前言
在众多IT职场中,SQL技术一直是一个非常重要的技能点。如果你正在准备SQL相关的面试,那么这份“SQL面试 100 问”绝对是你不能错过的宝藏!
这份清单涵盖了100道高频考题,从基础知识到复杂应用都有所涉及,帮助你全面掌握SQL面试必备技能,轻松应对各种挑战。
同时,每个问题还有详尽的解析和答案,让你更好地理解SQL核心概念和编程思路。
没有什么比自信满满地走进面试室更能给你加分了,快来查漏补缺,提升自己的SQL实力吧!

本文介绍并分析了 100 道常见 SQL 面试题,主要分为三个模块:SQL 初级查询、SQL 高级查询以及数据库设计与开发。
本文主要使用三个示例表:员工表(employee)、部门表(department)和职位表(job)。
下面是这些示例表的结构:
- 部门表(department),包含部门编号(dept_id)和部门名称(dept_name)字段,主键为部门编号。
- 职位表(job),包含职位编号(job_id)和职位名称(job_title)字段,主键为职位编号。
- 员工表(employee),包含员工编号(emp_id)、员工姓名(emp_name)、性别(sex)、部门编号(dept_id)、经理编 号(manager)、入职日期(hire_date)、职位编号(job_id)、月薪(salary)、奖金(bonus)以及电子邮箱(email)。主键为员工编号,部门编号字段是引用部门表的外键,职位编号字段是引用职位表的外键,经理编号字段是引用员工表自身的 外键。
1. 什么是 SQL?SQL 有哪些功能?
答案: SQL 代表结构化查询语言,它是访问关系数据库的通用语言,支持数据的各种增删改查操作。SQL 语句可以分为以下 子类: DQL,数据查询语言。这个就是 SELECT 语句,用于查询数据库中的数据和信息。DML,数据操作语言。包括 INSERT、UPDATE、DELETE 和 MERGE 语句,主要用于数据的增加、修改和删除。DDL,数据定义语言。主要包括 CREATE、ALTER 和 DROP 语句,用于定义数据库中的对象,例如表和索引。TCL,事务控制语言;主要包括 COMMIT、ROLLBACK 和 SAVEPOINT 语句,用于管理数据库的事务。DCL,数据控制语言。主要包括 GRANT 和 REVOKE 语句,用于控制对象的访问权限。解析:SQL 是一种声明性的编程语言,只需要告诉计算机想要什么内容(what),不需要指定具体怎么实现(how)。通过 几个简单的英文单词,例如 SELECT、INSERT、UPDATE、CREATE、DROP 等,就可以完成大部分的数据操作。
2. 如何查看员工表中的姓名和性别?
答案: SELECT emp_name, sex FROM employee; 解析:SQL 使用 SELECT 和 FROM 查询表中的字段,多个字段使用逗号分隔。
3. 如何查看员工表中的所有字段?
答案: SELECT * FROM employee; 或者: SELECT emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email FROM employee; 解析:SQL 查询中的星号(*)表示查询所有字段,可以方便快速查询数据;但是在产品中不推荐使用,因为星号可能带来不 确定性。
4. 如何知道每个员工一年的总收入?
答案: SELECT emp_name, salary * 12 + COALESCE(bonus, 0) FROM employee; 解析:查询结果中可以使用各种运算、函数以及表达式。COALESCE 函数用于将空值转换为 0。
5. 如何为查询结果指定一个容易理解标题?
答案: SELECT emp_name AS "姓名", salary * 12 + COALESCE(bonus, 0) "年薪" FROM employee; 解析:SQL 中的别名可以为查询中的表或结果指定一个临时名称。别名使用关键字 AS 表示,可以省略。
6. 怎么查看女性员工的信息?
答案: SELECT * FROM employee WHERE sex = '女'; 解析:SQL 中使用 WHERE 子句指定过滤条件,只有满足条件的数据才会返回。除了等于(=),还可以使用大于(>)、大 于等于(>=)、小于(<)、小于等于(<=)以及不等于(!= 或者 )这些比较运算符作为过滤条件。
7. 如何查看月薪范围位于 8000 到 12000 之间的员工?
答案: SELECT * FROM employee WHERE salary BETWEEN 8000 AND 12000; 解析:BETWEEN 用于查找范围值,包含两端的值。
8. 确认员工中有没有叫做“张三”、“李四” 或“张飞”的人,有的话查出他们的信息。
答案: SELECT * FROM employee WHERE emp_name IN ('张三', '李四', '张飞'); 解析:IN 用于查找列表中的任意值。
9. 只知道某个员工的姓名里有个“云”字,但不知道具体名字,怎么样查看有哪些这样的员工?
答案: SELECT * FROM employee WHERE emp_name LIKE '%云%'; 解析:SQL 中的 LIKE 运算符用于字符串的模式匹配。LIKE 支持两个通配符:% 匹配任意多个字符,_ 匹配单个字符。Oracle 区分大小写,MySQL 不区分大小写。
10. 有些员工有奖金(bonus),另一些没有。怎么查看哪些员工有奖金?
答案: SELECT emp_name, bonus FROM employee WHERE bonus IS NOT NULL; 解析:SQL 中的 NULL 表示空值,意味着缺失或者未知数据。判断空值不能直接使用等于或不等于,而需要使用特殊的 IS NULL 和 IS NOT NULL。
11. 在前面我们知道了如何查询女员工,如何查看 2010 年 1 月 1 日之后入职的女员工呢?
答案: SELECT emp_name, sex, hire_date FROM employee WHERE sex = '女' AND hire_date > DATE '2010-01-01'; 解析:AND、OR 和 NOT 表示逻辑与、逻辑或和逻辑非,可以用于构造复杂的查询条件。
12. 以下查询会不会出错,为什么?
SELECT * FROM employee WHERE 1 = 0 AND 1/0 = 1; 答案:不会出错,但是查不到任何数据。
解析:因为 SQL 对于逻辑运算符 AND 和 OR 使用短路运算(short-circuit evaluation)。也就是说,只要前面的表达式能够 决定最终的结果,不执行后面的计算。
13. 如何去除查询结果中的重复记录,比返回如员工性别的不同取值?
答案: SELECT DISTINCT sex FROM employee; 解析:DISTINCT 用于消除查询结果中的重复值,上面的查询只返回两个不同的性别记录。
14. 查看员工信息的时候,想要按照薪水从高到低显示,怎么实现?
答案: SELECT * FROM employee ORDER BY salary DESC; 解析:ORDER BY 子句用于对查询结果进行排序;ASC 表示升序,DESC 表示降序。
15. 在上面的排序结果中,有些人的薪水一样多;对于这些员工,希望再按照奖金的多少进行排序,又怎么实现?
答案: SELECT * FROM employee ORDER BY salary DESC, bonus DESC; 解析:按照多个字段排序时,使用逗号分隔;排序时先按照第一个条件排列,对于排名相同的数据,再按照第二个条件排列, 以此类推。
16. 员工的姓名是中文,如何按照姓名的拼音顺序进行排序?
答案: -- MySQL 实现 SELECT emp_name FROM employee WHERE emp_id <= 10 ORDER BY CONVERT(emp_name USING GBK); -- Oracle 实现 SELECT emp_name FROM employee WHERE emp_id <= 10 ORDER BY NLSSORT(emp_name,'NLS_SORT = SCHINESE_PINYIN_M'); 解析:中文可以按照拼音进行排序,或者按照偏旁部首进行排序。MySQL 中的 GBK 编码支持拼音排序,Oracle 可以指定排 序规则。
17. 由于很多人没有奖金,bonus 字段为空,对于下面的查询:
SELECT * FROM employee ORDER BY bonus; 没有奖金的员工排在最前面还是最后面? 答案:取决于数据库的实现。解析:对于 MySQL ,升序时 NULL 值排在最前面,降序时 NULL 值排在最后面。对于 Oracle,默认升序排序时时 NULL 值 排在最后面,降序时 NULL 值排在最前面;还可以使用 NULLS FIRST 或 NULLS LAST 指定 NULL 值排在最前或最后。
18. 薪水最高的 3 位员工都有谁? 答案:
-- Oracle 12c 实现 SELECT emp_name, salary FROM employee ORDER BY salary DESC FETCH NEXT 3 ROWS ONLY; -- MySQL 实现
SELECT emp_name, salary FROM employee ORDER BY salary DESC LIMIT 3; 解析:SQL 中用于限制返回数量的关键字是 FETCH,MySQL 使用 LIMIT。
19. 在上面的问题中,如果有 2 个人的排名都是第 3 位,怎么才能都返回(一共 4 条数据)?
答案: -- Oracle 12c 实现 SELECT emp_name, salary FROM employee ORDER BY salary DESC FETCH NEXT 3 ROWS WITH TIES; 解析:FETCH 子句支持 WITH TIES 选项,用于返回更多排名相同的数据。另外,还可以使用 PERCENT 按照百分比返回数 据。
20. 怎么返回第 11 名到 15 名,也就是实现分页显示的效果? 答案:
-- Oracle 12c 实现 SELECT emp_name, salary FROM employee ORDER BY salary DESC OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY; -- MySQL 实现 SELECT emp_name, salary FROM employee ORDER BY salary DESC LIMIT 5 OFFSET 10; 解析:OFFSET 关键字指定一个偏移量,表示忽略前面多少行数据,然后返回结果。
21. 什么是函数?SQL 中的函数有哪些分类?
答案:函数是一种功能模块,可以接收零个或多个输入值,并且返回一个输出值。
在 SQL 中,函数主要分为两种类型:标量函数(scalar function)和聚合函数(aggregate function)。标量函数针对每一行 输入参数,返回一行输出结果。例如,ABS 函数可以计算绝对值。聚合函数针对一组数据进行操作,并且返回一个汇总结 果。例如,AVG 函数可以计算一组数据的平均值。
22. 如何知道每个员工的邮箱长度?
答案: SELECT emp_name, length(email) FROM employee; 解析:length 函数用于返回字符长度。需要注意的是,Oracle 是按照字符数量计算,lengthb 按照字节计算;MySQL 是按照 字节数量计算,char_length 按照字符数量计算。对于汉字这种多字节字符需要注意区分。
23. 如何确认谁的邮箱是“GUANXING@SHUGUO.COM”?
答案: SELECT emp_name, email FROM employee WHERE UPPER(email) = 'GUANXING@SHUGUO.COM'; 解析:UPPER 函数用于将字符串转换为大写形式。另外,LOWER 函数用于将字符串转换为小写形式。
24. 以 CSV(逗号分隔符)格式显示员工的姓名、性别、薪水信息,如何写 SQL 查询语句?
答案: -- MySQL 实现 SELECT CONCAT_WS(',' emp_name, sex, salary) FROM employee;
-- Oracle 实现 SELECT emp_name||','||sex||','||salary FROM employee; 解析:CONCAT 函数用于连接两个字符串。MySQL 中的 CONCAT_WS 扩展了该功能;Oracle 支持使用 || 连接字符串。
25. 如何获取员工邮箱中的用户名部分( @ 符号之前的字符串)?
答案: SELECT emp_name, SUBSTR(email, 1, INSTR(email,'@') - 1) FROM employee; 解析:此处使用了两个字符串函数,INSTR 函数查找 @ 符号的位置,SUBSTR 函数获取该位置之前的子串。
26. 将员工邮箱中的“.com”替换为“.net”,写出 SQL 语句?
答案: SELECT emp_name, REPLACE(EMAIL, '.com','.net') FROM employee; 解析:REPLACE 函数用于替换字符串中的字串。另外,TRIM 函数用于截断字符串。
27. 如何返回随机排序的员工信息?
答案: -- MySQL 实现 SELECT emp_name, RAND() FROM employee ORDER BY RAND(); -- Oracle 实现 SELECT emp_name, DBMS_RANDOM.VALUE FROM employee ORDER BY DBMS_RANDOM.VALUE; 解析:利用生成随机数的函数进行排序。MySQL 使用 RAND 函数,Oracle 使用 DBMS_RANDOM.VALUE 函数。
28. 数学函数 CEILING、FLOOR 和 ROUND 有什么区别?
答案: SELECT CEILING(1.1), FLOOR(1.1), ROUND(1.1) FROM employee WHERE emp_id = 1; 解析:CEILING 向上取整,FLOOR 向下取整,ROUND 四舍五入。Oracle 中使用 CEIL 函数替代 CEILING。
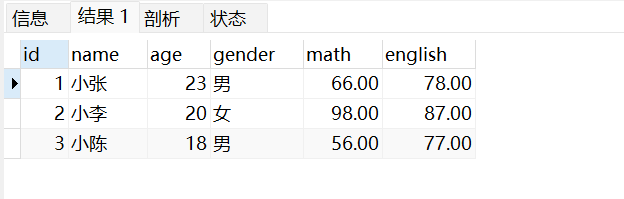
29. 下图是一个学生成绩表(score),如何知道每个学生的最高得分?
答案: SELECT student_id, GREATEST(chinese, math, english, history) FROM score; 解析:GREATEST 函数用于返回列表中的最大值,LEAST 函数用于返回列表中的最小值。
30. 如何知道每个员工的工作年限?
答案: SELECT emp_name, EXTRACT( year FROM CURRENT_DATE) - EXTRACT( year FROM HIRE_DATE) FROM employee; 解析:CURRENT_DATE 函数返回当前日期,EXTRACT 函数可以提取日期数据中的各个部分,本例中使用 year 参数获取年 份信息。
31. 工资信息比较敏感,不宜直接显示。按照范围显示收入水平,小于 10000 显示为“低收入”,大于等于 10000 并且小于 20000 显示为“中等收入”,大于 20000 显示为“高收入”。如何使用 SQL 实现?
答案: SELECT emp_name, CASE WHEN salary < 10000 THEN '低收入' WHEN salary < 20000 THEN '中等收入' ELSE '高收入'
END "薪水等级" FROM employee; 解析:CASE 表达式可以类似于 IF-THEN-ELSE 的逻辑处理。SQL 支持简单 CASE 和搜索 CASE,可以为查询增加基于逻辑 的复杂分析功能。掌握好 CASE 表达式是使用 SQL 进行数据分析的必备技能之一。
32. 如何统计员工的数量、平均月薪、最高月薪、最低月薪以及月薪的总和?
答案: SELECT COUNT(*), AVG(salary), MAX(salary), MIN(salary), SUM(salary) FROM employee; 解析:聚合函数针对一组数据计算出单个结果值。常见的聚会函数包括: AVG – 计算一组值的平均值。COUNT – 统计某个字段的行数。MIN – 返回一组值中的最小值。MAX – 返回一组值中的最大值。SUM – 计算一组值的和值。
33. 以下两个 COUNT 函数返回的结果是否相同? SELECT COUNT(*), COUNT(bonus) FROM employee;
答案:结果不同,COUNT() 返回 25 条记录,COUNT(bonus) 返回 9 条记录。解析:除了 COUNT () 之外,其他聚合函数都会忽略字段中的 NULL 值。另外,聚合函数中的 DISTINCT 选项可以在计算之 前排除重复值。
34. 群发邮件时,多个邮件地址使用分号进行分隔。如何获取所有员工的群发邮件地址?
答案: -- MySQL 实现 SELECT GROUP_CONCAT(email SEPARATOR ';') FROM employee; -- Oracle 实现 SELECT LISTAGG(email, '; ') WITHIN GROUP (ORDER BY NULL) FROM employee; 解析:使用字符串的聚合函数将多个字符串合并成一个。MySQL 中使用 GROUP_CONCAT 函数,Oracle 使用 LISTAGG 函 数。
35. 如何获取每个部门的统计信息,比如员工的数量、平均月薪?
答案: SELECT dept_id, COUNT(*), AVG(salary) FROM employee GROUP BY dept_id; 解析:SQL 中使用 GROUP BY 进行数据的分组,结合聚合函数可以获得分组后的统计信息。另外,可以使用多个字段分成 更多的组。
36. 以下语句能否正常运行,为什么?
SELECT dept_id, COUNT(*), emp_name FROM employee GROUP BY dept_id; 答案:不能运行。解析:使用了 GROUP BY 分组之后,SELECT 列表中只能出现分组字段和聚合函数,不能再出现其他字段。上面的语句中, 按照部门分组后,再查看员工姓名的话,存在逻辑上的错误。因为每个部门有多个员工,应该显示哪个员工呢?
37. 如果只想查看平均月薪大于 10000 的部门,怎么实现?
答案: SELECT dept_id, AVG(salary) FROM employee GROUP BY dept_id HAVING AVG(salary) > 10000;
解析:HAVING 子句用于对分组后的结果进行过滤,它必须跟在 GROUP BY 之后。
38. 如果想要知道哪些部门月薪超过 5000 的员工数量大于 5,如何写 SQL 查询?
答案: SELECT dept_id, COUNT() FROM employee WHERE salary > 5000 GROUP BY dept_id HAVING COUNT() > 5; 解析:WHERE 用于对表中的数据进行过滤,HAVING 用于对分组后的数据进行过滤,两者可以结合使用。
39. 什么是连接查询?SQL 中有哪些连接查询?
答案: 连接(join)查询是基于两个表中的关联字段将数据行拼接到一起,可以同时返回两个表中的数据。SQL 支持以下连 接: 内连接(INNER JOIN),用于返回两个表中满足连接条件的数据行。左外连接(LEFT OUTER JOIN),返回左表中所有的数据行;对于右表中的数据,如果没有匹配的值,返回空值。右外连接(RIGHT OUTER JOIN),返回右表中所有的数据行;对于左表中的数据,如果没有匹配的值,返回空值。全外连接(FULL OUTER JOIN),等价于左外连接加上右外连接,返回左表和右表中所有的数据行。MySQL 不支持全外连 接。交叉连接(CROSS JOIN),也称为笛卡尔积(Cartesian product),两个表的笛卡尔积相当于一个表的所有行和另一个表的 所有行两两组合,结果的数量为两个表的行数相乘。自连接(Self Join),是指连接操作符的两边都是同一个表,即把一个表和它自己进行连接。自连接主要用于处理那些对自己 进行了外键引用的表。
40. 如何通过内连接返回员工所在的部门名称?
答案:可以使用以下两种连接语句: SELECT d.dept_id, d.dept_name, e.emp_name FROM employee e JOIN department d ON (e.dept_id = d.dept_id); SELECT d.dept_id, d.dept_name, e.emp_name FROM employee e, department d WHERE e.dept_id = d.dept_id; 解析:使用两个表的部门编号(dept_id)进行连接,可以获得员工所在的部门信息。推荐使用第一种语句,即 JOIN 和 ON 的连接方式,语义上更清晰。
41. 统计每个部门的员工数量,同时显示部门名称信息。如何使用连接查询实现?
答案: SELECT d.dept_name, COUNT(e.emp_name) FROM department d LEFT JOIN employee e ON (e.dept_id = d.dept_id) GROUP BY d.dept_name; 解析:由于某些部门可能还没有员工,不能使用内连接,而需要使用左外连接或者右外连接;否则可能缺少某些部门的结果。
42. 如何知道每个员工的经理姓名(manager)?
答案: SELECT e.emp_name AS "员工姓名", m.emp_name AS "经理姓名" FROM employee e LEFT JOIN employee m ON (m.emp_id = e.manager) ORDER BY e.emp_id; 解析:通过自连接关联两个员工表,使用左连接是因为有一个员工没有上级,他就是公司的最高领导。
43. SQL 支持哪些集合运算?
答案: SQL 中提供了以下三种集合运算: 并集运算(UNION、UNION ALL),将两个查询结果合并成一个结果集,包含了第一个查询结果以及第二个查询结果中的数 据。交集运算(INTERSECT),返回两个查询结果中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据。MySQL 不支持 INTERSECT。差集运算(EXCEPT),返回出现在第一个查询结果中,但不在第二个查询结果中的数据。MySQL 不支持 EXCEPT,Oracle 使用 MINUS 替代 EXCEPT。
44. 假设存在以下两个表:
CREATE TABLE t1(id int); INSERT INTO t1 VALUES (1); INSERT INTO t1 VALUES (2); CREATE TABLE t2(id int); INSERT INTO t1 VALUES (1); INSERT INTO t1 VALUES (3); 下列查询的结果分别是什么? -- Oracle 实现 SELECT id FROM t1 UNION SELECT id FROM t2; SELECT id FROM t1 UNION ALL SELECT id FROM t2; SELECT id FROM t1 INTERSECT SELECT id FROM t2; SELECT id FROM t1 MINUS SELECT id FROM t2;
答案: 结果分别为(1、2、3)、(1、1、2、3)、(1)以及(2)。解析:UNION 的结果集中删除了重复的数据,UNION ALL 保留了所有的数据。
45. 对于 MySQL 而言,如何实现上题中的交集运算和差集运算效果?
答案: -- 使用连接查询实现交集运算 SELECT t1.id FROM t1 JOIN t2 ON (t1.id = t2.id); -- 使用左连接查询实现差集运算 SELECT t1.id FROM t1 LEFT JOIN t2 ON (t1.id = t2.id) WHERE t2.id IS NULL; 解析:交集运算等价于基于所有字段的内连接查询,差集运算等价于左连接中右表字段为空的结果。
46. 什么是子查询?子查询有哪些类型?
答案: 子查询(subquery)是指嵌套在其他语句(SELECT、INSERT、UPDATE、DELETE、MERGE)中的 SELECT 语 句。子查询中也可以嵌套另外一个子查询,即多层子查询。子查询可以根据返回数据的内容分为以下类型: 标量子查询(scalar query):返回单个值(一行一列)的子查询。上面的示例就是一个标量子查询。行子查询(row query):返回包含一个或者多个值的单行结果(一行多列),标量子查询是行子查询的特例。表子查询(table query):返回一个虚拟的表(多行多列),行子查询是表子查询的特例。基于子查询和外部查询的关系,也可以分为以下两类:关联子查询(correlated subqueries)和非关联子查询(non- correlated subqueries)。关联子查询会引用外部查询中的列,因而与外部查询产生关联;非关联子查询与外部查询没有关 联。
47. 如何找出月薪大于平均月薪的员工?
答案: SELECT emp_name, salary FROM employee WHERE salary > (SELECT AVG(salary) FROM employee); 解析:使用子查询获得平均月薪,然后在外部查询中的 WHERE 条件中使用该值。这是一个非关联的标量子查询。
48. 以下查询语句的结果是什么?
SELECT * FROM employee WHERE dept_id = (SELECT dept_id FROM department);
答案: 执行出错。解析:外部查询的 WHERE 条件使用了等于号,但是子查询返回了多个值,此时需要使用 IN 来进行匹配。正确的查询语句如 下: SELECT * FROM employee WHERE dept_id IN (SELECT dept_id FROM department); 另外,NOT IN 用于查询不在列表中的值。
49. 哪些员工的月薪高于本部门的平均值?
答案: SELECT emp_name, salary FROM employee e WHERE salary > (SELECT AVG(salary) FROM employee WHERE dept_id = e.dept_id); 解析:使用关联子查询获取每个员工所在部门的平均月薪,然后传递给外部查询进行判断。
50. 显示员工信息时,增加一列,用于显示该员工所在部门的人数。如何编写 SQL 查询?
答案: SELECT emp_name, (SELECT COUNT(*) FROM employee WHERE dept_id = e.dept_id) AS dept_count FROM employee e; 解析:SELECT 列表中同样可以使用关联子查询。
51. 以上问题能否使用下面的查询实现?
SELECT emp_name, dept_count FROM employee e JOIN (SELECT COUNT() AS dept_count FROM employee WHERE dept_id = e.dept_id) d ON (1=1); 答案:该语句执行出错。解析:FROM 子句中不能直接使用关联子查询,因为子查询和查询处于相同的层级,不能引用前表(e)中的数据。不过,使 用横向(LATERAL)子查询可以实现该功能: SELECT emp_name, dept_count FROM employee e JOIN LATERAL (SELECT COUNT() AS dept_count FROM employee WHERE dept_id = e.dept_id) d ON (1=1);
52. 找出哪些部门中有女性员工?
答案: SELECT * FROM department d WHERE EXISTS (SELECT 1 FROM employee e WHERE e.sex ='女' AND e.dept_id = d.dept_id); 解析:EXISTS 运算符用于检查子查询中结果的存在性。针对外部查询中的每条记录,如果子查询存在结果(部门中存在女性 员工),外部查询即返回结果。NOT EXISTS 执行相反的操作。
53. 按照部门和职位统计员工的数量,同时统计部门所有职位的员工数据,再加上整个公司的员工数量。如何用一个查询实现?
答案:
-- MySQL 实现 SELECT dept_id, job_id, COUNT() FROM employee GROUP BY dept_id, job_id WITH ROLLUP; -- Oracle 实现 SELECT dept_id, job_id, COUNT() FROM employee GROUP BY ROLLUP (dept_id, job_id); 解析:GROUP BY 支持扩展的 ROLLUP 选项,可以生成按照层级进行汇总的结果,类似于财务报表中的小计、合计和总 计。MySQL 中使用 WITH ROLLUP,与 SQL 标准不太一致。
54. GROUP BY 中的另一个选项 CUBE 的作用是什么?
解析:CUBE 用于生成多维立方体式的汇总统计。例如,以下查询统计不同部门和职位员工的数量,同时统计部门所有职位的 员工数据,加上所有职位的员工数据,以及整个公司的员工数量。-- Oracle 实现 SELECT dept_id, job_id, COUNT() FROM employee GROUP BY CUBE (dept_id, job_id); 另外,GROUPING SETS 选项可以用于指定更加复杂的自定义分组方式。MySQL 暂未支持 CUBE 和 GROUPING SETS。55. 使用扩展分组时,会产生一些 NULL 值,如何确认这些 NULL 值代表的意义? 答案: 使用 GROUPING 函数,例如: SELECT CASE GROUPING(dept_id) WHEN 1 THEN '所有部门' ELSE dept_id END, CASE GROUPING(job_id) WHEN 1 THEN '所有职位' ELSE job_id END, COUNT() FROM employee GROUP BY dept_id, job_id WITH ROLLUP; 查询结果如下图所示。解析:GROUPING 函数用于判断某个统计结果是否与该字段有关。如果是,函数返回 0;否则返回 1。比如第 3 行数据是所
56. 有职位的统计,与职位无关。然后使用 CASE 表达式进行转换显示。
答案: -- MySQL 实现 WITH RECURSIVE cte (n) AS ( SELECT 1 FROM dual UNION ALL SELECT n + 1 FROM cte WHERE n < 10 ) SELECT * FROM cte; -- Oracle 实现 WITH cte (n) AS ( SELECT 1 FROM dual UNION ALL SELECT n + 1 FROM cte WHERE n < 10 ) SELECT * FROM cte; 解析:通用表表达式(WITH 子句)是一个在语句级别的临时结果集。定义之后,相当于有了一个表变量,可以在语句中多次 引用该通用表表达式。递归(RECURSIVE)形式的通用表表达式可以用于生成序列,遍历层次数据或树状结构的数据。Oracle 中省略 RECURSIVE 即可。
57. 如何获取员工在公司组织结构中的结构图,也就是从最高领导到员工的管理路径?
答案: -- MySQL 实现 WITH RECURSIVE employee_paths (emp_id, emp_name, path) AS ( SELECT emp_id, emp_name, CAST(emp_name AS CHAR(200)) FROM employee WHERE manager IS NULL UNION ALL SELECT e.emp_id, e.emp_name, CONCAT(ep.path, '->', e.emp_name)
FROM employee_paths ep JOIN employee e ON ep.emp_id = e.manager ) SELECT * FROM employee_paths ORDER BY path; 查询结果如下(显示部分内容): 解析:同样是利用递归通用表表达式实现数据的遍历。Oracle 中省略 RECURSIVE 即可。通用表表达式是 SQL 中非常强大的功能,可以帮助我们简化复杂的连接查询和子查询,并且可以完成递归处理和层次遍历。
58. 什么是窗口函数?有哪些常见的窗口函数?
答案:窗口函数(Window function)也称为分析函数。与聚合函数类似,窗口函数也是基于一组数据进行分析;但是,窗口 函数针对每一行数据都会返回一个结果。窗口函数为 SQL 提供了强大的数据分析功能。专用窗口函数主要包括 ROW_NUMBER、RANK、DENSE_RANK、PERCENT_RANK、CUME_DIST、NTH_VALUE、 NTILE、FIRST_VALUE、LAST_VALUE、LEAD 以及 LAG 等。
59. 查询员工的月薪,同时返回该员工所在部门的平均月薪。如何使用聚合函数实现?
答案: SELECT emp_name, salary, AVG(salary) OVER (PARTITION BY dept_id) FROM employee; 解析:窗口函数 AVG 基于部门(dept_id)分组后的数据计算平均月薪,为每个员工返回一条记录。窗口函数中的 PARTITION BY 作用类似于 GROUP BY 子句。虽然也可以使用关联子查询与聚合函数实现相同的功能,显然窗口函数更加简 单易懂。
60. 查询员工的月薪,同时计算其月薪在部门内的排名?
答案: SELECT emp_name, dept_id, salary, ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY salary DESC), RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC), DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) FROM employee; 解析:ROW_NUMBER、RANK 和 DENSE_RANK 都可以用于计算排名。它们不同之处在于对排名相同的数据处理方式不一 样。比如说 10、9、9、8 这四个数,ROW_NUMBER 一定会排出不同的名次(1、2、3、4);RANK 对于相同的数据排名 相同(1、2、2、4);DENSE_RANK 对于相同的数据排名相同,并且后面的排名不会跳跃(1、2、2、3)。
61. 查询员工的入职日期,同时计算其部门内在该员工之前一个和之后一个入职的员工?
答案: SELECT emp_name, dept_id, hire_date, LAG(emp_name, 1) OVER (PARTITION BY dept_id ORDER BY hire_date), LEAD(emp_name, 1) OVER (PARTITION BY dept_id ORDER BY hire_date) FROM employee; 解析:LAG 和 LEAD 用于返回排名中相对于当前行的指定偏移量之前和之后的数据。
62. 查询员工的月薪,同时计算其部门内到该员工为止的累计总月薪?
答案: SELECT emp_name, dept_id, salary, SUM(salary) OVER (PARTITION BY dept_id ORDER BY NULL ROWS UNBOUNDED PRECEDING) FROM employee; 解析:窗口函数支持定义窗口范围,UNBOUNDED PRECEDING 表示从分组内的第一行到当前行,可以用于计算累计值。
63. 查询员工的月薪,同时计算其部门内按照月薪排序后,前一个员工、当前员工以及后一个员工的平均月薪?
答案: SELECT emp_name, dept_id, salary, AVG(salary) OVER (PARTITION BY dept_id ORDER BY salary ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) FROM employee; 解析:BETWEEN N PRECEDING AND M FOLLOWING 定义了一个随着当前行移动的窗口,可以用于计算移动平均值。窗口函数为我们带来了强大的数据分析和报表生成功能,MySQL 8.0 也增加了对于窗口函数的支持。设计与开发
64. 什么是数据库(Database)?什么是数据库管理系统(DBMS)?
答案: 数据库(Database)是各种数据的集合,按照一定的数据结构进行存储和管理;数据库管理系统(Database Management System)是用于管理数据库的软件,负责数据库的创建、查询、修改等管理操作。这两者共同构成了数据库系 统(Database System)。应用程序或者最终用户通过 DBMS 访问和管理数据库。
65. 什么是关系数据库?
答案: 关系数据库是指基于关系模型的数据库。在关系模型中,用于存储数据的逻辑结构就是二维表(Table)。表由行和列 组成,行也称为记录,代表了单个实体;列也称为字段,代表了实体的某些属性。关系数据库使用 SQL 作为标准语言,执行 数据的增删改查以及各种管理操作。关系数据库还定义了三种约束完整性:实体完整性、参照完整性以及用户定义完整性。大多数主流数据库都属于关系数据库,例如 Oracle、MySQL、SQL Server 以及 PostgreSQL 等。另外,数据库领域还存在 一些非关系模型的数据库(NoSQL ),例如 Mongodb、Redis、Cassandra 等。
66. 关系型数据库有哪些约束?
答案: 关系数据库定义了以下约束: 非空约束(NOT NULL),用于限制字段不会出现空值。比如员工姓名不能为空。唯一约束(UNIQUE),用于确保字段中的值不会重复。例如,每个员工的电子邮箱不能重复。每个表可以有多个唯一约束。主键约束(Primary Key),主键是唯一标识表中每一行的字段。例如员工编号,部门编号等。主键字段必须唯一且非空,每 个表可以有且只能有一个主键。外键约束(FOREIGN KEY),用于表示两个表之间的引用关系。例如,员工属于部门,因此员工表中的部门编号字段可以定 义为外键,它引用了部门信息表中的主键。检查约束(CHECK),可以定义更多用户自定义的业务规则。例如,薪水必须大于 0 ,性别只能是男和女等。默认值(DEFAULT),用于向字段中插入默认数据。
67. OLTP 和 OLAP 的区别?
答案: OLTP OLAP 在线事务处理系统 在线分析处理系统 专注于事务数据的增删改,事务相对简单但频繁,要求响应时间快 专注于决策数据分析,查询通常比 较复杂,处理时间长 数据来源于在线业务 数据来源于各种 OLTP 通常采用规范化的设计,需要保证数据的完整性 不需要太多规范化,可以存储冗余信 息,采用多维数据模型 常见应用包括银行 ATM、在线订票系统、网上商城 常见应用包括数据仓库、报表分析、商务智能
68. 什么是数据库规范化,有哪些常见的数据库范式?
答案: 数据库规范化是一种数据库设计的方法,用于有效地组织数据,减少数据的冗余和相互之间的依赖,增加数据的一致 性。由于非规范化的数据库存在冗余,可能导致数据的插入、删除、修改异常等问题,因此引入了规范化过程。数据库规范化的程度被称为范式(Normal Form),目前已经存在第一范式到第六范式,每个范式都是基于前面范式的增强。第一范式(First Normal Form),表中的每个属性都是单值属性,每个记录都唯一,也就是需要主键。举例来说,如果员工 存在工作邮箱和个人邮箱,不能都放到一个字段,而需要拆分成两个字段; 第二范式(Second Normal Form),首先需要满足第一范式,且不包含任何部分依赖关系。举例来说,如果将学生信息和选 课信息放在一起,学号和课程编号可以作为复合主键;但此时学生的其他信息依赖于学号,即主键的一部分。通常使用单列主 键可以解决部分依赖问题; 第三范式(Third Normal Form),首先需要满足第二范式,并且不存在传递依赖关系。举例来说,如果将部门信息存储在每 个员工记录的后面,那么部门名称依赖部门编号,部门编号又依赖员工编号,这就是传递依赖。解决的方法就是将部门信息单 独存储到一个表中; 更高的范式包括 Boyce-Codd 范式、第四范式、第五范式以及第六范式等,不过很少使用到这些高级范式。对于大多数系统而 言,满足第三范式即可。另外,反规范化(Denormalization)是在完成规范化之后执行的相反过程。反规范化通过增加冗余信息,减少 SQL 连接查询 的次数,从而减少磁盘 IO 来提高查询时的性能。但是反规范化会导致数据的重复,需要更多的磁盘空间,并且增加了数据维 护的复杂性。数据库的设计是一个复杂的权衡过程,需要综合考虑各方面的因素。
69. 什么是实体关系图(ERD)?
答案:实体关系图是一种用于数据库设计的结构图,它描述了数据库中的实体,以及这些实体之间的相互关系。实体代表了一 种对象或者概念。例如,员工、部门和职位可以称为实体。每个实体都有一些属性,例如员工拥有姓名、性别、工资等属性。关系用于表示两个实体之间的关联。例如,员工属于部门。三种主要的关系是一对一、一对多和多对多关系。例如,一个员工 只能属于一个部门,一个部门可以有多个员工,部门和员工是一对多的关系。ERD 也可以按照抽象层次分为三种: 概念 ERD,即概念数据模型。概念 ERD 描述系统中存在的业务对象以及它们之间的关系。逻辑 ERD,即逻辑数据模型。逻辑 ERD 是对概念数据模型进一步的分解和细化,明确定义每个实体中的属性并描述操作和事 务。物理 ERD,即物理数据模型。物理 ERD 是针对具体数据库的设计描述,需要为每列指定类型、长度、可否为空等属性,为表
增加主键、外键以及索引等约束。下图是我们使用的三个示例表的物理 ERD(基于 MySQL 实现):
70. 数据库常见对象有哪些?
答案: 表(Table)、视图(View)、序列(Sequence)、索引(Index)、存储过程(Stored Procedure)、触发器 (Trigger)、用户(User)以及同义词(Synonym)等等。其中,表是关系数据库中存储数据的主要形式。
71. 常见 SQL 数据类型有哪些?
答案: SQL 定义了大量的数据类型,其中最常见的类型包括字符类型、数字类型、日期时间类型和二进制数据类型。日期时间类型,分为日期 DATE、时间 TIME 以及时间戳 TIMESTAMP 。二进制数据类型,主要是 BLOB。用于存储图片、文档等二进制数据。主流的数据库都支持这些常见的数据类型,但是在类型名称和细节上存在一些差异。另外,SQL 还提供其他的数据类型,例 如 XML、JSON 以及自定义的数据类型。
72. CHAR 和 VARCHAR 类型的区别?
答案: CAHR 是固定长度的字符串,如果输入的内容不够使用空格进行填充,通常用于存储固定长度的编码;VARCHAR 是 可变长度的字符串,通常用于存储姓名等长度不一致的数据。Oracle 中使用 VARCHAR2 表示变长字符串。
73. 如何创建一个表?
答案: SQL 中创建表的基本语句如下: CREATE TABLE table_name ( column_1 data_type column_constraint, column_2 data_type, ..., table_constraint ); 其中 table_name 指定了表的名称,括号内是字段的定义,创建表时可以指定字段级别的约束(column_constraint)和表级别 的约束(table_constraint)。以下是员工表(employee)的创建语句: CREATE TABLE employee ( emp_id INTEGER NOT NULL PRIMARY KEY , emp_name VARCHAR(50) NOT NULL , sex VARCHAR(10) NOT NULL , dept_id INTEGER NOT NULL , manager INTEGER , hire_date DATE NOT NULL , job_id INTEGER NOT NULL , salary NUMERIC(8,2) NOT NULL , bonus NUMERIC(8,2) , email VARCHAR(100) NOT NULL , CONSTRAINT ck_emp_sex CHECK (sex IN ('男', '女')) , CONSTRAINT ck_emp_salary CHECK (salary > 0) , CONSTRAINT uk_emp_email UNIQUE (email) , CONSTRAINT fk_emp_dept FOREIGN KEY (dept_id) REFERENCES department(dept_id) , CONSTRAINT fk_emp_job FOREIGN KEY (job_id) REFERENCES job(job_id) , CONSTRAINT fk_emp_manager FOREIGN KEY (manager) REFERENCES employee(emp_id) );
74. 如何基于已有的表复制一个表?
答案: 使用以下语句可以基于已有的表或者查询语句复制一个表: CREATE TABLE table_name AS SELECT ...; 查询的结果也会复制到新的表中,如果在查询中使用 WHERE 子句指定一个永不为真的条件,可以创建只有结构的空表。例 如,以下语句基于 employee 表创建一个空的新表: CREATE TABLE emp_new AS SELECT * FROM employee WHERE 1 = 0; MySQL 还支持以下语句复制一个空表:
CREATE TABLE emp_copy LIKE employee;
75. 什么是自增列?
答案:自增列(auto increment),也称为标识列(identity column),用于生成一个自动增长的数字。它的主要用途就是为 主键提供唯一值。Oracle 使用标准 SQL 中的 GENERATED ALWAYS AS IDENTITY 表示自增列,MySQL 使用关键字 AUTO_INCREMENT 表示自增列。以下示例演示了自增列的使用: -- Oracle 实现 CREATE TABLE emp_identity( emp_id INT GENERATED ALWAYS AS IDENTITY, emp_name VARCHAR(50) NOT NULL, PRIMARY KEY (emp_id) ); -- MySQL 实现 CREATE TABLE emp_identity( emp_id INT AUTO_INCREMENT, emp_name VARCHAR(50) NOT NULL, PRIMARY KEY (emp_id) ); INSERT INTO emp_identity(emp_name) VALUES ('张三'); INSERT INTO emp_identity(emp_name) VALUES ('李四'); INSERT INTO emp_identity(emp_name) VALUES ('王五'); SELECT * FROM emp_identity; emp_id |emp_name ------------------ 1 |张三 2 |李四 3 |王五 插入数据时,不需要为自增列提供输入值,系统自动生成一个增长的数字序列。
76. 如何修改表的结构?
答案: SQL 提供了 ALTER TABLE,用于修改表的结构: ALTER TABLE table_name action; 其中,action 表示要执行的修改操作,常见的操作包括增加列,修改列,删除列;增加约束,修改约束,删除约束等。例如, 以下语句可以为 emp_new 表增加一列: ALTER TABLE emp_new ADD weight NUMERIC(4,2) DEFAULT 60 NOT NULL; 不同的数据库实现了各自支持的修改操作,具体实现可以查看产品的文档。77. 如何删除一个表? 答案:SQL 中删除表的命令如下: DROP TABLE table_name; 如果被删除的表是其他表的外键引用表,比如部门表(department),需要先删除子表。Oracle 支持级联删除选项,同时删 除父表和子表: -- Oracle 实现 DROP TABLE department CASCADE CONSTRAINTS;
78. DROP TABLE 和 TRUNCATE TABLE 的区别?
答案: DROP TABLE 用于从数据库中删除表,包括表中的数据和表结构自身。同时还会删除与表相关的的所有对象,包括索 引、约束以及访问该表的授权。TRUNCATE TABLE 只是快速删除表中的所有数据,回收表占用的空间,但是会保留表的结 构。
79. 什么是数据库事务?
答案:在数据库中,事务(Transaction)是指一个或一组相关的操作(SQL 语句),它们在业务逻辑上是一个原子单元。一 个最常见的数据库事务就是银行账户之间的转账操作。比如从 A 账户转出 1000 元到 B 账户,其中就包含了多个操作: 查询 A 账户的余额是否足够;
从 A 账户减去 1000 元; 往 B 账户增加 1000 元; 记录本次转账流水。数据库必须保证所有的操作要么全部成功,要么全部失败。如果从 A 账户减去 1000 元成功执行,但是没有往 B 账户增加 1000 元,意味着客户将会损失 1000 元。用数据库中的术语来说,这种情况导致了数据库的不一致性。数据库事务拥有以下 4 个特性:原子性、一致性、隔离性以及持久性(ACID)。Atomic,原子性。一个事务包含的所有 SQL 语句要么全部成功,要么全部失败。例如,某个事务需要更新 100 条记录,但是 在更新到一半时,系统出现故障,数据库必须保证能够回滚已经修改过的数据,就像没有执行过该事务一样。Consistency,一致性。事务开始之前,数据库位于一致性的状态;事务完成之后,数据库仍然位于一致性的状态。例如,银 行转账事务中,如果一个账户扣款成功,但是另一个账户加钱失败,那么就会出现数据不一致(此时需要回滚已经执行的扣款 操作)。另外,数据库还必须保证满足完整性约束,比如账户扣款之后不能出现余额为负数(可以在余额字段上添加检查约 束)。Isolation,隔离性。隔离性与并发事务有关,一个事务的影响在其完成之前对其他事务不可见,多个并发的事务之间相互隔 离。例如,账户 A 向账户 B 转账的过程中,账户 B 查询的余额应该是转账之前的数目;如果多人同时向账户 B 转账,结果也 应该保持一致性,就像依次转账的结果一样。Durability,持久性。已经提交的事务必须永久生效,即使发生断电、系统崩溃等故障,数据库都不会丢失数据。数据库通常 使用重做日志(redo log)来保证数据的持久性。
80. 数据库事务支持哪些隔离级别?
答案: 当数据库存在并发访问时,可能导致以下问题: 更新丢失,当两个事务同时更新某一数据时,后者会覆盖前者的结果; 脏读,当一个事务正在操作某些数据但并未提交时,如果另一个事务读取到了未提交的结果,就出现了脏读; 不可重复读,第一个事务第一次读取某一记录后,该数据被另一个事务修改提交,第一个事务再次读取该记录时结果发生了改 变; 幻象读,第一个事务第一次读取数据后,另一个事务增加或者删除了某些数据,第一个事务再次读取时结果的数量发生了变 化。为了解决并发访问可能导致的问题,数据库提供了不同的事务隔离级别: 脏读 不可重复读 幻读 「读未提交」 可能 可能 可能 「读已提交」 不会 可能 可能 「可重复读」 不会 不会 可能 「序列化」 不会 不会 不会 Oracle 默认的隔离级别为 READ COMMITTED,MySQL 中 InnoDB 存储引擎的默认隔离级别为 REPEATABLE READ。
81. MySQL 中的 InnoDB 和 MyISAM 存储引擎有什么区别?
答案:MySQL 的一大特点就是支持不同的存储引擎,存储引擎用于管理表中的数据并提供数据操作接口。MySQL使用以下命 令查看系统支持的存储引擎: SHOW ENGINES; 主要的存储引擎包括 InnoDB 和 MyISAM。自从 MySQL 5.5 版本之后,默认使用 InnoDB 存储引擎。InnoDB 存储引擎支持事务(ACID),提供了事务提交、回滚以及故障恢复能力,能够确保数据不会丢失。InnoDB 支持行级 锁和多版本一致性的非锁定读取,能够提高并发访问和性能。InnoDB 使用聚集索引存储数据,能够减少使用主键查找时的磁 盘 I/O。另外,InnoDB 还支持外键约束,能够维护数据的完整性。MyISAM 存储引擎数据文件占用的空间更小。MyISAM 采用表级锁,限制了同时读写的性能,通常用于只读或者以读为主的应 用。下表是两者对于各种功能特性的支持比较。特性 MyISAM InnoDB 「B 树索引」 支持 支持 「备份/时间点恢复」 支持 支持 「聚集索引」 不支持 支持 「压缩数据」 支持 支持 「数据缓存」 不支持 支持 「加密数据」 支持 支持 「外键支持」 不支持 支持 「全文搜索索引」 支持 支持 「空间数据类型」 支持 支持 「空间数据索引」 支持 支持 「哈希索引」 不支 持 不支持 「索引缓存」 支持 支持 「锁定级别」 表级 行级 「MVCC」 不支持 支持 「复制」 支持 支持 「存储限制」 256TB 64TB 「数据库事务」 不支持 支 持 一般情况下,使用默认的 InnoDB 存储引擎即可,除非是有特殊的需求和应用场景。
82. 如何插入数据?
答案: SQL 主要提供了两种数据插入的方式: INSERT INTO ... VALUES ... INSERT INTO ... SELECT ... 第一种方式通过提供字段的值插入数据,例如: INSERT INTO department(dept_id, dept_name) VALUES (1, '行政管理部');
MySQL 支持一次提供多个记录值的方式插入多条记录: -- MySQL 实现 INSERT INTO department(dept_id, dept_name) VALUES (1, '行政管理部'), (2, '人力资源部'), (3, '财务部'); 第二种方式使用查询的结果值插入多条数据,例如: INSERT INTO emp_new SELECT * FROM employee; 以上查询将员工表种的所有数据插入表 emp_new 中。
83. 如何修改数据?
答案:SQL 中的 UPDATE 语句用于更新表中的数据: UPDATE table_name SET column1 = expr1, column2 = expr2, ... [WHERE condition]; 其中,table_name 是要更新的表名;SET 子句指定了要更新的列和更新后的值,多个字段使用逗号进行分隔;满足 WHERE 条件的数据行才会被更新,如果没有指定条件,将会更新表中所有的行。以下语句为表 emp_new 中的员工“赵云”增加 1000 元的月薪: UPDATE emp_new SET salary = salary + 1000 WHERE emp_name = '赵云';
84. 如何删除数据?
答案: SQL 中用于删除数据的命令主要是 DELETE 语句。DELETE FROM table_name [WHERE conditions]; DELETE 语句删除满足条件的数据;如果不指定 WHERE 子句,将会删除表中的所有数据。以下语句将会清空表 emp_new 中的所有数据: DELETE FROM emp_new; Oracle 中可以省略 FROM 关键字。
85. 删除数据时,DELETE 和 TRUNCATE 语句的区别?
DELETE TRUNCATE 用于从表中删除指定的数据行。用于删除表中的所有行,并释放包含该表的存储空间。删除数据后,可以提交或者回滚。操作无 法回滚。属于数据操作语言(DML)。属于数据定义语言(DDL)。删除数据较多时比较慢。执行速度很快。通常来说,使用 DELETE 语句删除数据时需要指定一个 WHERE 条件,否则会删除表中所有的数据;使用 TRUNCATE 语句 需要小心,因为它会直接清空数据。
86. 什么是 MERGE 或者 UPSERT 操作?
答案:
MERGE 是 SQL:2003 标准中引入的一个新的数据操作命令,它可以同时完成 INSERT 和 UPDATE 的操作,甚至 DELETE 的功能。基本的 MERGE 语句如下: MEGRE INTO target_table [AS t_alias] USING source_table [AS s_alias] ON (condition) WHEN MATCHED THEN UPDATE SET column1 = expr_1, column2 = expr_2, ... WHEN NOT MATCHED THEN INSERT (column1, column2, ...) VALUES (expr_1, expr_2, ...); 其中,target_table 是合并的目标表;USING 指定了数据的来源,可以是一个表或者查询结果集;ON 指定了合并操作的判断 条件,对于数据源中的每一行,如果在目标表中存在满足条件的记录,执行 UPDATE 操作更新目标表中对应的记录;如果不 存在匹配的记录,执行 INSERT 在目标表中插入一条新记录。Oracle 提供了 MERGE 语句的支持,MySQL 使用另一种专用的 UPSERT 语法: INSERT INTO target_table (column1, column2, ...) SELECT col1, col2, ... FROM source_table s
ON DUPLICATE KEY UPDATE column1 = s.col1, column2 = s.col2, ...;
87. 什么是索引?有哪些类型的索引?
答案:
索引(Index)是一种数据结构,主要用于提高查询的性能。索引类似于书籍最后的索引,它指向了数据的实际存储位 置;索引需要占用额外的存储空间,在进行数据的操作时需要额外的维护。另外,索引也用于实现约束,例如唯一索引用于实 现唯一约束和主键约束。不同的数据库支持的索引不尽相同,但是存在一些通用的索引类型,主要包括: B/B+ 树索引,使用平衡树或者扩展的平衡树结构创建索引。这是最常见的一种索引,几乎所有的数据库都支持。这种索引通 常用于优化 =、<、、BETWEEN、IN 以及字符串的前向匹配查询。Hash 索引,使用数据的哈希值进行索引。主要用于等值(=)和 IN 查询。聚集索引,将表中的数据按照索引的结构(通常是主键)进行存储。MySQL 中称为聚集索引,Oracle 中称为索引组织表 (IOT)。非聚集索引,也称为辅助索引。索引与数据相互独立,MySQL InnoDB 中的索引存储的是主键值,Oracle 中存储的时物理地 址。全文索引,用于支持全文搜索。唯一索引与非唯一索引。唯一索引可以确保被索引的数据不会重复,可以实现数据的唯一性约束。非唯一索引仅仅用于提高查 询的性能。单列索引与多列索引。基于多个字段创建的索引称为多列索引,也叫复合索引。函数索引。基于函数或者表达式的值创建的索引。索引是优化 SQL 查询的一个有效方法,但是索引本身也需要付出一定的代价,过渡的索引可能给系统带来负面的影响。
88. 如何查看 SQL 语句的执行计划?
答案: 查询计划是数据库执行 SQL 的具体方式。包括读取表的方式,使用全表扫描还是使用索引;表的连接方式;预计占用 的 CPU、IO 等资源。查看查询计划是进行 SQL 性能诊断和优化的基础。主流数据库都提供了类似的查看执行计划的方式: EXPLAIN 命令。MySQL 查看执行计划: EXPLAIN SELECT * FROM employee e WHERE emp_id = 5;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | e | const | PRIMARY | PRIMARY | 4 | const | 1 | 100 |
由于 emp_id 是主键,执行计划显示通过主键索引(PRIMARY)进行查询。
另外,也可以通过一些图形工具或者数据库提供的其他方式查看 SQL 语句的执行计划。
89. 以下查询语句会不会使用索引?
CREATE INDEX idx ON test (col); SELECT COUNT() FROM test WHERE col * 12 = 2400; 答案: 不会。解析:针对索引字段进行运算或者使用函数之后,会导致无法使用索引。可以将运算改到操作符的右边: SELECT COUNT() FROM test WHERE col = 2400 / 12;
90. 针对以下查询,如何创建索引?
SELECT * FROM test WHERE col1 = 100 AND col2 = 'SQL' SELECT * FROM test WHERE col2 = 'NoSQL';
答案:
创建一个复合索引,并且将 col2 放在前面: CREATE INDEX idx ON test (col2, col1); 解析:创建复合索引时需要注意字段的顺序。当查询条件使用索引左侧的字段时,可以有效的利用索引。91. 员工表的 email 字段上存在唯一索引,以下查询会不会使用该索引? SELECT * FROM employee e WHERE email LIKE 'zhang%'; 答案:会。解析:对于 LIKE 运算符,如果通配符不在最左侧,可以使用索引。但是 ‘%zhang’ 和 ‘%zhang%’ 无法使用索引。
92. 多表连接查询有哪三种执行方式?
答案: 数据库在实际执行连接查询时,可以采用以下三种物理方式: 嵌套循环连接(Nested Loop Join),针对驱动表中的每条记录,遍历另一个表找到匹配的数据,相当于两层循环。Nested Loop Join 适用于驱动表数据比较少,并且连接的表中有索引的时候。排序合并连接( Sort Merge Join),先将两个表中的数据基于连接字段进行排序,然后合并。Sort Merge Join 通常用于没有 索引,并且数据已经排序的情况,比较少见。哈希连接(Hash Join),将一个表的连接字段计算出一个哈希表,然后从另一个表中一次获取记录并计算哈希值,根据两个 哈希值来匹配符合条件的记录。Hash Join 对于数据量大,且没有索引的情况下可能性能更好。MySQL 目前只支持 Nested Loop Join,不建议使用多个表的连接查询,因为多层循环嵌套会导致查询性能的急剧下降。
93. 什么是视图?
答案: 视图(View)是一个存储在数据库中的 SELECT 语句。视图也被称为虚表,在许多情况下可以当作表来使用。视图与 表最大的区别在于它自身不包含数据,数据库中存储的只是视图的定义语句。视图具有以下优点: 替代复杂查询,减少复杂性; 提供一致性接口,实现业务规则; 控制对于表的访问,提高安全性。但是,使用视图也需要注意以下问题: 不当使用可能会导致查询的性能问题; 可更新视图(Updatable View)需要满足许多限制条件。
94. 创建一个视图,包含员工所在部门、所属职位、姓名、性别以及邮箱信息?
答案:
CREATE OR REPLACE VIEW emp_info AS SELECT d.dept_name,j.job_title, e.emp_name, e.sex, e.email FROM employee e JOIN department d ON (d.dept_id = e.dept_id) JOIN job j ON (j.job_id = e.job_id); SELECT * FROM emp_info WHERE emp_name = '法正'; 解析:视图的定义中可以像其他查询语句一样包含任意复杂的多表连接、子查询、以及集合操作等。
95. 什么是可更新视图?
答案:
可更新视图是指可以通过对视图的 INSERT、UPDATE、DELETE 等操作,实现对视图对应的基础表的数据修改。通 常来说,可更新视图必须是简单的查询语句,不能包含以下内容: 聚合函数,例如 SUM、AVG 以及 COUNT 等; DISTINCT 关键字; GROUP BY 或者 HAVING 子句; 集合操作符 UNION 等; 不同的数据库特定的限制 简单来说,可能导致无法通过视图找到对应基础表中的数据的操作都不允许。以下语句创建了一个简单的视图,只包含了开发 部门的员工信息,并且隐藏了工资等敏感信息: CREATE OR REPLACE VIEW emp_devp AS SELECT emp_id, emp_name, sex, manager, hire_date, job_id, email FROM employee WHERE dept_id = 4 WITH CHECK OPTION; 其中的 WITH CHECK OPTION 确保无法通过视图修改超出其可见范围之外的数据。以下是通过该视图修改员工信息的操作: UPDATE emp_devp SET email = 'zhaoyun@sanguo.net' WHERE emp_name = '赵云'; 如果尝试更新非开发部门的员工,不会更新到任何数据: UPDATE emp_devp SET email = 'zhangfei@sanguo.net' WHERE emp_name = '张飞';
96. 什么是存储过程?
答案: 存储过程(Stored Procedure)是存储在数据库中的程序,它是数据库对 SQL 语句的扩展,提供了许多过程语言的功 能,例如变量定义、条件控制语句、循环语句、游标以及异常处理等等。一旦创建之后,应用程序(Java、C++ 等)可以通 过名称调用存储过程。存储过程的优点包括: 提高应用的执行效率。存储过程经过编译之后存储在数据库中,执行时可以进行缓存,可以提高执行的速度; 减少了应用与数据库之间的数据传递。调用存储过程时,只需要传递参数,业务代码已经存在数据中; 存储过程可以实现代码的重用。不同的应用可以共享相同的存储过程; 存储过程可以提高安全性。存储过程实现了代码的封装,应用程序通过存储过程进行数据访问,而不需要之间操作数据表。另一方面,存储过程也存在一些缺点: 不同数据库的实现不同,Oracle 中称为 PL/SQL,MySQL 中称为 PSM,其他数据库也都有各自的实现; 存储过程需要占用数据库服务器的资源,包括 CPU、内存等,而数据库的扩展性不如应用; 存储过程的开发和维护需要专业的技能。是否使用存储过程需要考虑具体的应用场景。对于业务变化快的互联网应用,通常倾向于将业务逻辑放在应用层,便于扩展; 而对于传统行业的应用,或者复杂的报表分析,合理使用存储过程可以提高效率。
97. 如何创建存储过程?
答案:使用 CREATE PROCEDURE 语句创建存储过程,不同的数据库存在一些实现上的差异。以下语句创建了一个为员工 表增加员工的存储过程: -- MySQL 实现
DELIMITER $$
CREATE PROCEDURE insert_employee(IN pi_emp_id INT, IN pi_emp_name VARCHAR(50),
IN pi_sex VARCHAR(10),
IN pi_dept_id INT,
IN pi_manager INT,
IN pi_hire_date DATE,
IN pi_job_id INT,
IN pi_salary NUMERIC,
IN pi_bonus NUMERIC,
IN pi_email VARCHAR(100))
BEGIN
DECLARE EXIT HANDLER FOR 1062
SELECT CONCAT('Duplicate employee: ', pi_emp_id);
INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email)
VALUES(pi_emp_id, pi_emp_name, pi_sex, pi_dept_id, pi_manager, pi_hire_date, pi_job_id, pi_salary, pi_bonus, pi_email);
END$$ DELIMITER ;
-- Oracle 实现
CREATE OR REPLACE PROCEDURE insert_employee(IN pi_emp_id INT,
IN pi_emp_name VARCHAR2,
IN pi_sex VARCHAR2,
IN pi_dept_id INT,
IN pi_manager INT,
IN pi_hire_date DATE,
IN pi_job_id INT,
IN pi_salary NUMERIC,
IN pi_bonus NUMERIC,
IN pi_email VARCHAR2)
BEGIN
INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager,
hire_date, job_id, salary, bonus, email)
VALUES(pi_emp_id, pi_emp_name, pi_sex, pi_dept_id, pi_manager, pi_hire_date, pi_job_id, pi_salary, pi_bonus, pi_email);
EXCEPTION
WHEN dup_val_on_index THEN
RAISE_APPLICATION_ERROR(SQLCODE, 'Duplicate employee: '||pi_emp_id); WHEN OTHERS THEN
RAISE;
END;
然后可以调用存储过程增加新的员工: CALL (26, '张三', '男', 5, 2, CURRENT_DATE, 10, 5000, NULL, 'zhangsan@shuguo.com');
98. 如何删除存储过程?
答案:
使用 DROP PROCEDURE 命令删除存储过程,使用 DROP FUNCTION 命令删除存储函数。以下语句删除存储过程 insert_employee: DROP PROCEDURE insert_employee;
99. 什么是触发器?
答案:
触发器(Trigger)是一种特殊的存储过程,当某个事件发生的时候自动执行触发器中的操作。最常见的触发器是基于 表的触发器,包括 INSERT、UPDATE 和 DELETE 语句触发器。根据触发的时间,又可以分为 BEFORE 和 AFTER 触发 器。另外,根据触发的粒度,又可以分为行级触发器和语句级触发器。触发器典型的应用场景包括: 审计表的数据修改。某些表中可能包含敏感信息,比如员工的薪水,要求记录所有的修改历史。这种需求可以通过创建针对员 工表的 语句级 UPDATE 触发器实现。实现复杂的业务约束。在触发器中增加业务检查和数据验证,阻止非法的业务操作。不过,触发器也可能带来一些问题。比如增加数据库服务器的压力;逻辑隐藏在数据库内部,应用端无法进行控制。触发器的管理主要包括创建和删除: CREATE TRIGGER 用于创建触发器。
DROP TRIGGER 用于删除触发器。另外,Oracle 还支持 DDL 触发器和系统事件触发器。
100. 为员工表创建一个审计表和审计触发器,记录每次修改员工月薪的操作。
答案:
CREATE TABLE employee_audit ( emp_id INTEGER NOT NULL , salary_old NUMERIC(8,2) NOT NULL , salary_new NUMERIC(8,2) NOT NULL , update_ts TIMESTAMP NOT NULL ); -- MySQL 实现
DELIMITER $$
CREATE TRIGGER employee_audit
BEFORE UPDATE ON employee
FOR EACH ROW
BEGIN
IF OLD.salary NEW.salary THEN
INSERT INTO employee_audit(emp_id, salary_old, salary_new, update_ts) VALUES(OLD.emp_id, OLD.salary, NEW.salary, CURRENT\_TIMESTAMP); END IF;
END$$
DELIMITER ;
-- Oracle 实现
CREATE OR REPLACE TRIGGER employee_audit
BEFORE UPDATE ON employee
FOR EACH ROW
DECLARE
BEGIN
IF :OLD.salary :NEW.salary THEN
INSERT INTO employee_audit(emp_id, salary_old, salary_new, update_ts) VALUES(:OLD.emp_id, :OLD.salary, :NEW.salary, CURRENT\_TIMESTAMP); END IF;
END;
不同的数据库在语法上存在一些差异,但是基本的原理相同。然后可以修改员工的月薪,并且查看审计的结果: UPDATE employee SET salary = salary + 1000 WHERE emp_name = '张飞'; SELECT * FROM employee_audit;
结语
这篇贴子到这里就结束了,最后,希望看这篇帖子的朋友能够有所收获。
面试题获取方式:留言【SQL面试题】即可
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!