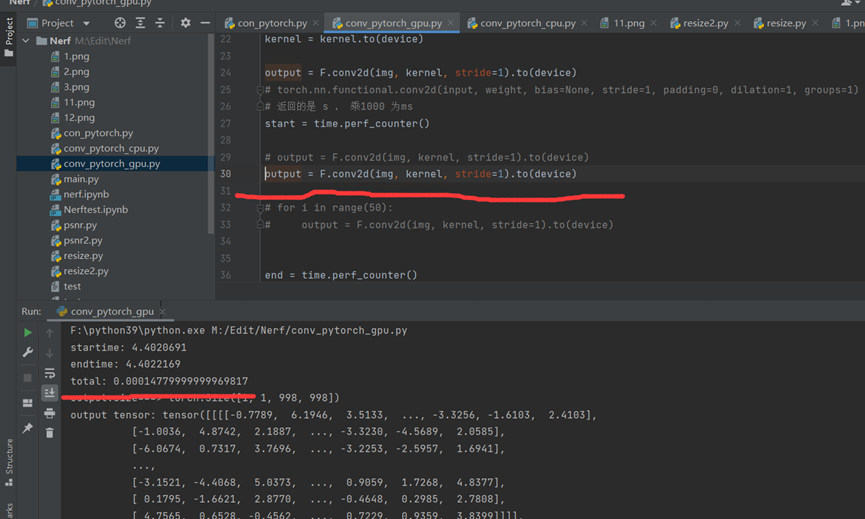
计算50次
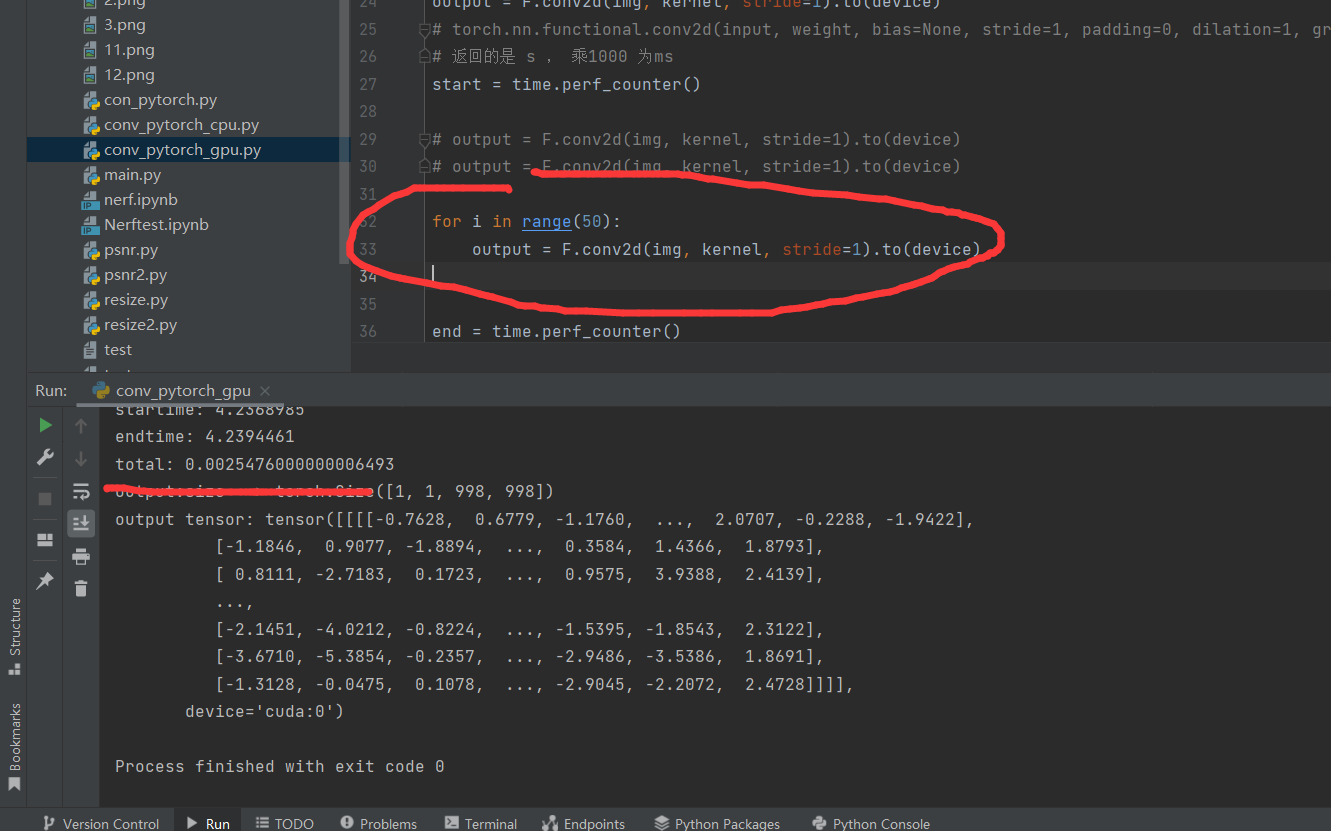
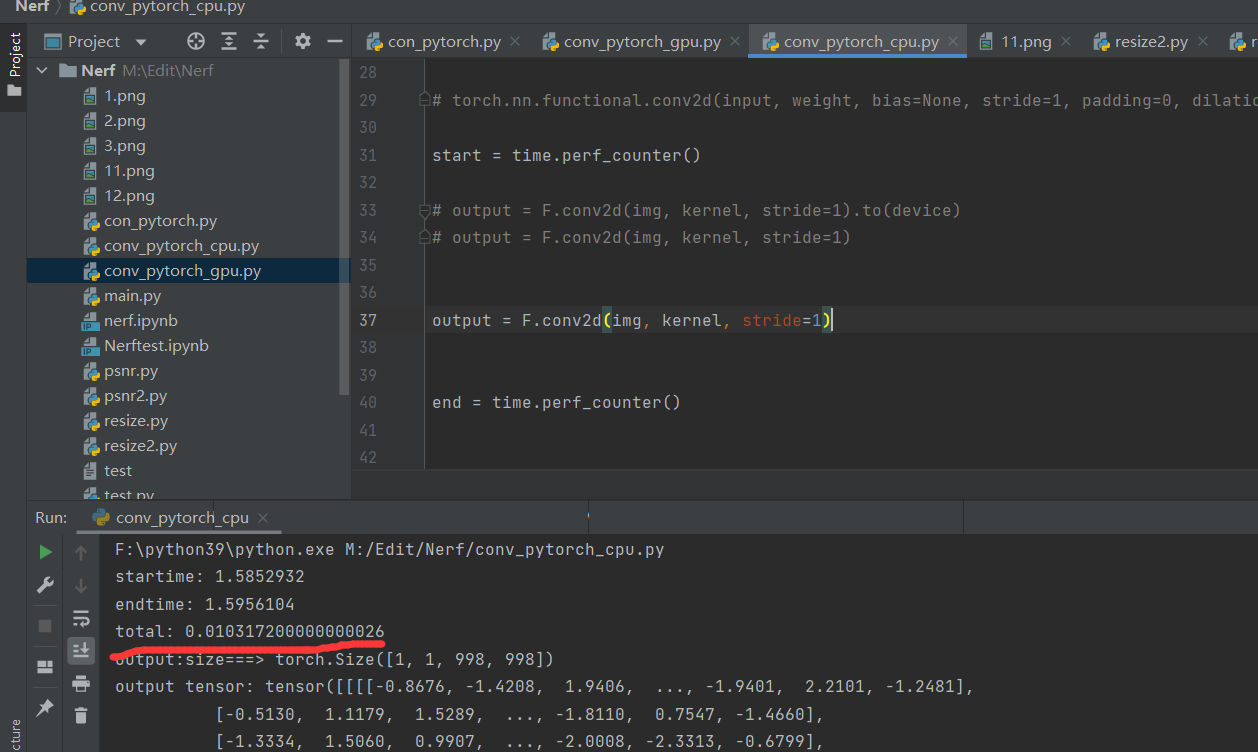
CPU
import time
import torch
import torch.nn.functional as F
width = 1000;
height = 1000;
#img =torch.ones([width,height])
img =torch.randn([width,height])
# print(img.shape)
# print(img)
kernel = torch.tensor([[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0],
[-1.0, 0.0, 1.0]])
#input = torch.reshape(input, (1, 1, 5, 5))
img = torch.reshape(img, (1, 1, width, height))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# print(kernel.shape)
# torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
start = time.perf_counter()
# output = F.conv2d(img, kernel, stride=1).to(device)
output = F.conv2d(img, kernel, stride=1)
end = time.perf_counter()
print("startime:",start)
print("endtime:",end)
print("total:",end-start)
print("output:size===>",output.shape)
print("output tensor:",output)
计算1次
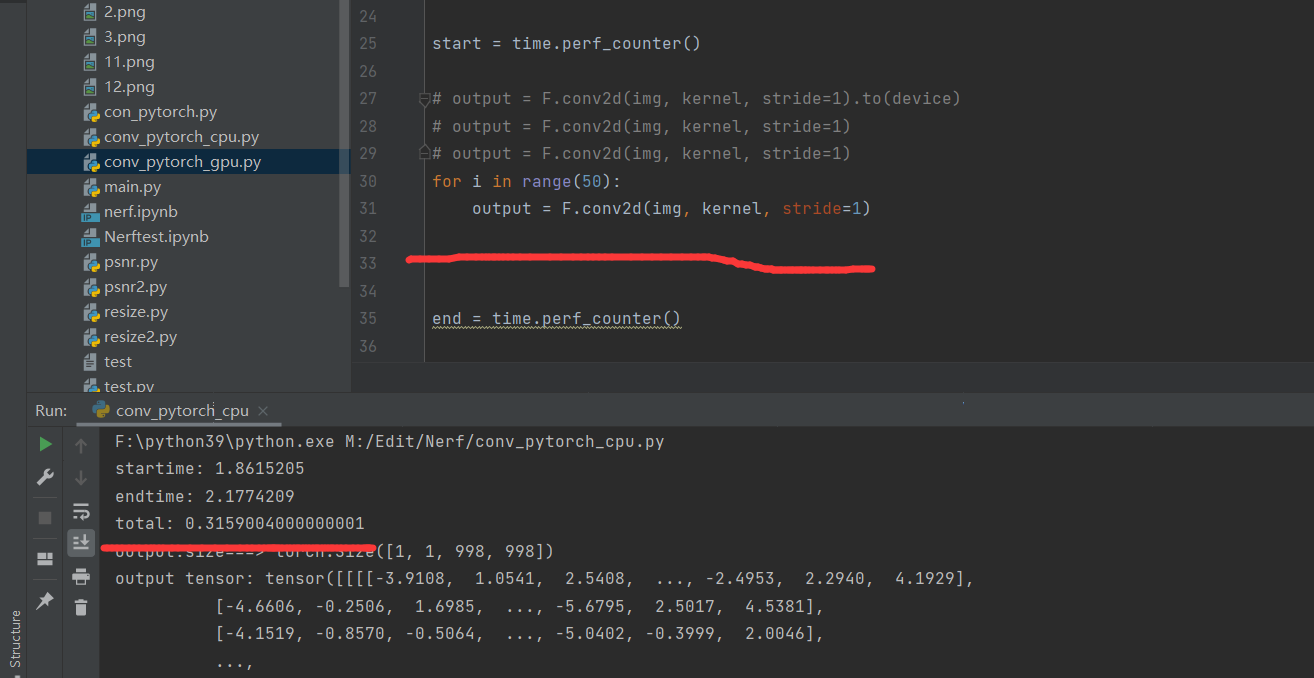
计算50次
性能对比
1epoch 50epoch
CUDA 1.4-2.2ms == 1.6ms 9ms
Pytorch(CPU) 10ms 290ms
Pytorch(GPU) 0.1ms 2.4ms
7:总结(优化性能)
优化性能必要条件:
(1)数据传输比例较小。
(2) 核函数的算术强度较高。
(3)核函数中定义的线程数目较多。
编程手段:
• 减少主机与设备之间的数据传输。
• 提高核函数的算术强度。
• 增大核函数的并行规模。
8:拓展
(1)数据传输的比例
如果一个程序的目的仅仅是计算两个数组的和,那么 用GPU可能比用CPU还要慢。这是因为,花在数据传输(CPU与GPU之间)上的时间比计算(求和)本身还要多很多。GPU计算核心和设备内存之间数据传输的峰值理论带宽要 远高于 GPU 和 CPU 之间数据传输的带宽。
设计算任务不是做一次数组相加的计算,而是做10000次数组相加的计算,而且只需 要在程序的开始和结束部分进行数据传输,那么数据传输所占的比例将可以忽略不计。此时,整个 CUDA 程序的性能就大为提高。
(2)算术强度
数组相加的问题之 所以很难得到更高的加速比,是因为该问题的算术强度(arithmetic intensity)不高。一个 计算问题的算术强度指的是其中算术操作的工作量与必要的内存操作的工作量之比。
例如, 在数组相加的问题中,在对每一对数据进行求和时需要先将一对数据从设备内存中取出来, 然后对它们实施求和计算,最后再将计算的结果存放到设备内存。这个问题的算术强度其 实是不高的,因为在取两次数据、存一次数据的情况下只做了一次求和计算。在CUDA中,设备内存的读、写都是代价高昂(比较耗时)的。
(3)并行规模:
并行规模可用 GPU 中总的线程数目来衡量。
从硬件的角度来看,一个GPU由多个流多处理器(streaming multiprocessor,SM)构成,而每个SM中有若干CUDA核心。每个SM是相对独立的。从开普勒架构到伏特架 构,一个SM中最多能驻留(reside)的线程个数是 2048。对于图灵架构,该数目是 1024。 一块GPU中一般有几个到几十个SM(取决于具体的型号)。所以,一块GPU一共可以驻 留几万到几十万个线程。如果一个核函数中定义的线程数目远小于这个数的话,就很难得到很高的加速比。