1、Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行在于操作系统之上的应用程序。
1.1 Yarn基础架构
Yarn主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
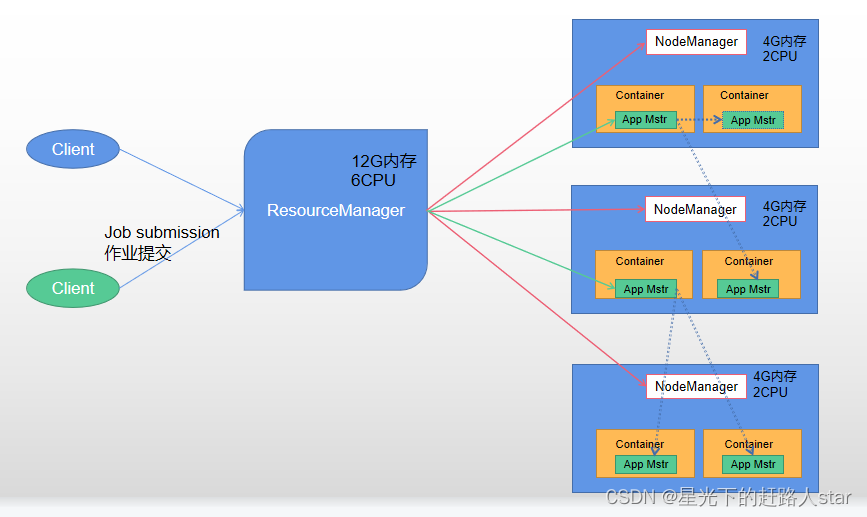
1、ResourceManager(RM)主要作用:
(1)处理客户端请求
(2)监控NodeManager
(3)启动或监控ApplicationMaster
(4)资源的分配和调度
2、NodeManager(NM)主要作用:
(1)管理单个节点上的资源
(2)处理来自ResourceManager的命令
(3)处理来自ApplicationMaster的命令
3、ApplicationMaster(AM)的主要作用·:
(1)为应用程序申请资源并分配给内部的任务
(2)任务的监控与容错
4、Container
Container是Yarn中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
1.2 Yarn工作机制
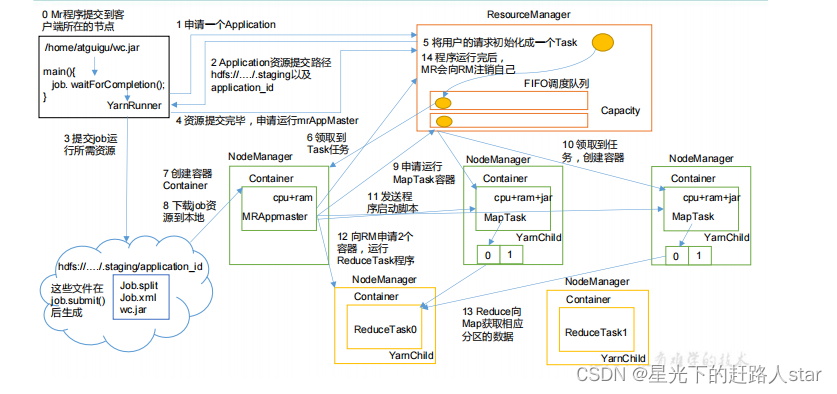
(1)MR程序提交到客户端所在的节点
(2)YarnRunner向ResourceManager申请一个Application
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上
(5)程序资源提交完毕后,申请运行mrAppMaster
(6)RM将用户的请求初始化成一个Task
(7)其中一个NodeManager领取到Task任务
(8)该NodeManager创建容器,并尝试MRAppmaster
(9)Container从HDFS上拷贝资源到本地
(10)MRAppMaster向RM申请运行MapTask资源
(11)RM将运行MapTask任务分配给另外两个NodeManager,另外两个NodeManager分别领取任务并创建容器。
(12)MR向两个接受到任务的NodeManager发生程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MRAppMaster等待所以MapTask运行完毕后,向RM申请容器,运行Reduce Task。
(14)ReduceTask向MapTask获取相应分区的数据
(15)程序运行完毕后,MR会向RM申请注销自己。
1.3 作业提交全过程
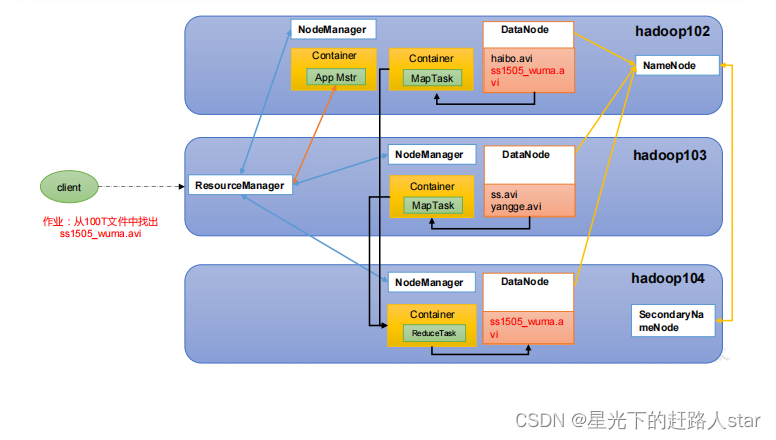
1、作业提交过程之YARN
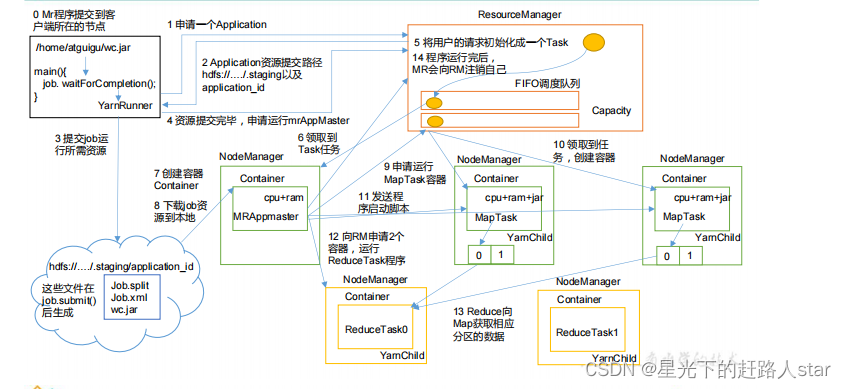
2、作业提交之HDFS&&MapReduce
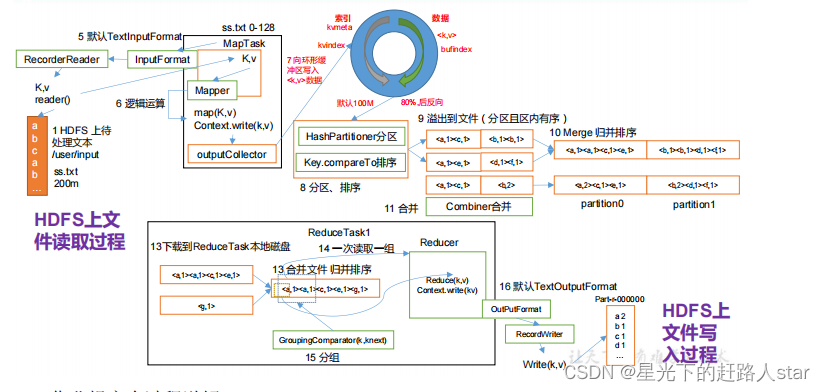
作业提交全过程详解
(1)作业提交
(a)client调用job.waitForCompletion()方法,向整个集群提交MapReduce作业。
(b)client向RM申请一个作业id
(c)RM给Client返回该job资源的提交路径和作业id
(d)client提交jar包、切片信息和配置文件到指定的资源提交路径
(e)client提交完资源后,向RM申请运行MRAppMaster
(2)作业初始化
(a)当RM收到client的请求后,将该job添加到容量调度器中
(b)某一个空间的NM领到该Job
(c)该NM创建Container,并产生MRAppMaster
(d)下载Client提交的资源到本地
(3)任务分配
(a)MRAppMaster向RM申请运行多个MapTask任务资源
(b)RM将运行MapTask任务分配给另外两个NodeManager,这两个NodeManager分别领取任务并创建容器。
(4)任务运行
(a)MR向两个接受到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(b)MRAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(c)ReduceTask向MapTask获取相应分区的数据
(d)程序运行完毕后·,MR会向RM申请注销自己。
(5)进度和状态更新
Yarn中的任务将其进度和状态(包括counter)返回给应用管理器,客户端每秒(通过mapreduce.client.progressmonitor.pollinterval 设置)向应用管理器请求进度更新,展示给用户。
(6)作业完成
除了向应用管理器请求作用进度外,客户端每5秒都会通过调用waitForCompletion()方法来检查作业是否完成。时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后,应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器储存以备之后用户核查。
1.4 Yarn调度器和调度算法
目前,Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
CDH框架默认调度器是Fair Scheduler。
具体详见:yarn-default.xml文件
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
1.4.1 先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交·作业的先后顺序,先来先服务。
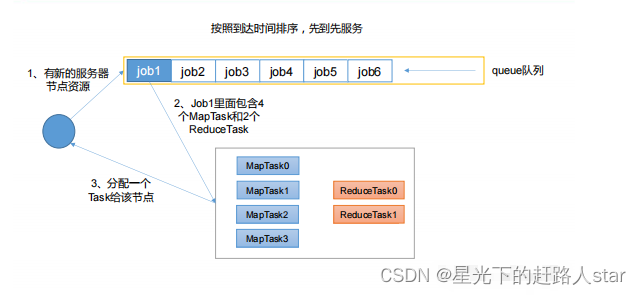
优点:简单易懂
缺点:不支持多队列,生产环境很少使用
1.4.2 容量调度器(Capacity Scheduler)
Yahoo开发的多用户调度器

1、多队列:每个队列可配置一定的资源量,每个队列采用FIFO调度策略
2、容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
3、灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序,则其他队列借调的资源会归还给该队列。
4、多租户:
(1)支持多用户共享集群和多应用程序同时运行
(2)为了防止同一个用户的作业独占队列中的资源,该调度器会对象同一用户提交的作业所占资源量进行限定。
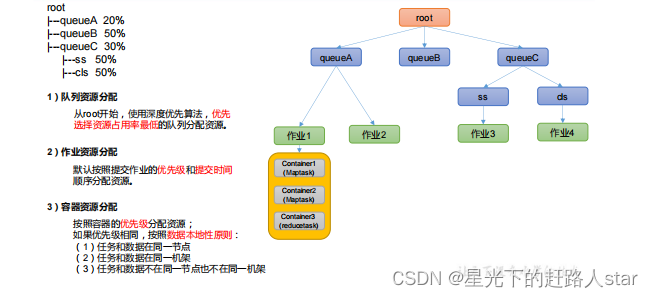
容量调度器资源分配算法:
(1)队列资源分配
从root开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源。
(2)作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源
(3)容器资源分配
按容器的优先级分配资源:
如果优先级相同,按照数据本地性原则:
(a)任务和数据在同一个节点
(b)任务和数据在同一个机架
(c)任务和数据不同节点和不同机架
1.4.3 公平调度器(Fair Scheduler)
是Facebook开发的多用户调度器

1、与容量调度器相同点
(1)多队列:支持多队列多作业
(2)容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
(3)灵活性:如果一个队列的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
(4)多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一个用户提交的作业所占资源量进行限定。
2、与容量调度器不同点
(1)核心调度策略不同
(a)容量调度器:优先选择资源利用率低的队列
(b)公平调度器:优先选择对资源缺额比例大的资源
(2)每个队列可以单独设置资源分配方式
(a)容量调度器:FIFO、DRF
(b)公平调度器:FIFO、FAIR、DRF
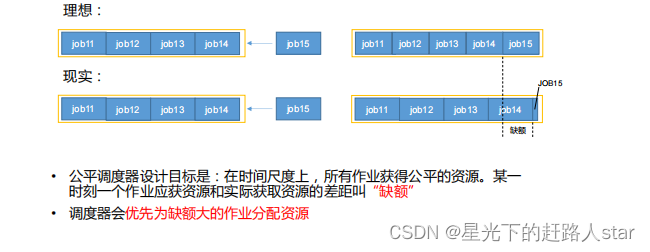
3、公平调度器队列资源分配方式
(1)FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
(2)Fair策略
Fair策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式。默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序在同时运行,则每个应用程序可以得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可以得到1/3的资源。
具体资源分配流程和容量调度器一致:
(1)选择队列
(2)选择作业
(3)选择容器
以上三步,每一步都是按照公平策略分配资源
实际最小资源份额:mindshare = Min(资源需求量,配置的最小资源)
是否饥饿:isNeedy = 资源使用量 < mindshare(实际最小资源份额)
资源分配比:minShareRatio = 资源使用量 / Max(mindshare, 1)
资源使用权重比:useToWeightRatio = 资源使用量 / 权重
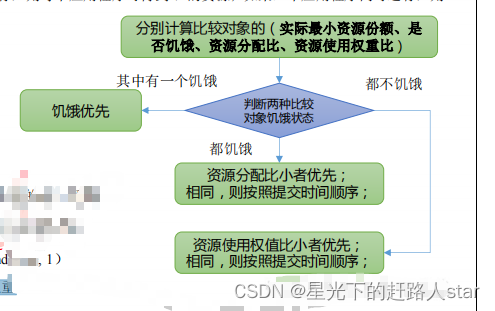
(3)公平调度器资源分配算法
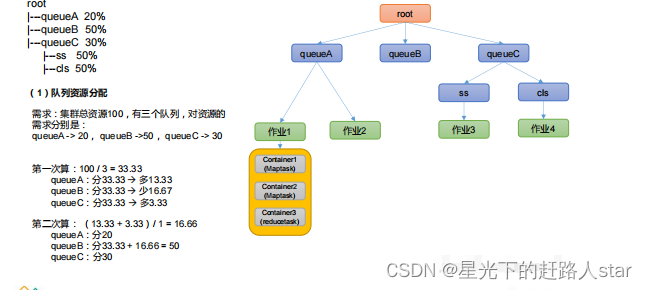
(4)公平调度算法队列资源分配方式

(5)DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:
假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU,100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
1.5 Yarn常用命令
Yarn状态的查询,除了可以在ResourceManager节点ip+端口号8088在页面查看外,还可以通过命令操作。常见的命令操作如下:
1.5.1 yarn Application查看任务
(1)列出所有Application:
yarn application -list
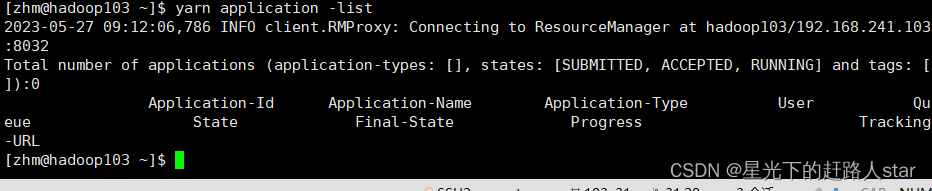
(2)根据Application状态过滤 (所有状态:ALL、NEW、
NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
yarn application -list -appStates
(3)kill 掉Application
yarn application -kill application_1612577921195_0001
1.5.2 yarn logs查看日志
(1)查询 Application 日志:yarn logs -applicationId
(2)查询 Container 日志:yarn logs -applicationId -containerId
1.5.3 yarn applicationattempt 查看尝试运行的任务
(1)列出所有 Application 尝试的列表:yarn applicationattempt -list
(2)打印 ApplicationAttemp 状态:yarn applicationattempt -status
1.5.4 yarn Container查看容器
(1)列出所有 Container:yarn container -list
(2)打印 Container 状态:yarn container -status
注意:只有在任务跑的途中才能看到 container 的状态
1.5.5 yarn node 查看节点状态
列出所有节点:yarn node -list -all
1.5.6 yarn rmadmin 更新配置
加载队列配置:yarn rmadmin -refreshQueues
1.5.6 yarn queue 查看队列
打印队列信息:yarn queue -status
1.6 Yarn生产环境核心参数
1、ResourceManager相关
| 核心参数 | 说明 |
|---|---|
| yarn.resourcemanager.scheduler.class | 配置调度器,默认容量 |
| yarn.resourcemanager.scheduler.client.thread-count | ResourceManager处理调度器请求的线程数量,默认50 |
2、NodeManager相关
| 核心参数 | 说明 |
|---|---|
| yarn.nodemanager.resource.detect-hardware-capabilities | 是否让yarn自己检测硬件进行配置,默认false |
| yarn.nodemanager.resource.count-logical-processors-as-cores | 是否将虚拟核数当作CPU核数,默认false |
| yarn.nodemanager.resource.pcores-vcores-multiplier | 虚拟核数和物理核数乘数,例如:4核8线程,该参数就应设为2,默认1.0 |
| yarn.nodemanager.resource.memory-mb | NodeManager使用内存,默认8G |
| yarn.nodemanager.resource.system-reserved-memory-mb NodeManager | 为系统保留多少内存以上二个参数配置一个即可 |
| yarn.nodemanager.resource.cpu-vcores | NodeManager使用CPU核数,默认8个 |
| yarn.nodemanager.pmem-check-enabled | 是否开启物理内存检查限制container,默认打开 |
| yarn.nodemanager.vmem-check-enabled | 是否开启虚拟内存检查限制container,默认打开 |
| yarn.nodemanager.vmem-pmem-ratio | 虚拟内存物理内存比例,默认2.1 |
3、Container相关
| 核心参数 | 说明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 容器最最小内存,默认1G |
| yarn.scheduler.maximum-allocation-mb | 容器最最大内存,默认8G |
| yarn.scheduler.minimum-allocation-vcores | 容器最小CPU核数,默认1个 |
| yarn.scheduler.maximum-allocation-vcores | 容器最大CPU核数,默认4个 |
2、案例实操
2.1 Yarn的Tool接口案例
(1)需求:自己写的程序可以动态传参。编写Yarn的Tool接口。
(2)编码
(a)WordCount类
package org.example._14yarntool;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.io.IOException;
/**
* @ClassName WordCount
* @Description TODO
* @Author Zouhuiming
* @Date 2023/5/24 17:34
* @Version 1.0
*/
public class WordCount implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
Job job= Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration configuration) {
this.conf=configuration;
}
@Override
public Configuration getConf() {
return conf;
}
public static class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
private Text outK=new Text();
private IntWritable outV=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] words = line.split(" ");
for (String word : words) {
outK.set(word);
context.write(outK,outV);
}
}
}
public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable outV=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
outV.set(sum);
context.write(key,outV);
}
}
}
(b)Driver类
package org.example._14yarntool;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.Arrays;
/**
* @ClassName WordCountDriver
* @Description TODO
* @Author Zouhuiming
* @Date 2023/5/24 17:42
* @Version 1.0
*/
public class WordCountDriver {
private static Tool tool;
public static void main(String[] args) throws Exception {
//1、创建配置文件
Configuration conf=new Configuration();
//2、判断是否有tool接口
switch (args[0]){
case "wordcount":
tool=new WordCount();
break;
default:
throw new RuntimeException("No such tool:"+args[0]);
}
//3、用Tool执行程序
//Arrays.copyOfRange()将老数组的元素放到新数组里面
int run=ToolRunner.run(conf,tool,Arrays.copyOfRange(args,1,args.length));
System.exit(run);
}
}







![[golang 微服务] 1.单体式架构以及微服务架构介绍](https://img-blog.csdnimg.cn/img_convert/f0dc37907a53072ef356b8bfc4b23f93.png)