目录
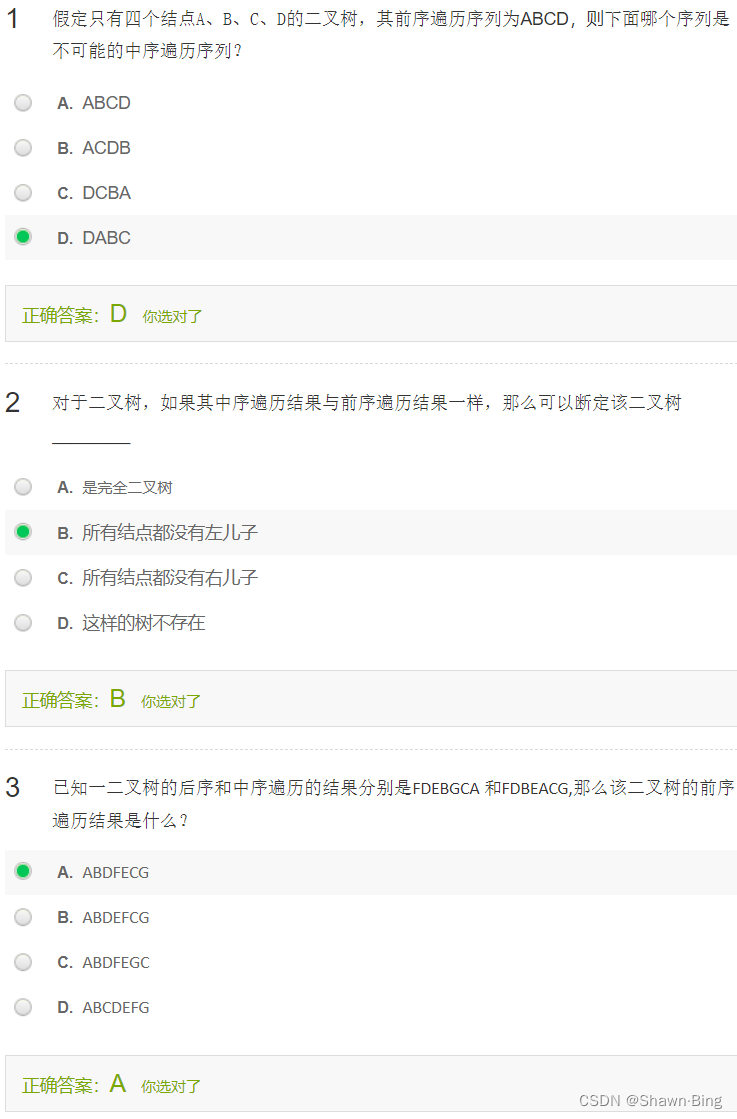
3.3.1 遍历(先中后)
二叉树的遍历
先序遍历:
中序遍历
后序遍历
tips:
3.3.2 中序非递归遍历
非递归算法实现的基本思路:使用堆栈
中序遍历的非递归算法具体实现方法为:
3.3.3 层序遍历
难点
解决方法:
队列实现
思路
有如下二叉树作为例子:
遍历过程:(出队即printf)
思考:
3.3.4 遍历应用例子
1. 输出二叉树中的叶子结点
2. 求二叉树高度
3. 二元运算表达式树及其遍历
4. 由两种遍历序列确定二叉树
3.3.1 遍历(先中后)
二叉树的遍历
先序遍历:
遍历过程:
- 访问根结点
- 先序遍历其左子树(递归遍历,根结点左子树如果也有左右子树也要遍历)
- 先序遍历其右子树
既然需要递归遍历左右子树,我们设想以下如果直接用递归实现这个算法(伪码):
void PreOrderTraversal( BinTree BT )
{
if( BT ) {
printf(“%d”, BT->Data);
PreOrderTraversal( BT->Left );
PreOrderTraversal( BT->Right );
}
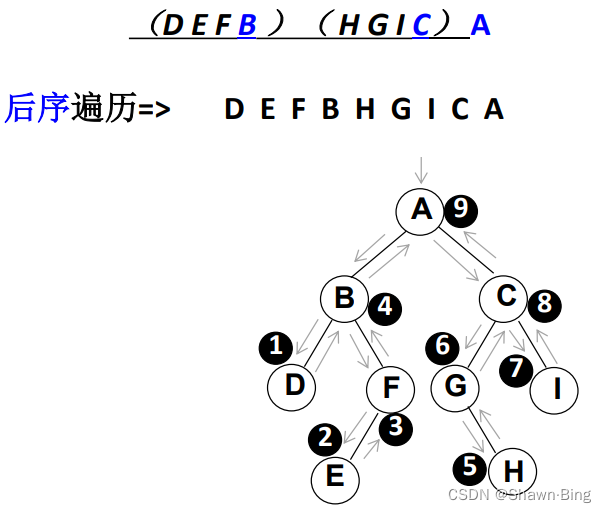
}若有二叉树为A(B(DF(E))C(G(H)I)),其先序遍历访问顺序为——A-B-D-F-E-C-G-H-I
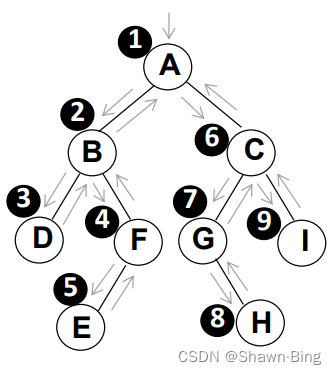
中序遍历
遍历过程:
- 先序遍历其左子树
- 访问根结点
- 先序遍历其右子树
代码就直接将Printf放到两次递归中间即可
void PreOrderTraversal( BinTree BT )
{
if( BT ) {
PreOrderTraversal( BT->Left );
printf(“%d”, BT->Data);
PreOrderTraversal( BT->Right );
}
}
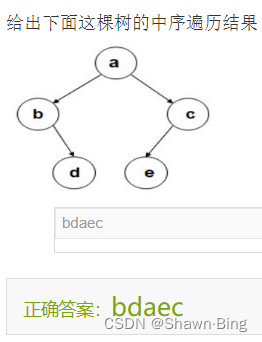
后序遍历
遍历过程:
- 先序遍历其右子树
- 访问根结点
- 先序遍历其左子树
void PostOrderTraversal( BinTree BT )
{
if( BT ) {
PostOrderTraversal( BT->Left );
PostOrderTraversal( BT->Right);
printf(“%d”, BT->Data);
}
} 
tips:
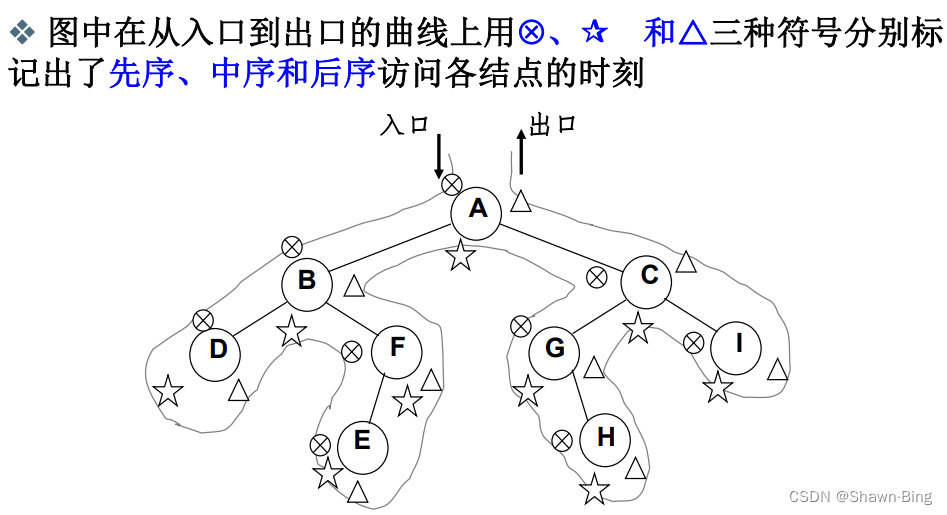
先序、中序和后序遍历过程:遍历过程中经过结点的路线一 样,只是访问各结点的时机不同。
3.3.2 中序非递归遍历
非递归算法实现的基本思路:使用堆栈
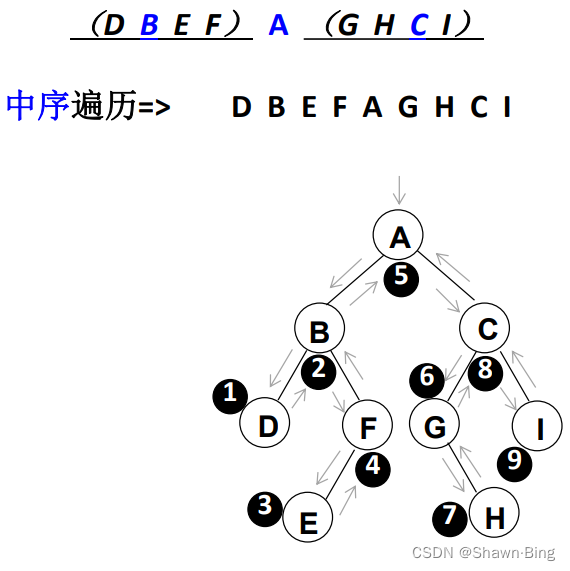
中序遍历是按左、根、右的顺序,所以以上一节的树为例:
- 在一开始遇到A,A有左子树,所以将A放入堆栈
- 下一个要处理的是A的左子树B,B也有左子树,所以再把B放到堆栈里
- 下一个是B的左子树D,D没有孩子,D放入堆栈后就要出栈了,随后B出栈。
- 此时B这棵树左、根都遍历完了,接下来处理右子树F。
- F有左子树,所以先把F放入堆栈
- F的左子树E没有孩子,E入栈然后出栈,F再出栈,最后A的左子树处理完毕,A也出栈
- 此时遍历顺序为DBEFA,接着处理A的右子树
- A的右子树C,C有左子树,存入栈,处理其左子树
- G没有左子树,所以先入栈后出栈
- G有右子树H(中序遍历顺序),H没有左子树,入栈后紧接着出栈
- 处理完C的左子树,C可以出栈
- C有右子树I,I没有左子树,入栈后紧接着出栈
- 最后遍历顺序即为:DBEFAGHCI
中序遍历的非递归算法具体实现方法为:
- 遇到一个结点就将其压入栈,并遍历其左子树(若有左子树的话),
- 当左子树遍历完毕,就从栈顶弹出这个结点并访问它
- 按结点右指针去遍历这个结点的右子树
void InOrderTraversal( BinTree BT )
{
BinTree T=BT;
Stack S = CreatStack( MaxSize ); /*创建并初始化堆栈S*/
while( T || !IsEmpty(S) ){
while(T){
/*一直向左并将沿途结点压入堆栈*/
Push(S,T);
T = T->Left;
}
if(!IsEmpty(S)){
T = Pop(S); /*结点弹出堆栈*/
printf(“%5d”, T->Data); /*(访问)打印结点*/
T = T->Right; /*转向右子树*/
}
}
}也可推知,先序遍历也能用非递归实现,修改printf位置即可
void PreOrderTraversal( BinTree BT )
{
BinTree T=BT;
Stack S = CreatStack( MaxSize ); /*创建并初始化堆栈S*/
while( T || !IsEmpty(S) ){
while(T){
/*一直向左并将沿途结点压入堆栈*/
Push(S,T);
printf(“%5d”, T->Data); /*第一次碰到就打印*/
T = T->Left;
}
if(!IsEmpty(S)){
T = Pop(S); /*结点弹出堆栈*/
T = T->Right; /*转向右子树*/
}
}
}但后序遍历不能简单挪动位置实现,因为后序遍历在操作完左右子树后需要返回到根结点,而且是在第三次经过根结点时将其pop出去,所以实现它需要用到两个堆栈
1. 初始化两个堆栈s1和s2,将根节点压入s1中。
2. 从s1中弹出栈顶节点,将其压入s2中。
3. 如果该节点有左子节点,则将左子节点压入s1中。
4. 如果该节点有右子节点,则将右子节点压入s1中。
5. 重复步骤2到步骤4,直到s1为空。
6. 从s2中依次弹出节点并输出,即可得到后序遍历序列。
void PostOrder(BinTree BT)
{
BinTree T = BT;
stack S = createstack();
while(T || IsEmpty(S)){
while(T){
push(S, T);
T = T->Left;
}
if(top(S)->Right != NULL){
T = top(S)->Right;
continue;
}
T = pop(S);
printf("%5d", T->data);
while(top(S)->Right == T){
T = pop(S);
printf("%5d", T->data);
}
T = top(S)->Right;
}3.3.3 层序遍历
难点
除了先中后序,我们还有一种遍历方式是层序遍历。二叉树是一个二维结构,而遍历的序列是一个线性结构,遍历二叉树的本质是将一个二维结构变成一维线性结构。
而难点在于,只有通过父结点才能访问到左右孩子结点,再通过子结点来访问子结点的左右孩子结点,因此如果变成线性结构,线性就意味着一个点只与另一个点有关,而子结点会有两个,当访问了一个子结点之后另一个子结点该怎么处理?
解决方法:
用一个存储结构来保存暂时不访问的结点。如堆栈、队列
队列实现
思路
遍历从根结点开始,首先将根结点入队,然后开始执行循环:
- 从队列中取出一个元素
- 访问该元素所指结点
- 若该元素所指结点的左、右孩子结点非空, 则将其左、右孩子的指针顺序入队。
有如下二叉树作为例子:
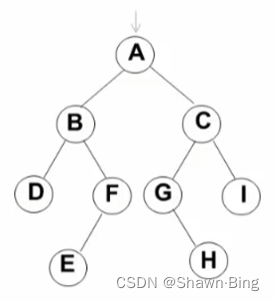
遍历过程:(出队即printf)
A入队,第一个元素为A,队列为A
A出队,将A的左右儿子BC入队,此时第一个元素为B,队列为BC
B出队,将B的左右儿子DF入队,此时第一个元素为C,队列为CDF
C出队,将C的左右儿子GI入队,此时第一个元素是D,队列为DFGI
D出队,D没有左右儿子,此时第一个元素是F,队列为FGI
F出队,将F的左儿子E入队,此时第一个元素是G,队列为GIE
G出队,将G的右儿子H入队,此时第一个元素是I,队列为IEH
I出队,EH都没有子结点,依次出队
出队顺序为:A B C D F G I E H,序列恰好是每一层的结点顺序
void LevelOrderTraversal ( BinTree BT )
{
Queue Q;
BinTree T;
if ( !BT ) return; /* 若是空树则直接返回 */
Q = CreatQueue( MaxSize ); /*创建并初始化队列Q*/
AddQ( Q, BT );
while ( !IsEmptyQ( Q ) ) {
//Step1
T = DeleteQ( Q );
//step2
printf(“%d\n”, T->Data); /*访问取出队列的结点*/
//Step3
if ( T->Left ) AddQ( Q, T->Left );
if ( T->Right ) AddQ( Q, T->Right );
}
}
思考:
若将层序遍历中的队列实现修改为堆栈实现,是否也是一种遍历方法?
是的,改为堆栈后一般称其为深度优先遍历,简单来说就是访问根结点,再依次访问其左右子树直到遍历完整棵树。
3.3.4 遍历应用例子
1. 输出二叉树中的叶子结点
思路:在遍历算法中加入一个“检测该结点左右子树是否都为空”,即可得知是否为叶子结点
//以前序遍历为例
void PreOrderPrintLeaves( BinTree BT )
{
if( BT ) {
//若左右子树为空,则打印结点
if ( !BT-Left && !BT->Right )
{
printf(“%d”, BT->Data );
}
PreOrderPrintLeaves ( BT->Left );
PreOrderPrintLeaves ( BT->Right );
}
}
2. 求二叉树高度
二叉树的总高度=左右子树的最大高度+1,因此要求二叉树总高度,需要先知道左右子树的高度。后序遍历的遍历顺序显然很符合这样的算法
int PostOrderGetHeight( BinTree BT )
{
int HL, HR, MaxH;
if( BT ) {
HL = PostOrderGetHeight(BT->Left); /*求左子树的深度*/
HR = PostOrderGetHeight(BT->Right); /*求右子树的深度*/
MaxH = (HL > HR)? HL : HR; /*取左右子树较大的深度*/
return ( MaxH + 1 ); /*返回树的深度*/
}
else return 0; /* 空树深度为0 */
}
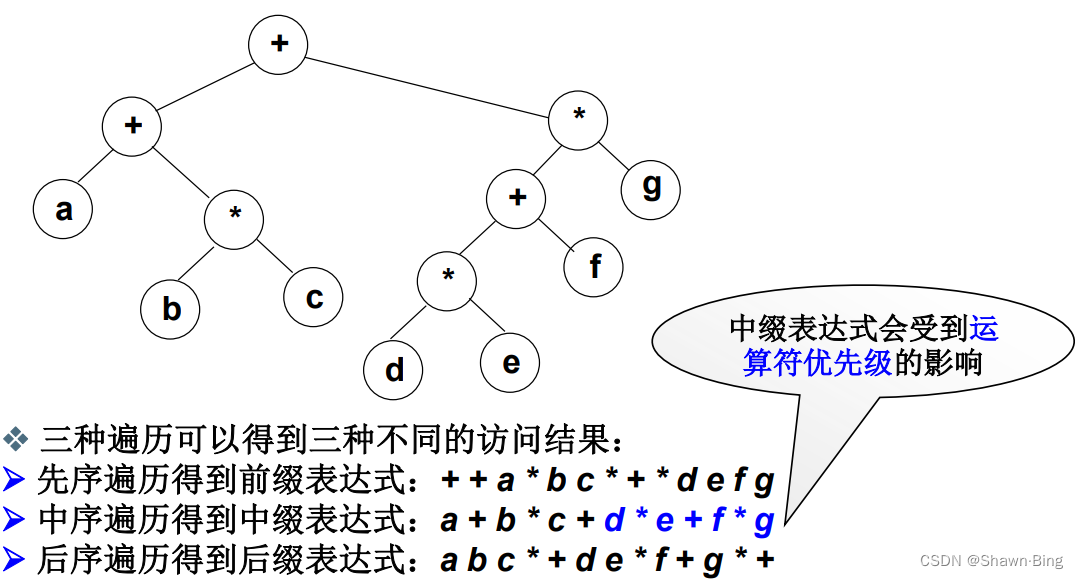
3. 二元运算表达式树及其遍历
如下表达式树,其作用是对左右两颗树做根结点运算
4. 由两种遍历序列确定二叉树
若已知三种遍历中的任意两种遍历序列,能否唯一确定一颗二叉树呢?
答案是不能,必须要知道中序遍历+其他任意遍历序列才行
若已知先序和中序遍历序列,如何确定一颗二叉树?
思路:已知先序第一个结点是根结点,只要在中序中找到一样的结点,就能在中序遍历序列中分割开左子树和右子树,再递归使用这个方法分解全部结点。