目录
- Hbase 架构
- Client
- ZooKeeper
- Master
- RegionServer
- HRegion
- Store
- MemStore
- StoreFile
- HFile
- HLog
- Hbase数据模型
- 关于数据模型的其他概念
- Name Space
- Table
- Row
- Column
- Time Stamp
- Cell
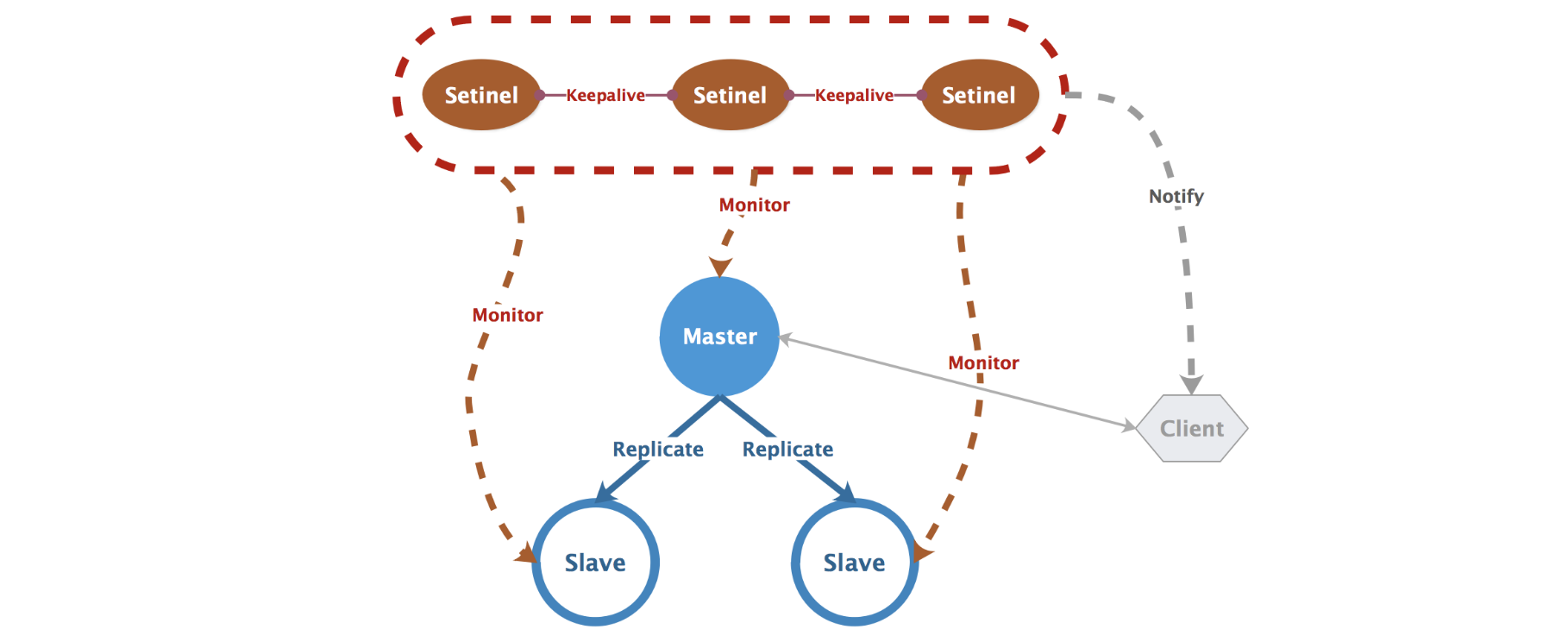
Hbase 架构

Client
(1).META.表,记录了用户所有表拆分出来的 Region 的映射信息,.META.可以有多个Region。
(2)-ROOT- 表,记录了 .META. 表的 Region 信息,-ROOT- 自身只有一个 Region,无论如何不会分裂。
Client 访问用户数据前需要首先访问ZK,找到 -ROOT- 表的 Region 所在的位置,然后访问 -ROOT- 表,接着访问 .META. 表,最后找到具体的数据的位置。
ZooKeeper
(1)为 HBase 提供 Failover 机制,选举 Master ,避免 Master 单点故障。
(2)存储所有 Region 的寻址入口:-ROOT- 表在哪台服务器上。-ROOT- 这张表的位置信息。
(3)实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master 。
(4)存储 HBase 的 schema,包括有哪些 table,每个table有哪些Column Family。
Master
(1)为 RegionServer 分配 Region。
(2)负责 RegionServer 的负载均衡。
(3)发现失效的 RegionServer 并重新分配其中的 Region。
(4)HDFS 上的垃圾文件(HBase)回收。
(5)处理 schema 更新请求(表的创建,删除,修改,列簇的增加等等)。
RegionServer
(1)RegionServer 维护Master分配给它的 Region,处理对这些 Region 的 IO 请求。
(2)RegionServer 负责切割变得过大的 Region,负责 Compact 操作。
(3)Client 访问 HBase 上的数据的过程并不需要 master(寻址时访问的是 zookeeper 和 RegionServer,数据读写访问的是 RegionServer)。Master 仅仅维护 Table 和 Region 的元数据信息,负载很低。
(4).META.存的是所有 Region 的位置信息,那么 RegionServer 当中 Region 在进行分裂之后产生的心 Region,由 master 决定发到哪个 RegionServer,这意味着,只有 Master 知道新的 Region 的位置信息,所以由 Master 来管理 .META. 这个表中数据的 CRUD。
HRegion
(1)table 在行的方向上分割为多个 Region。Region 是 HBase 中分布式存储和负载均衡的最小单元,即不同的 region 可以分别在不同的 RegionServer 上,但同一个 Region 不会拆分到多个 server 上。
(2)随着 Region 不断增大,某个列族达到一个阈值时,就会分成两个新的 Region。
(3)每个 Region 由以下信息标识:<表名,startRowkey,创建时间>,再由(-ROOT-和.META.)记录该region的endRowkey。
Store
每一个 Region 由一个或多个 Store 组成,至少是一个 store,hbase 会把一起访问的数据放在一个 store 里面,即为每个 ColumnFamily 建一个 store,如果有几个 ColumnFamily,就有几个 store。一个 store 由一个 memStore 和多个 StoreFile 组成。HBase 以 store 的大小来判断是否需要切分 Region。
MemStore
memStore 是放在内存里的,用于保存修改的数据。当 memStore 的大小达到一个阈值(默认128M)时,memStore 会被 flush 到文件,即生成一个快照。
StoreFile
memStore 内存中的数据写到文件后就是 StoreFile,StoreFile 底层是以 HFile 的格式保存
HFile
HBase中Key - Value数据的存储格式,HFile 是 Hadoop 的二进制格式文件,实际上 StoreFile 就是对 Hfile 做了轻量级包装,即 StoreFile 底层就是 HFile
HLog
用于做灾难恢复,HLog记录数据的所有变更,一旦 RegionServer 宕机,就可以从 Log 中进行恢复。
Hbase数据模型
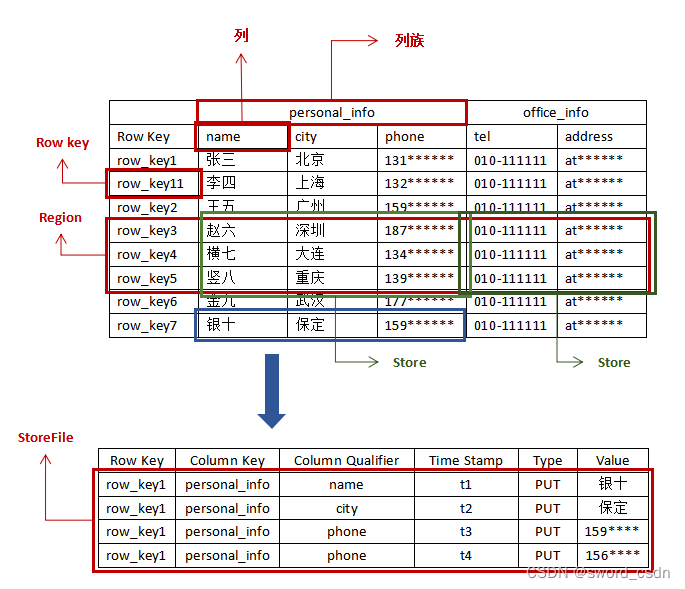
每个store是以行为单位进行列式存储,如图蓝色标识出来的数据,它每一列的数据都会按照[Row Key,Column Key,Column Qualifier,Time Stamp,Type,Value]的方式被存成一行。
Hbase的底层依赖HDFS,而HDFS不支持修改,那我们怎么修改呢?实际上是假修改,实际是新增了一行,比如上图的phone,只是时间戳变了,我们读的时候读最新的时间戳的数据。
关于数据模型的其他概念
Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是Hbase内置的表,default表是用户默认使用的命名空间
Table
类似于关系型数据库的表概念。Hbase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
Row
Hbase表中的每行数据由一个RowKey和多个Column组成,数据是按照RowKey的字典顺序存储的,查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要,HBase支持3中查询方式:1、基于Rowkey的单行查询;2、基于Rowkey的范围扫描;3、全表扫描。
Column
Hbase中的每个列都由Column Family(列族)和Column Qualifier(列限定符,就是列名)进行限定。
Time Stamp
用于标识数据的不同版本(Version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间,我们修改后读的最新数据就是通过时间戳确定。
Cell
由<rowkey,column family,column qualifier,time stamp>唯一确定的单元。cell中的数据全部是字节码形式存储。