1 Storm是什么
Apache Storm是一个分布式实时流式大数据处理框架。
2 计算框架对比
(1) Storm是在线处理数据方式,Mapreduce/spark是离线处理数据方式。
(2) Mapreduce数据处理特点
-
海量数据处理:G、T、P级都能处理
-
全量数据集同时处理:有多少输入数据都一次性同时处理
-
批处理方式:大数据输入、大批数据输出
-
吞吐能力强
(3) 其他数据处理类型:(mapredece满足不了的)
-
实时数据分析:实时报表动态展现、数据流量波动状况、反馈系统(有输入立马又输出,机器学习迭代),比如:炒股票、数据报表。
-
时效性:秒级处理完成数据,storm毫秒级别。
-
增量式处理:不同于mapreduce的批处理方式,任何时刻都在处理数据,数据来一条处理一条,比如:生产线传送带。
(4) 迭代:它会不断的循环多轮,最后达到一个比较好的状态,最后输出这个数据或者模型,然后限量使用,机器学习模型常用迭代概念。
(5) 流式计算框架特征:时效性高、逐条处理数据(增量式处理数据)、低延时(耗时少)。
(6) 无分布式流式处理:通过哈希(hash)算法分发到不同的服务器上。
(7) 分布式流式处理
-
单机处理不了原因:硬件条件限制(CPU、内存、存储)。
-
多机处理问题:流量控制、容灾冗余、路径选择、拓展。
(8) 分布式流式计算方案:storm、spark streaming;
两者差别:storm 毫秒级别、spark streaming 分钟级别。
(9) 延时:指数据从产生到运算产生结果的时间。
(10)吞吐:指系统单位时间处理的数据量。
3 Storm特点
(1) 有高容错性;
(2) 没有持久化层:持久化是指把数据持久化到磁盘上,就是数据存储,而没有持久化层就是storm是不存储的,不写磁盘,也是实效性的原因,不像MapReduce依赖HDFS;
(3) 保证消息得到处理:处理情况实时上报,消息确认的过程,数据处理可靠(TCP);
(4) 支持多种编程语言:Strom有一个thrift rpc协议,这是透明协议,可以支持多种编程语言,而Mapreduce支持多种语言是因为有一个包装;
(5) 高效:有基于底层的成熟消息队列,网络之间的联系和数据传输,以前用ZeroMQ,现在多用netty;
(6) 支持本地模式,可模拟集群所有功能:先本地测试代码是否成功;
(7) 使用原语:spout、bolt,类似mapreduce的map函数和reduce函数。
4 Storm与Hadoop(MapReduce)的区别
(1) Storm面向在线实时处理,MapReduce面向离线批量处理;
(2) storm任务一开启就没有结束,只能kill掉,Hadoop任务执行完结束;
(3) Storm内存计算,不经磁盘,延时更低;Hadoop使用磁盘作为中间交换介质;
(4) storm吞吐能力不及Hadoop,不适合批处理计算模型;
(5) mapreduce优点是稳定、吞吐能力强,缺点是时效性差,storm优点是时效性强,毫秒级别,缺点是吞吐差。
5 批量作业和增量作业
结合真正的业务场景:MapReduce和Storm各有优缺点,相互互补,让系统更健全,一起应用到业务场景批量作业和增量作业中。
批量作业和增量作业结合一起就是使用Mapreduce和storm结合的方式,
Mapreduce通常从hbase或者HDFS读取数据,storm是要数据落地的,通常对接的方式都是从一个消息队列里面进来的,或者数据库读取的,数据库可以是nosql或者hbase,storm速度比mapreduce快,但是稳定性比mapreduce差。
数据读取过程出问题,数据丢失,这时候可以回数。
回溯方案:
第一:消息队列做缓冲,就是一条信息处理完了再继续下一条,没处理完就不会再发过来,处理流程出问题了就先等流程恢复再继续处理;
第二:借助存储HBase;这是数据处理前,数据先经过存储;
第三:离线补,就是MapReduce根据时间去把数据补回来,耗时长。
6 Storm基本概念
(1) Stream:以tuple为基本单位组成的一条有向无界的数据流;
(HDFS基本单位是block,Storm基本单位是tuple)
(2) Tuple:数据基本单位,像integer,long,short,byte等,也可以自定义,相当于是数据封装;
(3) Topology:(网络拓扑)
-
计算逻辑的封装(执行任务),提交任务就是提交拓扑
-
由spouts原语和bolts原语组成的图,通过stream grouping将图中的spouts和bolts连接起来
-
类似MapReduce中的job
-
不会结束,除非主动kill
-
开头是spout,中间和结束都是bolt
(4) Spout
-
消息来源,消息生产者,消息分可靠和不可靠,消息发给bolt;
-
可靠消息是指有反馈的,不管执行成功失败,如果没有被成功处理,可重新emit(发出)一个tuple;
-
不可靠消息,就是不管执行成功失败,都不会又反馈的;
-
接收消息是否成功处理,至于具体消息如何处理,特别是收到failed消息时处理的策略由用户开发;
-
可指定emit多个Stream流:OutFieldsDeclarer.declareStream定义
SpoutOutputCollector指定。
(5) Bolt
-
消息处理者,如:过滤、访问外部服务、数据格式化、聚合、汇总、业务处理(设置黑名单,类似过滤)
-
多个bolt处理负责步骤
-
可以发射多个数据流
-
主方法为execute:以tuple为输入à处理具体的tupleà发射0或多个tupleàOutputCollector的ack,确认àIBasicBolt,会自动调节
(6) Spout输入可以多种类型:Queues(队列)、logs(日记)、database(数据库)、apicalls(api 调用)
(7) 对spout的开发主要是nexttuple,对bolt的开发主要是execute
(8) 比MapReduce更丰富:
-
数据同步并发处理,可设置并发参数,相比单节点reduce,速度快
-
task就是一个线程,多线程处理,MapReduce是进程处理
-
Grouping相当于partition,数据分桶,但可设置随机数
-
原语Spout和Bolt类似map和reduce。
数据流都可以汇总到HBase,当需要查看具体数据时,直接到HBase中查找rowkey。

7 Topology执行流程
Storm jar code.jar MyTopology arg1 arg2
(1) Storm jar负责连接到Nimbus并且上传jar包。
(2) 运行主类My Topology,参数是arg1,arg2;这个类的main函数定义这个topology并且把它提交给Nimbus。
(3) Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务,可以提交由任何语言创建的topology。
8 Storm数据处理流程
Storm实现worldcount

Spout与bolt之间是grouping通过分发策略分发的

Spout做分词,分发机制是随机的,目的是保证后面节点压力,负载均衡

第一列的bolt和第二列的bolt功能是不一样的,两列bolt中间实现有四种方式,
9 Strem Grouping
spout与bolt之间是通过grouping策略分发的,常用的是前2种
(1) Shuffle Grouping:随机分组
(2) Fields Grouping:按指定的field分组
(3) All Grouping:广播分组
(4) Global Grouping:全局分组

10 常见模型
(1) 流式计算
-
过滤:在一个Blot上设置一些条件(if判断),把不合适的数据过滤掉
-
组装:多个不同的bolt,把数据合并到一个bolt上,前提是集群同步
如:三个bolt属于不同的环节,三个环节是不同的角色,不同的功能

c. join:流式计算中数据有时候多有时候少,不能做全局的join,只能在一定的范围内,有很强的局限性
(2) 持续计算
类似反馈系统,输出直接反馈到输入,数据不断迭代,机器学习中用的多

(3) 分布式RPC
一种web服务,用一个集群来为一个用户的请求做一个响应。
11 Storm架构组件对比hadoop架构组件

(1) hadoop和mapreduce进程是Child,Storm进程是worker;
(2) mapreduce提交的任务是Job,Storm提交的任务是Topology;
12 Storm架构

(1) Nimbus:主节点,负责资源分配和任务调度,监控从节点状态;
(2) zookeeper:主从联系,任务协调,数据存放,Nimbus和Supervisor之间所有协调工作都是通过zookeeper集群完成;
(3) Supervisor:从节点,接收nimbus分配的任务,监控管理进程,进程是worker;
(4) worker:
-
是运行具体处理组件逻辑的进程;
-
一个Topology可能会在一个或者多个worker里面执行;
-
每个worker是一个物理JVM并且执行整个Topology的一部分;
-
采取JDK的Executor;
(5) Task:
-
是线程,worker中的每一个spout/bolt的线程称为task;
-
每一个spout和bolt会被当作很多task在整个集群里面执行;
-
每一个executor对应到一个线程,在这个线程上运行多个task(任务);
-
一个executor内部可以维护多个task,但是每次只会执行一个task;
-
stream grouping则是定义怎么从一堆task发射tuple到另外一堆task;
-
可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)。
(6) Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有状态要么在zookeeper里面,要么在本地磁盘上。
(7) 快速失败和无状态:即不管是Nimbus挂了还是Supervisor挂了,重启即可,无数据丢失,不影响。
(8) mapreduce中,如果JobTracker挂了,相当于集成框架挂了,Storm中,Nimbus挂了,之前已经提交的Topolopy是不受影响的,只是没有了主,后面的任务提交不了。
(9) 对于Storm集群有一个很重要的概念:并行度,并行度可配置,并行度可以理解为在执行mapreduce时,map的并发或者reduce的并发,并发约多,任务处理速度越快。
(10)比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks,Storm会尽量均匀的工作分配给所有的worker。
(11)同一个spout和bolt会共享同一个物理线程,Spout,bolt线程本质就是task线程,多个task线程共享同一个executor线程 。
(12)每一个进程执行一个Topolopy的一个子集,一个Topolopy由运行在很多机器上的很多worker工作进程组成。
(13)Work是进程,work里面有多个executor,在一个executor线程上,会执行很多task,标准的来说,executor是线程,task是executor处理一个或多个任务,这个任务就是spout或者bolt,storm中最细的粒度就是task,task本质就是一个节点类的实例对象。
(14)Set_num_task是用来配置一个executor同时处理多少个task,如果不设置的话,默认一个executor执行一个task。

Nimbus监控supervisor,supervisor监控worker;
task之间通过socket连接,实际就是spout与bolt通过StremGrouping连接。
13 Worker与task关系

(1) Storm集群的物理机会启动一个或多个worker进程(即jvm进程),所有的topology都在这些worker进程里被运行;
(2) 在一个单独的worker进程里会运行1个或者多个executor线程。executor里面可以有一个或多个task,每个executor只会运行1个topology的1个component(spout或者bolt)的实例(task);
(3) 1个task是最终完成数据处理的实体单元;
(4) 1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。 1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的;
(5) executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例);
(6) task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。 topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
14 集群配置
(1) topology配置
//得到集群默认配置
config conf = new Config();
• //设置Worker数量
conf.setNumWorkers(2);
// 设置Executor数量,Spout为2,Bolt也为2
topolopyBuilder.setSpout("BlueSpout",new BlueSpout(), 2);
topolopyBuilder.setBolt("GreenBolt",new GreenBolt(), 2)
.setNumTasks(4) // 设置Task数量为4,即2个bolt各有2个task
.shuffleGrouping("BlueSpout");
topolopyBuilder.setBolt("YellowBolt",new YellowBolt(), 6)
.shuffleGrouping("GreenBolt")
topolopyBuilder.setBolt("YellowBolt",new YellowBolt(), 6) //并发度为6
.shuffleGrouping("GreenBolt");
(2) 画图表示:BlueSpout、GreenBolt并发都为2,YellowBolt为6,采用shuffleGrouping随机分发。

(3) 进程与线程处理逻辑

全局的并发度:2+2+6=10,就是需要10个线程同时启动,worker为2个,所以每个进程处理5个线程,Green golt中有2个线程,但只需要1个工作即可,另一个是额外设置的,方便扩容。
(4) 临时调整并发度
重新配置topology使用5个workers,BlueSpout使用3个executors,YellowSpout使用10个executors;
]# storm rebalance myTopology -n 5 -e BlueSpout=3 -eYellowSpout=10
(5) 一个topology可以通过setNumWorkers来设置worker的数量,通过设置parallelism来规定executor的数量(一个component(spout/bolt)可以由多个executor来执行),通过setNumTasks来设置每个executor跑多少个task(默认为一对一)。task是spout和bolt执行的最小单元。
15 架构容错
容错功臣:ZooKeeper
(1) zookeeper:存储Nimbus与Supervisor数据(fail-fast原因);
(2) 节点宕机:Heartbeat心跳监控、Nimbus监控supervisor;
(3) Nimbus/Supervisor宕机:zookeeper存储有数据,worker继续工作;但如果worker失败,那任务失败;
(4) Worker出错:Supervisor重启worker;
(5) 大多数监控都是心跳形象汇报的:
-
Worker通过zookeeper汇报executor状态给nimbus;
-
Supervisor通过zookeeper汇报自己状态给nimbus。
16 数据容错
数据容错依靠两点:timeout(时间超时)和ack机制。
(1) storm可靠性是指storm会告知用户每一个消息单元是否在一个指定的时间
(timeout)内被完全处理。
(2) Ack机制,Storm中的每一个Topolog中都包含有一个Acker组件,ack本质是一个或者多个task,特殊的task,而且非常轻量,数据处理速度很快,方法简单,时间少,ack主要工作:反馈信息和透传。
(3) 把数据流比作一颗树,树根肯定是spout,数据增多,树枝分支也就越多。
(4) Ack机制:通过异或完成树遍历优化,ack个数如果设置太少,影响性能;ack个数如果设置太多,浪费空间。
(5) ack是由一组特殊的task来维护:一致性hash算法完成ack高可用。
(6) 异或原理:真假为真,假真为真,假假为假,真真为假。
(7) 所有节点的ack成功,任务成功,比如下图,一个消息经历spout-bolt-bolt三个阶段,如果这三个阶段都能成功处理,那这个任务就是成功了。
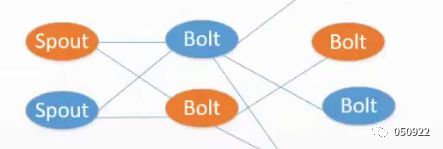
(8) 特殊的task(Acker Bolt):从tuple树的角度来监控任务运行的情况
Acker跟踪每一个spout发出的tuple树,一个tuple树完成时,发送ack给tuple的创造者,acker的数量,默认值是1,如果你的topology里面的tuple比较多的话,那么把acker的数量设置多一点,效率会高一点。
(9) 实现困难:acker task并不显式的跟踪tuple树。对于那些有成千上万个节点的tuple树,把这么多的tuple信息都跟踪起来会耗费太多的内存。这种方法是不太合适的,线下也不是这么实现的,但是可以借助异或原理。
(10)真实实现:内存量是恒定的(20bytes),对于100万tuple,大小20M左右,
ack_val所有创建的tupleid/ack的tuple一起异或,一个ackertask存储了一个spout-tuple-id到一对值的一个mapping。这个对子的第一个值是创建这个tuple的taskid,这个是用来在完成处理tuple的时候发送消息用的。第二个值是一个64位的数字称作ack val,ack val是整个tuple树的状态的一个表示,不管这棵树多大。它只是简单地把这课树上的所有创建的tupleid/ack的tupleid一起异或(XOR)。
(11)处理流程:由一个spout的发出信息通过了三个Botl来处理,那我们看一下如果我们初始化有一个0,这个0作为一个value,那如果一个task发出去消息的时候它就会帮你生成一个id号,那这个value1就代表tuple1,从spout生成tuple,只要生成了一个tuple它就会有一个tuple的ID,那么这个value1就是你的tuple的ID,输出和输入都会做一下异或,输出的时候做一下异或,输入的时候也要进行异或,那这个时候就可以发现一个很有意思的现象,输出和输入是成对出现的,只要是中间有任何一个节点都不失败的话那里面的话,异或最后的结果肯定是个0,这是一个比较简单的流程。

(12)一个tuple没有被ack:处理的task挂掉了,超时,重新处理。
(13)Ack挂掉了:其中一个ack挂了可以通过一致性hash找其他ack帮忙处理;所有ack全挂了,超时,重新处理。
(14)Spout挂掉了:重新处理。
(15)Anchoring:锚点,在bolt端,只有产生一个新的tuple消息才会有一次anchoring,anchcring相当于是一个产生新tuple消息的一个情况的描述,将新tuple作为一个锚点添加到原tuple上,即新消息添加到尾部。
(16)Multi-anchoring:多个锚点,spout同时发出多个消息,如果tuple有两个原tuple,则为每个tuple添加一个锚点。
(17)Ack:通知ack task,该tuple已被当前bolt成功消费。
(18)Fail:通知ack task,该tuple已被消费失败。
(19)说明:如下图
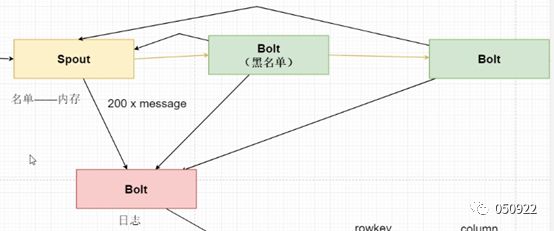
Bolt处理成功反馈ack给spout,处理失败返回fail给spout;成功失败说的是消息处理逻辑;
if(task_handle() == 1) {
ack()
} else {
//fail()
}
结果返回1,发送ack,处理成功,否则发送fali,处理失败;
storm本身没有重发逻辑,spout有200条信息名单,全部发送,发送一次,成功就成功,失败就失败,如果失败的还需要再重发,那就得额外开发,定义重新开发流程,开发工程师工作。
17 常用配置
Config.TOPOLOGY_WORKERS:
这个设置用多少个工作进程来执行这个topology。比如,如果你把它设置成25,那么集群里面一共会有25个java进程来执行这个topology的所有task。如果你的这个topology里面所有组件加起来一共有150的并行度,那么每个进程里面会有6个线程(150 / 25 = 6)。
Config.TOPOLOGY_ACKERS:
这个配置设置acker任务的并行度。默认的acker任务并行度为1,当系统中有大量的消息时,应该适当提高acker任务的并发度。设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用。
Config.TOPOLOGY_MAX_SPOUT_PENDING:
这个设置一个spout task上面最多有多少个没有处理的tuple(没有ack/failed)回复,我们推荐你设置这个配置,以防止tuple队列爆掉。
Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS:
这个配置storm的tuple的超时时间 – 超过这个时间的tuple被认为处理失败了。这个设置的默认设置是30秒。





![[golang 微服务] 1.单体式架构以及微服务架构介绍](https://img-blog.csdnimg.cn/img_convert/f0dc37907a53072ef356b8bfc4b23f93.png)