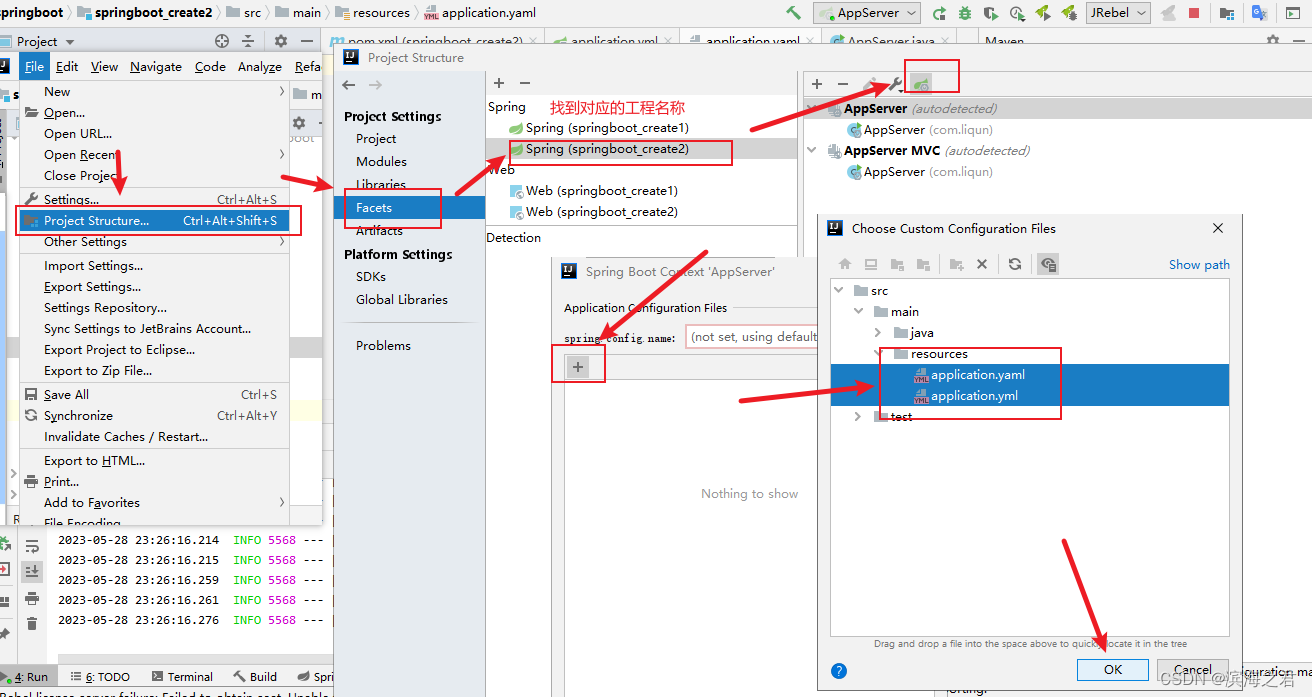
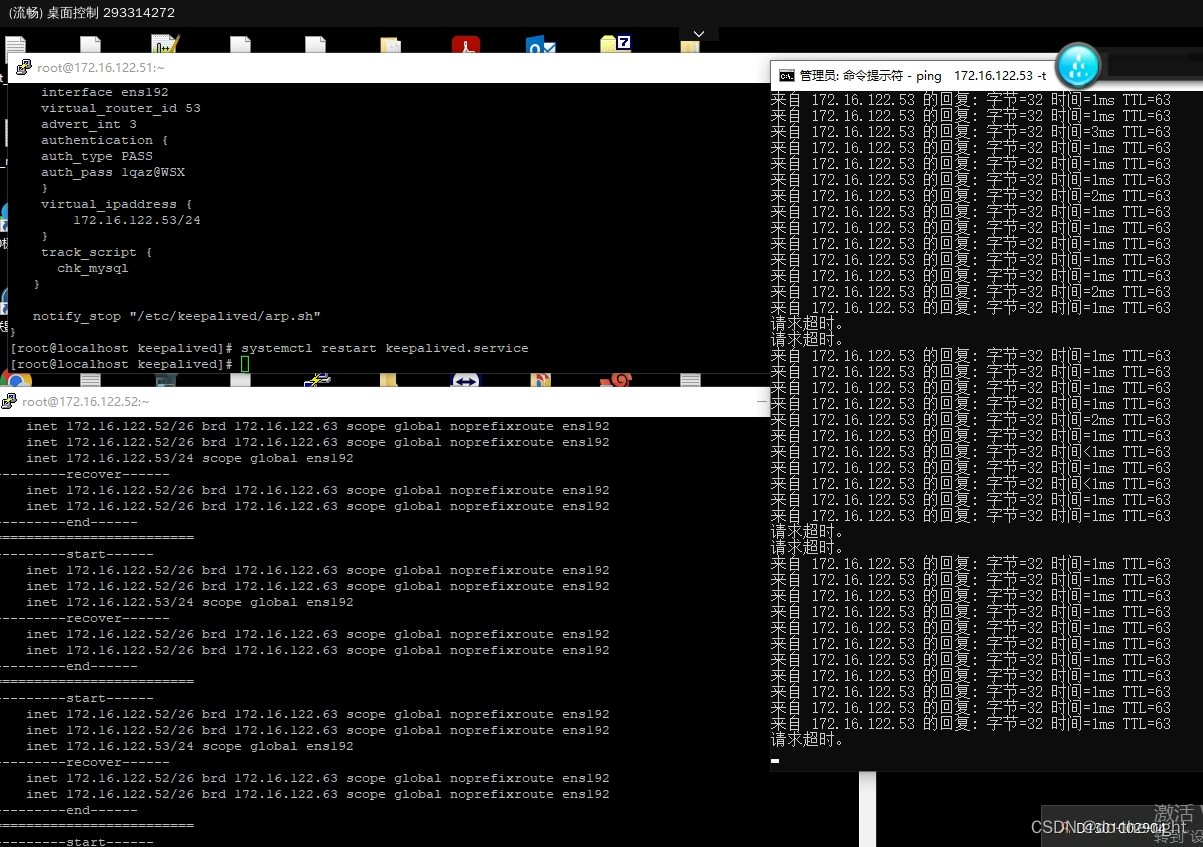
jieba.NET除分词和关键词提取功能之外,还有一些其它用法,本文基于参考文献学习并记录。
设置停用词
提取关键词时,部分词语可能不重要或者并非所需的词语,此时可以通过设置停用词,在提取关键词时过滤掉指定的停用词。jieba.NET的停用词词库放在Resources文件夹下的stopwords.txt,程序启动时会自动加载该文件。
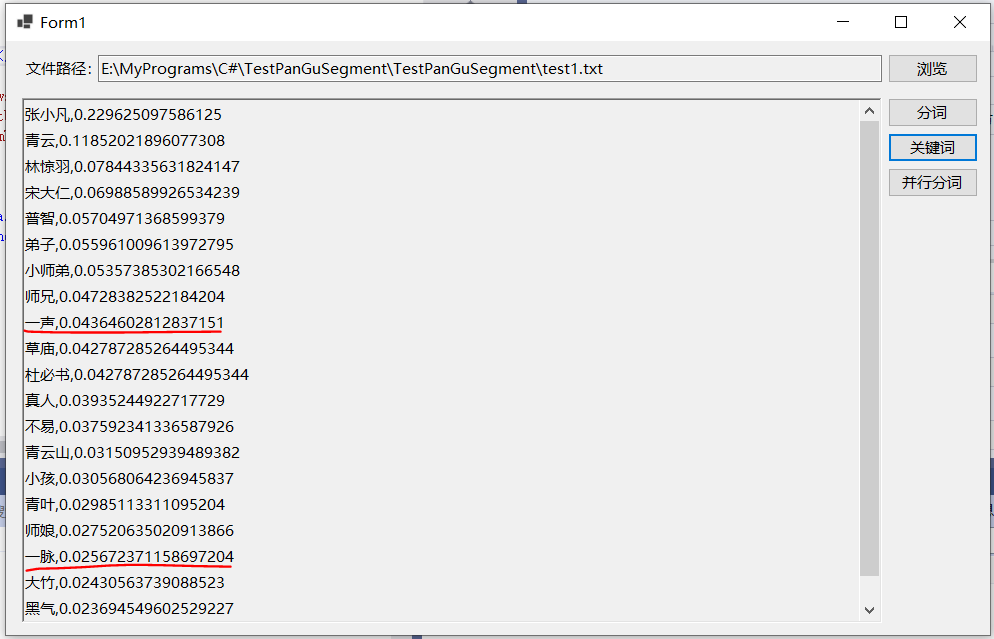
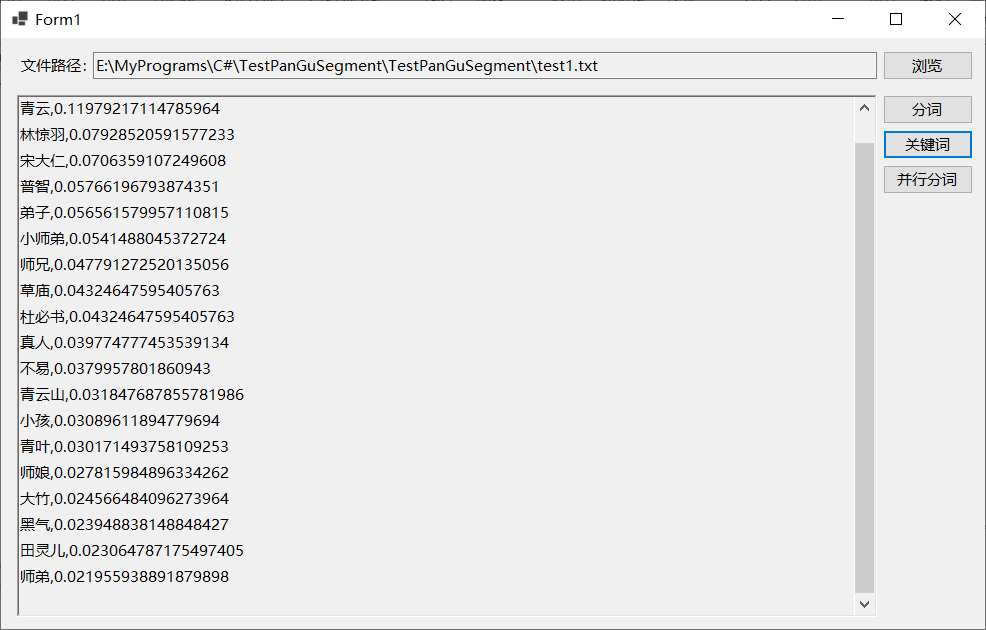
以之前的测试文本为例,提取前20个关键词,将其中的“一声”、“一脉”两次设置停用词,即在stopwords.txt后追加这两词,再次运行程序提取关键词,可以看到这两个词已经消息。
词性标注
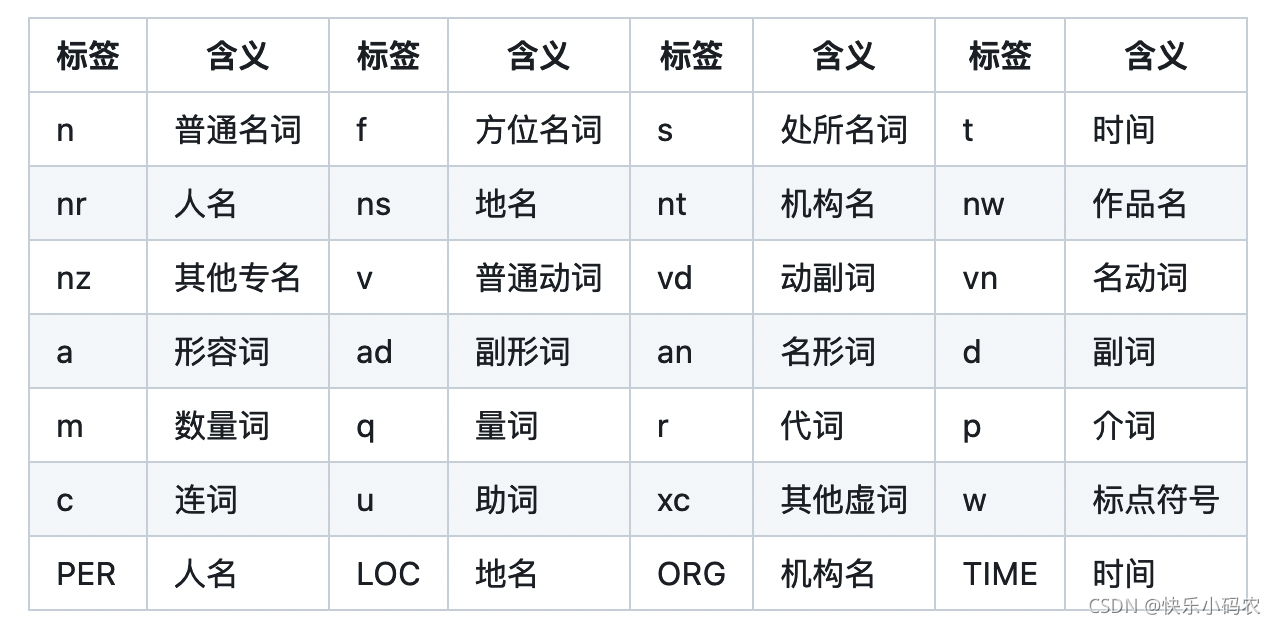
jieba.NET中的PosSegmenter类支持在分词的同时,为每个词添加词性标注,词性标注的含义表如下所示(图片来自参考文献):
测试代码及程序运行效果如下所示:
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
var segmenter = new PosSegmenter();
var tokens = segmenter.Cut(tr.ReadToEnd());
txtResult.Text = string.Join(" ", tokens.Select(token => string.Format("{0}/{1}", token.Word, token.Flag)));
}

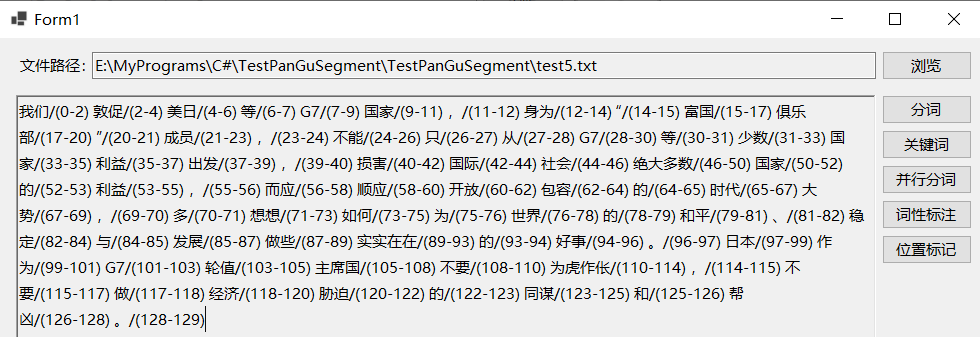
获取分词词语的起始位置
jieba.NET中的JiebaSegmenter类的Tokenize函数除了返回分词词语之外,还会返回每个分词词语的起止位置。该函数支持默认模式和搜索模式两种分词方式,根据官网说明及测试,默认模式类似于分词函数的精确模式分词,每个词语只会被分一次,而搜索模式类似于全模式及搜索引擎模式分词,把所有可能的分词形式都返回。程序运行效果如下所示:
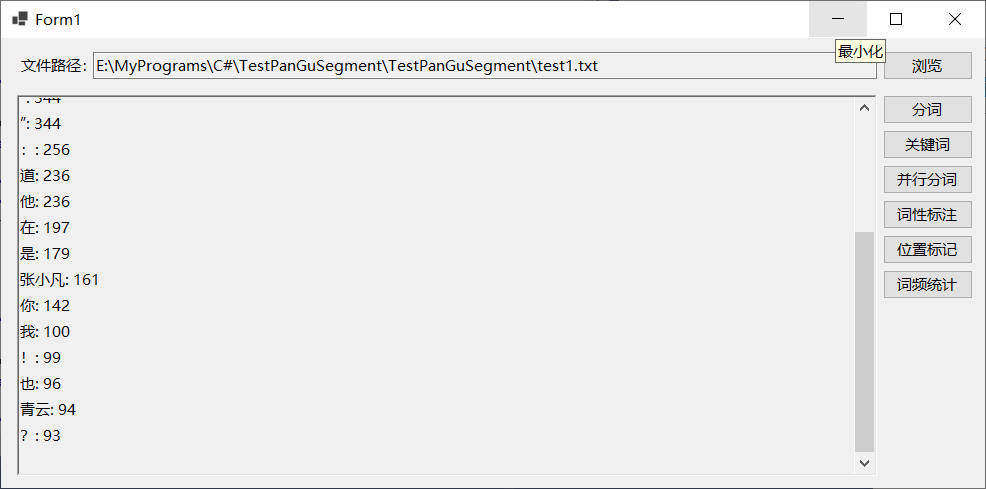
词频统计
jieba.NET中的Counter类支持统计词频,也即指定文本中的词语的使用次数。示意代码请见参考文献3,测试程序运行效果如下所示:
查找关键词
jieba.NET中的KeywordProcessor类预先指定的一组关键词,然后在指定的文本中查找存在哪些关键词,也即查找指定的关键词在文本中是否存在。
除了上述用法之外,jieba.NET的文档中还介绍了与Lucene.NET的集成的方式,后续会学习并进行测试。
参考文献:
[1]https://github.com/linezero/jieba.NET
[2]https://www.jianshu.com/p/6f47b670fcb0
[3]https://github.com/anderscui/jieba.NET
[4]https://github.com/JimLiu/Lucene.Net.Analysis.PanGu
[5]https://github.com/apache/lucenenet
[6]https://blog.csdn.net/lijingguang/article/details/127262360
[7]https://blog.51cto.com/u_15834522/5766716
[8]https://www.cnblogs.com/dacc123/p/8431369.html
[9]https://blog.csdn.net/wangkun9999/article/details/1574114
[10]https://baijiahao.baidu.com/s?id=1744467856047121907&wfr=spider&for=pc
[11]https://blog.csdn.net/qq_57832544/article/details/127806572
[12]https://blog.csdn.net/u012744245/article/details/119967119