【论文阅读】Analyzing group-level emotion with global alignment kernel based approach
- 摘要
- 1.介绍与相关工作
- 2.方法
- 3.实验
摘要
本篇博客参考IEEE于2022年收录的论文Analyzing group-level emotion with global alignment kernel based approach,对其主要内容进行总结,以便加深理解和记忆
1.介绍与相关工作
1)群体情绪
从社会科学的角度来看,近一个世纪以来,研究人员在理解小团体的结构和绩效方面做出了更多的贡献[4],[5],[6],[7]。其中一个值得注意的是定义群体情感。Barsade和Gibson在[5]中对群体情感做了一个共同的定义。也就是说,群体情感是一群人的情绪、情感和性格影响。此外,群体情绪还会影响团队过程和结果[8]。例如,积极情绪的增加会导致更强的合作性和更少的群体冲突[9]。考虑到一个家庭在婚礼上摆姿势合影的心情,预计会有一个自动系统来识别家庭的心情。
近年来,一些研究者对群体层面的情绪识别任务进行了研究,如群体层面的效价和唤醒预测[10]和群体层面的面部表情识别[11]。
- 在[10]中,Mou等人旨在预测图像中一组人的效价和唤醒。它可能会在未来的计算机视觉领域带来各种好处。
- 计算机视觉系统基于对图像的正确预测,可以自动选择候选照片供人们制作相册[12]。
- 这种系统还可以帮助教育领域的社会科学家/研究人员分析学生在协作学习中的互动[13]等。
特别是在[10]、[11]、[14]、[15]的激励下,我们主要关注群体层面情绪识别中的三个任务:群体层面幸福感强度估计[15]、群体层面效价和唤醒预测[10]、群体层面面部表情识别[11]。
群体被称为“情感实体和各种情感表现的丰富来源”[5]。Kelly和Barsade指出,情感影响大量存在于群体/团队中[6]。
Barsade和Gibson在[5]中讨论的早期研究强调,社会科学界的研究人员应该针对“自上而下的方法”和“自下而上的方法”这对组合产生群体情绪。“自上而下的方法”表明群体所表现出的情绪在群体层面上表现出来,并被个体成员感受到,而“自下而上的方法”强调个体群体成员情绪的独特构成效果。在[5]的框架基础上,Kelly和Barsade[6]]进一步提出群体情绪由“自下而上”的成分(即情感构成效应)和“自上而下”的成分(即情感语境)组成。换句话说,群体情感产生于个人层面的情感因素和群体层面的情感因素的结合,其中个人层面的情感因素是由群体成员提出的,群体层面的因素“塑造了群体的情感体验”
2)一般思路
理解图像或视频中群体/团队的行为最近受到了计算机视觉社区的广泛关注。计算机视觉领域的研究人员根据Barsade et al .[5]和Kelly et al [6]提出的群体情绪理论设计了这些方法。计算机视觉中的方法可以大致分为自底向上和自顶向下两种策略。自下而上的分类使用主体的属性来推断群体情绪。另一方面,自顶向下的方法考虑外部属性,如场景的影响和人的位置,来描述群体成员。然而,单独使用自底向上或自顶向下的方法进行群体情感分析可能会错过图像中一些有用的和有区别的信息。
为了解决群体情感分析中存在的问题,近年来提出了自下而上和自上而下相结合的群体情感分析混合模型方法。它们分为两个分支:组表达模型[12]、[15]、[18]和多模态框架[10]、[11]、[19]、[20]、[21]、[22]、[23]。
①组表达式模型将组级图像1中的多个面编码为图形结构。它涉及全局和局部社会属性的建模方法:
- 基于图的面部属性和场景[24]。
- 较早的组表达模型出现在[12]、[15]。例如,Dhall等人利用了三种模型,即基于平均、加权和潜在狄利克雷分配的群体表达模型,用于群体水平的幸福强度估计。特别是,他们将事件和群体环境的影响作为自上而下的组成部分,并将群体成员与群体成员的属性(如自发的表情、服装、年龄、性别)一起作为自下而上的组成部分。
- Huang等[18]提出了另一种群体表达模型用于群体层面的幸福强度估计,以提高绩效。他们将全局属性(如相邻组成员的影响)称为自顶向下组件,将局部属性(如个人的特征)称为自底向上组件。
然而,群体表达模型由于图的构造导致计算效率不高,并且由于人脸描述子中的噪声而不能稳定运行。
- 例如,在[15]中,基于潜狄利克雷分配的群体表达模型受到k-means中聚类数量选择的严重影响。这意味着k-means中的大量聚类会使特征非常稀疏,而少量聚类则会失去判别信息。
- 在[18]中,图的构建存在支持向量回归错误预测的问题。
此外,群体表达模型不能通过潜在狄利克雷分配等统计模型直接度量图像之间的距离。
②多模态框架是一种结合图像自底向上和自顶向下成分的群体级情感识别方法。
-
例如,在[11]中,面部动作单元和面部特征被认为是自下而上的组件,而场景特征被认为是自上而下的组件。
-
在[25]中,Tan等人使用例外架构并融合图像上下文和面部特征来识别群体层面的情绪。类似的作品也出现在[19]、[20]、[21]中。
-
另一个有趣的多模态研究[10]结合面部和身体信息来预测一群人的效价和唤醒。一些关于多模态框架的研究,如[10],更倾向于基于固定数量的面孔和身体,设置群体层面情绪识别的条件,对特定群体进行实验。
-
此外,[11]提出的特征编码方法使用聚类方法构建词汇表,并将每张图像表示为词汇表的频率直方图。这个中间阶段可能会在分类阶段引入一些错误。此外,这些方法受到聚类方法中参数设计的强烈影响。
我们对群体表达模型和多模态框架的实证分析表明,它们缺乏对不同任务的适应性。
- 例如,具有连续条件随机场的群体表达模型[18]不适合对情绪类别进行分类,因为它最初的设计目的是估计群体的幸福强度。
- 此外,由于可调参数较多,计算量较大。例如,多模态框架[26]包含三个重要参数,即主成分分析的维数、核数和面块数。
因此,是否有一种高效有效的方法可以让我们直接计算图像之间的距离,从而可以灵活、自适应地嵌入到任何分类器中,例如最近邻分类器或支持向量机,用于群体级情感识别的各种任务。这个问题导致了群体层面情感识别中一个相对未被探索的新主题:如何制定用于计算图像之间距离的距离度量(如图1所示)。在数学上,我们假设两幅图像由 Σ a = { x 1 , . . . , x n } Σ_a = \{x_1,...,x_n\} Σa={x1,...,xn}和 Σ b = { y 1 , . . . , y m } Σ_b = \{y_1,...,y_m\} Σb={y1,...,ym},我们的目标是找出距离度量函数 F ( Σ a ; Σ b ) F(Σ_a;Σ_b) F(Σa;Σb)以便更好地描述图像之间的距离。
3)作者思路
与群表达模型和多模态框架不同,我们关注的是一种基于图像之间距离度量函数F的新方法,从而允许我们直接测量图像之间的距离,并将此距离度量应用于任何分类器。如图1所示,两个图像之间的面数并不总是一致的。换句话说,两张图像包含不同数量的人脸。直接使用距离测量,如欧几里得距离来测量两幅图像之间的距离 Σ a Σ_a Σa和 Σ b Σ_b Σb是很困难的。
近年来,一组基于动态规划的时间序列核被用于构建语音、生物信息学和文本处理等领域的核。这些时间序列核可以解决两个关键问题:(1)时间序列可能是可变长度的;(2)在测量变长序列时,不能通过构建其时间序列相邻状态之间的局部依赖关系来捕获向量的标准核。
时间序列核方法,如动态时间翘曲[27],[28],已经被研究用于动作识别[29],[30]和音乐检索[31]。然而,这种距离不能轻易地转化为正定核,这是核机在训练阶段的一个重要要求。为了解决时间序列核的正定问题,Cuturi等人提出了一种**全局对齐核(global alignment kernel, GAK)**方法,并应用于语音识别[32]和手写识别[33]。将全局对齐核用于动态面部表情识别,对时间信息进行对齐,并证明了其在面部表情识别中的有效性[34],[35]。结果表明,与其他时间序列核方法相比,全局对齐核方法能更好地测量变长度时间序列,并能捕获时间序列相邻状态之间的局部依赖关系。
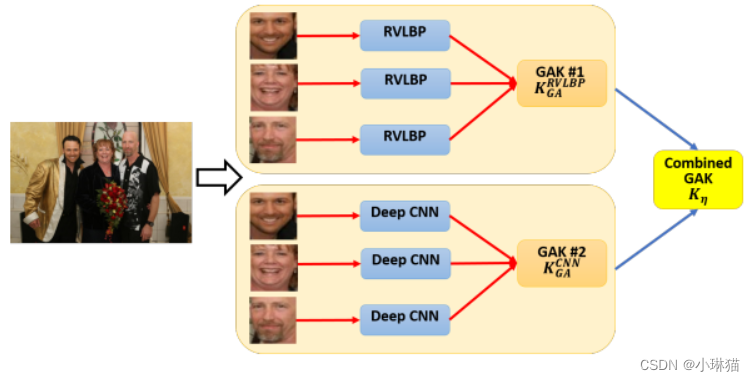
因此,我们提出了一种基于全局对齐核的方法来直接测量两幅图像之间的距离。我们首先将图像中的人脸视为一个集合。接下来,我们使用全局对齐核来测量两个集合 Σ a Σ_a Σa和 Σ b Σ_b Σb之间的距离。例如,如图1上面的图像所示,我们可以将该图像视为包含9个人脸的人脸序列。然后,测量两幅图像之间的距离可以明确地表示为两幅图像序列之间的对齐。
在制作群体级情感识别的全局对齐核之前,我们注意到全局对齐核存在图像上人脸的无序性问题。例如,如图1所示,三个图像中的人物具有不同的空间位置。如何在图像上设置合适而良好的面部设置是一个问题。它的目的是减少人脸无序的影响,提高全局对齐的效率。在[34],[35]中,他们使用全局对齐核来测量面部表情序列之间的相似性。
可以观察到,实验中使用的面部表情视频是从中性到顶点。换句话说,这些视频在表达强度上有相同的现象。这一现象使得动态时间翘曲等时间序列核可以简单、直接地找到两个面部表情序列之间的最佳对齐路径。
因此,我们设计了一种在两幅图像之间构建一致人脸集的方法,以进一步增强全局对齐核的良好判别距离度量函数。全局对齐核将从两个面集的起始节点处得到最优搜索路径。好的人脸集可能有助于更好地计算两幅图像之间的距离。一方面,我们假设群体层面的情感行为被限制在人们有序表现的路径上。另一方面,面部表情识别中普遍存在的一个关键问题是:面部可能会受到恶劣环境的影响,例如光线不足、头部姿势变化等。一般来说,我们可以很好地探索多个鲁棒特征描述符来描述图像中的人脸,但是计算多维特征的多个特征集之间的距离是很重要的。在这里,我们开发了低级和高级特征,以增强面部表情表示对具有挑战性的环境的鲁棒性,并将它们输入两个单独的全局对齐核。接下来,我们提出利用多核学习方法将两个全局对齐核结合起来进行群体级情感识别,因为多核学习已被广泛使用,并在许多领域取得了良好的表现[36],[37]。

4)贡献
- 提出了全局权重排序方案,在图像间构建高效的人脸集,并进一步评价了其对全局对齐核的重要性,与随机排序相比,可以更有效地增强全局对齐核
- 提出全局对齐核和全局权值排序方案用于测量两幅图像之间的距离,并将其嵌入到支持向量机中进行群体级情感识别
- 采用多核学习方法,根据两个特征分别学习两个全局对齐核的最优权值,并提出组合全局对齐核的支持向量机来推断感知的群体层次情绪
- 在三个“野外”数据库上进行的综合实验表明,本文提出的方法在群体水平情绪识别的三个不同任务上优于大多数最先进的方法:群体水平幸福感强度估计、群体水平效价和唤醒预测以及群体水平面部表情识别。
5)问题
数据问题:缺乏视频;人工标注;更广泛的类别
2.方法
1)群体规模的可变性使得构建群体情绪识别的核函数K变得困难,固定的群体大小策略严重限制了群体情绪识别的应用。作者将此称为“组大小变异性问题”
- Dhall等人在[11]中使用Bag-of-VisualWords,将图像特征视为单词,从多个面累积直方图来表示图像的特征。然而,得到的特征是非常稀疏的。
- 在[26]中,Huang等人提出了一种信息聚合方法,对人脸块的直方图进行编码,以表示图像的特征。虽然这种方法可以使图像的特征不稀疏,但它的缺点是有很多参数需要手动调整,如主成分分析的块数和降维。

2)结合全局对齐核的支持向量机
①全局权重排序:相对脸大小、相对距离
②距离测量的构造
全局对齐核将找到两个面集之间的最优搜索路径π,然后计算相对于最优路径的距离。全局对齐核可以使同一类的图像彼此接近,而不同类的图像彼此远离。这意味着全局对齐核可以保留判别信息。全局对齐核可以为支持向量机提供判别信息。还可以看出,全局对齐核在计算不同组大小的两幅图像之间的距离时是灵活的。

③基于组合全局对齐核的支持向量机SVM-GAK
- 别从人脸中提取RVLBP和deep CNN特征
- 生成两个全局对齐核,分别对RVLBP和deep CNN特征表示为KRVLBP GA和KCNN GA
- 采用组合策略对两个核进行融合
3.实验
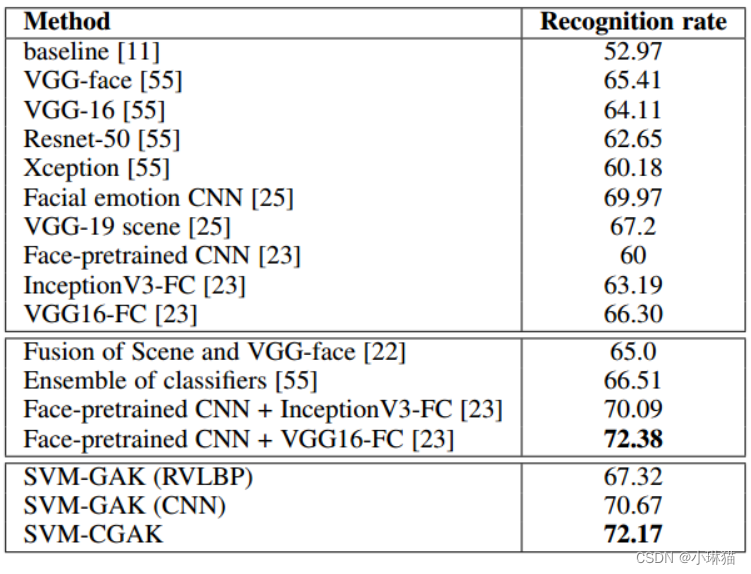
GAF 2.0



![[SpringBoot]xml写mapper](https://img-blog.csdnimg.cn/e8a4039252d4426ea076557ea8afea73.png)