0、前言
近期学习redis相关原理,记录一下开发过程中Redis的一些常见问题及应对方法。
1、缓存穿透
一句话总结:先查redis发现没数据,再去数据库查发现还是没数据。
这种情况下缓存永远不会生效,数据库将承担巨大压力。
我们知道,redis的缓存作用,是在客户端发起查询请求时:
(1)先找redis,如果redis内命中数据则直接返回。
(2)如果未命中,则不得不去数据库中查询,把数据放到redis里,然后再返回数据给客户端。
对于缓存穿透的情况,例如多次恶意查询数据库和redis里都没有的数据,将给数据库带来巨大压力。
常见解决方法:
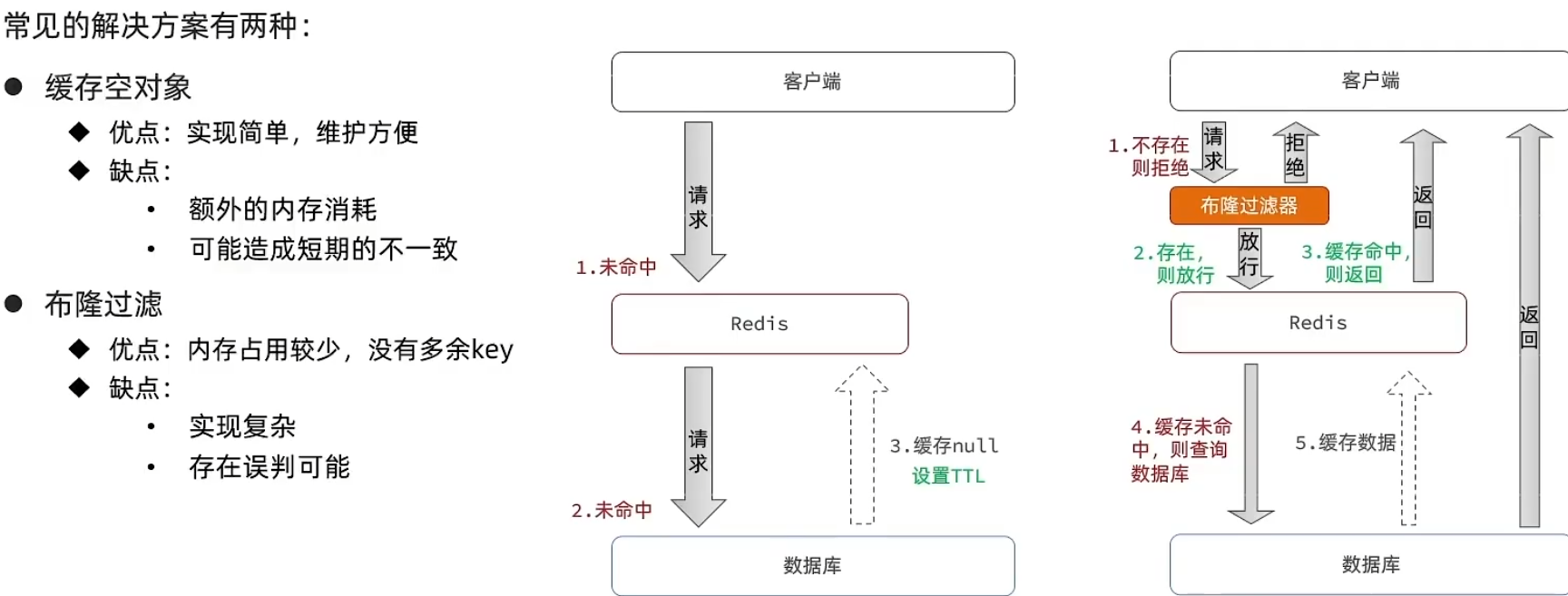
缓存空对象,就是发现数据库也没有这个数据的时候,缓存一个空值在redis里,那么下次这种访问就会从redis里返回null,而不会继续查询数据库了。
2. 缓存雪崩
一句话:大量的缓存key同时失效(比如同时过期了),或者redis服务宕机(redis寄了),导致大量请求直接给到数据库,压力过大寄了。
缓存雪崩,指的是大面积的 key 同时过期,导致大量并发打到我们的数据库。不像击穿,只是因为 1 个 key 的过期。所以,对于雪崩来说,一般少量的 key 失效,所带来的数据库的并发压力是不会太大的。而大量 key 的同时失效,导致所有 key 的并发加起来,会影响到我们的数据库。
那就算一个 key 失效,也会对数据库造成很大的影响,那么你把雪崩的所有 key 拆成一个一个 key 来看,也就是雪崩可以拆分成一个一个缓存击穿的集合。
其实在真实场景中,雪崩才是一个更容易发生的一个问题,它不像击穿那么极端,一个 key 就成千上万的并发,直接把数据库打垮了;而是,可能就一个 key 几十几百的并发,然后大量的 key 一过期,然后就使得好多并发,同时叠加起来,累积到上千上万个,把数据库打崩了。
解决方案
怕key同时失效,那就把缓存的TTL时间分散开, 比如在失效时间的基础上加上一个随机值。
针对redis宕机情况,可以进行Redis集群的布置,或者添加多级缓存,增强系统的容错性。
3、缓存击穿
概括:要查的key对应的数据是存在的(不像穿透,是不存在的数据),但redis里没有(比如过期了,这很常见),如果这个key的数据是热点数据,即可能会有大量并发请求。
这么多的并发请求都发现redis没有对应的数据,则都要去查数据库,这样一来将造成巨大压力。
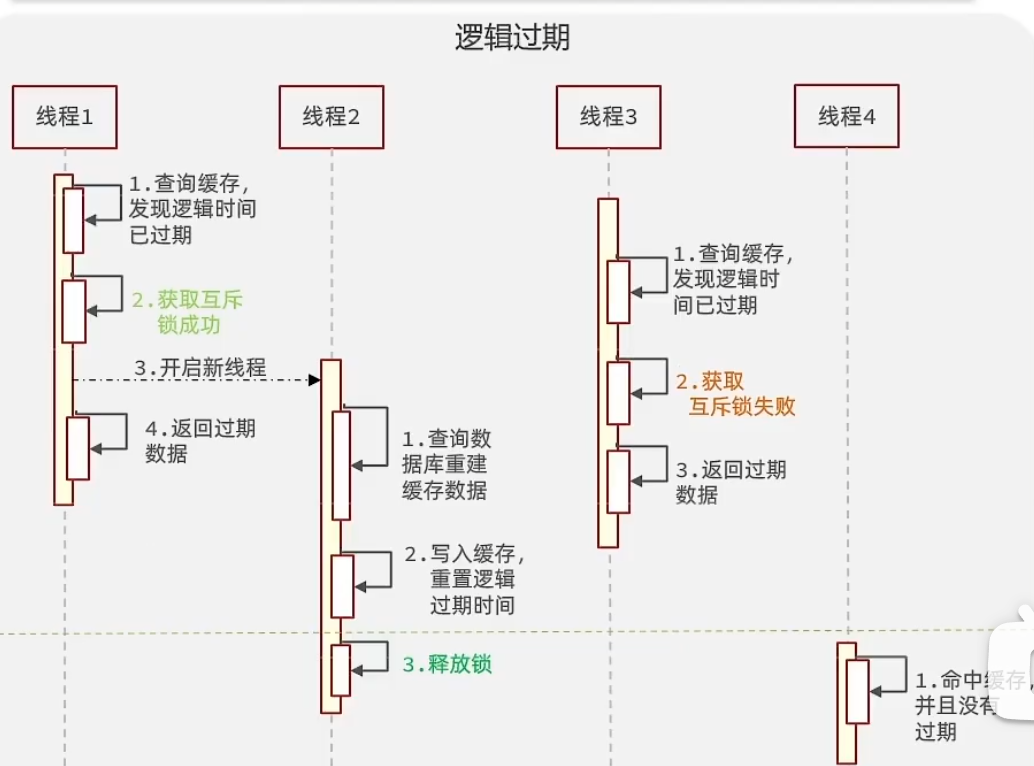
例如下图中,在线程1把数据写入缓存之前,其他多个并发线程都会去查数据库,这样将造成巨大的压力。
解决方案
有的人可能会觉得,热点key过期容易导致缓存击穿,那我们把它的存活时间设成永久不就好了?
这样肯定是不可以的,毕竟redis空间有限,不可能缓存那么多数据,而且“热点数据”也是会随时间变化的,也不可能把所有数据当成热点数据来缓存。
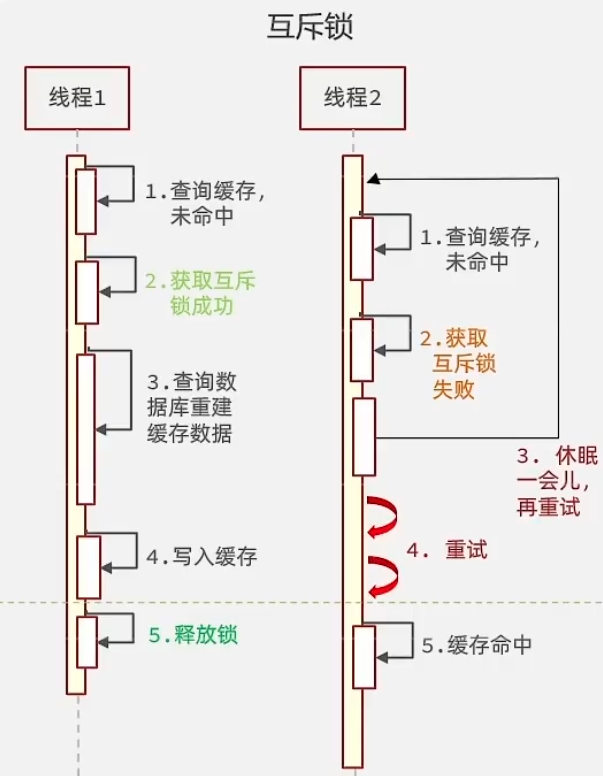
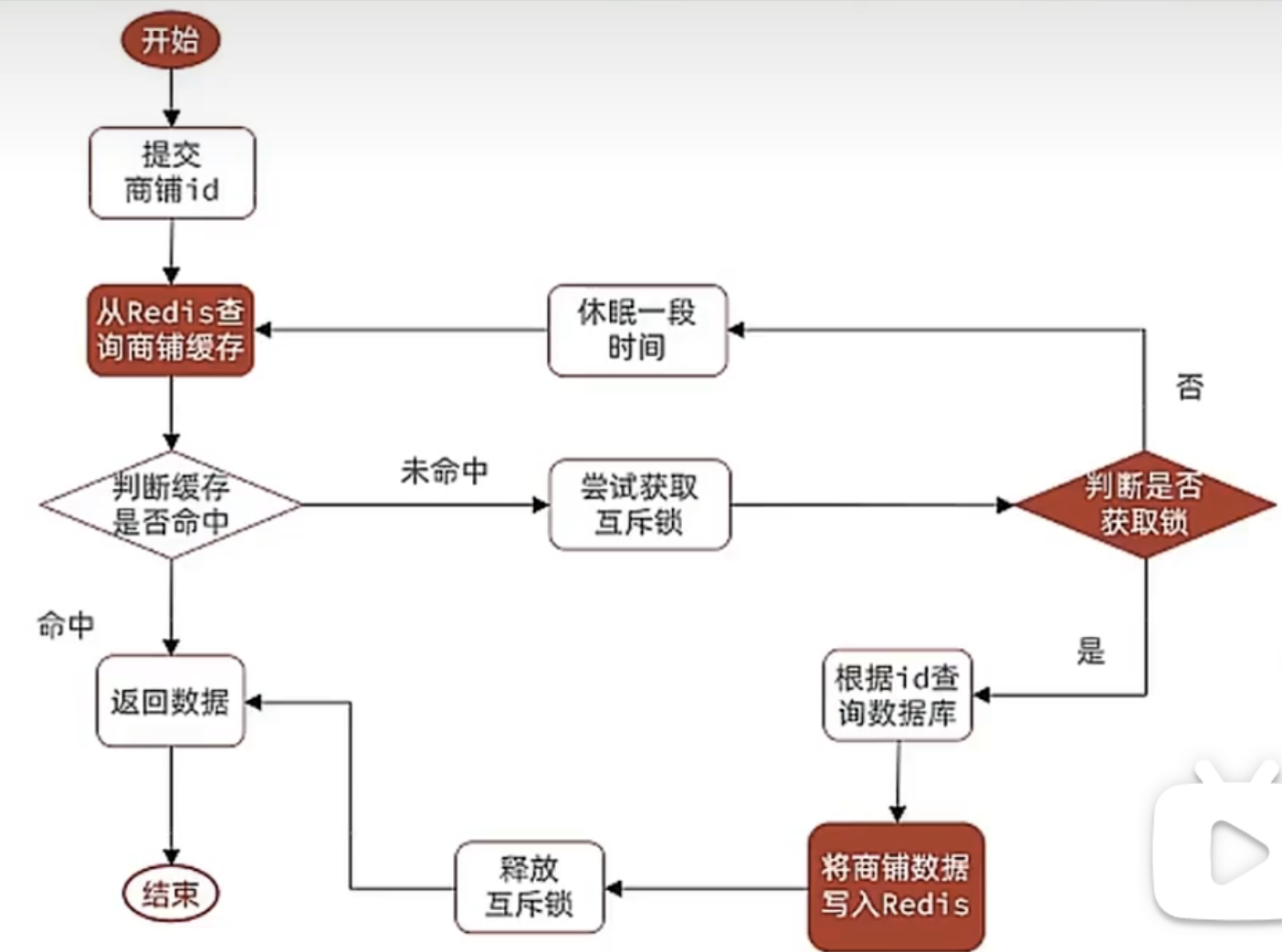
方案1:互斥锁(开发常用)
假设会有 1w 个并发来访问这个 key,那么它们就会先查询 redis,然后都发现,这个 key 不存在;然后,它们就会对应的,往 redis 用 setnx 设置一个 key,来表示这是一把锁;
这里介绍一下redis的setnx,该方法的作用可以标识锁,什么意思呢?
setnx的使用方法是这样的:
setnx key value如果key没有value,设置值成果。如果key已经有对应value,设置失败。
类似于我们的互斥。上锁就是赋值、释放锁就是删掉锁(del key即可)
一般会设置有效期,防止死锁。

该方法通过传入锁的id,返回一个布尔值,来模拟获取锁的过程。
然后,只有一个线程,会设置成功,然后去读取数据库,写回 redis;其他的 9999 个线程,则 sleep 一小会,然后再去访问我们的 redis。
有人看到这,首先会问,这个 sleep 要多久?
这个是要根据压测,以及线上环境进行调整的,一般会给出一个合适的值,也就是大约从数据库取出数据的时间。
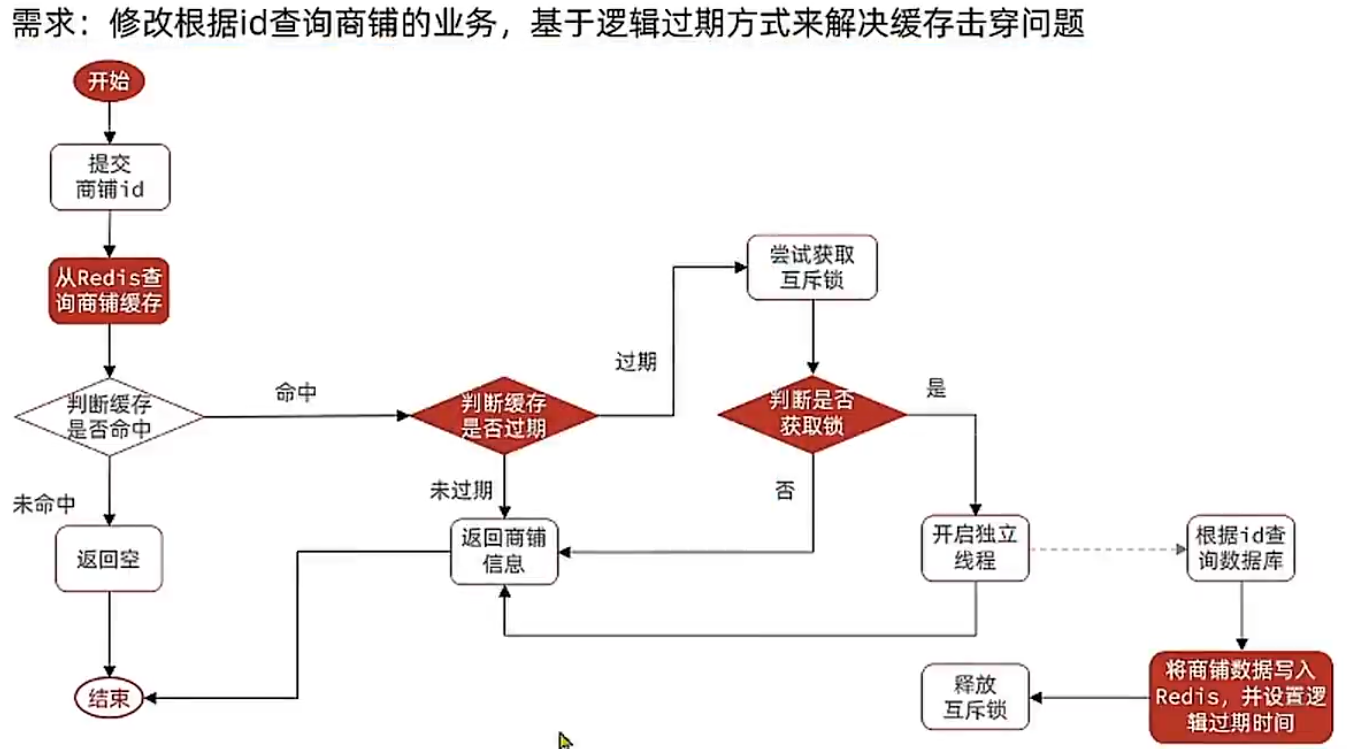
方案2:逻辑过期
这种情况,我们假设key不会过期,而是通过人为地设置”expire time“一个属性,来进行人为地判断数据是否过期(比如,热门商品,那就在活动期间把它变为不会过期地key,等活动过了以后在主动让他过期)。
中心思路就是,线程1抢到锁以后,将查数据库、返回缓存,这项比较耗时的任务交给别的线程(线程2)去做,然后多个并发线程就可以先返回过期的数据,等更新好了再返回新的。
这样避免了大量线程休眠等待的情况。