HashMap与HashSet是我们日常最常使用的两个集合类。在实现上,两者也有很大的相似性。HashSet基本就是对HashMap的一个简单包装。
为了更好的理解Hash结构的实现原理,从而更好的指导我们的代码使用,本文就主要对HashMap的实现及设计做分析介绍。
底层数据结构
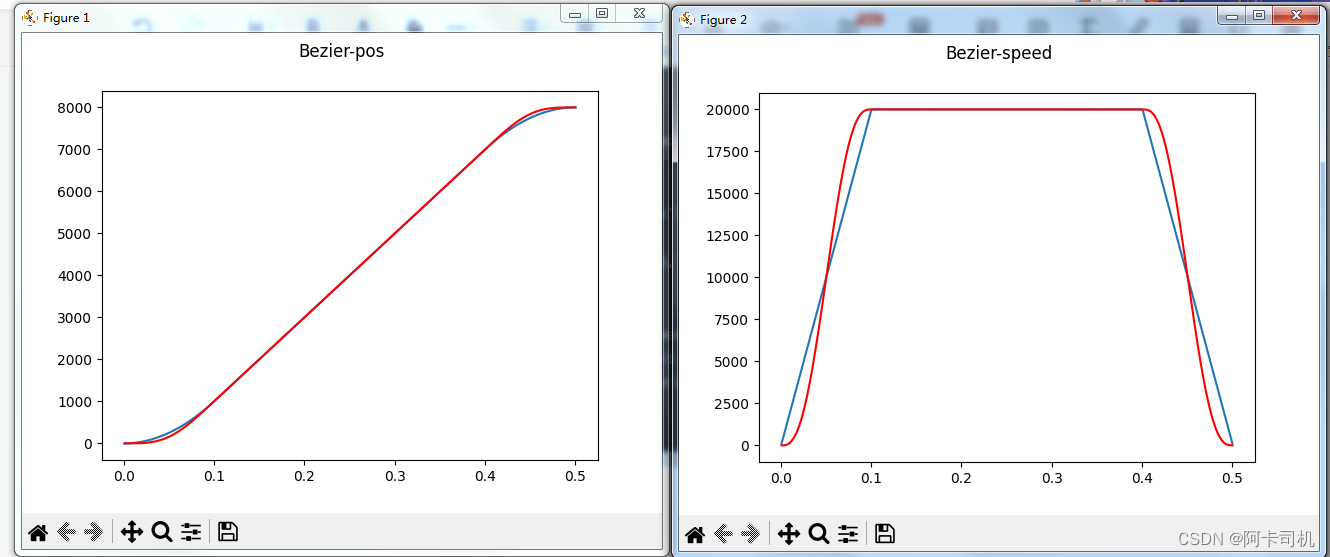
HashMap属于经典的K-V数据结构,因此,在HashMap中定义了一个**Node<K,V>**对象,借助于泛型的编程实现,hashMap可以轻易地用于记录当前需要保存的Key及Value对象。
同时,由于这类对象是多个,因此hashMap的最底层结构是基于一个Node<K,V>[]对象进行操作的。对于出现哈希冲突的情况,常见的哈希处理方法有两种:开放寻址法和链地址法。HashMap的实现,主要基于链地址法实现的。
综上,我们可以简单绘制出hashMap的底层结构如下所示:
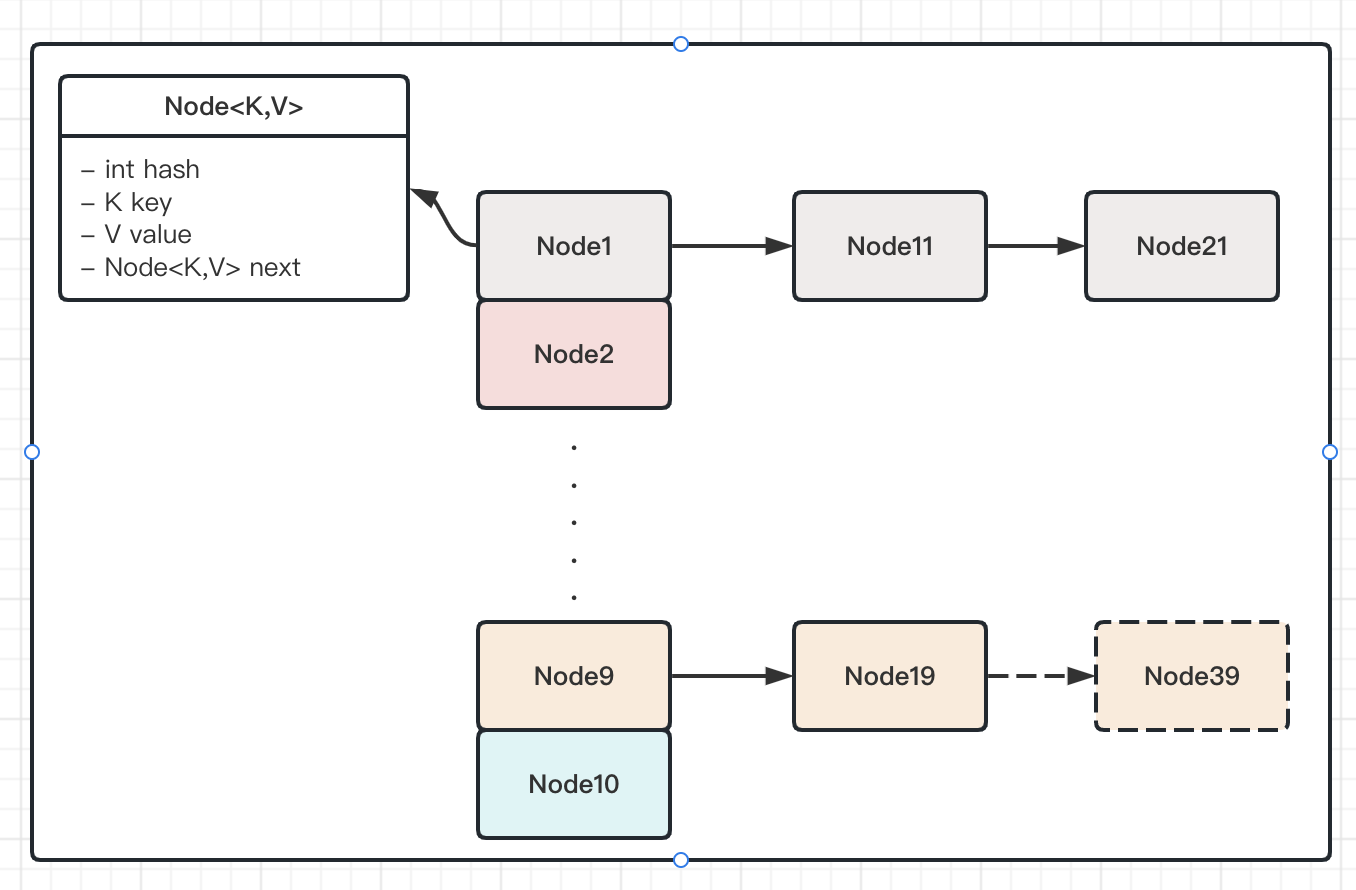
结合着上述对于hashMap结构的理解,我们可以很简单地得出一个元素,其添加到hashMap中的过程大致如下所示:
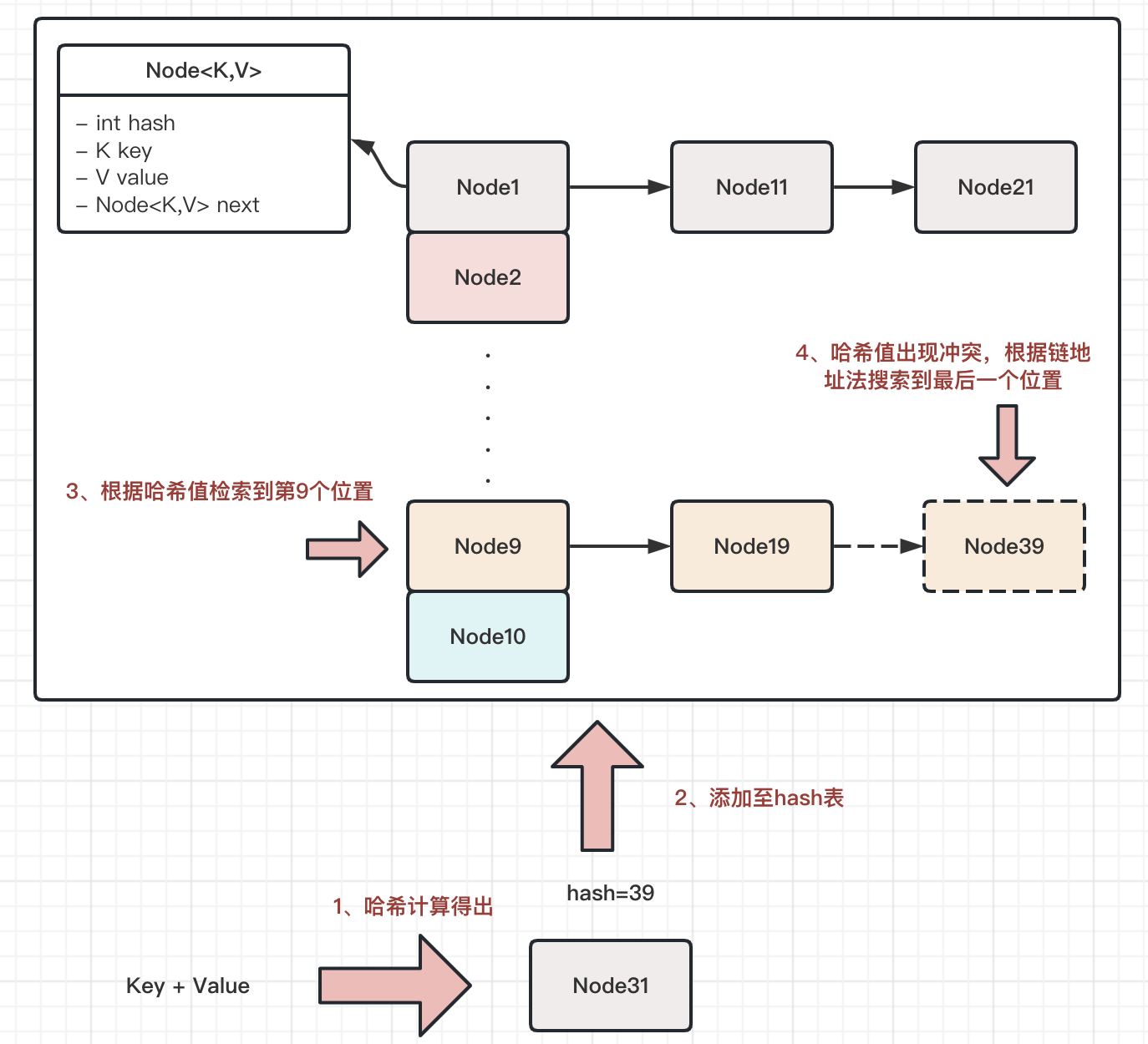
当然,实际情况中hashMap会更复杂一些,由于考虑到哈希冲突的性能问题,过长的哈希冲突产生的链表会使得检索效率从原本的O(1)降低至最差的O(n)的情况(如果每个元素都冲突的情况。)。
为此,HashMap在长度超过8时候会将链表结构转换成红黑树进行处理,而在长度小于6的时候,又会重新恢复成链表结构。具体的实现内容,我会在接下来的关键方法的源码解析中逐一介绍。
言归正传,从上述的流程来看,归纳起来hash表存储的最主要的过程无非以下几个:
1、计算哈希值。
2、根据哈希值检索位置。
为此,我们后续主要围绕这两个部分展开学习。
关键方法源码
hash计算
在hashMap中,最重要的一个函数当属hash(Object)函数。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
首先我们主要知道h>>>16代表哈希值无符号右移动了16位,这里其实是hashMap设计的一个小技巧,无符号右移16位,就相当于h%16,通过位运算加快了操作运算的过程。
但是在取模以后,hashmap还用前十六位同后十六位做了一个异或操作。这里我们举一个具体例子来看。假设咱们的哈希值是二进制4294967295(2的32次方-1):11111111111111111111111111111110。无符号右移16位后,就会变成2的16次方,也就是:00000000000000001111111111111111;两者做位异或运算可以得到如下的结果:
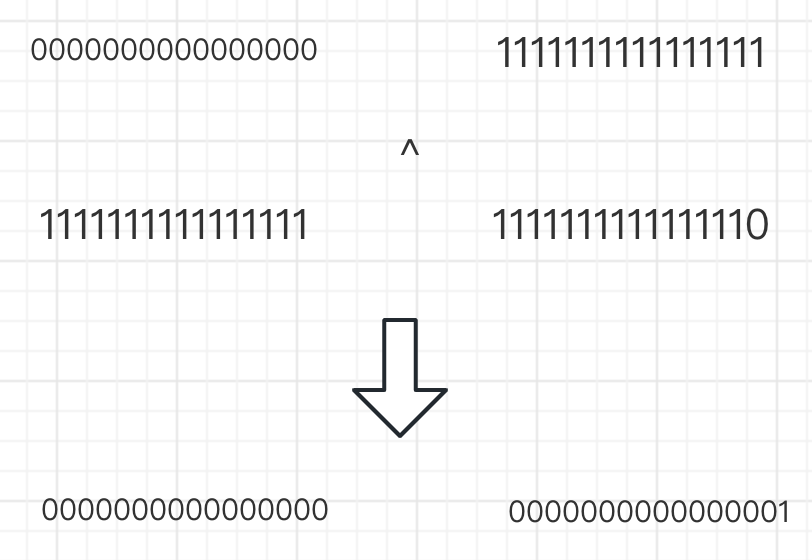
那么为什么hashMap要这么做呢?其实是为了将对象的哈希值尽可能的散列开。假设我们取模后直接用前16位来作为哈希值,那么相当于后16位的数据,hashMap是根本用不上的,也就意味着有一半的数据会出现冲突,因此,hashMap将后16位也纳入到考虑范围内,从而充分将数据散列开来,减少冲突。
哈希值检索
在理解了哈希值是如何计算的之后,下一步自然是需要了解如何根据hash值做插入、删除。这里我们以put()方法为例,逐步揭开hashmap的神秘面纱。
从put方法的源码分析,put方法主要涉及到三种情况:数组为空、数组非空但未哈希冲突、哈希冲突。我们逐一来看这三个内容在hashMap中的处理及实现。
数组为空
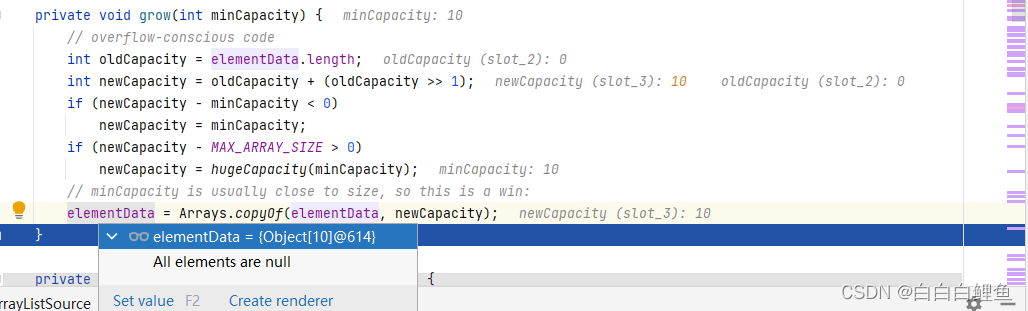
针对于当前数组长度为空的情况,此时首先需要进行数组的扩容。通常情况下,哈希数组默认的长度是16。同时,hashmap还会保存一个叫做负载因子的变量,这个就是hashMap设计中的其中一个精华所在。
负载因子的作用很简单,即长度若达到的负载因子控制的上限,那么此时就让hashMap进行扩容。默认情况下,负载因子为0.75,意味着默认情况下在数组长度达到12(16*0.75 = 12)的时候,就需要进行第一次扩容。那么问题来了,为什么是0.75呢?
首先假设我们的扩容因子如果设置成1,那么意味着需要整个数组都被填充完,才会进行扩容。但是这样一来会带来一个问题,即如果多次哈希都无法命中最后一个数组节点,那么其余的节点冲突会越来越多,也就会导致红黑树的层深、链表的长度都过长,进而影响查询的效率。
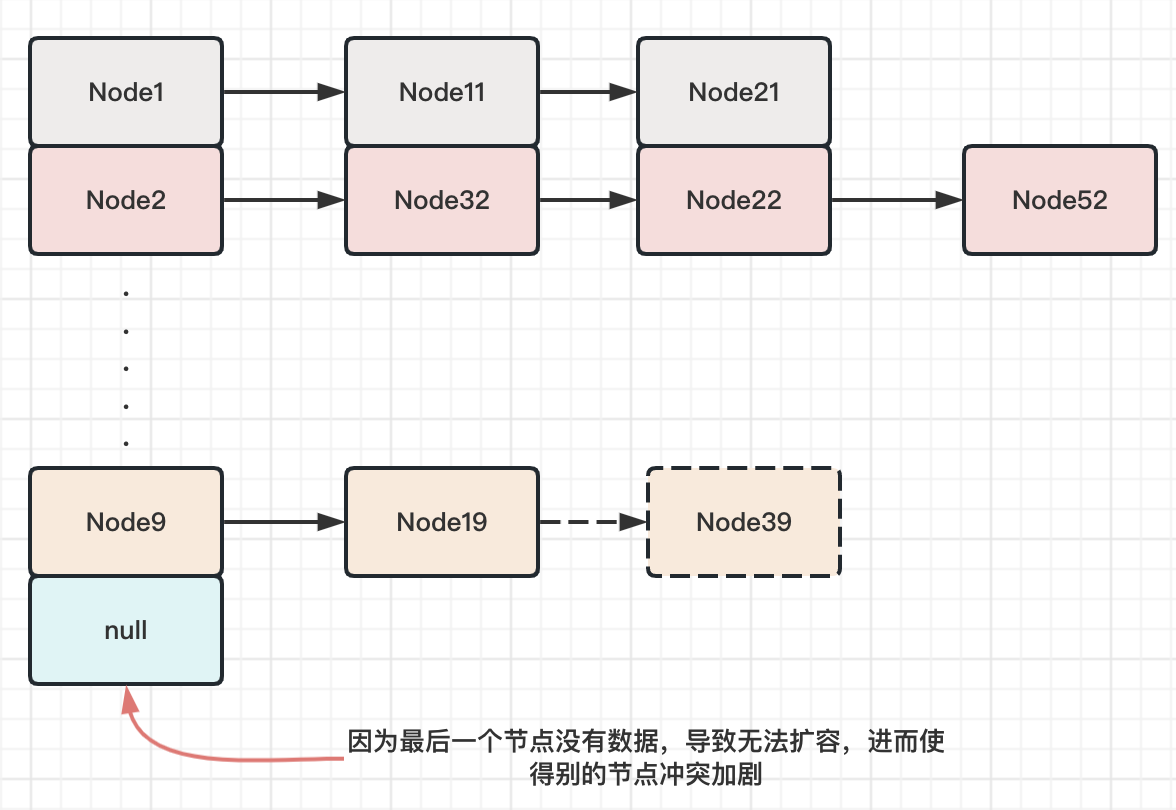
而假设如果负载因子设置的过小,那么就会频繁的触发数组扩容,同时,也意味着有极大部分的数组空间是无法被使用到的,造成了资源上的浪费。基于此,hashMap开发人员们经过反复的测试、比较,最终选择了0.75作为负载因子,最大程度平衡时间效率和空间利用率。
数组非空但未哈希冲突
数组为空的情况我们就介绍完了,接下来简单介绍下数组为空,但是没有出现哈希冲突的情况。在该种情况下,hashmap要处理的逻辑则相对简单,只需要在索引到具体的哈希位置,填充一个新的Node值即可。具体的源代码如下所示:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
从源码中不难看到,hashMap找寻数组下标的方式,是通过用先前计算好的哈希值同数组的长度进行位与,这里(n-1)&hash,其实就等于hash%n,也算是在源码中使用到的一个小技巧吧。
哈希冲突
介绍完了上述的两种情况,还剩下最为复杂的一种情况,即出现哈希冲突的情况。哈希冲突的情况我们也可以拆分成三种情况考虑:
首节点即待替换节点: 如果首节点即待替换的节点,那么此时只需要直接替换首节点即可。
需要遍历红黑树查找插入节点:调用红黑树插入的方法进行遍历查找,这里就不展开介绍了。
需遍历列表搜索节点:思路上相对简单,即逐个遍历节点,如果相同则将该节点的值做替换,否则就创建一个节点做尾插法。需要注意的是,如果当前长度大于等于了阈值-1(即6),那么就会从链表结构转换成红黑树结构。如果后续节点数因为删除或扩容又小于8了,那么又会回退成链表的结构。
put方法实现的源代码如下所示,有兴趣的小伙子可以看看:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 数组扩容
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 通过用长度-1 与 哈希值进行 位与运算,得到具体的下标。如果下标为空,代表此时并没有发生冲突,那么就直接新建一个存放。
else { // 长度不为0,且存在冲突
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
//首先判断当前第一个冲突的node节点同待插入节点是否相同,如果相同则不做处理。
e = p;
else if (p instanceof TreeNode)
// 如果是红黑树结构,那么此时按照红黑树结构进行插入
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 否则按照链表形式进行插入
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//插入完成节点后,覆盖插入节点的值val
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
参考文献
为什么HashMap使用高16位异或低16位计算Hash值?
](https://npm.elemecdn.com/youthlql@1.0.8/Java_concurrency/Source_code/Second_stage/0033.png)





![[SpringBoot]xml写mapper](https://img-blog.csdnimg.cn/e8a4039252d4426ea076557ea8afea73.png)