文章目录
- 一. 问题描述
- 二. 解决方案
- 2.1 收集统计信息
- 2.2 并行
- 2.3 autovacuum
- 2.3 统计信息读取
- 参考:
一. 问题描述
前端页面需要分页展示,经常需要查询总数,然后做分页展示。
遇到的问题是,第一次执行会很慢,6秒左右,如果间隔时间段第二次执行,因为缓存了第一次的数据,所以查询很快。
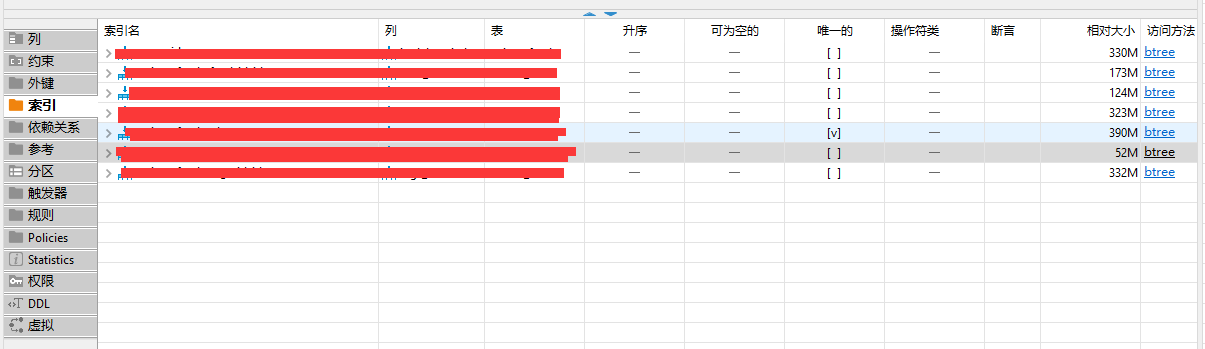
表的总行数才56W左右,而且有主键索引
表总数据量21GB
主键索引数据量390M
最小的索引数据量52M

二. 解决方案
领导是做开发出身的,习惯的是redis、Elastic、StarRocks、ClickHouse之类的数据库,这类数据库的count() 都是非常快的,完全理解不了,为什么一个几十万的count() 查询需要 六七秒,甚至更久。
首先想到的是网上看一看,原来有好多大佬已经遇到过类似的问题了。
2.1 收集统计信息
analy tablename;
统计信息收集速度还比较快,大概3秒钟左右。然而收集完成后,问题依旧。
2.2 并行
count(*) 操作较为简单,既然资源足够,完全可以开更多的并行来协助解决这个问题。
show max_parallel_workers;
show max_parallel_workers_per_gather ;
原来默认已经开了2个并行了
set max_parallel_workers=10
set max_parallel_workers_per_gather=10;
alter table table_name set (parallel_workers =4);
alter table table_name set (parallel_workers =6);
select pg_sleep(300);
将并行度调整为4和6,分别看看执行情况。
因为数据量不大,并行度为4的运行速度在2秒左右,并行度为6的运行速度在10秒左右。
顾此处考虑将并行度调整为4
2.3 autovacuum
对于count(*) 操作,完全可以借助索引,因为索引占的空间比表小太多,那么几十M的索引扫描起来为什么那么慢呢?
尝试扫描一个小的索引而不是整个表来计算行数是很好的一个解决方案。然而,由于PostgreSQL的多版本并发控制策略,这并不是那么简单。每个行版本(“元组”)均包含可见的数据库快照的信息。但是,此信息未(冗余地)存储在索引中。因此,通常不足以对索引中的条目进行计数,因为PostgreSQL必须访问表条目(“堆元组”)以确保索引条目可见。为了缓解这个问题,PostgreSQL引入了可见性映射(visibility map),这是一种数据结构,用于存储每个人是否都可以看到表块中的所有元组。如果大多数表块都是可见的,则索引扫描不需要经常访问堆元组来确定可见性。这样的索引扫描称为“仅索引扫描”,因此会更快地扫描索引以对行进行计数。现在是VACUUM维护了可见性映射,所以如果你想使用索引来加速count(*),请确保autovacuum在表上运行得足够频繁。
psql -h hostname -U dbname
\timing
ALTER TABLE table_name SET (
autovacuum_vacuum_scale_factor = 0,
autovacuum_analyze_scale_factor = 0,
autovacuum_vacuum_threshold = 1000,
autovacuum_analyze_threshold = 1000);
select count(*) from table_name;
select pg_sleep(300);
select count(*) from table_name;
select pg_sleep(300);
select count(*) from table_name;
select pg_sleep(300);
select count(*) from table_name;
select pg_sleep(300);
select count(*) from table_name;
开启4个并行,并调整参数后,我进行了5次测试,以示公平,每次测试后,休眠5分钟
从结果可以看,执行的时间在1秒左右
2.3 统计信息读取
如果要求不那么准确,可以直接从统计信息中读取
SELECT reltuples::bigint
FROM pg_catalog.pg_class
WHERE relname = 'mytable';
我测试了下,未收集统计信息之前,表行数不准,大概是2倍的差距。
手工收集了统计信息之后,也存在一定的差距。
目前1秒钟可以出结果,没必要冒这个风险了。
参考:
- https://www.modb.pro/db/617661
- https://dba.stackexchange.com/questions/245990/postgresql-extremely-slow-count-with-index-simple-query