“TDengine除vnode分片之外,还对时序数据按照时间段进行分区。每个数据文件只包含一个时间段的时序数据,时间段的长度由DB的配置参数days决定。这种按时间段分区的方法还便于高效实现数据的保留策略,只要数据文件超过规定的天数(系统配置参数keep),将被自动删除。而且不同的时间段可以存放于不同的路径和存储介质,以便于大数据的冷热管理,实现多级存储。”
可以看出,时序数据的保留策略是由keep和days这两个参数牢牢把控的。但是,如果我们想更加深入地理解TDengine时序数据的存储逻辑,从而优化性能的话,只知道上面这些是不够的。
官方文档关于keep和days的描述是这样的:
keep:数据库中数据保留的天数,单位为天,默认值:3650
days:一个数据文件存储数据的时间跨度,单位为天,默认值:10
TDengine通过keep和days严格控制插入数据的时间戳范围:对于过去的数据,不可以超出当前时间减去keep的时间戳值;对于未来的数据,不可以超出当前时间加上days的时间戳值。
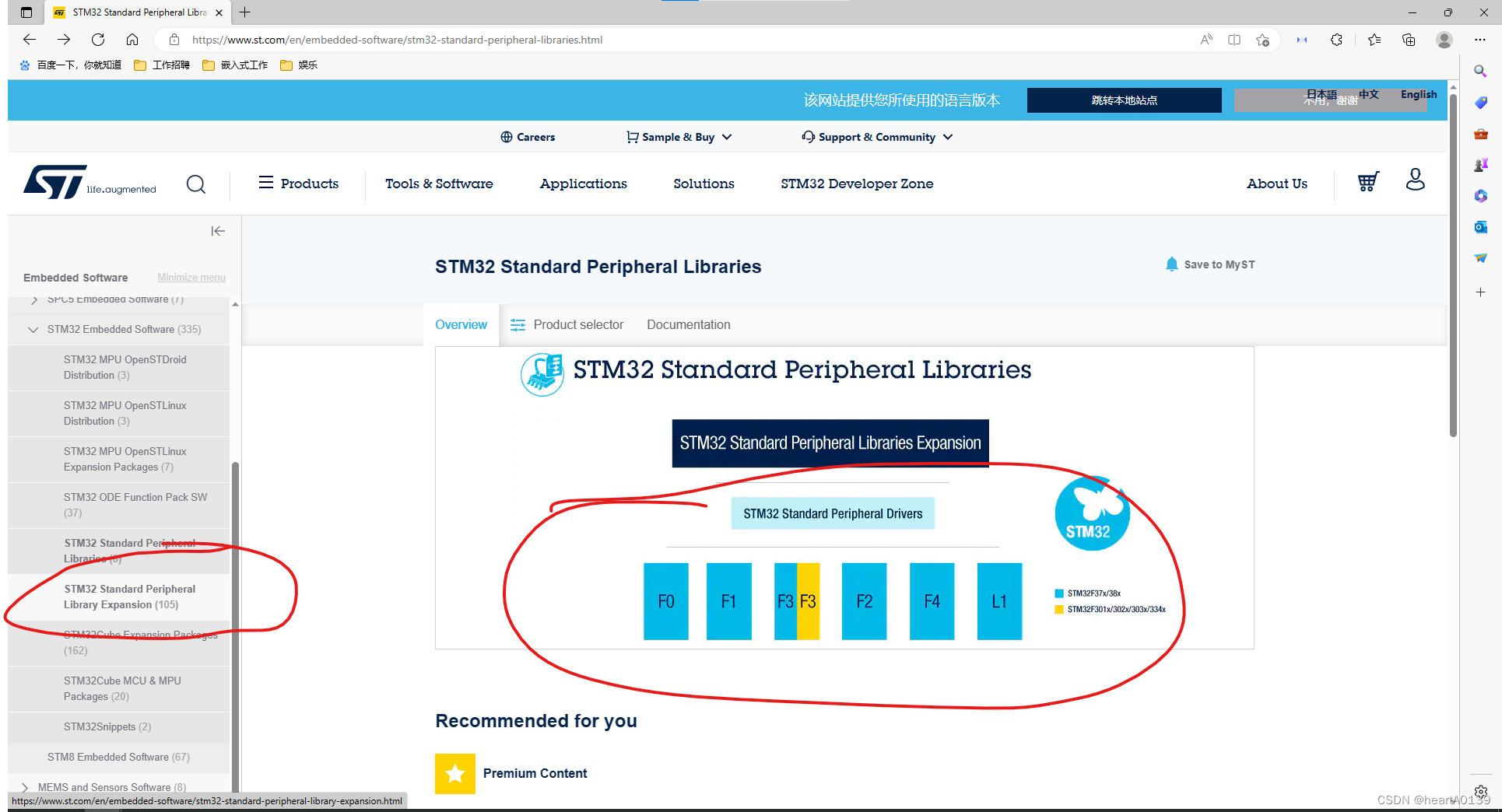
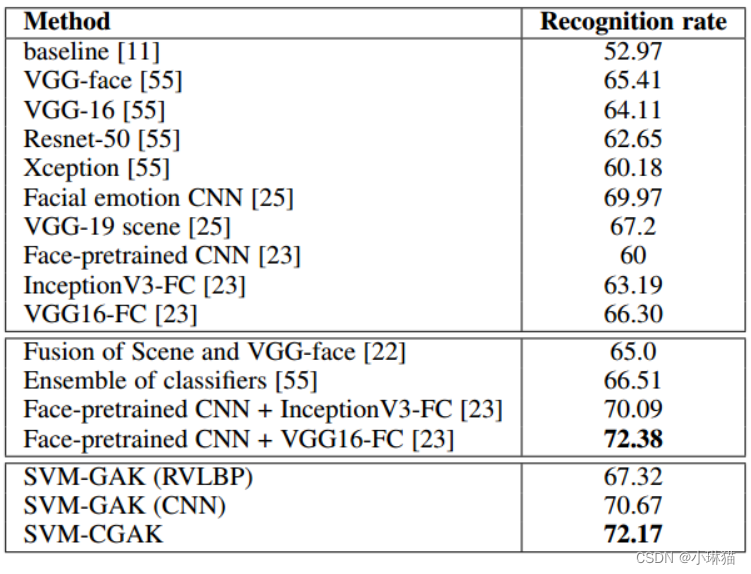
我们假设某数据库的keep参数为7,days参数为3,当前时间为某月9日的0点0分。
由于keep为7,所以2日(9-7)之前的数据一定是不可以写入的。再加上限制未来时间数据的插入,12日(9+3)之后的数据也是不可以插入的。通过这样的方式,就有了TDengine当前可处理数据的时间范围time range(彩色范围),当你试图写入位于灰色时间区域的数据时——就会看到“timestamp out of time range”的提示了。
这组图代表了随着当前时间轴的移动,数据文件的分布情况和可写入数据范围的变化。
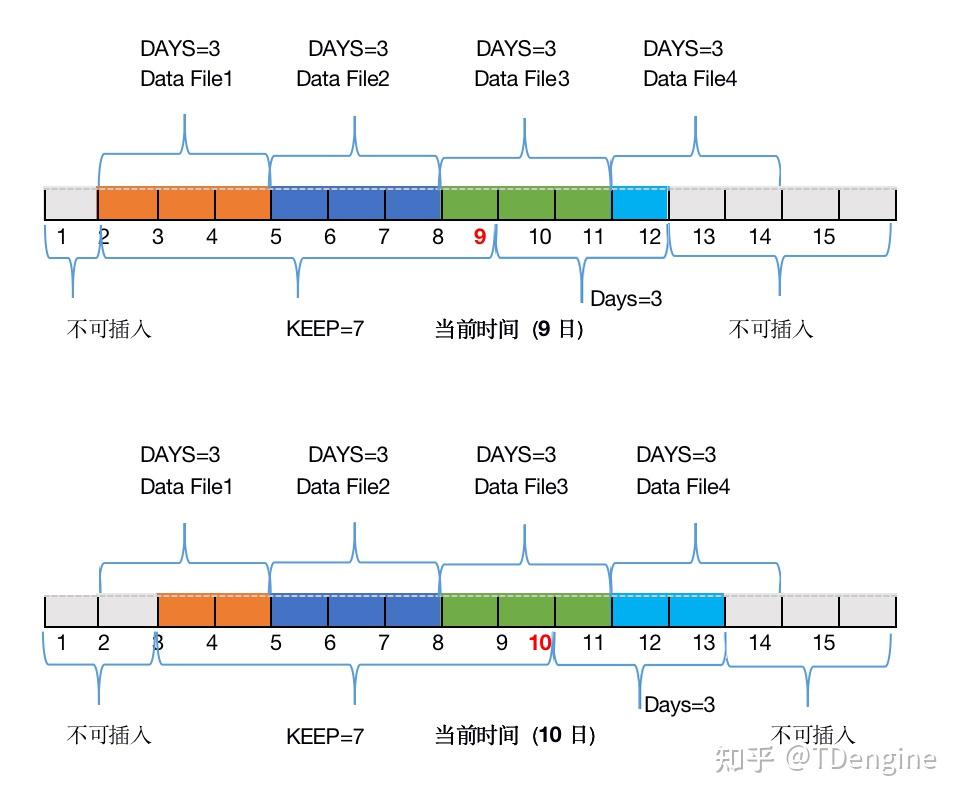
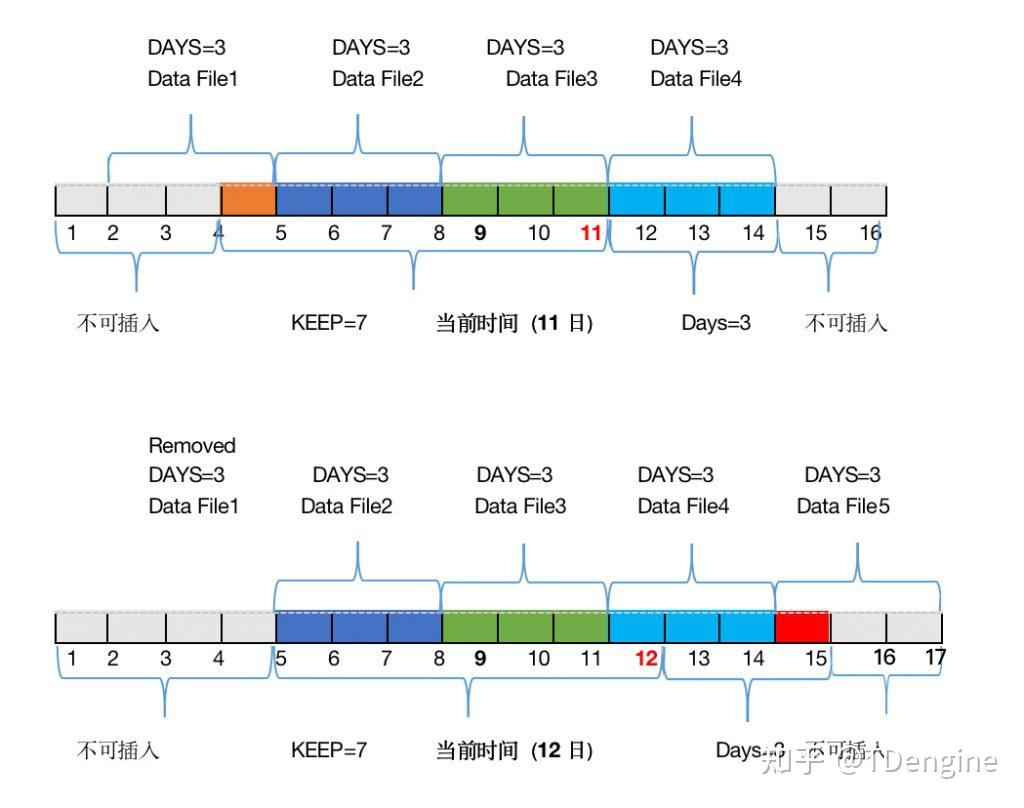
随着时间的推移,数据的时间戳会与系统时间做计算,一旦超过keep天数,就会被识别为过期数据,等到这个数据文件内的所有数据都过期后,这个数据文件才会被从计算机上清除。
以上述组图为例,由于2日和4日的数据是在同一个数据文件(Data File 1)中,4日的数据最多可以保留到11日结束,所以2日的数据同样也要保留到11日结束。所以我们可以看到,12日的时候,Data File 1已经被删除掉了。
细心的读者可能会问,假如我写入3日的数据,我是如何知道这个数据会落在345这个区间,还是123,或是234呢。其实是这样——TDengine是从1970年1月1日0时0分0秒起(EpochTime)开始,每3天划一个分区。因此,对任何一个时间戳都是“划到哪一片就算到哪一片”。
由于上述的机制删除粒度较粗,所以为了优化用户的体验,在2.1.5.0版本后,我们通过默认设置SQL查询的where timestamp的起始时间大于过期时间来实现用户侧完全可控的“过期数据删除”。所以,现在凡是过期的数据对用户都是不可见的。
虽然在物理层面上,数据仍然是以数据文件为单位删除的。但是除了对存储空间有极其精细要求的用户,绝大多数用户都是没有感知的。本次优化过后,用户不再需要为删除粒度的粗细而产生顾虑。只要安心根据自己的业务类型,灵活设置days参数的大小以找到性能最优的状况就好了。
此外,由于给定了可写入数据的时间范围(now-keep到now+days),给定了数据切分的时间范围(days),所以只要vnode目录下面的数据文件组数量小于等于keep/days向上取余+1,就可以认为自动删除机制是在正常工作的。
以上就是官方文档上所说的:“给定days与keep两个参数,一个vnode总的数据文件数目最多为:keep/days+2”的含义。
从概念上来说,“TDengine是通过vnode以及时间两个维度,对大数据进行切分,便于并行高效的管理,实现水平扩展。”但是如何让枯燥的概念能转化成自己正确的理解,还是需要学习的。《这几个神秘参数,教你TDengine集群的正确使用方式》与本文正是分别从这两个维度切入TDengine原理的,可以说是比较核心的知识点了。
对于TDengine,我们希望大家可以知其然,也知其所以然。




](https://npm.elemecdn.com/youthlql@1.0.8/Java_concurrency/Source_code/Second_stage/0033.png)