这篇文章我觉得做的也挺有意思的。
是在探究提示学习中渐进式的更新参数比一窝蜂的直接更新参数效果要佳。
开头
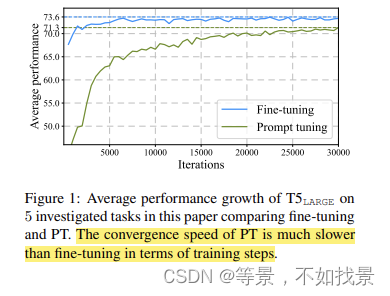
是从比较PT(prompt learning和fine tuning)开始的。为什么PT的收敛速度慢,训练效率低下?
因为PT中中可训练的参数大大减少了吧。微调起来不是很容易。
(我感觉论文中提到的PT是soft PT),折磨说的:PT prepends a few virtual
tokens to the input text, these tokens are tuned during training while all the other PLM parameters remain frozen
Core idea
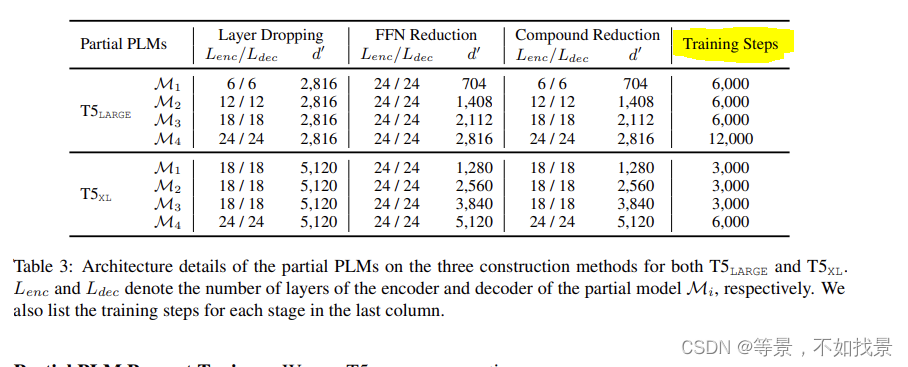
Fast Prompt Tuning (FPT), which starts by conducting PT using a small-scale partial PLM, and then progressively expands its depth and width until the full-model size.
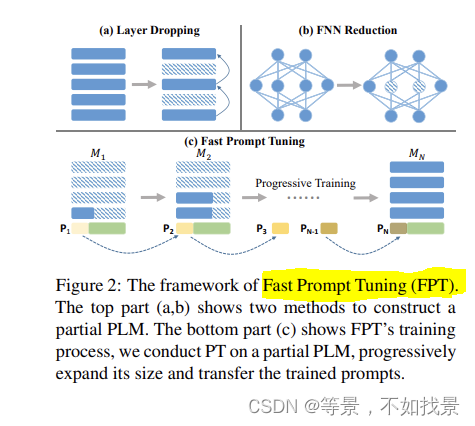
split the original PT training process into N stages.
We start with a small-size partial PLM M1 and
then progressively rehabilitate its depth and width
until the full-size model MN, creating a series of
partial PLMs {Mi}N−1i=1 with growing sizes在每个训练阶段 i,我们对部分 PLM Mi 进行 PT,并获得学习的软提示 Pi。基于观察到 Mi 保留了全尺寸 PLM MN 的大部分功能,我们推测 Mi 可以作为 MN 的完美替代品并学习如何处理下游任务。此外,考虑到不同部分 PLM 学习到的软提示在参数空间中很接近,我们可以通过回收 Pi 将 Mi 学到的知识迁移到 Mi+1。具体来说,每次模型扩展后,我们直接使用Pi作为下一阶段训练Mi+1的初始化。由于对于每个部分 PLM,参与前向和后向过程的参数较少,因此可以减少计算量。保持总训练步数不变,FPT 与 vanilla PT 相比可以加速训练
总结
渐进式(Progressive Training)对于加速和改善PT训练过程有帮助。
原文中给出的是train effect(训练效率:比如计算资源的使用量…)的对比表,在消耗较低资源下,还能取得不错的效果。
对照于开头中的训练效率对比图,给出的实验结果为:
![[附源码]计算机毕业设计新冠疫苗接种预约系统Springboot程序](https://img-blog.csdnimg.cn/568a2f3901e24607b3bcd14e44f715b7.png)




![[附源码]Python计算机毕业设计Django基于Java的图书购物商城](https://img-blog.csdnimg.cn/75a75284f55246019277cdc82bd71054.png)