1.从main函数开始:
1.1 确定使用的哪个GPU.

1.2 保存训练时的参数和日志



2. 加载数据

先找到存放训练和测试数据的目录,接下来加载相关的数据参数:
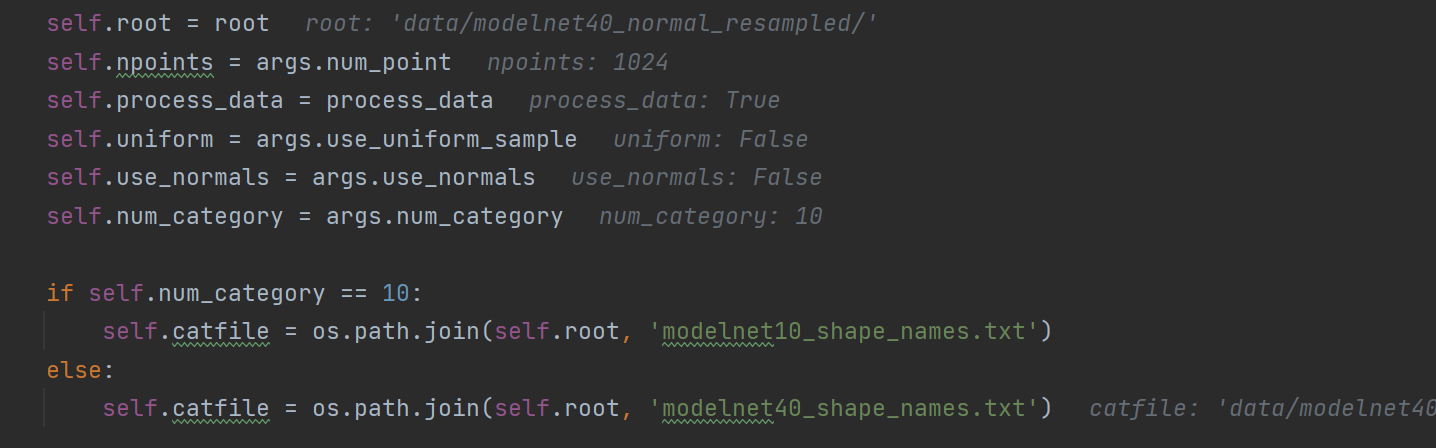
下面是执行的结果:

接下来为训练样本开始做准备:

给不同标签做上标记:
定位每个样本文件:

 3.导入模型
3.导入模型
4.其他参数
4.1使用GPU
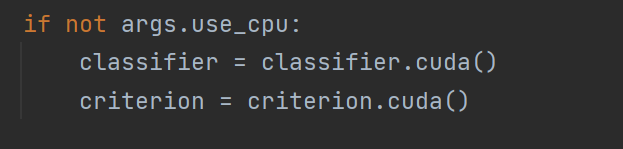
4.2 加载预训练模型
4.3
5.训练部分
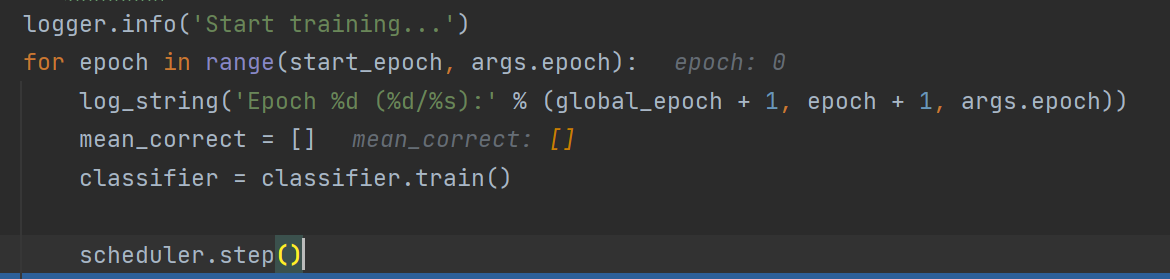

optimizer.zero_grad()//将梯度清零,如果不加此话,梯度就会一直不断的累加。
接下来将点云转为Numpy的形式,并进行随机点剔除、缩放和平移
以上的内容对于防止过拟合很有帮助,提升模型的泛化能力
接下来就是将numpy转为tensor的数据形式,并将维度中 第2维和第3维进行转置,再放入cuda。
数据发生的变化:16*1024*3---》16*3*1024
进入网络开始训练
数据进入网络后进入 PointNetSetAbstraction 函数:
先将数据16*3*1024---》16*1024*3 因为我将数据 batch_size 设置为了16
16*1024*3:16个样本,每个样本1024个点,每个点3个维度(x,y,z)也可以认为是3个特征。
点云样本被送入 sample_and_group:什么作用
点云变化:
new_xyz:16*512*3 中心点
new_points:16*3*32*512-->16*64*32*512-->16*128*32*512-->16*128*512
new_points 是在512个点附近查询的32个点,并采用PointNet的思想对32个点进行特征生维,然后计算32个点云的最大值,完成特征计算。
new_xyz:16*128*3
new_points:16*131*64*128-->16*128*64*128-->16*256*64*128-->16*256*128
这里出现131是因为128维特征再加上每个点原有的3个特征。
new_xyz:16*1*3
new_points:16*259*128*1-->16*256*128*1-->16*512*128*1-->16*1024*128*1-->16*1024*1
现在相当于降采样后,在1点查询附近的128个点,并进行特征生维然后,进行MaxPooling
x:16*1024-->16*512-->16*256-->16*10 训练完成,将loss和预测结果返回去

计算每个样本的最大概率,将其记为预测结果。同时计算Loss,
loss.backward() 反向传播,计算当前梯度;
optimizer.step() 根据梯度更新网络参数