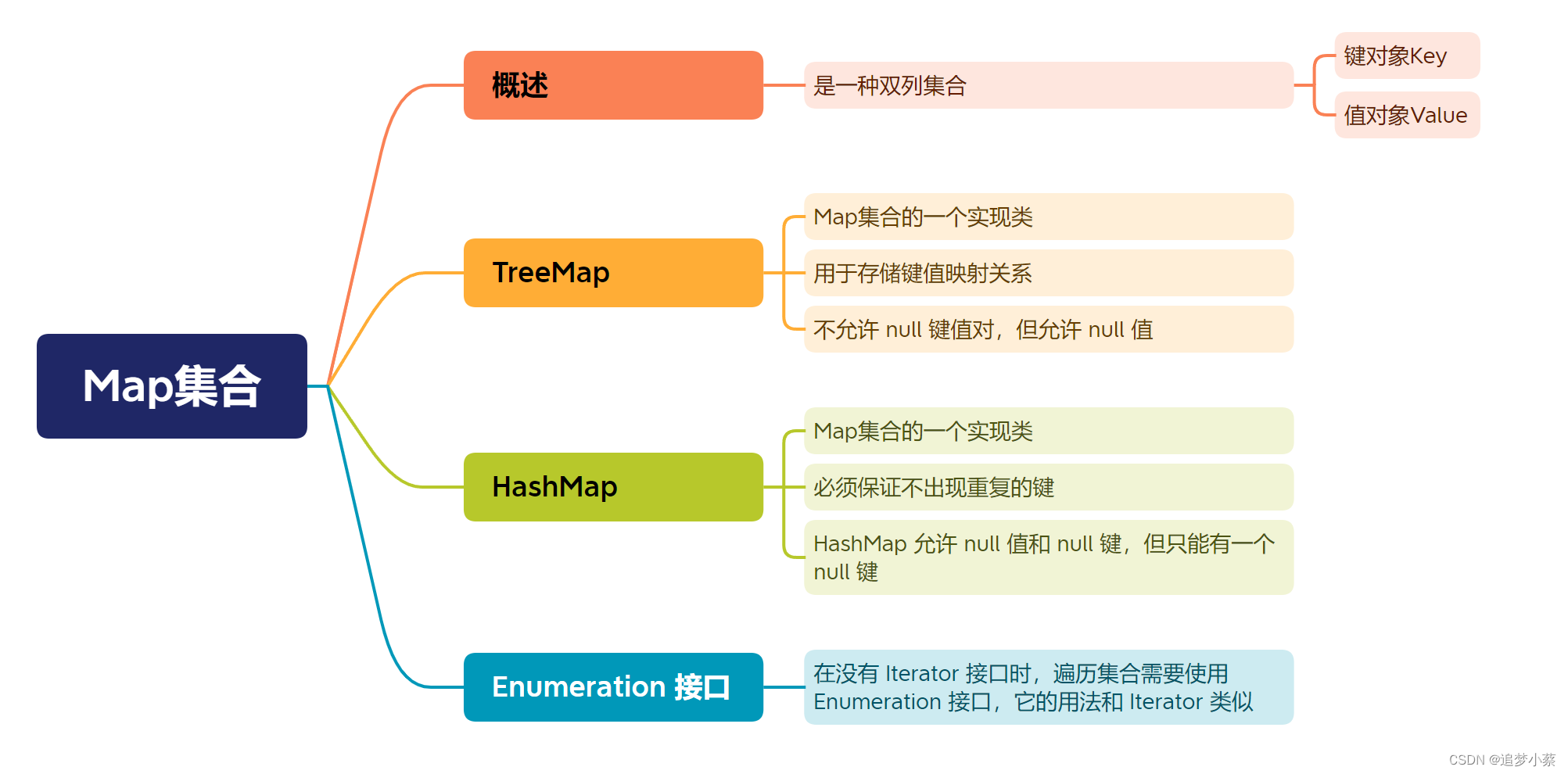
一、概述
蚂蚁在寻找食物源时,会在其经过的路径上释放一种信息素,并能够感知其它蚂蚁释放的信息素。信息素浓度的大小表征到食物源路径的远近,信息素浓度越高,表示对应的路径距离越短。通常,蚂蚁会以较大的概率优先选择信息素浓度较高的路径,并释放一定量的信息素,以增强该条路径上的信息素浓度,这样会形成一个正反馈。最终,蚂蚁能够找到一条从巢穴到食物源的最佳路径,即最短距离。值得一提的是,生物学家同时发现,路径上的信息素浓度会随着时间的推进而逐渐衰减。
举一个例子来进行说明:
蚂蚁从A点出发,速度相同,食物在D点,可能随机选择路线ABD或ACD。假设初始时每条分配路线一只蚂蚁,每个时间单位行走一步,本图为经过9个时间单位时的情形:走ABD的蚂蚁到达终点,而走ACD的蚂蚁刚好走到C点,为一半路程。
经过18个时间单位时的情形:走ABD的蚂蚁到达终点后得到食物又返回了起点A,而走ACD的蚂蚁刚好走到D点。
假设蚂蚁每经过一处所留下的信息素为一个单位,则经过36个时间单位后,所有开始一起出发的蚂蚁都经过不同路径从D点取得了食物,此时ABD的路线往返了2趟,每一处的信息素为4个单位,而ACD的路线往返了一趟,每一处的信息素为2个单位,其比值为2:1
寻找食物的过程继续进行,则按信息素的指导,蚁群在ABD路线上增派一只蚂蚁(共2只),而ACD路线上仍然为一只蚂蚁。再经过36个时间单位后,两条线路上的信息素单位积累为12和4,比值为3:1。
若按以上规则继续,蚁群在ABD路线上再增派一只蚂蚁(共3只),而ACD路线上仍然为一只蚂蚁。再经过36个时间单位后,两条线路上的信息素单位积累为24和6,比值为4:1。
若继续进行,则按信息素的指导,最终所有的蚂蚁会放弃ACD路线,而都选择ABD路线。这也就是前面所提到的正反馈效应。
20世纪90年代初,意大利学者M.Dorigo等人提出了模拟自然界蚂蚁群体觅食行为的蚁群算法。其基本思想是:用蚂蚁的行走路径表示待优化问题的可行解,整个蚂蚁群体的所有路径构成待优化问题的解空间。路径较短的蚂蚁释放的信息素量较多,随着时间的推进,较短的路径上积累的信息素浓度逐渐增高,选择该路径上的蚂蚁个数也越来越多。最终,整个蚂蚁会在正反馈的作用下集中到最佳的路径上,此时对应的便是待优化问题的最优解。
蚁群算法的基本原理:
1、蚂蚁在路径上释放信息素。
2、碰到还没走过的路口,就随机挑选一条路走。同时,释放与路径长度有关的信息素。
3、信息素浓度与路径长度成反比。后来的蚂蚁再次碰到该路口时,就选择信息素浓度较高路径。
4、最优路径上的信息素浓度越来越大。
5、最终蚁群找到最优寻食路径。
二、最基本的蚁群算法解决TSP问题
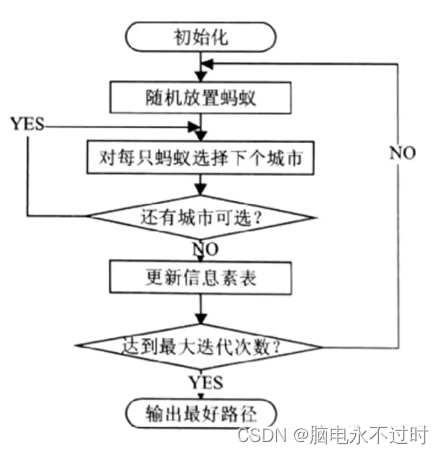
1、初始化(各个参数): 在计算之初需要对相关的参数进行初始化,如蚂蚁数量m、信息素因子α、启发函数因子β、信息素挥发因子ρ、信息素常数Q、最大迭代次数t等等。
2、构建解空间: 将各个蚂蚁随机地放置于不同的出发点,对每个蚂蚁k(k=1,2,……,m),根据信息素等因素计算其下一个待访问的城市,直到每个蚂蚁访问完所有的城市。
3、更新信息素: 计算各个蚂蚁经过的路径长度L,记录当前迭代次数中的最优解(最短路径)。同时,对各个城市连接路径上的信息素浓度进行更新。
4、判断是否终止: 若迭代次数小于最大迭代次数则迭代次数加一,清空蚂蚁经过路径的记录表,并返回步骤二;否则终止计算,输出最优解。
三、步骤详解
1. 初始化参数
设整个蚂蚁群体中蚂蚁的数量为m ,城市的数量为n,城市与城市之间的距离为,t时刻城市i 与城市j 连接路径上的信息素浓度为
。初始时刻,各个城市间连接路径上的信息素浓度相同,不妨设
=
。
注:在初始化之前需要根据城市位置坐标,计算两两城市间的相互距离,从而得到对称的距离矩阵。由于启发函数为,为了保证分母
不为零,需要将距离矩阵对角线上的元素零,修正为一个非常小的正数(如
等)。
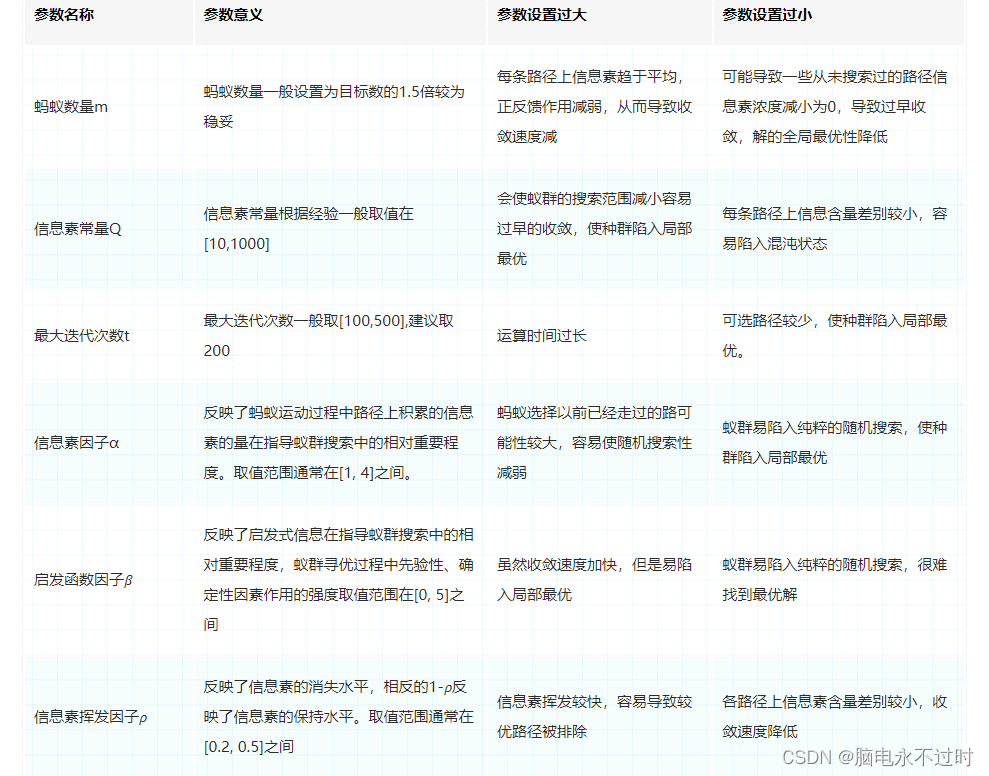
各个参数具有的基本含义:
很明显算法的关键步骤是:
第二步中的怎么根据信息素等因素计算其下一个待访问的城市
第三步中的怎么更新信息素
2. 路径构建:怎么根据信息素等因素计算其下一个待访问的城市
每个蚂蚁都随机选择一个城市作为其出发城市,并维护一个路径记忆向量,用来存放该蚂蚁依次经过的城市。 蚂蚁在构建路径的每一步中,按照轮盘赌规则(也可以选择其他的)选择下一个要到达的城市。
轮盘赌:
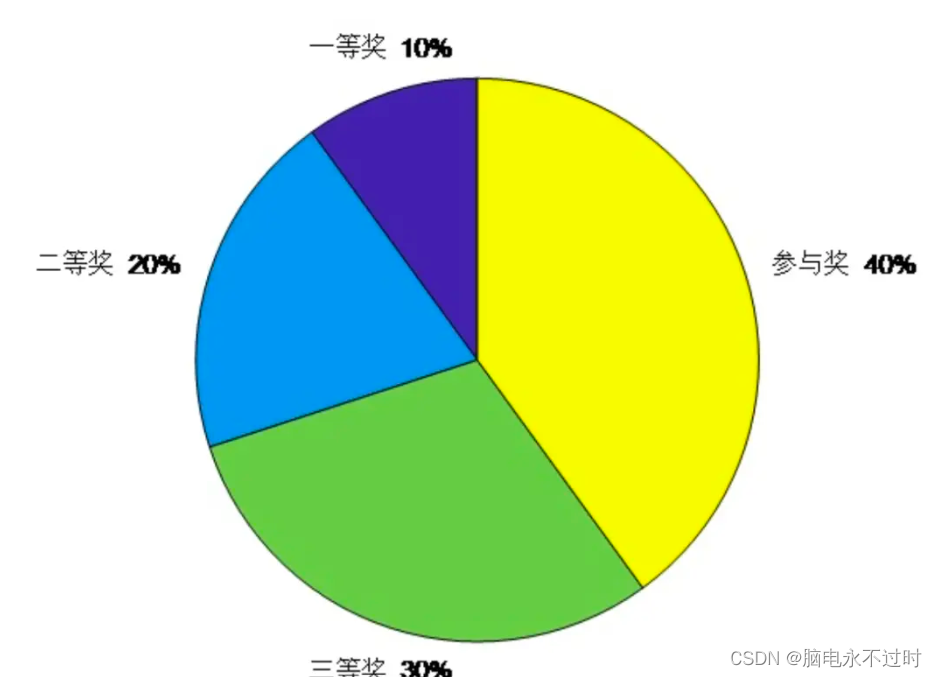
某个概率 = 某个因子 除以 所有因子之和。
比如一等奖的因子是10,所有因子之和是 100,则一等奖的概率是 10%。
学会了轮盘赌算法,让我们回到蚁群算法。
那么现在我们的目标是计算出蚂蚁去下个目的地的因子。因为蚂蚁走过的路上会留下信息素,信息素越高,选择这条路的概率越高,所以假定 因子 = 信息素。在这里,信息素就是一种变量,会在后续的反向传播环节中进行校准。
但是这样会带来一个问题,当第一次迭代完成后,走过的路上留下了信息素,没走过的路上没有信息素,导致之后的蚂蚁会更偏向于之前已经走过的路,而之前已经走过的路不一定是最优路线。因此我们需要给因子再加一个参数,因为我们的问题是求最短路径,所以我们把两点之间的距离引入进来。从贪心的角度来说,两点之间距离越短,则选择这条路线的概率越大,所以我们乘上距离的倒数。
现在,因子 = 信息素 * (距离的倒数)
因子在受到多个参数影响后,我们希望能够调整各个参数的权重,在之前的人工神经网络中,我们是通过乘法的形式把权重和参数结合。
但是在这里我们已经使用了乘法,所以在处理权重时,我们可以使用指数,即:
这边使用 alpha 和 beta 分别代表 信息素 和 距离 的权重,这两个值属于常量,调参时可以灵活调整。
在求得每段路程的因子之后,每只蚂蚁使用轮盘赌算法去选择它要去的下个节点,遍历的时候顺便计算走过的路程,毕竟我们要求的就是最短路径。
蚂蚁根据各个城市间连接路径上的信息素浓度决定下一个访问城市,设表示时刻蚂蚁k 从城市i 转移到城市j 的转移概率,其公式为:
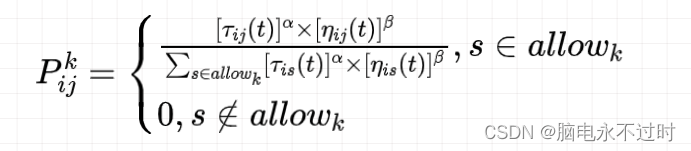

选择下一个城市:
蚂蚁选择城市的概率主要由𝜏ij (t)和𝜂ij (𝑡)有关,分母为蚂蚁k可能访问的城市的信息素*距离倒数之和(为常数),这样才能使蚂蚁选择各个城市的概率之后为1,符合概率的定义。𝜏ij (t)和𝜂ij (𝑡)上的指数信息素因子ɑ和启发函数因子𝛽只决定了信息素浓度以及启发函数对蚂蚁k从i到j的可能性的贡献程度。
为蚂蚁k 待访问城市的集合,开始时,
中有n-1个元素,即包括除了蚂蚁k出发城市的所有其它城市,随着时间的推进,
中的元素不断减少,直至为空,即表示所有的城市均访问完毕;
为信息素重要程度因子,其值越大,表示信息素的浓度在转移中起的作用越大;
为启发函数重要程度因子,其值越大,表示启发函数在转移中的作用越大,即蚂蚁会以较大的概率转移到距离短的城市。当
=0 时,算法就是传统的贪心算法,而当
=0 时,就成了纯粹的正反馈的启发式算法。经过n 个时刻,蚂蚁可以走完所有的城市,完成一次循环,每只蚂蚁所走过的路径就是一个解。
举例:

3、更新信息素
蚂蚁在走的过程中,会一直散发信息素,同时之前的信息素也在挥发,因此,当所有蚂蚁完成一次循环后,各个城市间连接路径上的信息素浓度需进行实时更新。
设参数 表示信息素的挥发程度。
信息素的更新也分为两个部分:
- 首先,每一轮过后,空间中的所有路径上的信息素都会发生蒸发
- 然后,所有的蚂蚁根据自己构建的路径长度在它们本轮经过的边上释放信息素
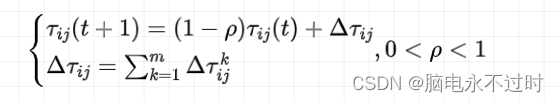
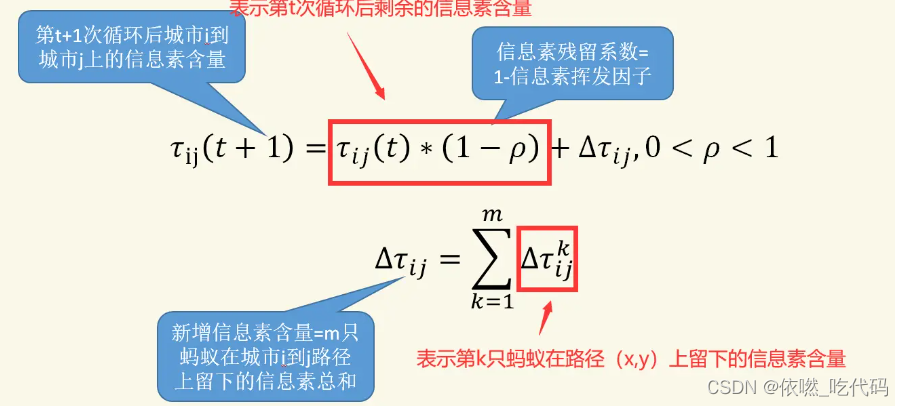
其中,表示第k 只蚂蚁在城市i 与城市j 连接路径上释放的信息素浓度;
表示所有蚂蚁在城市i 与城市j 连接路径上释放的信息素浓度之和。

信息素挥发(evaporation) 信息素痕迹的挥发过程是每个连接上的信息素痕迹的浓度自动逐渐减弱的过程,这个挥发过程主要用于避免算法过快地向局部最优区域集中,有助于搜索区域的扩展。
信息素增强(reinforcement) 增强过程是蚁群优化算法中可选的部分,称为离线更新方式(还有在线更新方式)。这种方式可以实现 由单个蚂蚁无法实现的集中行动。基本蚁群算法的离线更新方式是在蚁群中的m只蚂蚁全部完成n城市的访问后,统一对残留信息进行更新处理。
蚁周模型的例子:
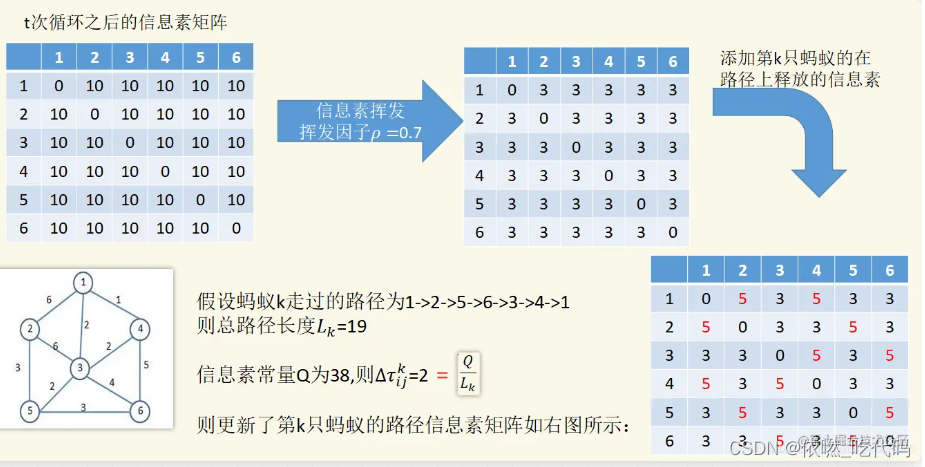
四、以一个例子进行说明:

其中矩阵D表示各城市间的距离




一般蚁群算法的框架和上述算法大致相同,有三个组成部分:蚁群的活动;信息素的挥发;信息素的增强;主要体现在转移概率公式和信息素更新公式的不同。
五、改进的蚁群算法
上述基本的AS算法,在不大于75城市的TSP中,结果还是较为理想的,但是当问题规模扩展时, AS的解题能力大幅度下降。进而提出了一些改进版本的AS算法,这些AS改进版本的一个共同点就是增强了蚂蚁搜索过程中对最优解的探索能力,它们之间的差异仅在于搜索控制策略方面。
1 精英策略的蚂蚁系统(Elitist Ant System, EAS)
-
AS算法中,蚂蚁在其爬过的边上释放与其构建路径长度成反比的信息素量,蚂蚁构建的路径越好,则属于路径的各个边上的所获得的信息素量就越多,这些边以后在迭代中被蚂蚁选择的概率也就越大。
-
我们可以想象,当城市的规模较大时,问题的复杂度呈指数级增长,仅仅靠这样一个基础单一的信息素更新机制引导搜索偏向,搜索效率有瓶颈。
因而精英策略(Elitist Strategy) 被提出,这是一种较早的改进方法,通过一种“额外的手段”强化某些最有可能成为最优路径的边,让蚂蚁的搜索范围更快、更正确的收敛。
-
在算法开始后即对所有已发现的最好路径给予额外的增强,并将随后与之对应的行程记为Tb(全局最优行程);
-
当进行信息素更新时,对这些行程予以加权,同时将经过这些行程的蚂蚁记为“精英”,从而增大较好行程的选择机会。
其信息素的更新方式如下:
2 基于排列的蚂蚁系统(Rank-based AS, ASrank )
精英策略被提出后,人们提出了在精英策略的基础上,对其余边的信息素更新机制加以改善
3 最大最小蚂蚁系统(MAX-MIN Ant System, MMAS)
首先思考几个问题:
问题一:对于大规模的TSP,由于搜索蚂蚁的个数有限,而初始化时蚂蚁的分布是随机的,这会不会造成蚂蚁只搜索了所有路径 中的小部分就以为找到了最好的路径,所有的蚂蚁都很快聚集在 同一路径上,而真正优秀的路径并没有被搜索到呢?
问题二:当所有蚂蚁都重复构建着同一条路径的时候,意味着算法的已经进入停滞状态。此时不论是基本AS、EAS还是ASrank , 之后的迭代过程都不再可能有更优的路径出现。这些算法收敛的 效果虽然是“单纯而快速的”,但我们都懂得欲速而不达的道理, 我们有没有办法利用算法停滞后的迭代过程进一步搜索以保证找 到更接近真实目标的解呢?
对于MAX-MIN Ant System
- 该算法修改了AS的信息素更新方式,只允许迭代最优蚂蚁(在本次迭代构建出最短路径的蚂蚁),或者至今最优蚂蚁释放信息素;
- 路径上的信息素浓度被限制在[MAX,MIN ]范围内;
- 另外,信息素的初始值被设为其取值上限,这样有助于增加算法初始阶段的搜索能力。
- 为了避免搜索停滞,问题空间内所有边上的信息素都会被重新初始化。
改进1借鉴于精华蚂蚁系统,但又有细微的不同。
- 在EAS中,只允许至今最优的蚂蚁释放信息素,而在MMAS中,释放信息素的不仅有可能是至今最优蚂蚁,还有可能是迭代最优蚂蚁。
- 实际上,迭代最优更新规则和至今最优更新规则在MMAS中是交替使用的。
- 这两种规则使用的相对频率将会影响算法的搜索效果。
- 只使用至今最优更新规则进行信息素的更新,搜索的导向性很强,算法会很快的收敛到Tb附近;反之,如果只使用迭代最优更新规则,则算法的探索能力会得到增强,但搜索效率会下降。
改进2是为了避免某些边上的信息素浓度增长过快,出现算法早熟现象。
- 蚂蚁是根据启发式信息和信息素浓度选择下一个城市的。
- 启发式信息的取值范围是确定的。
- 当信息素浓度也被限定在一个范围内以后,位于城市i的蚂蚁k选择城市j作为下一个城市的概率pk(i,j)也将被限制在一个区间内。
改进3,使得算法在初始阶段,问题空间内所有边上的信息素均被初始化τmax的估计值,且信息素蒸发率非常小(在MMAS中,一般将蒸发率设为0.02)。
- 算法的初始阶段,不同边上的信息素浓度差异只会缓慢的增加,因此,MMAS在初始阶段有着较基本AS、EAS和ASrank更强搜索能力。
- 增强算法在初始阶段的探索能力有助于蚂蚁“视野开阔地”进行全局范围内的搜索,随后再逐渐缩小搜索范围,最后定格在一条全局最优路径上。
之前的蚁群算法,包括AS、EAS以及ASrank,都属于“一次性探索”,即随着算法的执行,某些边上的信息素量越来越小,某些路径被选择的概率也越来越小,系统的探索范围不断减小直至陷入停滞状态。
- MMAS中改进4,当算法接近或者是进入停滞状态时,问题空间内所有边上的信息素浓度都将被初始化,从而有效的利用系统进入停滞状态后的迭代周期继续进行搜索,使算法具有更强的全局寻优能力。
六、python代码
# -*- coding: utf-8 -*-
import random
import copy
import time
import sys
import math
import tkinter #//GUI模块
import threading
from functools import reduce
# 参数
'''
ALPHA:信息启发因子,值越大,则蚂蚁选择之前走过的路径可能性就越大
,值越小,则蚁群搜索范围就会减少,容易陷入局部最优
BETA:Beta值越大,蚁群越就容易选择局部较短路径,这时算法收敛速度会
加快,但是随机性不高,容易得到局部的相对最优
'''
(ALPHA, BETA, RHO, Q) = (1.0,2.0,0.5,100.0)
# 城市数,蚁群
(city_num, ant_num) = (50,50)
distance_x = [
178,272,176,171,650,499,267,703,408,437,491,74,532,
416,626,42,271,359,163,508,229,576,147,560,35,714,
757,517,64,314,675,690,391,628,87,240,705,699,258,
428,614,36,360,482,666,597,209,201,492,294]
distance_y = [
170,395,198,151,242,556,57,401,305,421,267,105,525,
381,244,330,395,169,141,380,153,442,528,329,232,48,
498,265,343,120,165,50,433,63,491,275,348,222,288,
490,213,524,244,114,104,552,70,425,227,331]
#城市距离和信息素
distance_graph = [ [0.0 for col in range(city_num)] for raw in range(city_num)]
pheromone_graph = [ [1.0 for col in range(city_num)] for raw in range(city_num)]
#----------- 蚂蚁 -----------
class Ant(object):
# 初始化
def __init__(self,ID):
self.ID = ID # ID
self.__clean_data() # 随机初始化出生点
# 初始数据
def __clean_data(self):
self.path = [] # 当前蚂蚁的路径
self.total_distance = 0.0 # 当前路径的总距离
self.move_count = 0 # 移动次数
self.current_city = -1 # 当前停留的城市
self.open_table_city = [True for i in range(city_num)] # 探索城市的状态
city_index = random.randint(0,city_num-1) # 随机初始出生点
self.current_city = city_index
self.path.append(city_index)
self.open_table_city[city_index] = False
self.move_count = 1
# 选择下一个城市
def __choice_next_city(self):
next_city = -1
select_citys_prob = [0.0 for i in range(city_num)] #存储去下个城市的概率
total_prob = 0.0
# 获取去下一个城市的概率
for i in range(city_num):
if self.open_table_city[i]:
try :
# 计算概率:与信息素浓度成正比,与距离成反比
select_citys_prob[i] = pow(pheromone_graph[self.current_city][i], ALPHA) * pow((1.0/distance_graph[self.current_city][i]), BETA)
total_prob += select_citys_prob[i]
except ZeroDivisionError as e:
print ('Ant ID: {ID}, current city: {current}, target city: {target}'.format(ID = self.ID, current = self.current_city, target = i))
sys.exit(1)
# 轮盘选择城市
if total_prob > 0.0:
# 产生一个随机概率,0.0-total_prob
temp_prob = random.uniform(0.0, total_prob)
for i in range(city_num):
if self.open_table_city[i]:
# 轮次相减
temp_prob -= select_citys_prob[i]
if temp_prob < 0.0:
next_city = i
break
# 未从概率产生,顺序选择一个未访问城市
# if next_city == -1:
# for i in range(city_num):
# if self.open_table_city[i]:
# next_city = i
# break
if (next_city == -1):
next_city = random.randint(0, city_num - 1)
while ((self.open_table_city[next_city]) == False): # if==False,说明已经遍历过了
next_city = random.randint(0, city_num - 1)
# 返回下一个城市序号
return next_city
# 计算路径总距离
def __cal_total_distance(self):
temp_distance = 0.0
for i in range(1, city_num):
start, end = self.path[i], self.path[i-1]
temp_distance += distance_graph[start][end]
# 回路
end = self.path[0]
temp_distance += distance_graph[start][end]
self.total_distance = temp_distance
# 移动操作
def __move(self, next_city):
self.path.append(next_city)
self.open_table_city[next_city] = False
self.total_distance += distance_graph[self.current_city][next_city]
self.current_city = next_city
self.move_count += 1
# 搜索路径
def search_path(self):
# 初始化数据
self.__clean_data()
# 搜素路径,遍历完所有城市为止
while self.move_count < city_num:
# 移动到下一个城市
next_city = self.__choice_next_city()
self.__move(next_city)
# 计算路径总长度
self.__cal_total_distance()
#----------- TSP问题 -----------
class TSP(object):
def __init__(self, root, width = 800, height = 600, n = city_num):
# 创建画布
self.root = root
self.width = width
self.height = height
# 城市数目初始化为city_num
self.n = n
# tkinter.Canvas
self.canvas = tkinter.Canvas(
root,
width = self.width,
height = self.height,
bg = "#EBEBEB", # 背景白色
xscrollincrement = 1,
yscrollincrement = 1
)
self.canvas.pack(expand = tkinter.YES, fill = tkinter.BOTH)
self.title("TSP蚁群算法(n:初始化 e:开始搜索 s:停止搜索 q:退出程序)")
self.__r = 5
self.__lock = threading.RLock() # 线程锁
self.__bindEvents()
self.new()
# 计算城市之间的距离
for i in range(city_num):
for j in range(city_num):
temp_distance = pow((distance_x[i] - distance_x[j]), 2) + pow((distance_y[i] - distance_y[j]), 2)
temp_distance = pow(temp_distance, 0.5)
distance_graph[i][j] =float(int(temp_distance + 0.5))
# 按键响应程序
def __bindEvents(self):
self.root.bind("q", self.quite) # 退出程序
self.root.bind("n", self.new) # 初始化
self.root.bind("e", self.search_path) # 开始搜索
self.root.bind("s", self.stop) # 停止搜索
# 更改标题
def title(self, s):
self.root.title(s)
# 初始化
def new(self, evt = None):
# 停止线程
self.__lock.acquire()
self.__running = False
self.__lock.release()
self.clear() # 清除信息
self.nodes = [] # 节点坐标
self.nodes2 = [] # 节点对象
# 初始化城市节点
for i in range(len(distance_x)):
# 在画布上随机初始坐标
x = distance_x[i]
y = distance_y[i]
self.nodes.append((x, y))
# 生成节点椭圆,半径为self.__r
node = self.canvas.create_oval(x - self.__r,
y - self.__r, x + self.__r, y + self.__r,
fill = "#ff0000", # 填充红色
outline = "#000000", # 轮廓白色
tags = "node",
)
self.nodes2.append(node)
# 显示坐标
self.canvas.create_text(x,y-10, # 使用create_text方法在坐标(302,77)处绘制文字
text = '('+str(x)+','+str(y)+')', # 所绘制文字的内容
fill = 'black' # 所绘制文字的颜色为灰色
)
# 顺序连接城市
#self.line(range(city_num))
# 初始城市之间的距离和信息素
for i in range(city_num):
for j in range(city_num):
pheromone_graph[i][j] = 1.0
self.ants = [Ant(ID) for ID in range(ant_num)] # 初始蚁群
self.best_ant = Ant(-1) # 初始最优解
self.best_ant.total_distance = 1 << 31 # 初始最大距离
self.iter = 1 # 初始化迭代次数
# 将节点按order顺序连线
def line(self, order):
# 删除原线
self.canvas.delete("line")
def line2(i1, i2):
p1, p2 = self.nodes[i1], self.nodes[i2]
self.canvas.create_line(p1, p2, fill = "#000000", tags = "line")
return i2
# order[-1]为初始值
reduce(line2, order, order[-1])
# 清除画布
def clear(self):
for item in self.canvas.find_all():
self.canvas.delete(item)
# 退出程序
def quite(self, evt):
self.__lock.acquire()
self.__running = False
self.__lock.release()
self.root.destroy()
print (u"\n程序已退出...")
sys.exit()
# 停止搜索
def stop(self, evt):
self.__lock.acquire()
self.__running = False
self.__lock.release()
# 开始搜索
def search_path(self, evt = None):
# 开启线程
self.__lock.acquire()
self.__running = True
self.__lock.release()
while self.__running:
# 遍历每一只蚂蚁
for ant in self.ants:
# 搜索一条路径
ant.search_path()
# 与当前最优蚂蚁比较
if ant.total_distance < self.best_ant.total_distance:
# 更新最优解
self.best_ant = copy.deepcopy(ant)
# 更新信息素
self.__update_pheromone_gragh()
print (u"迭代次数:",self.iter,u"最佳路径总距离:",int(self.best_ant.total_distance))
# 连线
self.line(self.best_ant.path)
# 设置标题
self.title("TSP蚁群算法(n:随机初始 e:开始搜索 s:停止搜索 q:退出程序) 迭代次数: %d" % self.iter)
# 更新画布
self.canvas.update()
self.iter += 1
# 更新信息素
def __update_pheromone_gragh(self):
# 获取每只蚂蚁在其路径上留下的信息素
temp_pheromone = [[0.0 for col in range(city_num)] for raw in range(city_num)]
for ant in self.ants:
for i in range(1,city_num):
start, end = ant.path[i-1], ant.path[i]
# 在路径上的每两个相邻城市间留下信息素,与路径总距离反比
temp_pheromone[start][end] += Q / ant.total_distance
temp_pheromone[end][start] = temp_pheromone[start][end]
# 更新所有城市之间的信息素,旧信息素衰减加上新迭代信息素
for i in range(city_num):
for j in range(city_num):
pheromone_graph[i][j] = pheromone_graph[i][j] * RHO + temp_pheromone[i][j]
# 主循环
def mainloop(self):
self.root.mainloop()
#----------- 程序的入口处 -----------
if __name__ == '__main__':
print (u"""
--------------------------------------------------------
程序:蚁群算法解决TPS问题程序
--------------------------------------------------------
""")
TSP(tkinter.Tk()).mainloop()
由于蚁群算法是随机选取初始点,因此如果要选定起始点有两个解决方案:
一:将初始点单独拿出来
二:蚁群进行路径循环也就是最后回到起始点,所以不用在乎起始点。