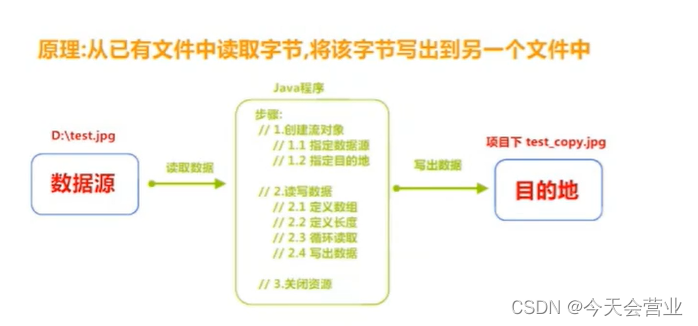
SQL语句分类
1.DDL 数据库定义语言 主要是用于来操作数据库 以及数据库表 关键字 alter drop create truncate
- DQL 数据库查询语言 主要是用于操作数据库表 主要用于查询数据库中的数据 关键字 select
- DML 数据库操纵语言 主要是用于操作数据库中数据表 主要是对数据进行 增加 insert 删除 delete 修改 update
- DCL 数据库控制语言 主要是用于对数据库的用户的管理 以及权限的管理 运维工程师操作 关键字为grant、revoke
单表查询
1.增删改
intsert into 表名(列名,列名..)values(对应列名的数据,对应列名的数据..)
delete from 表名 where 条件 例(id=1)
#删除多行
delete from 表名 where id in (a,b,c)
update 表名 set 列名=值,列名=值 where 条件
2.查
select 列名 from 表名 where 条件
3.模糊查询
1. 模糊查询的关键字 like
2. 匹配的符号 % 匹配多个 _ 匹配一个
#查询第二个字为'想'的所有商品
SELECT * FROM product WHERE pname LIKE '_想%'
排序
order by 升序 asc 降序 desc
多个字段排序(未指定默认按升序(ASC)排列),直接在后面加字段就行,用逗号隔开
SELECT * FROM students st ORDER BY st.sAge DESC, st.sGrade DESC; //先按年龄降序,年龄相同再按年级降序
limit分页 查询第一条与第二条数据
SELECT * FROM product LIMIT 0,2 //第一页 每页显示两条数据
去重
SELECT DISTINCT price FROM product
分组
SELECT category_name ,COUNT(1) FROM product GROUP BY category_name
HAVING category_name IS NOT NULL
一般分组之后需要用取最大最小函数min(id),max(id),count(1)或者 limit 1 ,dinstinct来对每个组只取一条数据
聚合函数count()
COUNT(列名) 会统计 不包括null值的所有符合条件的字段的条数
COUNT( * )会统计 包括null值的所有符合条件的字段的条数
count(1)会统计 包括null值的所有符合条件的字段的条数
count(1) 的查询速度比COUNT( * )快
多表查询
select * from 表名 where 条件
直接英翻中 选择筛选 列名,列名… 从 表名,表名… 当 什么条件时
列名…就是显示的结果表的列名
表名 就是从哪张表中查询 ,如果表中没有相应列名就会报错,结果表显示不出来,子查询无连接表的功能
用where 时,表名… 中的多张表会连接起来,只要多张表有的列名都可以在结果表显示出来,不报错
连接表功能的语句还有 INNER JION 内连接
左连接 LEFT JOIN 表名 ON 条件 右连接 RIGHT JOIN 表名 ON 条件
子查询 IN() 就没有连接表的功能,只是通过逻辑连接的外键 在 from紧接的表名 中需要筛选的列进行提前筛选一次
A.一个子查询的结果当做另一查询语句条件使用 B.一个查询语句的结果当前另一个查询语
句的列或者表来使用
第一种体现
查询研发部门下所有的员工
SELECT * FROM emp e WHERE e.did
IN(SELECT d.did FROM dept d WHERE d.dname=“研发部门” )
第二种体现
查询出所有员工的信息 以及部门的名称
SELECT e.*,(SELECT d.dname FROM dept d WHERE d.did=e.did) AS dname FROM
emp e
where 字段名 not in (结果集) 即字段名不在这个结果集里,in 和not in 都是直接用,没有 is not in
select customers.name as 'Customers'
from customers
where customers.id not in
(
select customerid from orders
);
作者:力扣 (LeetCode)
链接:https://leetcode.cn/problems/customers-who-never-order/solutions/3566/cong-bu-ding-gou-de-ke-hu-by-leetcode/
用左连接,右表id为null,即左表id 不在右表id结果集里
select c.Name as Customers
from Customers as c
left join Orders as o on c.Id = o.CustomerId
where o.Id is null
笛卡尔积以及多表连接的原理
数据库的连接(内连接,外连接,笛卡尔积)
所用的表为student表和score表
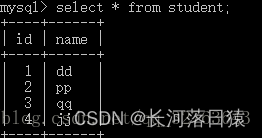

- 内连接
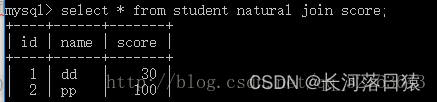
1.1 自然连接
自然连接只考虑属性相同的元组对。在本例中考虑的就是id,所以的到的结果如下
1.2 等值连接
内连接,又叫等值连接,顾名思义只有两张表中匹配的数据才会发生连接,即只保留相等的数据
select * from student inner join score on student.id =score.id
select * from student join score on student.id =score.id -- MySQL的join默认为inner jion
/* 对应的where语句 */
select * from student,score where student.id =score.id
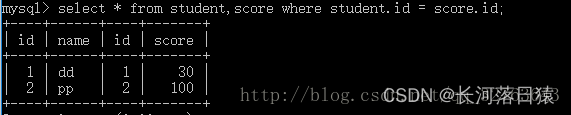
-
外连接
2.1 左外连接
以第一个关系为主,在第二个关系中找到满足条件的元素,并把他们连接起来,如果没有对应的元素,则在相应位置上的值为nullselect * from 左表 left或right join 右表 on 条件 即只保留左表数据,横向扩充字段,将右表部分的数据添加过来,没有则填充null
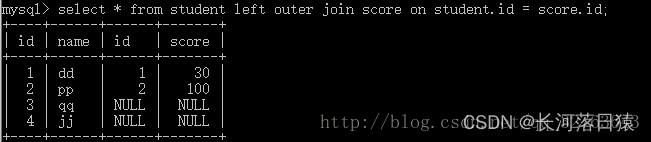
2.2 右外连接
和左外连接一样,右外连接找到满足条件的元素进行连接,不同的只是关系的位置而已,
select * from 左表 right join 右表 on 条件
即只保留右表数据,横向扩充字段,将左表部分的数据添加过来,没有则填充null

2.3 全外连接
全外连接是左外连接和右外连接的组合。简单说就是将左外连接和右外连接同时做多一次。做在mysql中没有全连接运算,但是根据全连接的定义,我们可以写成左外连接和右外连接组合起来。如下图所示
左连接的结果集 和右连接的结果集,同时去重
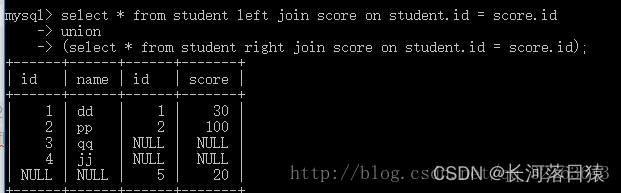
- 笛卡尔积
笛卡尔积原本是代数的概念,他的意思是对于两个不同的集合A,B。对于A中的每一个元素,都有对于在B中的所有元素做连接运算 。可以见得对于两个元组分别为m,n的表。笛卡尔积后得到的元组个数为m x n个元组。而对于mysql来说,默认的连接就是笛卡尔积连接。
左表所有数据都要连接右边所有数据,基本要杜绝这种情况,因为数据多了,笛卡尔积连接会造成更多数据,效率低。
如下图中,select * from 左表,右表
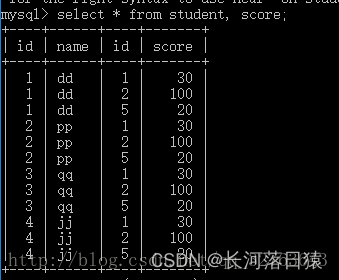
参考原文链接:http://t.csdn.cn/IhfFM
null空值比较
带null的列无法与值做比较,需要先把null转为0,或者加上 or 字段名 is null这个条件
ifnull(referee_id,0),校验规则,如果是空就返回0,不是空就返回原值
!= 只能比较值,不能比较 null
<> 等于 !=
不能写 = null 要用 is null 或者 is not null
查找包含null 结果集可以用子查询 not in 相当于取补集
select name from customer
where id not in (select id from customer where referee_id=2)
<=>
<=> 只用于MySQL数据库(不推荐使用),相当于is 和 = 的两者兼顾,只用 =,不会得到值为null 的数据,用is 不能比较具体值
字段名 <=> 值 等价于 字段名 = 值 or 字段名 is null
字段名 <=> null 等价于 字段名 is null
not 字段名 <=> null 等价于 字段名 is not null
not 字段名 <=> 值 等价于 字段名 != 值 or 字段名 is null
SELECT name
FROM customer
WHERE NOT referee_id <=> 2;
unino 联合,连接子查询,union all
都是取结果的并集,unino 类似于where 后的or,但union 效率略高于or
1、union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;会对获取的结果进行排序操作
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;不会对获取的结果进行排序操作
例子
1、union看到结果中ID=3的只有一条
select * from student2 where id < 4
union
select * from student2 where id > 2 and id < 6
2、union all 结果中ID=3的结果有两个
select * from student2 where id < 4
union all
select * from student2 where id > 2 and id < 6
union all只是合并查询结果,并不会进行去重和排序操作,在没有去重的前提下,使用union all的执行效率要比union高
力扣小妙招:可以巧妙的先union,左连接或右连接 将数据结合起来,再进行筛选
union all 的去重和排序
select
employee_id
from
(
select employee_id from employees
union all
select employee_id from salaries
) as t
group by
employee_id
having
count(employee_id) = 1
order by
employee_id;
作者:int_64
链接:https://leetcode.cn/problems/employees-with-missing-information/solutions/1373507/by-jam007-0731/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
union all 与全外连接不同,全外连接用了左连接 union 右连接, 数据表会横向扩充(左右连接),纵向扩充(union)并去重,
union all 不会去重和排序,但是通过
group by
employee_id
having
count(employee_id) = 1
order by
employee_id;
实现了去重排序,操作就是
通过 employee_id 来分组,筛选出 分组后count(employee_id ) 相等的只有一个结果,在根据employee_id 升序排序
分组gruop by ,having 具体的效果与应用
例子
Employees 表和Salaries 表

union all 取并集后 即表 纵向添加数据
select employee_id from (select employee_id from employees union all select employee_id from salaries) as t

分组之后
select employee_id from (select employee_id from employees union all select employee_id from salaries) as t
group by employee_id
此时表重复的数据被聚合了,只显示不重复的

select employee_id,count(employee) as "该组的聚合数"from (select employee_id from employees union all select employee_id from salaries) as t
group by employee_id
使用group by 分组后,聚合函数就是对每个分组的结果集进行计算,未使用分组,聚合函数则是对所有结果集进行计算

select employee_id from (select employee_id from employees union all select employee_id from salaries) as t
group by employee_id
having count(employee_id) =1
having 即筛选条件,筛选出分组之后聚合数为1 的结果集
最后在加上order by employee_id 就是想要的结果了

聚合函数与分组 group的纠葛
- MySQL(5.7 ) 官方文档中给出的聚合函数列表(图片)如下:
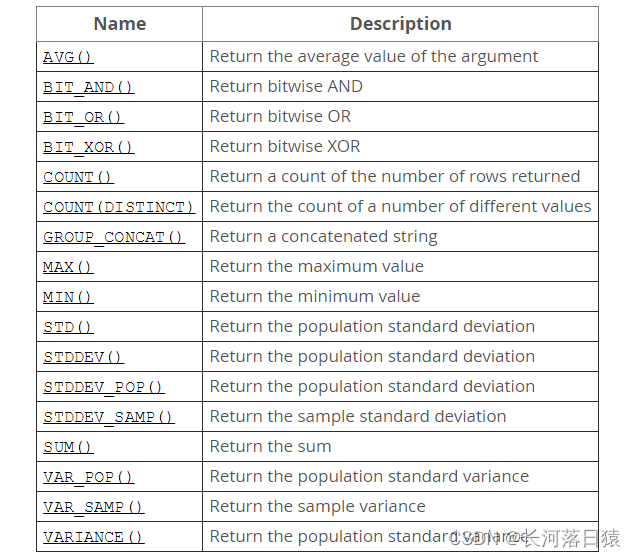
-
总结
-
使用group by 分组后,聚合函数就是对每个分组的结果集进行计算,未使用分组,聚合函数则是对所有结果集进行计算
-
分组查询的结果相当于去重,但并没有删除数据
-
sum(),avg(),min(),max()只能对数字类型的字段使用,count()则是所有类型的字段
-
使用HAVING对分组后的结果进行查询限定,限定的条件只能为聚合列,聚合列指的是在 SELECT 列 (SELECT list)中使用聚合函数产生的列,也可以是分组的列(group by 列名),要对非聚合列限定,需在分组前使用where 条件限定
-
使用group by 分组后,其最前面的SELECT 列 (SELECT 列名1,列名2) 只能是 分组的列(group by 列名)和使用聚合函数产生的列
-
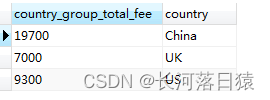
使用group by 多个字段分组,结果是先根据第一字段分组,在对分组后的结果进行第二字段分组,如对国家和性别分组,对国家分组,有3条数据,之后再对国家分组里的性别分组,有3*2 条数据
#对国家分组
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country
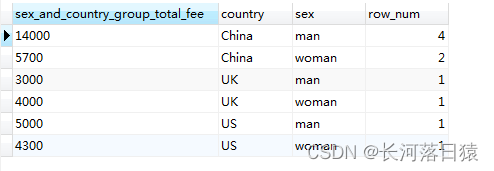
#多分组字段分组,并统计每组个数
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex, COUNT(*) AS row_num FROM member GROUP BY country, sex
结果如下:
**
** -
分组后可以使用order by 排序,可以使用limit 选取其中前几条数据
参考原文链接:https://blog.csdn.net/weixin_39878760/article/details/113164130
-
distinct 去重
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZaEYawre-1670055629976)(SQL 专项笔记/d419c8907f0bb06ff2e9d50dbd1129cc.jpeg)]](https://img-blog.csdnimg.cn/af3fe494d1b54b0d948bba5330040eae.png)
单列去重
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n6MnrngI-1670055629977)(SQL 专项笔记/c51c97b14854606056354996c93c6047.jpeg)]](https://img-blog.csdnimg.cn/41413e5d38544f6dab10122f188951dc.png)
多列去重
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cmEyZAr0-1670055629978)(SQL 专项笔记/f46e4d0ca3a46531b5e32855172541fc.jpeg)]](https://img-blog.csdnimg.cn/3ddfd2e3f2dd465cac9a611ac7632df3.png)
distinct去重后使用count,是计算去重后结果的总数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yRKexXPc-1670055629979)(SQL 专项笔记/f85540bdb633460fdf1db12156c45c90.jpeg)]](https://img-blog.csdnimg.cn/32af5c2b3735481cbe9990d9e3873b73.png)
与 distinct 相比 group by 可以显示更多的列,而 distinct 只能展示去重的列
distinct是取不同的值,通过对数据两两进行比较,最终去掉重复的值,单reduce执行,group by 是分组,多reduce执行
建议用group by
if函数和case when
if(条件表达式,结果一,结果二) as 字段名 ,相当于三目运算符 即这个字段名的值先通过条件表达式判断,为真,值就是结果一,假就是结果二
case when 条件表达式 then 结果一 else 结果二 end as 字段名
select employee_id, if(employee_id % 2 =1 and left(name,1) !='M',salary,0) as bonus from employees order by employee_id
其中 left(name,1) != 'M' 等价于 name not like 'M%'
employee_id % 2 =1 等价于 mod(employee_id, 2)=1
select
employee_id,
case when employee_id % 2 = 1 and left(name, 1) <> 'M' then salary else 0 end as bonus
from Employees
order by employee_id asc;
多条件多情况可以用 多个union ,case when 表达式一 then 结果一 when 表达式二 then 结果二 else 结果三 end , if(表达式一,结果一,if(表达式二,结果二,结果三))
SELECT
id AS `Id`,
CASE
WHEN tree.id = (SELECT atree.id FROM tree atree WHERE atree.p_id IS NULL)
THEN 'Root'
WHEN tree.id IN (SELECT atree.p_id FROM tree atree)
THEN 'Inner'
ELSE 'Leaf'
END AS Type
FROM
tree
ORDER BY `Id`
;
SELECT
atree.id,
IF(ISNULL(atree.p_id),
'Root',
IF(atree.id IN (SELECT p_id FROM tree), 'Inner','Leaf')) Type
FROM
tree atree
ORDER BY atree.id
SELECT
id, 'Root' AS Type
FROM
tree
WHERE
p_id IS NULL
UNION
SELECT
id, 'Leaf' AS Type
FROM
tree
WHERE
id NOT IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
UNION
SELECT
id, 'Inner' AS Type
FROM
tree
WHERE
id IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
ORDER BY id;
作者:力扣 (LeetCode)
链接:https://leetcode.cn/problems/tree-node/solutions/23160/shu-jie-dian-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Limit 和offset
1、当 limit后面跟一个参数的时候,该参数表示要取的数据的数量
例如 select* from user limit 3 表示直接取前三条数据
2、当limit后面跟两个参数的时候,第一个数表示要跳过的数量,后一位表示要取的数量,例如
select * from user limit 1,3;
就是跳过1条数据,从第2条数据开始取,取3条数据,也就是取2,3,4三条数据
3、当 limit和offset组合使用的时候,limit后面只能有一个参数,表示要取的的数量,offset表示要跳过的数量 。
例如select * from user limit 3 offset 1;表示跳过1条数据,从第2条数据开始取,取3条数据,也就是取2,3,4三条数据
IFNULL(值,null) as 列名 ,若值不为空,则value 为值,为空则value 为null
截取字符串函数
left(name, 1),right(name,lenth(name)-1)
一般不会用到实际开发中,只是力扣,牛客这样的题目会需要,实际开发都会把一些具体操作在service层解决
行转列用case…when或if分类讨论, group by进行分组。 列转行用union或union all将多列的字段整合到一行。
行转列用groupby+sum/或max/min+if,列转行用union all
1、列转行
SELECT product_id, ‘store1’ store, store1 price FROM products WHERE store1 IS NOT NULL
UNION
SELECT product_id, ‘store2’ store, store2 price FROM products WHERE store2 IS NOT NULL
UNION
SELECT product_id, ‘store3’ store, store3 price FROM products WHERE store3 IS NOT NULL;
其中 select ’ 值’ (as) 列名1, 列名2 (as) 新列名2 from … 第一个as 是将值作为这个列名1 的所有值,第二个as 是将列明2 取别名为新列名2
单引号括起来的是值,双引号括起来的一般是中文字符串当作列名或者值,单引号和双引号区别不大,看所处位置
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NOYScaj6-1670055629980)(SQL 专项笔记/1658455815-YlCygp-原图.png)]](https://img-blog.csdnimg.cn/a636a001b9c54f8b8b8ffc2ae6b60e87.png)
2、行转列
SELECT
product_id,
SUM(IF(store = ‘store1’, price, NULL)) ‘store1’,
SUM(IF(store = ‘store2’, price, NULL)) ‘store2’,
SUM(IF(store = ‘store3’, price, NULL)) ‘store3’
FROM
Products1
GROUP BY product_id ;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qMaJmyjC-1670055629982)(SQL 专项笔记/1658455824-fvVcVb-转换后.png)]](https://img-blog.csdnimg.cn/d2f1caeda07b424f9de61f86d70b47da.png)
作者:Strive
链接:https://leetcode.cn/problems/rearrange-products-table/solutions/1688814/by-esqiimulme-pjiy/








![[附源码]计算机毕业设计学习帮扶网站设计与实现Springboot程序](https://img-blog.csdnimg.cn/6659184590f6482a83fb0c58a04a9e83.png)