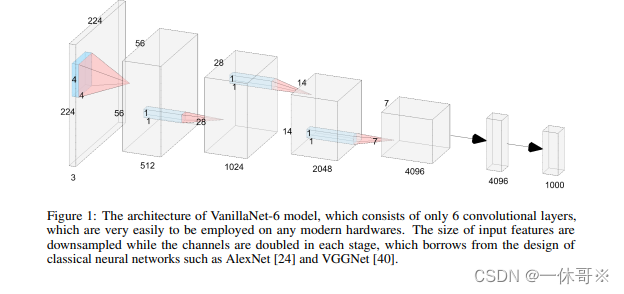
基本思想
存在一组观察值
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi),其中
y
i
y_i
yi和
x
i
x_i
xi之间满足一定的线性关系,如
y
=
a
0
f
0
(
x
)
+
a
1
f
1
(
x
)
+
.
.
.
+
a
m
−
1
f
m
−
1
(
x
)
y = a_0 f_0(x) + a_1 f_1(x) + ... + a_{m-1} f_{m-1}(x)
y=a0f0(x)+a1f1(x)+...+am−1fm−1(x)
其中
f
i
(
x
)
f_i(x)
fi(x)是已知的,
a
i
a_i
ai未知。
由于测量过程中存在一定的误差,所以导致测量得到的
y
i
y_i
yi具有一定的误差,即
y
i
=
a
0
f
0
(
x
i
)
+
a
1
f
1
(
x
i
)
+
.
.
.
+
a
m
−
1
f
m
−
1
(
x
i
)
+
e
i
y_i = a_0 f_0(x_i) + a_1 f_1(x_i) + ... + a_{m-1} f_{m-1}(x_i) + e_i
yi=a0f0(xi)+a1f1(xi)+...+am−1fm−1(xi)+ei
假设,我们由
n
n
n组观察值,将其写为矩阵的形式
y
⃗
=
H
a
⃗
+
e
⃗
\vec{y} = H\vec{a} + \vec{e}
y=Ha+e
y
⃗
\vec{y}
y和
e
⃗
\vec{e}
e为一个
n
×
1
n\times1
n×1的向量,
a
⃗
\vec{a}
a为
m
×
1
m\times 1
m×1的向量,
H
H
H为一个已知的
n
×
m
n\times m
n×m的矩阵
(
f
0
(
x
0
)
f
1
(
x
0
)
.
.
.
f
m
−
1
(
x
0
)
f
0
(
x
1
)
f
1
(
x
1
)
.
.
.
f
m
−
1
(
x
1
)
.
.
.
.
.
.
.
.
.
.
.
.
f
0
(
x
n
−
1
)
f
1
(
x
n
−
1
)
.
.
.
f
m
−
1
(
x
n
−
1
)
)
\begin{pmatrix} f_0(x_0) & f_1(x_0) & ... & f_{m-1}(x_0) \\ f_0(x_1) & f_1(x_1) & ... & f_{m-1}(x_1) \\ ... & ... & ... & ... \\ f_0(x_{n-1}) & f_1(x_{n-1}) & ... & f_{m-1}(x_{n-1})\end{pmatrix}
f0(x0)f0(x1)...f0(xn−1)f1(x0)f1(x1)...f1(xn−1)............fm−1(x0)fm−1(x1)...fm−1(xn−1)
由于测量误差满足高斯分布,由最大似然估计可得,选取使得
∣
y
⃗
−
H
a
⃗
∣
2
|\vec{y} - H\vec{a}|^2
∣y−Ha∣2达到最小值的
a
^
\hat{a}
a^就是最真实
a
⃗
\vec{a}
a的最优估计。
最小二乘估计表达式推导过程
令代价函数
L
(
a
⃗
)
=
∣
y
⃗
−
H
a
⃗
∣
2
L(\vec{a}) = |\vec{y} - H\vec{a}|^2
L(a)=∣y−Ha∣2,将
L
(
a
⃗
)
L(\vec{a})
L(a)对
a
⃗
\vec{a}
a进行求导可得
∂
L
(
a
⃗
)
∂
a
⃗
=
−
2
H
T
y
⃗
+
2
H
T
H
a
⃗
\frac{\partial{L(\vec{a})}}{\partial{\vec{a}}} = -2H^T\vec{y} + 2H^TH\vec{a}
∂a∂L(a)=−2HTy+2HTHa
令其为零可得
a
^
=
(
H
T
H
)
−
1
H
T
y
⃗
\hat{a} = (H^TH)^{-1}H^T\vec{y}
a^=(HTH)−1HTy
举例说明
利用matlab生成一组数据,满足如下的表达式
y
=
a
0
f
0
(
x
)
+
a
1
f
1
(
x
)
+
a
2
f
2
(
x
)
+
e
(
x
)
y = a_0 f_0(x) + a_1 f_1(x) + a_2 f_2(x)+e(x)
y=a0f0(x)+a1f1(x)+a2f2(x)+e(x)
其中
a
0
=
1
a_0 = 1
a0=1 ,
a
1
=
2
a_1 = 2
a1=2,
a
2
=
10
a_2 = 10
a2=10,
f
0
(
x
)
=
x
f_0(x) = x
f0(x)=x,
f
1
(
x
)
=
e
x
f_1(x) = e^x
f1(x)=ex,
f
2
(
x
)
=
x
2
f_2(x) = x^2
f2(x)=x2,
e
(
x
)
e(x)
e(x)服从标准正态分布
% 测试LSM算法
% f0 = 1; f1 = e^x; f2 = x^2
% a0 = 1; a1 = 2; a2 = 10
t = 0 : 0.01 : 3;
f0 = ones(1, length(t));
f1 = exp(t);
f2 = t.^2;
% f1 = t;
% f2 = t.^2;
a0 = 1;
a1 = 2;
a2 = 10;
H = [f0' f1' f2'];
y = a0*f0 + a1*f1 + a2*f2 + randn(1, length(t));
y = y';
est_a = inv(H'*H)*H'*y;
plot(y);
hold on
plot(est_a' * [f0;f1;f2]);
legend('带有噪声的观测量', '估计得到的观测量')
得到的结果如下:
 得到的
a
^
=
[
0.9807
,
1.9565
,
10.0977
]
\hat{a} = [0.9807, 1.9565, 10.0977]
a^=[0.9807,1.9565,10.0977],可以看到能够较好地估计原理论值
a
⃗
=
[
1
,
2
,
10
]
\vec{a} = [1, 2, 10]
a=[1,2,10]
得到的
a
^
=
[
0.9807
,
1.9565
,
10.0977
]
\hat{a} = [0.9807, 1.9565, 10.0977]
a^=[0.9807,1.9565,10.0977],可以看到能够较好地估计原理论值
a
⃗
=
[
1
,
2
,
10
]
\vec{a} = [1, 2, 10]
a=[1,2,10]