来源:投稿 作者:阿克西
编辑:学姐
建议搭配视频学习↓
视频链接:https://ai.deepshare.net/detail/p_5df0ad9a09d37_qYqVmt85/6
1.数据增强(data augmentation)
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。

看一下图片中的数据增强是怎么样的。上图是一张原始图片,对这张图片进行一系列的操作变换得到64张增强样本。64张图片中的第一张图片是对原始图片进行旋转,第二张图片是对原始图片进行颜色变换,第三张图片是进行镜像操作。
对图片进行一系列操作可以得到大量增强样本提供给模型进行训练,让模型见过更多的样本,从而提升模型的泛化能力,使得模型在验证集上的表现更好。本章学习具体的数据增强方法。
1.1 导入包和设置参数
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import numpy as np
import torch
import random
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
from tools.my_dataset import RMBDataset
# from tools.common_tools import set_seed, transform_invert
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
1.2 函数transform_invert(),对transform进行逆操作
transform_invert(),这个函数是用来对transform进行逆操作,使得我们可以观察到模型输入的数据是长什么样的。因为数据经过transfrom,转换为张量的形式,可能是一些浮点的数据,没有办法将这些数据进行可视化,因此需要一个transform_invert()函数,对transform进行逆操作,将张量的数据变换成img,这样就可以进行可视化。
这个函数接受一个img_和transform_train,返回PIL image,也就是可以直接plot将其可视化。
# 在训练部分被引用
# 传入两个参数img_和train_transform,返回PIL image,也就是可以直接plot将其格式化
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
# 对normalize进行反操作
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize),
transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean,
dtype=img_.dtype,
device=img_.device)
std = torch.tensor(norm_transform[0].std,
dtype=img_.dtype,
device=img_.device)
# normalize是减去均值除于方差,因此反操作就是乘于方差再加上均值
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
# 通道变换,C*H*W --> H*W*C,将channel放到最后面
img_ = img_.transpose(0, 2).transpose(0, 1)
# 将0-1尺度上的数据转换到0-255
if 'ToTensor' in str(transform_train) or img_.max() < 1:
img_ = img_.detach().numpy() * 255
# 将np_array的形式转换成PIL image
# 判断channel是3通道还是1通道,分别转换成RGB彩色图像和灰度图像
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!"
.format(img_.shape[2]) )
# 返回图像就可以对图像进行plot,对图像进行可视化
return img_
1.3 Dataset类参数一:从哪读数据,设置硬盘中的路径
# ============================ step 1/5 数据 ============================
split_dir = os.path.abspath(os.path.join("rmb_split"))
if not os.path.exists(split_dir):
raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir))
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
1.4 🔥Dataset类参数二:数据预处理transform
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
1.5 构建Dataset与DataLoder实例
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
1.6 训练
transforms方法的演示还是采用人民币二分类训练的主代码,这里我们只关心数据模块以及训练模块中取出数据那一部分。
除2.4 transforms.FiveCrop与transforms.TenCrop外,下述代码均适用。
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
# bs, ncrops, c, h, w = inputs.shape
# for n in range(ncrops):
# img_tensor = inputs[0, n, ...] # C H W
# img = transform_invert(img_tensor, train_transform)
# plt.imshow(img)
# plt.show()
# plt.pause(1)
以下主要针对1.4进行详细展开。
2.transforms 裁剪(crop)
2.1 transforms.CenterCrop中心裁剪
功能:从图像中心裁剪图片
-
size:所需裁剪图片尺寸
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 CenterCrop
transforms.CenterCrop(196), # 512
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
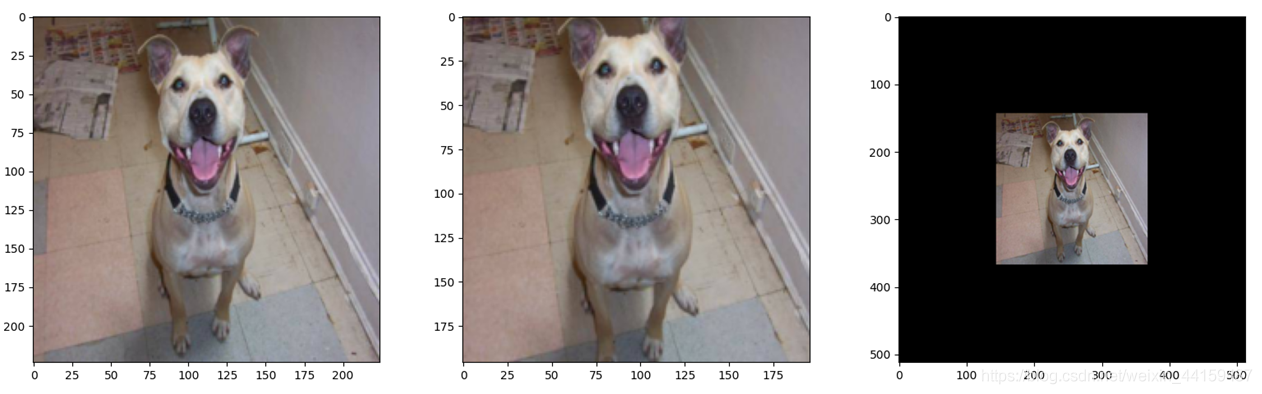
在transforms中,为了统一图片的尺寸,一开始会执行transforms.Resize((224,224)),把图片统一地缩放到 224 ∗ 224的尺寸大小。然后执行transforms.CenterCrop(196)操作,裁剪出来一个196大小的图片。假如把代码中的196改为512,大于224。执行debug操作,代码并没有报错,输出图片为(512, 512)大小的图片,对超出224的区域会自动填充为零的像素,也就是全黑的区域。
断点调试:
1、下面看代码中的transform.CenterCrop()函数,经过裁剪之后图像会变成什么样。首先设置断点,观察inputs的形状,(BATCH_SIZE, C, H, W):
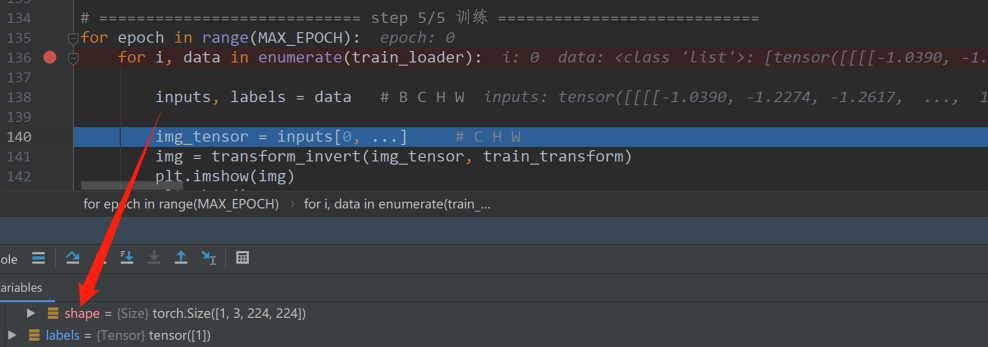
2、对程序进行debug,代码停在之前打断点的位置,如下图所示。点击step over功能键,到达代码img_tensor = inputs[0, …] 位置。观察一下代码中data的形式。
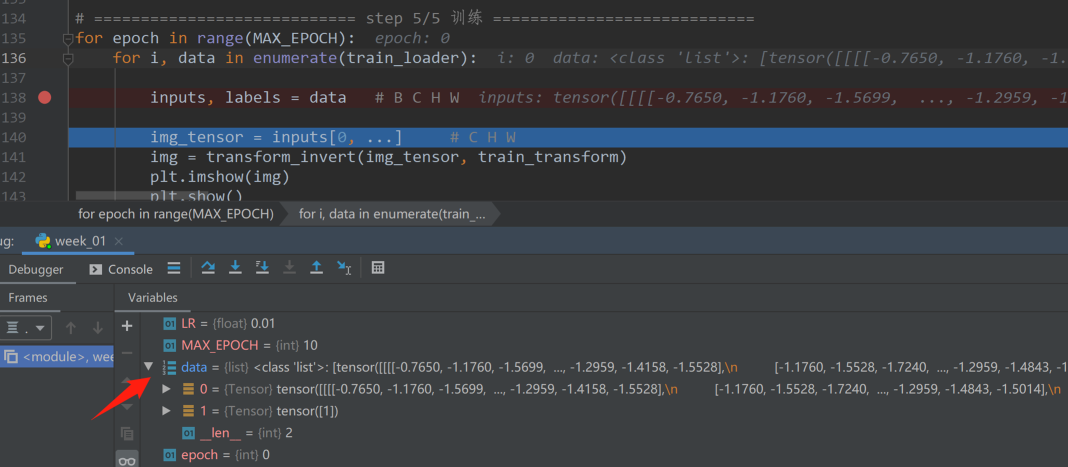
3、点击console就会打开一个命令窗,如下图所示,这个命令窗的环境与当前代码调试的环境是完全一致的,可以在这个命令窗对变量进行更改或者查看。
现在查看inputs的形状,inputs的形状是一个[1,3,196,196]的形式。第一个维度是BITCH_SIZE,因为在代码开始设置了BATCH_SIZE=1,所以inputs中的第一个维度为1;第二个维度是channel,也就是通道,由于是rgb图像,通道的长度为3;第三维和第四位分别是图像的高和宽。
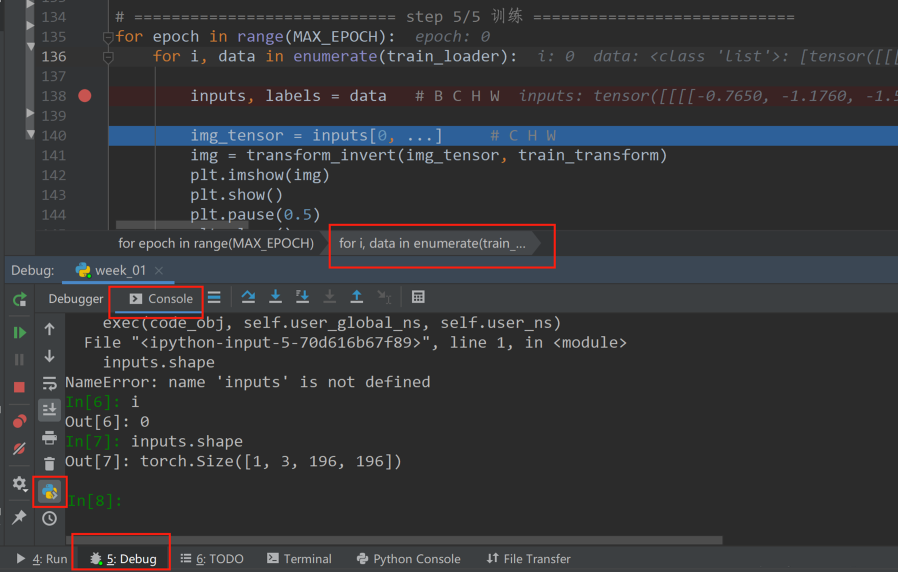
由于可视化图片是一个三通道的三维张量,所以需要对inputs进行索引操作,索引出第一块区域,也就是接下来的一句代码“img_tensor = inputs[0, …]”,这段代码的意思是取四维张量中的第一个三维张量,这样就把四维张量变为三维张量了,其顺序为 C ∗ H ∗ W。将得到的三维张量img输入到函数transform_invert()函数中进行逆变换,就返回可以可视化的img,然后将img进行plt操作,就得到上图的裁剪图片。
在debug之后,可以取消断点,将光标放置在plt.close() 代码处,反复执行run to cursor按键,可以查看不同图像。
2.2 transforms.RandomCrop随机裁剪
功能:从图片中随机裁剪出尺寸为size的图片(位置随机裁剪)。
transforms.RandomCrop(size,
padding=None,
pad_if_needed=False,
fill=0,
padding_mode='constant')
-
size:所需裁剪图片尺寸
- padding:设置填充大小(有三种模式)
-
当为a时,上下左右均填充a个像素
-
当为(a, b)时,左右填充a个像素,上下填充b个像素
-
当为(a, b, c, d)时,左,上,右,下分别填充a,b,c,d
-
-
pad_if_need:若图像小于设定size,则填充
- padding_mode:填充模式,有4种模式
-
constant:像素值由fill参数设定
-
edge:像素值由图像边缘像素决定
-
reflect:镜像填充,最后一个像素不镜像,eg:对[1,2,3,4]进行2个像素的填充,左侧最后一个像素不镜像,忽略1,从左至右为2,3,镜像填充为[3,2,1,2,3,4]。同理,右侧忽略4,从右至左为3,2,最终填充为[3,2,1,2,3,4,3,2]
-
symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] [2,1,1,2,3,4,4,3],最后一个像素镜像,所以不会跳过1和4,分别从1和4开始进行镜像填充
-
-
fill:constant时,设置填充的像素值
下面通过代码观察RandomCrop是怎样对图像进行裁剪的。和前面一样,对图像进行统一的尺寸变换,缩放为(224,224)。
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 RandomCrop
# 1)对上下左右均进行16像素的padding
transforms.RandomCrop(224, padding=16),
# 2)分别对左右、上下设置不同的填充,左右填充16,上下填充64
# transforms.RandomCrop(224, padding=(16, 64)),
# 3)设置fill参数,修改填充像素颜色
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# 4)当size大于图片原始尺寸的时候,pad_if_needed参数必须打开,否则会报错
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=False
# 5)采用图片的边界值对图片进行填充
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# 6)采用图片的镜像填充
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
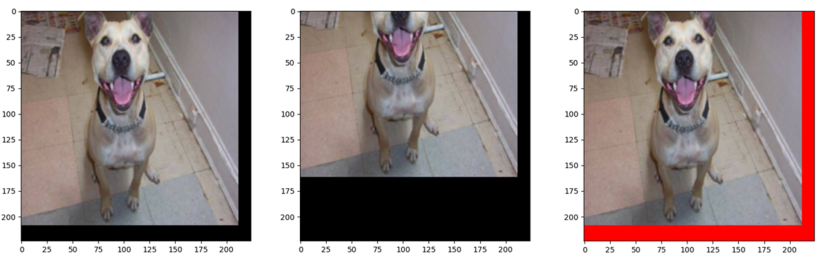
1、对上下左右均进行16像素的padding。裁剪出来的图片左边和上边都有一块黑色的填充区域。为什么左边和上边没有呢?这是因为经过填充之后的图片的尺寸应该是224+16+16,比224大32个像素。在这个大的图片上进行(224,224)的随机选取,由于图像选取右下角的这一部分,所以左边和上边是没有黑色的填充区域的。
2、padding的第二种模型,分别对左右、上下设置不同的填充,左右填充16,上下填充64。可以看到左右的填充区域相比于上下是更小的。
3、可以看到填充的区域都是黑色,默认填充的像素是0,如果想设置的填充区域是红色,或者是其它的彩色图,就可以对fill这个参数进行设置,代码中对fill设置一个长度为3的tuple类型,3个元素分别对应的是RGB通道,比如设定(255, 0, 0),可以看一下其padding出来的颜色是红色的。
4、接下来看一下pad_if_needed参数,当size大于图片原始尺寸的时候,pad_if_needed参数必须打开,否则会报错。可以看到在超出图片的范围全部填充上像素值为0的像素点,也就是黑色的。
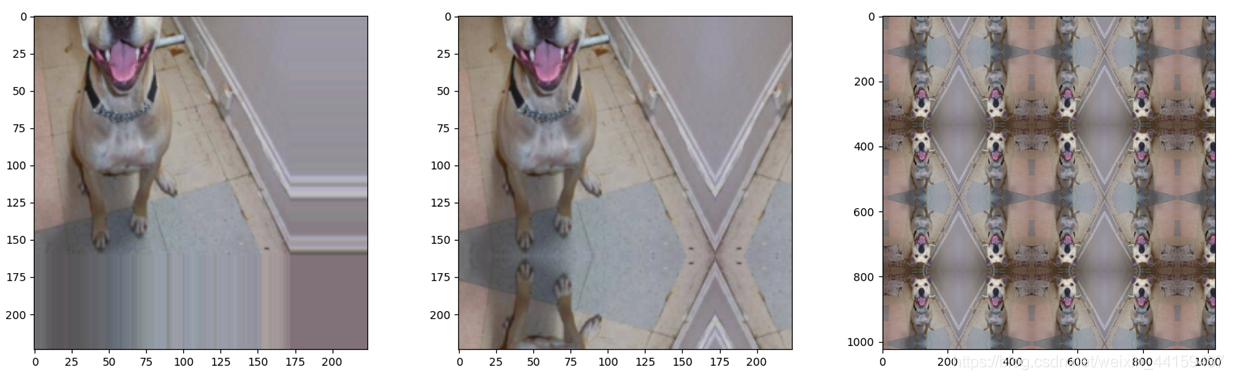
5、观察参数padding_mode的几种模式,padding_mode默认采用constant模式,在采用constant的时候,采用fill参数去设置填充的像素点的像素值。接下里看padding_mode的第二种模式,padding_mode=‘edge’,这种模式是采用图片的边界值对图片进行填充,设置padding的值大一点,padding=64,以便于更好地观察填充的效果。padding_mode='reflect',采用图片的镜像填充。当设置size与padding参数较大时,图像像印钞机填充。
padding_mode='symmetric’和padding_mode='reflect’功能相差不多,只是相差一个像素值点。
2.3 transforms.RandomResizedCrop随机裁剪并调整大小
功能:随机大小、长宽比裁剪图片。
RandomResizedCrop(size,
scale=(0.08,1.0),
ratio=(3/4,4/3),
interpolation)
-
size:所需裁剪图片尺寸;
-
scale:随机裁剪面积比例,默认(0.08,1),0.08-1之间随机选取一个数
-
ratio:随机长宽比,默认(3/4,4/3),3/4到4/3之间随机选取一个数
- interpolation:插值方法,裁剪出来的图片尺寸可能小于size,所以需要进行插值处理,插值方法有三种
-
PIL.Image.NEAREST:最近邻插值
-
PIL.Image.BILINEAR:双线性插值
-
PIL.Image.BICUBIC:双三次插值
-
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 RandomResizedCrop
transforms.RandomResizedCrop(size=224, scale=(0.08, 0.1)),
# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
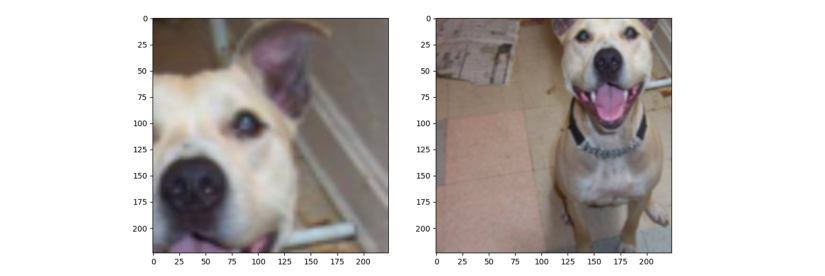
输出结果如上图所示,所得图片比原始图片小得多,这个比例是在scale=(0.08, 0.1)之间随机选取一个数作为裁剪图片面积得到的,之后再根据ratio长宽比设定图像的长和宽,裁剪得到一个图片。最后将裁剪得到图片resize到设定的size大小尺寸。
scale=(0.5, 0.5)表示采取一半的面积,然后再进行长宽比的缩放。
2.4 transforms.FiveCrop与transforms.TenCrop
transforms.FiveCrop(size)
功能:在图像的左上角、右上角、左下角、右下角以及中心裁剪出尺寸为size的5张图片。
transforms.TenCrop(size,
vertical_flip=False)
功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片,在这五张图片上进行水平或者垂直镜像获得10张图片。
-
size:所需裁剪图片尺寸大小
-
vertical_flip:是否垂直翻转,True为垂直翻转,False为水平翻转
示例:
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 4 FiveCrop
transforms.FiveCrop(112), # 直接操作会报错
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 5 TenCrop
# transforms.TenCrop(112, vertical_flip=False),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# transforms.ToTensor(), # 上面进行了ToTensor,这里不再需要,否则会报错
# transforms.Normalize(norm_mean, norm_std),
])
由于FiveCrop()裁剪出来的是五张图片,返回的是一个tuple(元组),不能直接进行操作,当尝试运行代码时,会报错,查看报错信息:
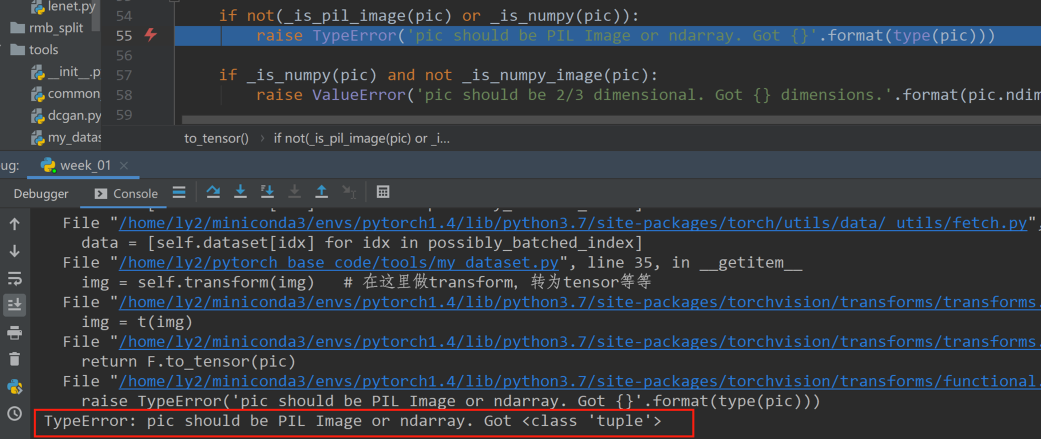
报错为:pic should be PIL Image or ndarray. Got <class ‘torch.Tensor’>。意思是pic这个参数应该是一个PIL Image或者是ndarray的,但是却得到了一个tuple。所以直接使用是不行的,需要对FiveCrop返回的tuple进行一定的操作,将tuple变换为张量的形式或者是PIL Image的形式。
这里使用到lambda方法,lambda是匿名函数,可以对FiveCrop()的输出进行一系列的变换,使其输出可以变换为代码可以执行的数据格式。看一下lambda匿名函数的功能:
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
lambda匿名函数代码中冒号之前的是函数的输入,冒号之后的整个语句是函数的返回值。
由于输入是一个tuple格式的数据,需要将tuple中每一张图片,将其拼接为张量的形式,所以代码中采用了torch.stack()的形式,在讲张量的操作的时候,stack是对张量在某一维度上进行拼接,这里采用默认维度,也就是第0个维度。stack()函数中传入的是一个list,代码中采用了python的列表解析式,列表生成器。它的功能是对参数crops进行for循环,每一次提取出一个元素crop,每一次对这个元素crops进行一些操作得到列表的元素。
crops是FiveCrop()函数输出的一个tuple,然后对tuple的每一个元素进行for循环,每一次取出一个crop,也就是一张图片,对每一张图片进行一个ToTensor()的操作,将其转换为张量的形式,将其变为list的一个元素。通过不断的循环,把五张图片都转为张量的形式,然后得到一个长度为5的list,把这个list放到stack()当中,stack()就把这个长度为5的list拼接成一个张量。这样,通过lambda(),就把tuple转为张量的形式,这样就可以输入到模型中。
点击运行之后还是会报错,报错如下,注意debug时,设置断点在plt.close():
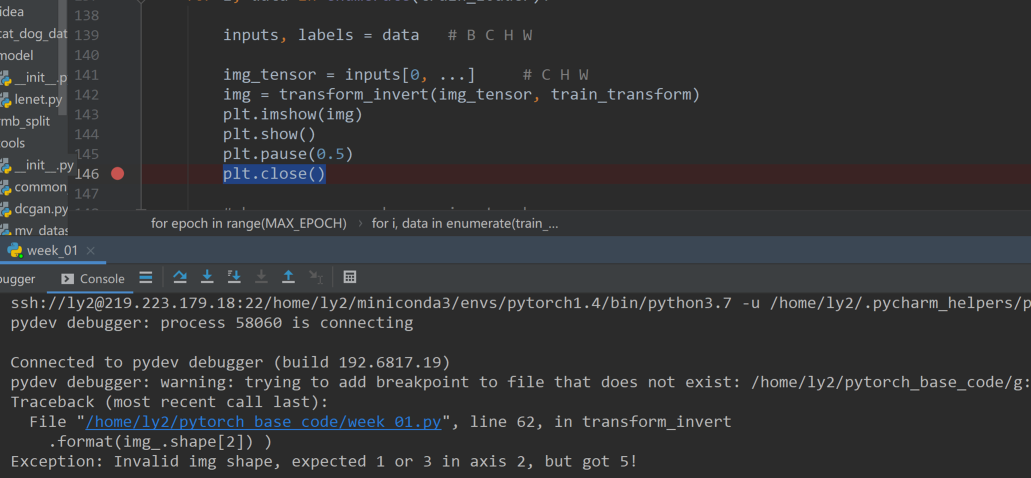
由于图片的维度和代码不匹配,不能用原始的方法可视化。因为得到的input不再是一个四维的张量,是一个五维的张量。
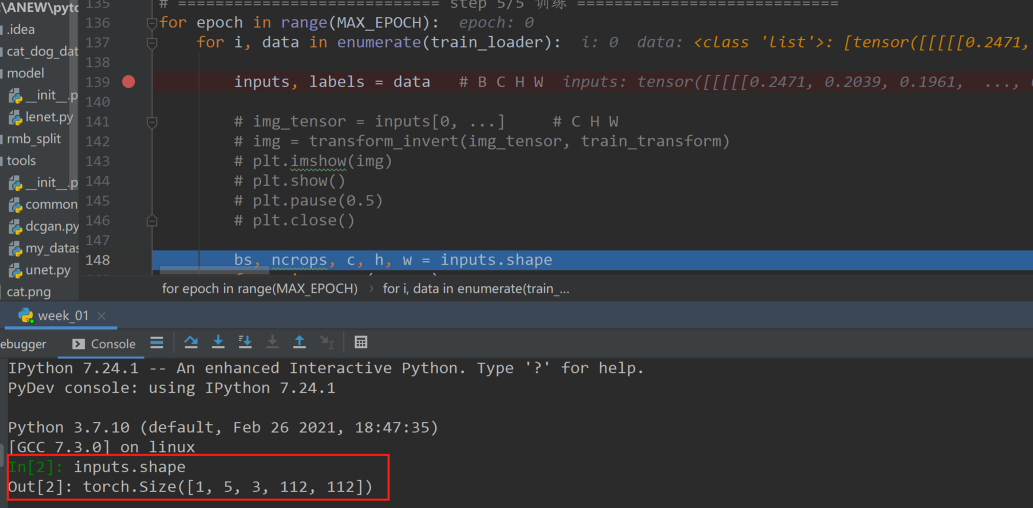
这个五维张量的各个维度分别为(batchsize, ncrops, c, h, w),通过下面这个新的代码对每个crop进行可视化。因此1.6应该修改成如下形式:
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
# img_tensor = inputs[0, ...] # C H W
# img = transform_invert(img_tensor, train_transform)
# plt.imshow(img)
# plt.show()
# plt.pause(0.5)
# plt.close()
bs, ncrops, c, h, w = inputs.shape
for n in range(ncrops):
img_tensor = inputs[0, n, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(1)
得到一张图片的五维表示,代码要在五维张量中获取每一张图片,每一张图片应该是一个3维的张量,对ncrops进行循环,分别将五张图片进行可视化。通过命令输入窗,可以看到img_tensor的形状(3,112,112),可以直接进行可视化。
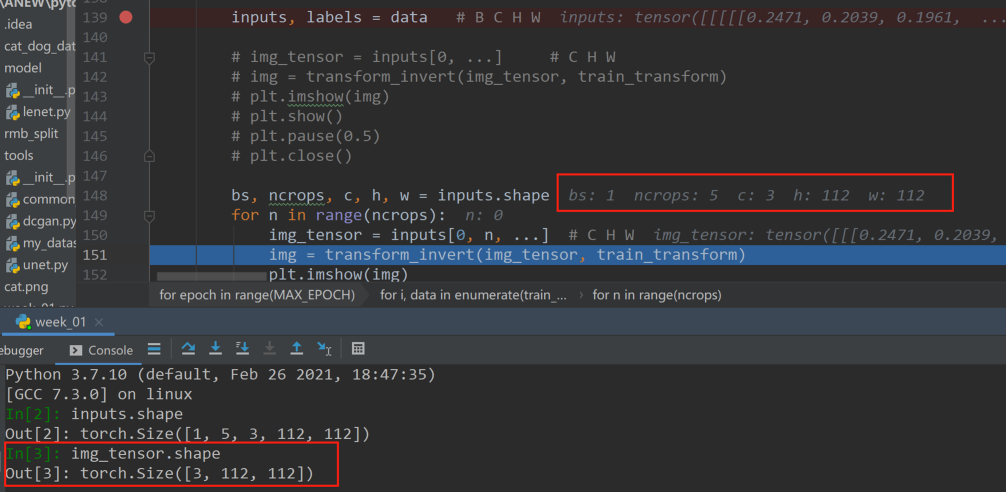
注意因为transforms.ToTensor()与transforms.Normalize(norm_mean, norm_std)被注释,所以应添加如下一行:
# 判断
if img_.shape[2] == 3:
img_ = img_.detach().numpy() * 255 # 添加一行
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
但是只能输出第一张图片五张图和第二张图片一张图,所以可将if 'Normalize' in str(transform_train):与if 'ToTensor' in str(transform_train) or img_.max() < 1:两段代码都注释掉。
输出五张照片如下所示:

下面看一下TenCrop()函数的使用方法,它是在FiveCrop()函数的基础上进行翻转得到的十张图片。设置vertical_flip=True,也就是进行垂直的翻转
3.transforms 翻转和旋转(flip and rotation)
3.1 transforms Flip 翻转
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 Horizontal Flip,水平翻转
transforms.RandomHorizontalFlip(p=1),
# 2 Vertical Flip,垂直翻转
# transforms.RandomVerticalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
功能:依概率水平(左右)或垂直(上下)翻转图片
-
p:翻转概率(即有多大的概率将图片进行翻转)
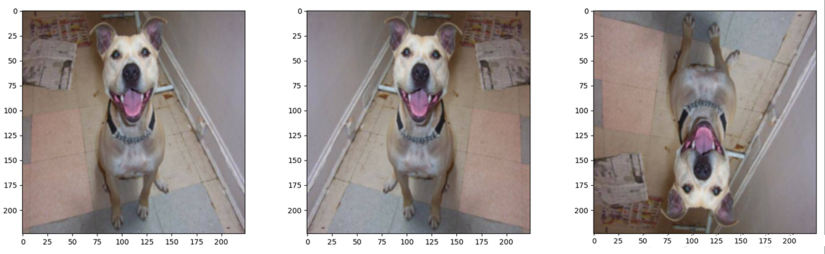
3.2 transforms Rotation 旋转
功能:随机旋转图片
RandomRotation(degrees,
resample=False,
expand=False,
center=None)
- degrees:旋转角度
-
当为a时,在(-a,a)之间选择旋转角度
-
当为(a,b)时,在(a,b)之间选择旋转角度
-
-
resample:重采样方法
-
expand:是否扩大图片,以保持原图信息,图片旋转后,可能会超出矩形框,超出部分可能会丢失,如果expand=True,矩形框会变大
-
center:旋转点设置,默认中心旋转,center=(0, 0)表示左上角旋转
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 RandomRotation
# transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# expand only for center rotation
transforms.RandomRotation(30, center=(0, 0), expand=True),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
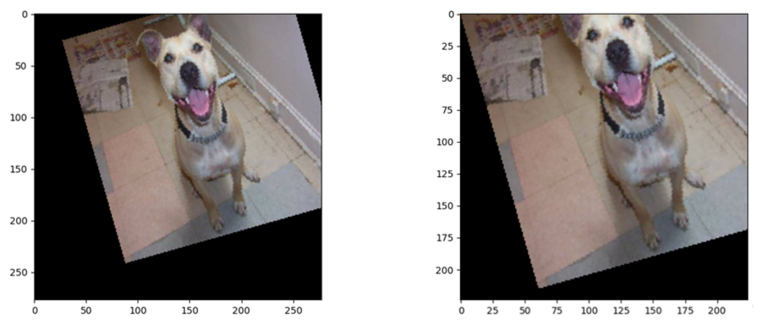
可以看到center=(0, 0),expand=True时,图片也会丢失一部分,因为expand是针对center rotation机制,计算所需扩大的尺度,而在中心和左上角需要计算出的尺度是不一样的,因此expand=True无法找到左上角图像丢失的所有信息。
当使用expand=True扩大图片时,因为每张图片旋转的角度不同,最后得到的图片的大小是不一样的,如果batchsize 1 最后拼接的时候collate_fn可能出现报错的问题,所以在使用expand的时候,需要注意对图片进行缩放,将所有照片缩放到统一的尺寸。
4.transforms 图像变换
4.1 transforms.Pad图片边缘填充
transforms.Pad(padding,
fill=0,
padding_mode=‘constant’)
功能:对图片边缘进行填充
- padding:设置填充大小
-
当为a时,上下左右均填充a个像素
-
当为(a,b)时,左右填充a个像素,上下填充b个像素
-
当为(a,b,c,d)时,左,上,右,下分别填充a,b,c,d
-
-
padding_mode:填充模式,有4种模式,constant、edge、reflect和symmetric
-
fill:constant时,设置填充的像素值,(R,G,B)or(Gray)
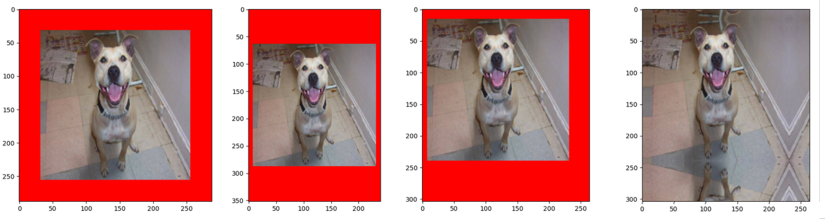
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 Pad
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
4.2 transforms.ColorJitter修改亮度、对比度、饱和度和色相
transforms.ColorJitter(brightness=0,
contrast=0,
saturation=0,
hue=0)
功能:修改修改亮度、对比度和饱和度
- brightness:亮度调整因子
-
当为a时,从[max(0, 1-a), 1+a]中随机选择一个数
-
当为(a, b)时,从[a, b]中随机选择一个数
-
-
contrast:对比度参数,同brightness
-
saturation:饱和度参数,同brightness
- hue:色相参数
-
当为a时,从[-a, a]中选择参数,注: 0 ≤ a ≤ 0.5
-
当为(a, b)时,从[a, b]中选择参数,注:-0.5 ≤ a ≤ b ≤ 0.5
-
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 ColorJitter
# transforms.ColorJitter(brightness=0.5),
# transforms.ColorJitter(contrast=0.5),
# transforms.ColorJitter(saturation=0.5),
# transforms.ColorJitter(hue=0.3),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])

对比度降低,图像发灰,对比度增高,白色更白,黑色更黑。
4.3 transforms.Grayscale转灰度图
transforms.RandomGrayscale(num_output_channels,
p=0.1)
# 是RandomGrayscale的一个特例,是p=1的情况
transforms.Grayscale(num_output_channels=1)
功能:依概率将图片转换为灰度图
-
num_ouput_channels:输出通道数,只能设1或3
-
p:概率值,图像被转换为灰度图的概率
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 3 Grayscale,num_output_channels=1会报错,因为这里使用的图像是3维的
# transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
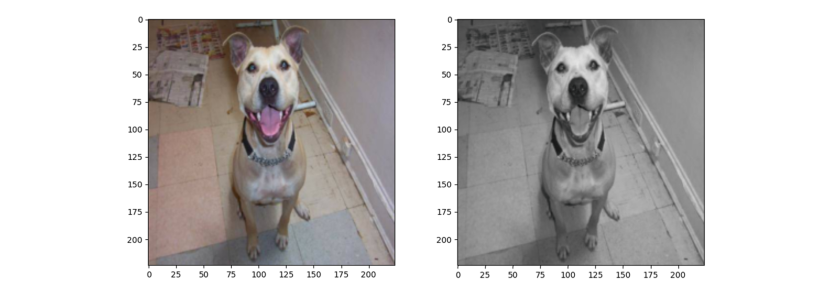
num_output_channels=1报错:因为高斯变换逆变换均值和方差为三维
4.4 transforms.RandomAffine仿射变换
空间几何变换
transforms.RandomAffine(degrees,
translate=None,
scale=None,
shear=None,
resample=False,
fillcolor=0)
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转。经过五种变换的随机组合,即可得到二维线性变换。
-
degrees:旋转角度设置,必设参数
-
translate:平移区间设置,如(a, b),a设置宽(width),b设置高(height) 图像在宽维度平移的区间为 -img_width * a < dx < img_width * a
-
scale:缩放比例(以面积为单位),0到1之间,原始图像占resize后图像的比例
-
fill_color:填充颜色设置,默认黑色填充
- shear:错切角度设置,有水平错切和垂直错切
-
若为a,则仅在x轴错切,错切角度在(-a,a)之间,以中心旋转形式
-
若为(a, b),则仅在x轴错切,错切角度在(a, b)之间
-
若为(a, h, c, d),则a, b设置x轴角度,c, d设置y轴角度
-
-
resample:重采样方式,有NEAREST、BILINEAR、BICUBIC
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 4 Affine
# transforms.RandomAffine(degrees=30),
# 平移
# transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),
# 错切
# 沿着x轴错切
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7), shear=45),
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7), shear=(45, 45)),
# 沿着y轴错切
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7), shear=(0, 0, 0, 45)),
transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])

下图分别为沿x轴错切,沿x轴错切,沿y轴错切。

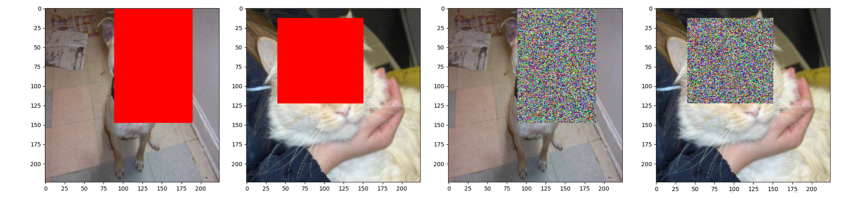
4.5 transforms.RandomErasing随机遮挡
transforms.RandomErasing(p=0.5,
scale=(0.02, 0.33),
ratio=(0.3, 3.3),
value=0,
inplace=False)
功能:对图像进行随机遮挡
-
p:概率值,执行该操作的概率
-
scale:遮挡区域的面积,原论文中推荐数值scale=(0.02, 0.33)
-
ratio:遮挡区域长宽比,设置一个区间,原论文中推荐数值ratio=(0.3, 3.3)
-
value:设置遮挡区域的像素值,(R,G,B)or(Gray),0-1之间,应为操作的是tensor张量。如果为任意字符串,而不是tuple,都默认为random
参考文献:《Random Erasing Data Augmentation》

train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 5 Erasing
transforms.ToTensor(),
# 随即遮挡接收的是tensor,在张量上进行操作,之前都是在PIL image上的操作
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='random'),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='1234'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
4.6 transforms.Lambda
Lambda匿名函数,常用来简单操作的实现。
transforms.Lambda(lambd)
功能:用户自定义lambda方法。
-
lambd:lambda匿名函数,语法实现形式,lambda [arg1 [,arg2, … , argn]] : expression,冒号之前是输入参数,之后是表达式,相当于return
示例:TenCrop返回10张图片的元组形式,而transforms输入输出一般是tensor或PIL image形式,所以需要对TenCrop输入的tuple形式进行变换,拼接成tensor形式,这是可以采用Lambda匿名函数
transforms.TenCrop(200, vertical_flip=True),
# 最后返回一个4维的张量
transforms.Lambda(lambda crops: torch.stack([transforms.Totensor()(crop) for crop in crops])),
5.transforms的选择操作
PyTorch不仅可设置对图片的操作,还可以对这些操作进行随机选择、组合,使得数据增强更加灵活多样。
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 RandomChoice
transforms.RandomChoice([transforms.RandomVerticalFlip(p=1),
transforms.RandomHorizontalFlip(p=1)]),
# 2 RandomApply
# 有的图像执行错切填充红色后进行灰度变换,有的不执行任何操作
# transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),
# transforms.Grayscale(num_output_channels=3)], p=0.5),
# 3 RandomOrder
# transforms.RandomOrder([transforms.RandomRotation(15),
# transforms.Pad(padding=32),
# transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
5.1 transforms.RandomChoice
transforms.RandomChoice([transforms1, transforms2, transforms3])
功能:从给定的一系列transforms中随机选择一个进行操作,randomly picked from a list。
5.2 transforms.RandomApply
transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
功能:依据概率执行一组transforms操作
5.3 transforms.RandomOrder
transforms.RandomOrder([transforms1, transforms2, transforms3])
功能:将transforms中的操作顺序随机打乱
6.自定义transforms方法
class Compose(object):
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
在dataset与dataloader机制一节中,我们知道transforms方法是在Compose类中的call函数被调用的。由上述代码可以看出,对一组transforms进行for循环,顺序挑选出transforms方法执行,每次输入一个参数,返回一个参数,因此transforms方法只能接收一个参数,返回一个参数。其次,for循环里,当前transforms方法的输入是上一个方法的输出,方法上下有前后关系,因此输入输出类型要匹配,比如都是PIL image形式或者都是tensor。
自定义transforms要素:
-
仅接收一个参数,返回一个参数,可以是PIL img,可以是tensor,list,tuple或者dict
-
注意上下游的输出与输入
在设计transforms方法时,可能需要多个参数,比如概率取值,信噪比等,这时可以通过类实现多参数传入:
class YourTransforms(object):
# 初始化,传入想要的参数
def __init__(self, ...):
...
# 类中必须有call函数,使得类的示例可以被调用,
# 在这个函数中实现自定义数据增强的具体功能
# 只能接受一个输入img参数,返回一个img参数
def __call__(self, img):
...
return img
椒盐噪声:又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声。
信噪比(Signal-Noise Rate, SNR)是衡量噪声的比例,图像像素在整张图象的占比。如下图所示,随着信噪比的减小,图像像素信息丢失逐渐增加。

椒盐噪声:
class AddPepperNoise(object):
def __init__(self, snr, p):
self.snr = snr
self.p = p
def __call__(self, img):
"""添加椒盐噪声具体实现过程
"""
return img
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) and (isinstance(p, float)) # 2020 07 26 or --> and
self.snr = snr
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 概率判断,以一定的概率执行椒盐噪声
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy() # 将输入的PIL img形式转变为numpy形式
h, w, c = img_.shape # 获取图像的高宽通道数
signal_pct = self.snr # 设置信号百分比
noise_pct = (1 - self.snr)
# 0,1,2分别表示是原始图像,盐噪声,椒噪声
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
AddPepperNoise(0.9, p=0.5), # 椒盐噪声
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
以一定概率添加椒盐噪声:

7.数据增强实战策略
原则:让训练集与测试集更接近。
-
空间位置:平移
-
色彩:灰度图,色彩抖动
-
形状:仿射变换
-
上下文场景:遮挡,填充
-
……

关注下方【学姐带你玩AI】🚀🚀🚀
回复“pytorch”了解更多视频详情
码字不易,欢迎大家点赞评论收藏!